How Glow Performs Genetic Association Studies 10x More Efficiently Than Hail - The Databricks Blogの翻訳です。
GlowがGWASベンチマークで10倍のコストパフォーマンスを達成
遺伝子技術はRNAワクチンから遺伝子操作、遺伝子診断に至るような新たな治療法を生み出しています。これらの領域における進展は、遺伝子に対する機械学習、データ分析のためのオープンソースツールキットであるGlowの開発の我々のモチベーションとなりました。このツールキットは、ビッグデータ処理の最先端エンジンである Apache Spark™上にネイティブで構築されており、人口規模の遺伝学を可能としています。
このプロジェクトはRegeneron Genetics CenterとDatabricksの業界コラボレーションとしてスタートしました。次世代ゲノミクスデータ分析ツールをコミュニティに提供することで、研究を前進させることがゴールです。Hail、Plink、bedtoolsのようなバイオインフォマティクスライブラリからインスピレーションを受け、大規模データ処理における最高の技術と結びつけました。今やGlowは、遺伝子関連解析における業界主要ツールよりも、計算処理の効率が10倍以上となっています。
Glow、大規模遺伝子分析におけるビジョン
ゲノミクスの成長を妨げている主要なボトルネックは、データ管理、データ分析の複雑性です。我々は、バイオインフォマティクスのトレーニングを受けていないデータエンジニア、データサイエンティストが分散クラウドコンピューティング環境においてゲノミクスデータ処理に貢献できるように、シンプルにすることを目指しています。このボトルネックを改善することで、より多くのシーケンスデータに対する要求をポジティブなフィードバックで回せるようになります。
Glowのユースケース
Glowの適用領域は、遺伝変異体データの集計、マイニングとなります。特に、以下のように何回も繰り返し実行するデータ分析や、完了に数時間以上要する処理が対象となります。
- アノテーションパイプライン
- 遺伝関連研究
- GPUベースのディープラーニングアルゴリズム
- バイオインフォマティクスツールとのデータ変換
例えば、GlowにはRegenie methodの分散処理実装が含まれています。Regenieをシングルノードで実行することは可能であり、これはアカデミックなサイエンティストには推奨となります。しかし、業界アプリケーションにおいて数千の関連テストを実行するためには、Glowは世界で最もコスト効率が高く、スケーラブルな方法となります。どのように動作するのかを見ていきましょう。
Hailに対するGlowのベンチマーク
あらゆる分析パイプラインにおいて、遺伝関連研究が最も計算リソースを必要とするステップであるため、我々はこれにフォーカスしました。Firth回帰においてGlowとHailと比較した場合、Glowは精度を損なうことなしに10倍以上の性能を実現します(図1)。最初に近似手法を適用し、疾病との関連の可能性がある変異体(P < 0.05)に対して、完全な手法を適用することでこの性能を達成することができました。Firth回帰は、稀有な疾病を持つ少数の個人によるバイアスを削減するため、バイオバンクデータに対して最もパワフルな手法となっています。より詳細なベンチマークはGlowのドキュメントで参照することができます。
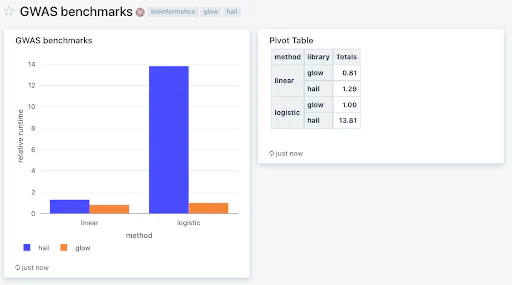
図1:500kのサンプル、250kの変異体の合成データセットに対して、メモリー最適化仮想マシン48台による768コアで実行したGlowとHailのベンチマークを表示するDatabricks SQLダッシュボード。Glow v1.1.0とHail v0.2.76を使用。相対的な実行時間を表示。これらのベンチマークを再現するには、Glow Github repositoryからノートブックをダウンロードし、環境構築には添付されているdockerコンテナを使用してください。
DatabricksレイクハウスプラットフォームにおけるGlow
タイトなスケジュールでGlowを開発している小規模なエンジニアリングチームが存在しています。では、どのようにして、世界最先端の生物医学研究機関、Hailの背後にある頭脳にキャッチアップすることができたのでしょうか?業界パートナーとのコラボレーションを通じて、Databricksのレイクハウスプラットフォーム上でGlowを開発したからです。Databrickは、あなたが実施するゲノミクスデータ分析を生産的にするインフラストラクチャを提供します。例えば、複数の依存関係を伴う複雑なパイプラインを構築するためにDatabricksのジョブを活用することができます(図2)。
さらに、Databricksは、データガバナンス(FAIR)やコンプライアンス(HIPAA、GDPR)に関する規制に準拠しており、フォーチュン100や最もセンシティブなデータを取り扱うヘルスケア企業から信頼されているセキュアなプラットフォームです。
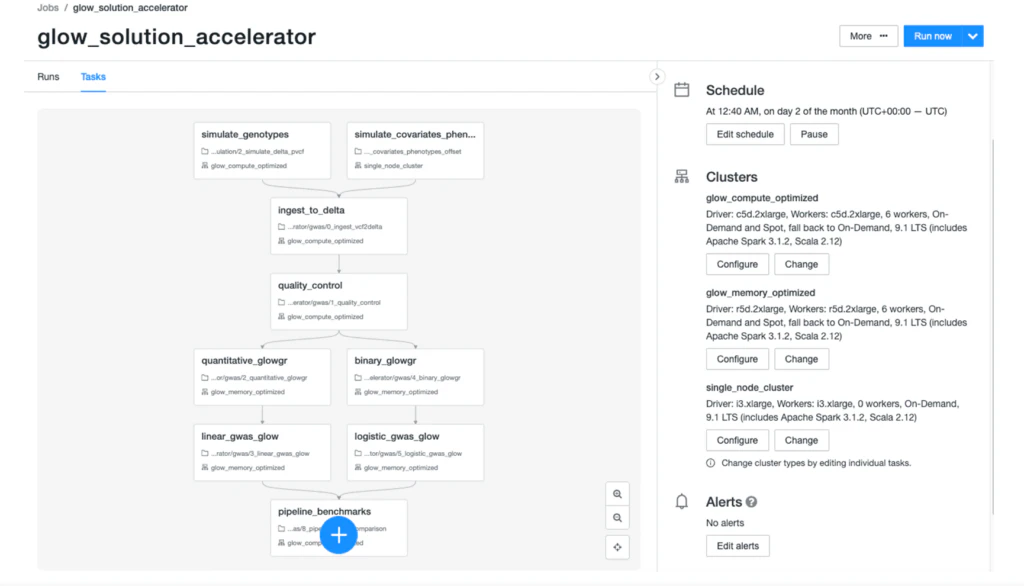
図2:DatabricksレイクハウスプラットフォームにおけるGlow
将来的には何が提供されるのか?
Glowはレベル1の成熟度であり、コミュニティの皆様が開発、拡張に貢献してくださることを着台しています。興奮すべき多くのことが存在しています。
ゲノミクスデータベースは非常に膨大であり、Apache Sparkのバッチ処理においても、特定のクラウドリージョンではキャパシティのリミットに達する場合があります。この問題は、バッチ、ストリーム処理を統合するオープンなDelta Lakeフォーマットによって解決されることでしょう。ストリーミングを活用することで、Delta Lakeは新規のサンプルや変異体をインクリメンタルに処理することができ、エッジケースを将来的な分析のために検疫することもできます。GlowとDelta Lakeを組み合わせることで、ゲノミクスにおける「n+1問題」を解決できることでしょう。
ゲノミクス研究における別の問題にデータの爆発があります。Amazon Web Services単体でもCancer Genome Atlasのコピーが50以上存在しています。現在提案できるソリューションは、ゲノミクスドメインプラットフォームにおけるデータセットの管理(walled garden:特定の人のみがアクセスできる環境)となります。これによりデータの重複を避け、プラットフォーム にデータを閉じ込めることができます。
このような摩擦は、大規模データセットをセキュア、リアルタイムに交換できるオープンプロトコルであるDelta Sharingによって軽減されることでしょう。これにより、企業間、クラウド間、ドメインプラットフォーム間でセキュアなデータ交換が可能となります。Unity Catalogを用いることで、これらのデータ資産の検索、監査、管理が容易になります。
我々はまだゲノミクスデータ分析の産業化を始めたばかりです。より詳細を知りたければ、Glowのドキュメント、YouTubeのテックトーク、ワークショップをご覧ください。