こちらの続きになります。
ノートブックはこちら。
リトリーバ評価のチュートリアル
MLflow 2.8.0では、mlflow.evaluate() APIに新たなモデルタイプ"retriever"を追加しました。これによって、RAGアプリケーションのリトリーバを評価できるようになります。2つのビルトインメトリクスprecision_at_kとrecall_at_kが含まれています。MLflow 2.9.0ではndcg_at_kを利用できます。
このノートブックでは、RAGアプリケーションのリトリーバを評価するためにどのようにmlflow.evaluate()を使うのかを説明します。以下のステップが含まれています:
- Step 1: パッケージのインストールとロード
- Step 2: 評価データセットの準備
- Step 3:
mlflow.evaluate()の呼び出し - Step 4: 結果の分析と可視化
Step 1: パッケージのインストールとロード
%pip install mlflow==2.9.0 langchain==0.0.339 openai faiss-cpu gensim nltk pyLDAvis tiktoken "pandas<2.0.0"
注意
結果の分析と可視化でこちらのエラーに遭遇したので、pandasのバージョンを下げています。
import ast
import os
import pprint
from typing import List
import pandas as pd
from langchain.docstore.document import Document
from langchain.embeddings.openai import OpenAIEmbeddings
from langchain.text_splitter import CharacterTextSplitter
from langchain.vectorstores import FAISS
import mlflow
os.environ["OPENAI_API_KEY"] = dbutils.secrets.get("demo-token-takaaki.yayoi", "openai_api_key")
CHUNK_SIZE = 1000
# https://github.com/mlflow/mlflow/blob/master/examples/llms/rag のパスで実行していることを前提としています
OUTPUT_DF_PATH = "question_answer_source.csv"
SCRAPPED_DOCS_PATH = "mlflow_docs_scraped.csv"
EVALUATION_DATASET_PATH = "static_evaluation_dataset.csv"
DB_PERSIST_DIR = "faiss_index"
Step 2: 評価データセットの準備
評価データセットには3つのカラムが含まれている必要があります: 質問、正解文書のID、収集された文書のIDです。"文書ID"はお使いのRAGアプリケーションにおける文書に対する一意の文字列IDです。例えば、WebページのURL、PDF文書のファイルパスなどになります。
評価したい一連の質問があるのであれば、手動での準備をご覧ください。まだ質問のリストがないのであれば、評価データセットの生成をご覧ください。
手動での準備
リトリーバを評価する際、評価のために、入力のクエリー、収集された文書のID、正解文書のIDを含むPandasデータフレーム、あるいはMLflow Pandasデータセットで表現される静的なデータセットに収集された文書のIDを保存することが推奨されます。
コンセプト
"文書ID"は文書を特定する文字列です。
"収集文書のID"のリストは、指定された入力クエリーとkの値によるリトリーバの出力です。
"正解文書のID"のリストは、指定された入力クエリーに対してラベル付けされた適切な文書です。
期待されるデータフォーマット
それぞれの行においては、文書ID文字列のタプルとして、収集された文書のIDと正解文書のIDが含まれる必要があります。
収集された文書のIDのカラム名はpredictionsパラメータで指定することができ、正解文書のIDのカラム名はtargetsパラメータで指定することができます。
期待されるデータフォーマットを説明するシンプルなサンプルデータセットを示します。文書IDはドキュメントページのパスとなっています。
data = pd.DataFrame(
{
"questions": [
"What is MLflow?",
"What is Databricks?",
"How to serve a model on Databricks?",
"How to enable MLflow Autologging for my workspace by default?",
],
"retrieved_context": [
[
"mlflow/index.html",
"mlflow/quick-start.html",
],
[
"introduction/index.html",
"getting-started/overview.html",
],
[
"machine-learning/model-serving/index.html",
"machine-learning/model-serving/model-serving-intro.html",
],
[],
],
"ground_truth_context": [
["mlflow/index.html"],
["introduction/index.html"],
[
"machine-learning/model-serving/index.html",
"machine-learning/model-serving/llm-optimized-model-serving.html",
],
["mlflow/databricks-autologging.html"],
],
}
)
評価データセットの生成
評価データセットの生成には2ステップあります: 正解文書IDで質問を生成し、文書IDを収集します。
正解文書IDによる質問の生成
評価する質問のリストがない場合には、LLMを用いて生成することができます。Question Generation Notebookでは、そのためのサンプルを提供しています。こちらが、そのノートブックの実行結果です。
generated_df = pd.read_csv(OUTPUT_DF_PATH)
generated_df.head(3)

# 必要なフォーマットで`data`データフレームを準備
data = pd.DataFrame({})
data["question"] = generated_df["question"].copy(deep=True)
data["source"] = generated_df["source"].apply(lambda x: [x])
data.head(3)

文書IDの収集
上で正解文書のIDを持つ質問のリストを得たら、文書IDを収集することができます。このチュートリアルでは、LangChainリトリーバを使います。必要に応じてお好きなリトリーバをプラグインすることができます。
はじめに、 https://github.com/mlflow/mlflow/blob/master/examples/llms/question_generation/mlflow_docs_scraped.csv に保存されている文書からFAISSリトリーバを構築します。このCSVファイルの作成方法については、Question Generation Notebookをご覧ください。
embeddings = OpenAIEmbeddings()
scrapped_df = pd.read_csv(SCRAPPED_DOCS_PATH)
list_of_documents = [
Document(page_content=row["text"], metadata={"source": row["source"]})
for i, row in scrapped_df.iterrows()
]
text_splitter = CharacterTextSplitter(chunk_size=CHUNK_SIZE, chunk_overlap=0)
docs = text_splitter.split_documents(list_of_documents)
db = FAISS.from_documents(docs, embeddings)
# dbをディスクに保存
db.save_local(DB_PERSIST_DIR)
# ディスクからdbをロード
db = FAISS.load_local(DB_PERSIST_DIR, embeddings)
retriever = db.as_retriever()
# クエリーでリトリーバをテスト
retrieved_docs = retriever.get_relevant_documents(
"What is the purpose of the MLflow Model Registry?"
)
len(retrieved_docs)
4
リトリーバを構築したら、入力として質問の文字列を受け取り、収集した文書IDの文字列のリストを返却する関数を定義します。
# 収集した文書IDのリストを返却する関数の定義
def retrieve_doc_ids(question: str) -> List[str]:
docs = retriever.get_relevant_documents(question)
return [doc.metadata["source"] for doc in docs]
収集した文書のIDをデータフレームのカラム"retrieved_doc_ids"に格納することができます。
data["retrieved_doc_ids"] = data["question"].apply(retrieve_doc_ids)
data.head(3)

# 静的な評価データセットをディスクに永続化
data.to_csv(EVALUATION_DATASET_PATH, index=False)
# ディスクから静的評価データセットをロードし、ソースと収集文書IDをデシリアライズ
data = pd.read_csv(EVALUATION_DATASET_PATH)
data["source"] = data["source"].apply(ast.literal_eval)
data["retrieved_doc_ids"] = data["retrieved_doc_ids"].apply(ast.literal_eval)
data.head(3)

Step 3: mlflow.evaluate()の呼び出し
メトリクスの定義
リトリーバモデルタイプには3つのビルトインのメトリクスが提供されています。メトリクスの定義を確認するには以下のメトリック名をクリックしてください。
すべてのメトリクスは、指定されたkの値におけるリトリーバの対応するメトリックを表現する0から1のスコアをそれぞれの行で計算します。
kパラメータは、それぞれの行で評価を行うために収集された文書の数を表現する正の整数でなくてはなりません。kのデフォルトは3です。
モデルタイプが"retriever"の場合、これらのメトリクスはkの値がデフォルトの3を用いて自動で計算されます。
基本的な使い方
リトリーバの出力を指定する方法は2つサポートされています:
- Case 1: 静的な評価データセットにリトリーバの出力を保存
- Case 2: 関数でリトリーバをラップ
# Case 1: 静的な評価データセットを評価
with mlflow.start_run() as run:
evaluate_results = mlflow.evaluate(
data=data,
model_type="retriever",
targets="source",
predictions="retrieved_doc_ids",
evaluators="default",
)
メトリクスが記録されます。
question_source_df = data[["question", "source"]]
question_source_df.head(3)

# Case 2: 関数を評価
def retriever_model_function(question_df: pd.DataFrame) -> pd.Series:
return question_df["question"].apply(retrieve_doc_ids)
with mlflow.start_run() as run:
evaluate_results = mlflow.evaluate(
model=retriever_model_function,
data=question_source_df,
model_type="retriever",
targets="source",
evaluators="default",
)
pp = pprint.PrettyPrinter(indent=4)
pp.pprint(evaluate_results.metrics)
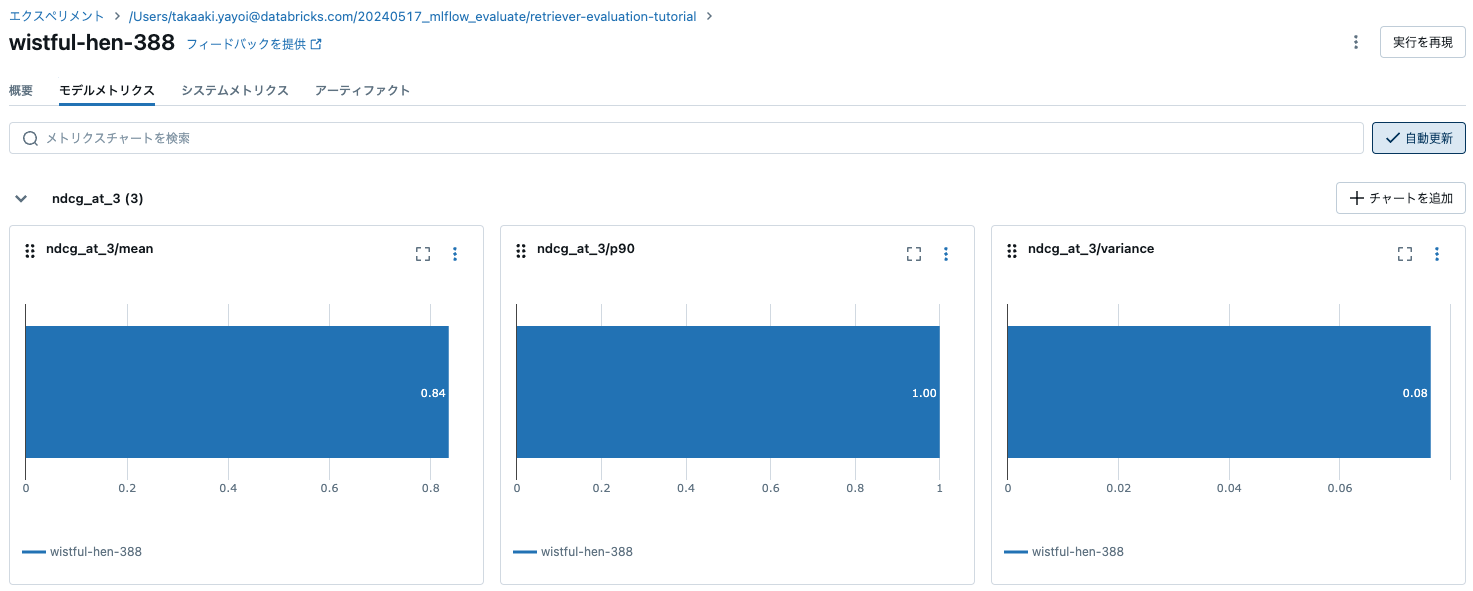
{ 'ndcg_at_3/mean': 0.8357404863796751,
'ndcg_at_3/p90': 1.0,
'ndcg_at_3/variance': 0.07640753464954265,
'precision_at_3/mean': 0.28888888888888886,
'precision_at_3/p90': 0.3333333333333333,
'precision_at_3/variance': 0.012839506172839505,
'recall_at_3/mean': 0.8666666666666667,
'recall_at_3/p90': 1.0,
'recall_at_3/variance': 0.11555555555555554}
異なるkの値を試す
別のkの値を使用するには、evaluator_config={"retriever_k": <k_value>}というように、mlflow.evaluate() APIでevaluator_configパラメータを使用します。
# Case 1: モデルタイプの指定
evaluate_results = mlflow.evaluate(
data=data,
model_type="retriever",
targets="ground_truth_context",
predictions="retrieved_context",
evaluators="default",
evaluator_config={"retriever_k": 5}
)
あるいは、モデルタイプを指定せずにmlflow.evaluate() APIのextra_metricsパラメータで必要なパラメータを直接指定することができます。この場合、evaluator_configパラメータで指定されたkの値は無視されます。
# Case 2: extra_metricsを指定
evaluate_results = mlflow.evaluate(
data=data,
targets="ground_truth_context",
predictions="retrieved_context",
extra_matrics=[
mlflow.metrics.precision_at_k(4),
mlflow.metrics.precision_at_k(5)
],
)
with mlflow.start_run() as run:
evaluate_results = mlflow.evaluate(
data=data,
targets="source",
predictions="retrieved_doc_ids",
evaluators="default",
extra_metrics=[
mlflow.metrics.precision_at_k(1),
mlflow.metrics.precision_at_k(2),
mlflow.metrics.precision_at_k(3),
mlflow.metrics.recall_at_k(1),
mlflow.metrics.recall_at_k(2),
mlflow.metrics.recall_at_k(3),
mlflow.metrics.ndcg_at_k(1),
mlflow.metrics.ndcg_at_k(2),
mlflow.metrics.ndcg_at_k(3),
],
)
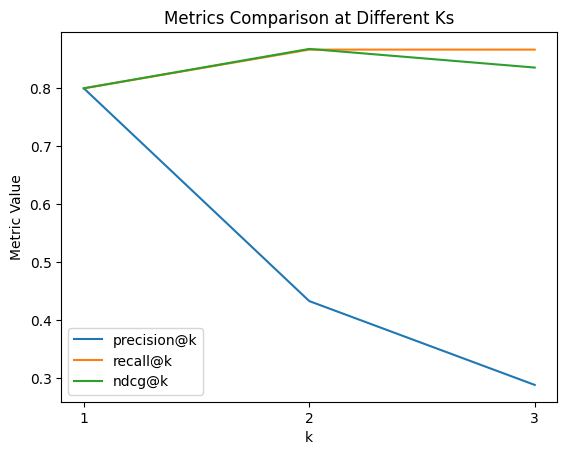
import matplotlib.pyplot as plt
# それぞれのメトリックをプロット
for metric_name in ["precision", "recall", "ndcg"]:
y = [evaluate_results.metrics[f"{metric_name}_at_{k}/mean"] for k in range(1, 4)]
plt.plot([1, 2, 3], y, label=f"{metric_name}@k")
# ラベルとタイトルの追加
plt.xlabel("k")
plt.ylabel("Metric Value")
plt.title("Metrics Comparison at Different Ks")
# x-axisのティックを設定
plt.xticks([1, 2, 3])
plt.legend()
# プロットの表示
plt.show()
極端なケースへの対応
それぞれのビルトインメトリックに関連する極端なケースが存在します。
空の収集文書ID
適切な文書が収集されない場合:
-
mlflow.metrics.precision_at_k(k)は以下のように定義されます:- 0 : 正解文書IDが空ではない場合
- 1 : 正解文書IDも空の場合
-
mlflow.metrics.ndcg_at_k(k)は以下のように定義されます:- 0 : 正解文書IDが空ではない場合
- 1 : 正解文書IDも空の場合
空の正解文書ID
正解文書のIDが指定されていない場合:
-
mlflow.metrics.recall_at_k(k)は以下のように定義されます:- 0 : 収集文書のIDが空ではない場合
- 1 : 収集文書のIDも空の場合
-
mlflow.metrics.ndcg_at_k(k)は以下のように定義されます:- 0 : 収集文書のIDが空ではない場合
- 1 : 収集文書のIDも空の場合
収集文書IDの重複
指定されたクエリーに対して、RAGシステムのリトリーバが同じ文書の複数のチャンクを収集してしまうことはよくあることです。この場合、mlflow.metrics.ndcg_at_k(k)は以下のように計算されます:
重複文書のIDが正解文書に含まれる場合、
これらは異なる文書として取り扱われます。例えば、正解文書IDが[1, 2]であり、収集文書のIDが[1, 1, 1, 3]である場合、スコアは正解文書ID[10, 11, 12, 2]で収集文書IDは[10, 11, 12, 3]と同じものとなります。
重複文書IDが正解文書に含まれない場合、ndcgスコアは通常通りに計算されます。
Step 4: 結果の解析と可視化
Pandasデータフレームにロードするか、MLflowランの比較UIにアクセスすることでアーティファクトの"eval_results_table.json"に記録された行ごとのスコアを参照することができます。
eval_results_table = evaluate_results.tables["eval_results_table"]
eval_results_table.head(5)
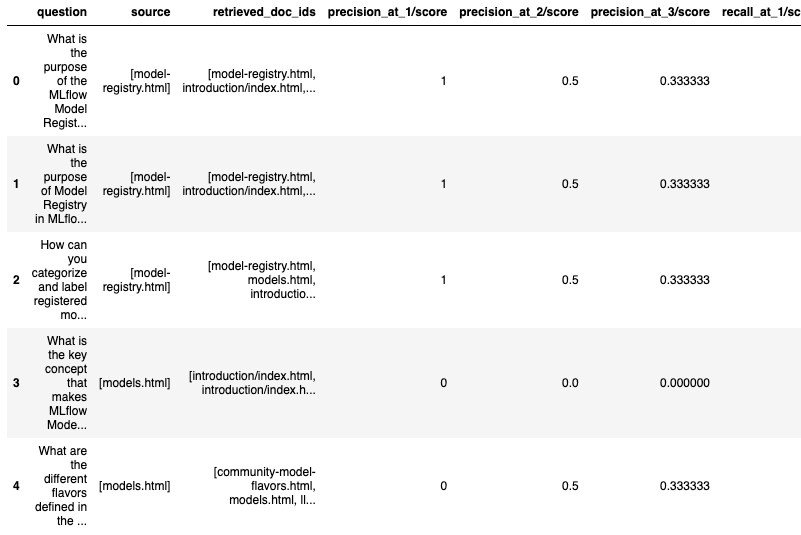
評価結果のテーブルを用いたトピック解析テクニックによって、適切に回答された質問と不適切に回答された質問をさらに可視化することができます。
import nltk
import pyLDAvis.gensim_models as gensimvis
from gensim import corpora, models
from nltk.corpus import stopwords
from nltk.tokenize import word_tokenize
# NLTKリソースの初期化
nltk.download("punkt")
nltk.download("stopwords")
def topical_analysis(questions: List[str]):
stop_words = set(stopwords.words("english"))
# トークナイズ、ストップワードの除外
tokenized_data = []
for question in questions:
tokens = word_tokenize(question.lower())
filtered_tokens = [word for word in tokens if word not in stop_words and word.isalpha()]
tokenized_data.append(filtered_tokens)
# ディクショナリーとコーパスの作成
dictionary = corpora.Dictionary(tokenized_data)
corpus = [dictionary.doc2bow(text) for text in tokenized_data]
# LDAモデルの適用
lda_model = models.LdaModel(corpus, num_topics=5, id2word=dictionary, passes=15)
# それぞれの質問に対するトピックの分布を取得
topic_distribution = []
for i, ques in enumerate(questions):
bow = dictionary.doc2bow(tokenized_data[i])
topics = lda_model.get_document_topics(bow)
topic_distribution.append(topics)
print(f"Question: {ques}\nTopic: {topics}")
# すべてのトピックの表示
print("\nTopics found are:")
for idx, topic in lda_model.print_topics(-1):
print(f"Topic: {idx} \nWords: {topic}\n")
return lda_model, corpus, dictionary
filtered_df = eval_results_table[eval_results_table["precision_at_1/score"] == 1]
hit_questions = filtered_df["question"].tolist()
filtered_df = eval_results_table[eval_results_table["precision_at_1/score"] == 0]
miss_questions = filtered_df["question"].tolist()
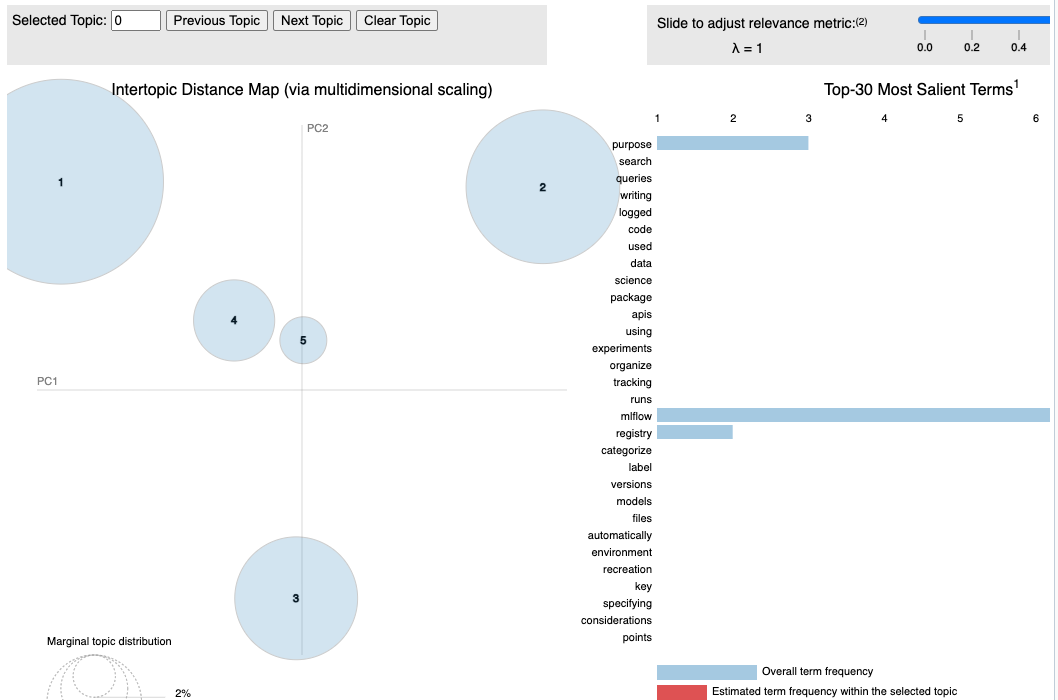
lda_model, corpus, dictionary = topical_analysis(hit_questions)
vis_data = gensimvis.prepare(lda_model, corpus, dictionary)
Question: What is the purpose of the MLflow Model Registry component?
Topic: [(0, 0.86343163), (1, 0.03338508), (2, 0.035914216), (3, 0.03361473), (4, 0.033654336)]
Question: What is the purpose of Model Registry in MLflow and what are the components of a registered model in Model Registry?
Topic: [(0, 0.91953593), (1, 0.020004475), (2, 0.020121705), (3, 0.020240884), (4, 0.020096948)]
Question: How can you categorize and label registered models and model versions in MLflow?
Topic: [(0, 0.025399163), (1, 0.02500914), (2, 0.025165884), (3, 0.89929116), (4, 0.02513462)]
Question: What files are automatically logged for environment recreation when a model is logged in MLflow?
Topic: [(0, 0.022455394), (1, 0.022229133), (2, 0.022349935), (3, 0.9106396), (4, 0.022325933)]
Question: What is an MLflow Project and how is it used to package data science code?
Topic: [(0, 0.025087232), (1, 0.025015809), (2, 0.8993774), (3, 0.025074318), (4, 0.025445208)]
Question: What are the key considerations for specifying project environments and entry points in MLflow?
Topic: [(0, 0.022290308), (1, 0.022230787), (2, 0.022324033), (3, 0.022279765), (4, 0.9108751)]
Question: What are the supported project environments in MLflow and how do they differ from each other?
Topic: [(0, 0.033498354), (1, 0.03334409), (2, 0.03358537), (3, 0.033471275), (4, 0.8661009)]
Question: How can you search MLflow runs based on metrics, params, tags, dataset information, and run metadata?
Topic: [(0, 0.016761385), (1, 0.016676927), (2, 0.93315375), (3, 0.016699089), (4, 0.016708862)]
Question: What is the purpose of writing search queries in MLflow?
Topic: [(0, 0.034033533), (1, 0.033350293), (2, 0.8653881), (3, 0.033469744), (4, 0.03375829)]
Question: What is the purpose of MLflow Tracking and what does it allow you to log and visualize?
Topic: [(0, 0.02913186), (1, 0.0285842), (2, 0.028816793), (3, 0.0286709), (4, 0.8847962)]
Question: How can you organize your runs into experiments using MLflow Tracking APIs?
Topic: [(0, 0.89948905), (1, 0.025011655), (2, 0.025191432), (3, 0.025084285), (4, 0.025223577)]
Question: How can you track datasets associated with model training events in MLflow?
Topic: [(0, 0.025844194), (1, 0.025015678), (2, 0.8985949), (3, 0.025446624), (4, 0.025098551)]
Topics found are:
Topic: 0
Words: 0.135*"model" + 0.104*"registry" + 0.096*"mlflow" + 0.068*"purpose" + 0.039*"tracking" + 0.039*"runs" + 0.039*"components" + 0.039*"experiments" + 0.039*"apis" + 0.039*"using"
Topic: 1
Words: 0.018*"component" + 0.018*"mlflow" + 0.018*"purpose" + 0.018*"model" + 0.018*"project" + 0.018*"tracking" + 0.018*"queries" + 0.018*"writing" + 0.018*"runs" + 0.018*"registered"
Topic: 2
Words: 0.106*"mlflow" + 0.052*"search" + 0.031*"purpose" + 0.029*"model" + 0.028*"dataset" + 0.028*"params" + 0.028*"metadata" + 0.028*"tags" + 0.028*"based" + 0.028*"metrics"
Topic: 3
Words: 0.085*"model" + 0.085*"mlflow" + 0.085*"logged" + 0.046*"registered" + 0.046*"environment" + 0.046*"files" + 0.046*"recreation" + 0.046*"automatically" + 0.046*"versions" + 0.046*"categorize"
Topic: 4
Words: 0.107*"mlflow" + 0.073*"project" + 0.073*"environments" + 0.040*"key" + 0.040*"specifying" + 0.040*"points" + 0.040*"considerations" + 0.040*"entry" + 0.040*"visualize" + 0.040*"allow"
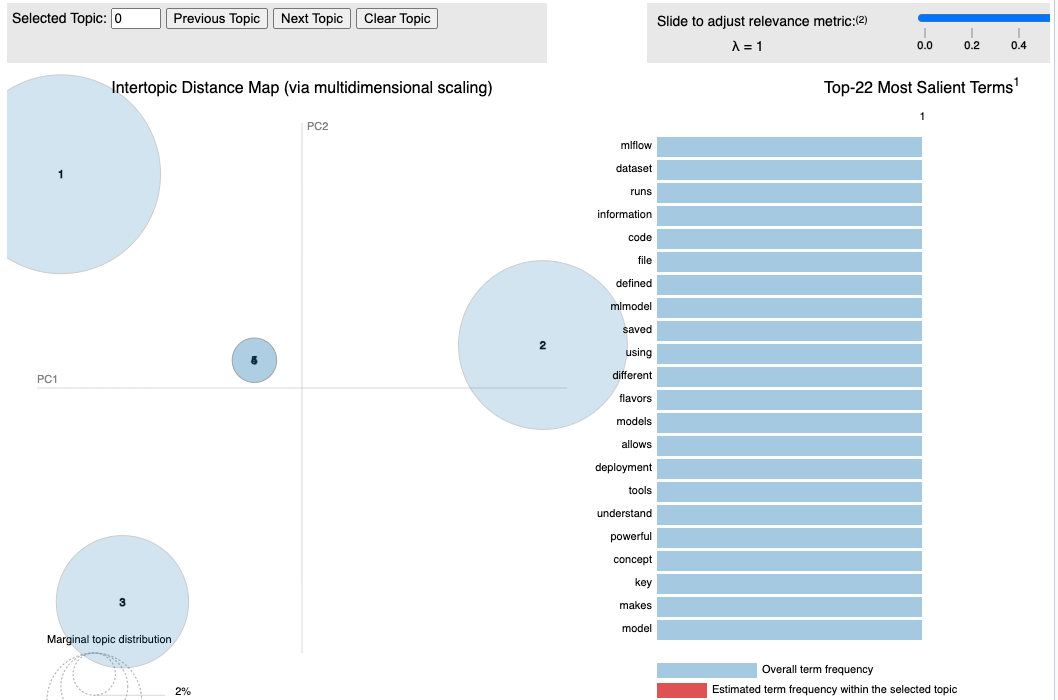
トピックを可視化します。
import pyLDAvis
pyLDAvis.display(vis_data)
lda_model, corpus, dictionary = topical_analysis(miss_questions)
vis_data = gensimvis.prepare(lda_model, corpus, dictionary)
Question: What is the key concept that makes MLflow Models powerful and allows deployment tools to understand the model?
Topic: [(0, 0.016677847), (1, 0.016677847), (2, 0.016720114), (3, 0.9331856), (4, 0.01673864)]
Question: What are the different flavors defined in the MLmodel file for a model saved using mlflow.sklearn?
Topic: [(0, 0.022234242), (1, 0.022234242), (2, 0.91101927), (3, 0.022284763), (4, 0.022227516)]
Question: What does the code above do with MLflow runs and dataset information?
Topic: [(0, 0.033347126), (1, 0.033347126), (2, 0.033337887), (3, 0.03344694), (4, 0.86652094)]
Topics found are:
Topic: 0
Words: 0.045*"mlflow" + 0.045*"model" + 0.045*"information" + 0.045*"code" + 0.045*"runs" + 0.045*"dataset" + 0.045*"mlmodel" + 0.045*"using" + 0.045*"flavors" + 0.045*"different"
Topic: 1
Words: 0.045*"mlflow" + 0.045*"model" + 0.045*"information" + 0.045*"code" + 0.045*"runs" + 0.045*"dataset" + 0.045*"using" + 0.045*"mlmodel" + 0.045*"different" + 0.045*"flavors"
Topic: 2
Words: 0.097*"model" + 0.097*"saved" + 0.097*"defined" + 0.097*"file" + 0.097*"flavors" + 0.097*"different" + 0.097*"mlmodel" + 0.097*"using" + 0.016*"mlflow" + 0.016*"information"
Topic: 3
Words: 0.078*"key" + 0.078*"powerful" + 0.078*"concept" + 0.078*"tools" + 0.078*"allows" + 0.078*"understand" + 0.078*"makes" + 0.078*"models" + 0.078*"deployment" + 0.078*"model"
Topic: 4
Words: 0.128*"mlflow" + 0.128*"dataset" + 0.128*"runs" + 0.128*"code" + 0.128*"information" + 0.021*"deployment" + 0.021*"models" + 0.021*"makes" + 0.021*"model" + 0.021*"understand"
pyLDAvis.display(vis_data)