こちらの続きです。
前回は動かしただけでしたが、せっかくDatabricksで動かしているので、MLflowによるモデルの記録、さらにはモデルサービングまでやってみます。
こちらは、AWS東京リージョンで動作確認しています。
MLflowとは
MLflowはオープンソースのモデルライフサイクルソフトウェアです。Databricksにインテグレーションされているので、transformersモデルをはじめ様々な機械学習モデル、LLMを簡単に記録、管理することができます。
Unity Catalogとは
Unity CatalogはDatabricksにおけるガバナンスソリューションです。データベースやテーブルだけではなく、ファイルや機械学習モデルに対するガバナンス管理を一手に引き受けています。もともと、MLflowにはモデルのバージョン管理のためのモデルレジストリが提供されていましたが、最近ではUnity Catalog配下でモデルを管理ができるようになっています。ここでは、Unity Catalogのモデル管理機能を活用します。
モデルサービングとは
LLMのみならず機械学習の最終的なユースケースの多くはリアルタイム推論です。GUIからLLMを呼び出してチャットbotを構成するというケースは増えています。このような場合、モデルにアクセスするためのREST APIのエンドポイントを構築する必要がありますが、モデルサービングの機能を使うことで容易にREST APIエンドポイントを構築することができます。
google/gemma-2-2b-jpn-itの記録とモデルサービング
ここでの最終目標のモデルサービングにまで到達するには、以下の手順が必要です。
- モデルのダウンロード
- MLflowによるエクスペリメントへのモデルの記録。この際にシグネチャとconda環境を設定
- Unity Catalogへのモデルの登録
- モデルサービングエンドポイントの構築
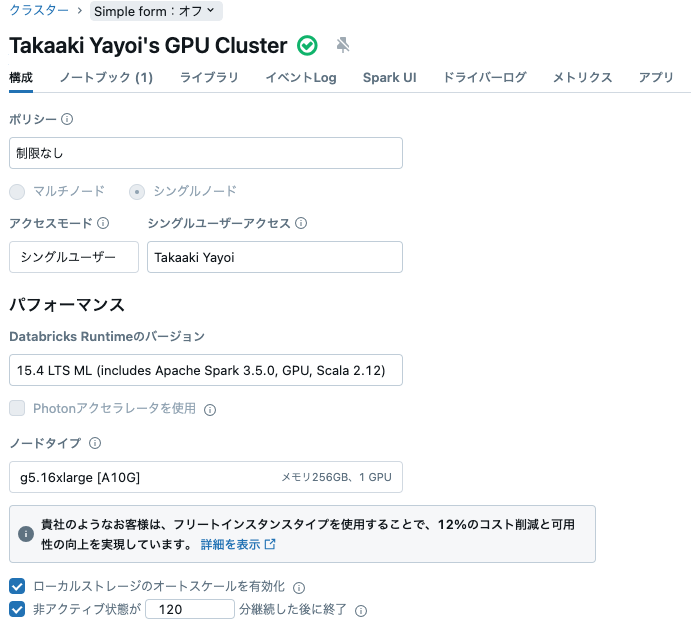
用語の説明を含め、以下で手順をウォークスルーしていきます。クラスターは前回と同じスペックです。
ライブラリのインストール
%pip install -U transformers torch accelerate torchvision
dbutils.library.restartPython()
# login to huggingface
from huggingface_hub import notebook_login
notebook_login()
モデルのダウンロード
import mlflow
import transformers
from mlflow.utils.environment import _mlflow_conda_env
# モデルの登録先をUnity Catalogに
mlflow.set_registry_uri("databricks-uc")
architecture="google/gemma-2-2b-jpn-it"
gemma_pipeline = transformers.pipeline(model=architecture, trust_remote_code=True, device=0) # GPUを使う
conda環境の作成
モデルサービングの環境が適切に構成されるように依存関係を設定します。
# MLflowにはモデルをサービングする際に用いられるconda環境を作成するユーティリティが含まれています。
# 必要な依存関係がconda.yamlに保存され、モデルとともに記録されます。
conda_env = _mlflow_conda_env(
additional_conda_deps=None,
additional_pip_deps=["transformers==4.45.1", "torch==2.4.1", "torchvision==0.19.1", "accelerate==0.34.2"],
additional_conda_channels=None,
)
シグネチャの作成
Unity Catalogにモデルを登録するにはシグネチャ(モデルの入出力のスキーマ)が必須となります。シグネチャの詳細はIntroduction to MLflow and Transformersをご覧ください。
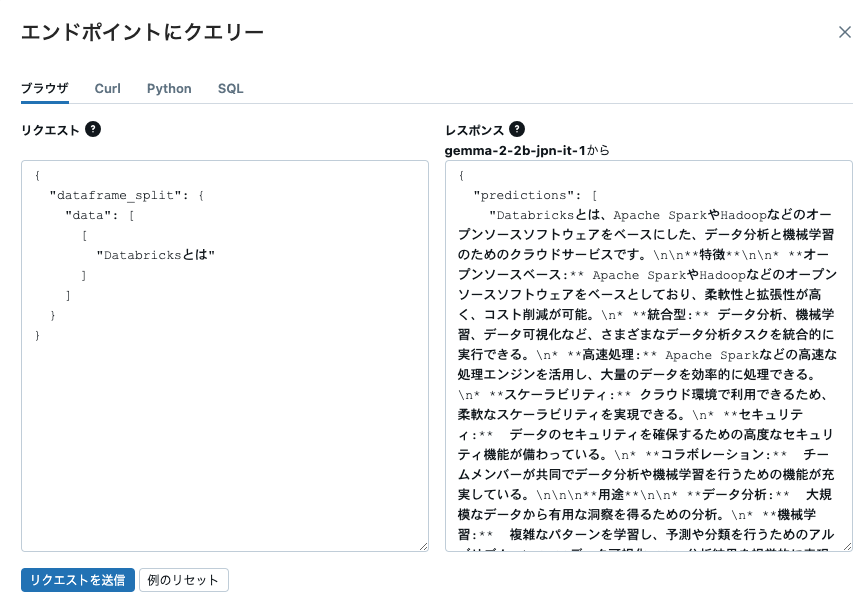
input_example = "Databricksとは"
# 推論時にオプションで上書きするためのパラメータ(およびそのデフォルト値)を定義します。
parameters = {"max_length": 512, "do_sample": True, "temperature": 0.4}
# 推論時の検証と型チェック(推論時に提出されるパラメータの検証も含む)に使用されるモデルのシグネチャを生成します
signature = mlflow.models.infer_signature(
input_example,
mlflow.transformers.generate_signature_output(gemma_pipeline, input_example),
parameters,
)
# シグネチャを可視化します
signature
inputs:
[string (required)]
outputs:
[string (required)]
params:
['max_length': long (default: 512), 'do_sample': boolean (default: True), 'temperature': double (default: 0.4)]
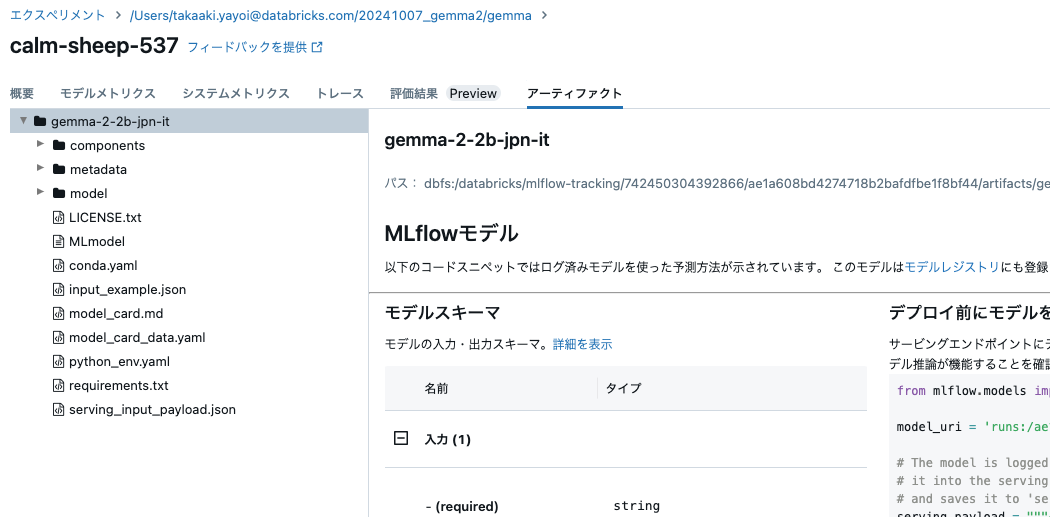
モデルの記録
Unity Catalogにモデルを登録するには、MLflowエクスペリメントに記録する必要があります。まずは、MLflowエクスペリメントにモデルを記録します。
with mlflow.start_run():
model_info = mlflow.transformers.log_model(
transformers_model=gemma_pipeline,
artifact_path="gemma-2-2b-jpn-it",
input_example=input_example,
signature=signature,
conda_env=conda_env,
)
上のmlflow.transformersの詳細に関しては、こちらの記事をご覧ください。
数分でモデルが記録されます。MLflowの用語では個々の記録レコードはMLflowランと呼ばれ、それら複数のランをエクスペリメントという箱で管理することになります。
モデルの登録
モデルをサービングするには、Unity Catalogへのモデルの登録が必要です。
model_name = "takaakiyayoi_catalog.llm_fine_tuning.gemma-2-2b-jpn-it"
mlflow.register_model(
f"runs:/{model_info.run_id}/gemma-2-2b-jpn-it", model_name
)
カタログエクスプローラからモデルを確認できるようになります。
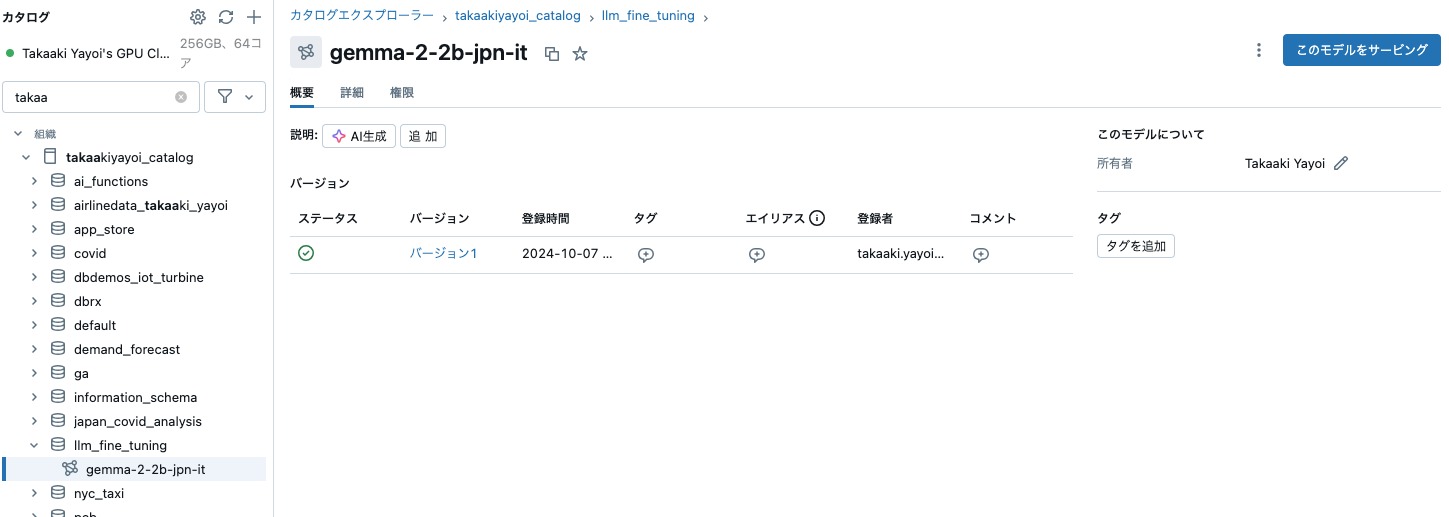
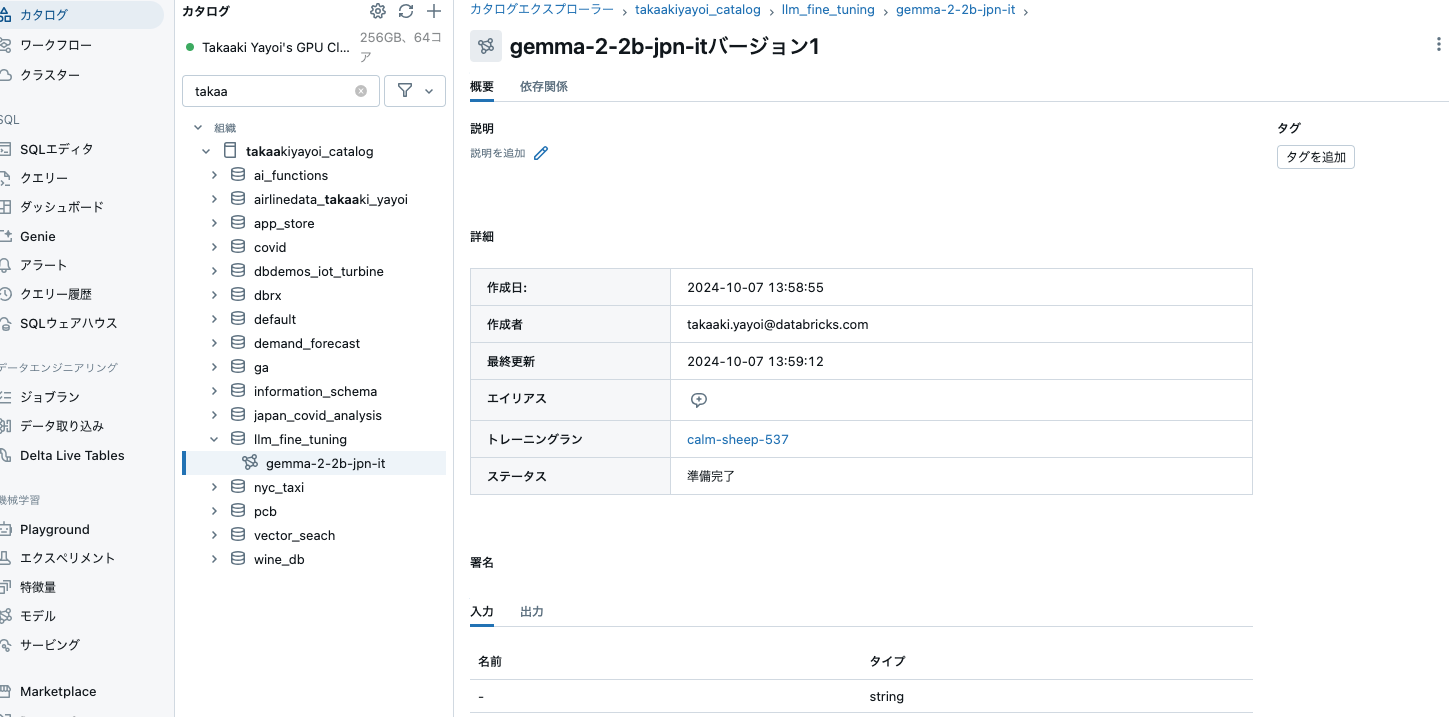
右上のこのモデルをサービングからでも、サービングエンドポイントは作成できるのですが、ここはPythonでやります。
サービングエンドポイントの作成
from mlflow import MlflowClient
def get_latest_model_version(model_name):
mlflow_client = MlflowClient(registry_uri="databricks-uc")
latest_version = 1
for mv in mlflow_client.search_model_versions(f"name='{model_name}'"):
version_int = int(mv.version)
if version_int > latest_version:
latest_version = version_int
return latest_version
# サービングエンドポイントの作成、更新
from databricks.sdk import WorkspaceClient
from databricks.sdk.service.serving import EndpointCoreConfigInput, ServedModelInput, ServedModelInputWorkloadSize, ServedModelInputWorkloadType
host = "https://" + spark.conf.get("spark.databricks.workspaceUrl")
serving_endpoint_name = "taka_gemma_2_endpoint"
latest_model_version = get_latest_model_version(model_name)
w = WorkspaceClient()
endpoint_config = EndpointCoreConfigInput(
name=serving_endpoint_name,
served_models=[
ServedModelInput(
model_name="takaakiyayoi_catalog.llm_fine_tuning.gemma-2-2b-jpn-it",
model_version=latest_model_version,
workload_size=ServedModelInputWorkloadSize.SMALL,
workload_type=ServedModelInputWorkloadType.GPU_MEDIUM,
scale_to_zero_enabled=True,
)
]
)
existing_endpoint = next(
(e for e in w.serving_endpoints.list() if e.name == serving_endpoint_name), None
)
serving_endpoint_url = f"{host}/ml/endpoints/{serving_endpoint_name}"
if existing_endpoint == None:
print(f"Creating the endpoint {serving_endpoint_url}, this will take a few minutes to package and deploy the endpoint...")
w.serving_endpoints.create_and_wait(name=serving_endpoint_name, config=endpoint_config)
else:
print(f"Updating the endpoint {serving_endpoint_url} to version {latest_model_version}, this will take a few minutes to package and deploy the endpoint...")
w.serving_endpoints.update_config_and_wait(served_models=endpoint_config.served_models, name=serving_endpoint_name)
displayHTML(f'Your Model Endpoint Serving is now available. Open the <a href="/ml/endpoints/{serving_endpoint_name}">Model Serving Endpoint page</a> for more details.')
タイムアウトになる場合がありますが、画面上処理が続いていれば問題ありません。
これでモデルがサーブされるようになりました。READYになるまで30-40分かかると思います。
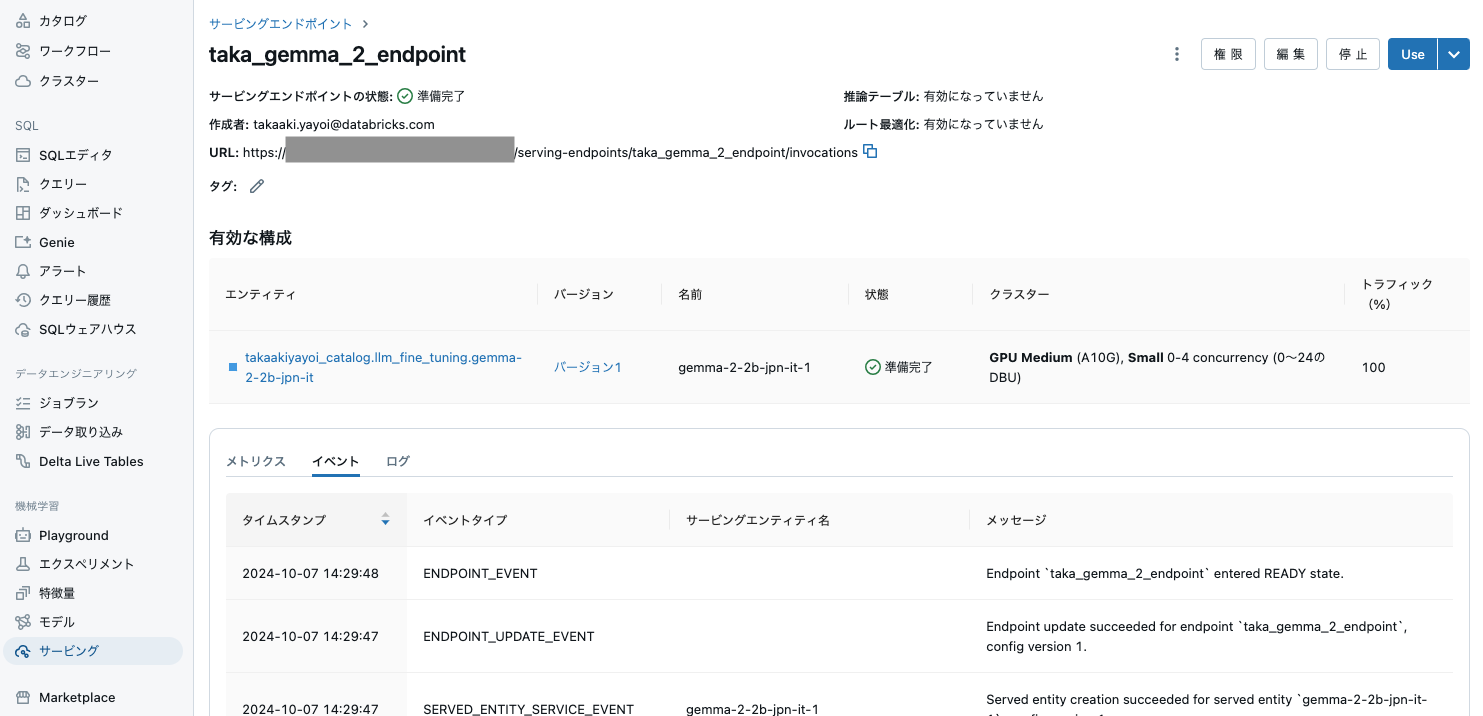
右上のUseをクリックすると、クイックに動作を確認することができます。