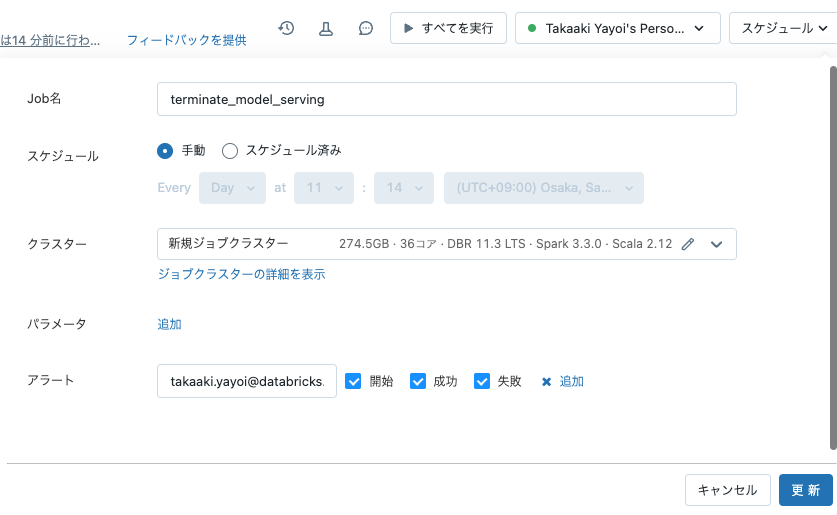
Databricksで機械学習モデルをREST APIから呼び出せる様にするための、モデルサービングは便利ですが、サービングを有効化するとクラスターが起動し、これは明示的に止めない限り稼働し続け、コスト増につながります。自動停止がないので止め忘れも結構あるかと思います。すみません。
なお、新たなサーバレス推論エンドポイントは、REST APIのリクエストがない場合、0ノードまでダウンスケールします。
そこで、サンドボックス環境など実験がメインの環境においては、一定時間ごとにモデルサービングエンドポイントを停止する処理をジョブで実行することがベストプラクティスと言えます。DatabricksのMLflow REST APIを活用することで、ノートブックからMLflowモデルサービングエンドポイントを制御することができます。
サンプルノートブックはこちらです。
注意
- すべてのモデルサービングエンドポイントを停止するには、管理者権限を持つユーザーでこのノートブックを実行してください。
- ジョブでこのノートブックを実行する際には、ユーザーにエンドポイントの運用を周知(xx時間ごとに停止ジョブが実行される等)してください。
ワークスペースURLとトークンの取得
ノートブックからREST APIを呼び出します。
こちらの記事にあるように、ノートブックからREST APIを呼び出す際には、パーソナルアクセストークンを発行しなくてもREST APIにアクセスすることができます。
Python
databricksURL = dbutils.notebook.entry_point.getDbutils().notebook().getContext().apiUrl().getOrElse(None)
myToken = dbutils.notebook.entry_point.getDbutils().notebook().getContext().apiToken().getOrElse(None)
エンドポイント一覧の取得
稼働中のエンドポイント一覧を取得します。
Python
import requests
import json
header = {'Authorization': 'Bearer {}'.format(myToken)}
endpoint = '/api/2.0/mlflow/endpoints/list'
payload = """{}"""
#print(payload)
resp = requests.get(
databricksURL + endpoint,
data=payload,
headers=header
)
data = resp.json()
print (json.dumps(data, indent=4))
(アクセス権を持つ)稼働中のモデルサービングエンドポイントを取得することができます。

エンドポイントの停止
エンドポイントに対して、endpoints/disableを呼び出すことで、モデルサービングエンドポイントを停止することができます。
Python
for rest_endpoint in data["endpoints"]:
print(rest_endpoint["registered_model_name"], ":", rest_endpoint["state"])
# REST APIの停止
header = {'Authorization': 'Bearer {}'.format(myToken)}
endpoint = '/api/2.0/mlflow/endpoints/disable'
payload = {"registered_model_name": rest_endpoint["registered_model_name"]}
# JSON形式の文字列に変換
payload = json.dumps(payload)
#print(payload)
resp = requests.post(
databricksURL + endpoint,
data=payload,
headers=header
)
result_data = resp.json()
print (json.dumps(result_data, indent=4))
ジョブの設定
ノートブック右上のスケジュールをクリックして定期実行の設定を行えば、このノートブックがジョブとして実行され、モデルサービングエンドポイントが停止されます。