こちらで公開されているノートブックをウォークスルーします。変更が生じているデータを生成して、Delta Live Tables(DLT)のチェンジデータキャプチャ(CDC)を用いて後段のテーブルに変更のみを反映させます。
翻訳版はこちらです。パイプラインのノートブックはPython版のみ翻訳しています。
データの準備
CDCの元となるデータをFakerを使って生成します。
Fakerのインストール
%pip install Faker
ダミーデータの生成
from pyspark.sql import functions as F
from faker import Faker
from collections import OrderedDict
import uuid
# データの格納パス: 適宜変更してください
folder = "/tmp/takaaki.yayoi@databricks.com/demo/cdc_raw"
#dbutils.fs.rm(folder, True)
try:
dbutils.fs.ls(folder)
except:
print("フォルダーが存在しません、データを生成中...")
fake = Faker()
fake_firstname = F.udf(fake.first_name)
fake_lastname = F.udf(fake.last_name)
fake_email = F.udf(fake.ascii_company_email)
fake_date = F.udf(lambda:fake.date_time_this_month().strftime("%m-%d-%Y %H:%M:%S"))
fake_address = F.udf(fake.address)
operations = OrderedDict([("APPEND", 0.5),("DELETE", 0.1),("UPDATE", 0.3),(None, 0.01)])
fake_operation = F.udf(lambda:fake.random_elements(elements=operations, length=1)[0])
fake_id = F.udf(lambda: str(uuid.uuid4()))
df = spark.range(0, 100000)
df = df.withColumn("id", fake_id())
df = df.withColumn("firstname", fake_firstname())
df = df.withColumn("lastname", fake_lastname())
df = df.withColumn("email", fake_email())
df = df.withColumn("address", fake_address())
df = df.withColumn("operation", fake_operation())
df = df.withColumn("operation_date", fake_date())
df.repartition(100).write.format("json").mode("overwrite").save(folder+"/customers")
df = spark.range(0, 10000)
df = df.withColumn("id", fake_id())
df = df.withColumn("transaction_date", fake_date())
df = df.withColumn("amount", F.round(F.rand()*1000))
df = df.withColumn("item_count", F.round(F.rand()*10))
df = df.withColumn("operation", fake_operation())
df = df.withColumn("operation_date", fake_date())
# 同じIDが生成された顧客とJoin
df = df.withColumn("t_id", F.monotonically_increasing_id()).join(spark.read.json(folder+"/customers").select("id").withColumnRenamed("id", "customer_id").withColumn("t_id", F.monotonically_increasing_id()), "t_id").drop("t_id")
df.repartition(10).write.format("json").mode("overwrite").save(folder+"/transactions")
データの確認
spark.read.json(folder+"/customers").display()
このように、架空の住所、氏名のデータがoperationのカラムと共に生成されます。これをベースにCDCを行います。

パイプラインの初期設定
ここで、Delta Live Tablesパイプラインで使用するデータベースとファイルパスを初期化しておきます。
-- データベースの作成: パイプラインのターゲットに指定してください
DROP DATABASE IF EXISTS cdc_data_taka CASCADE;
CREATE DATABASE cdc_data_taka;
# DLTパイプラインのストレージの初期化: パイプラインのストレージに指定してください
dbutils.fs.rm("/tmp/takaaki.yayoi@databricks.com/demo/dlt_cdc", True)
CDCパイプラインの実装および実行
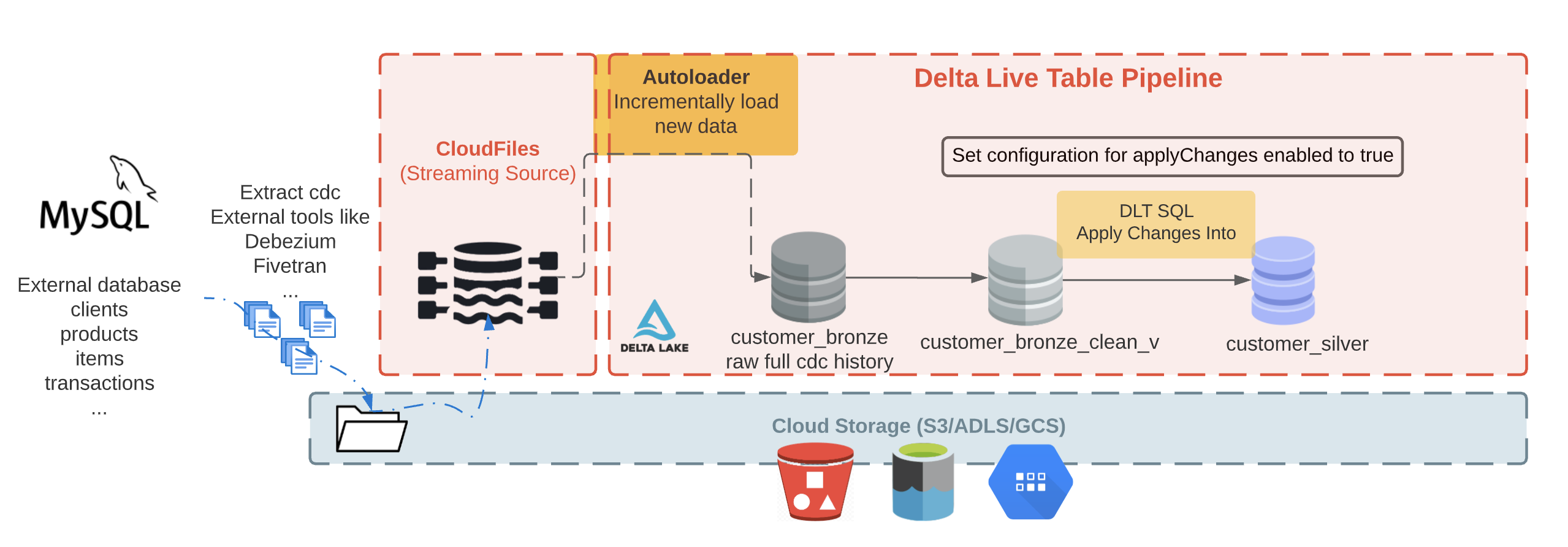
全体フローは以下のようになります。

チェンジデータキャプチャ(CDC)の重要性
チェンジデータキャプチャ(CDC)はデータベースやデータウェハウスのようなデータストレージにおけるレコードの変更をキャプチャするプロセスです。これらの変更は通常、データの削除、追加、更新のようなオペレーションとみなされます。
データベースをエクスポートするデータベースのダンプを取得し、レイクハウス/データウェアハウス/データレイクにインポートするデータレプリケーションはシンプルな方法ですが、これはスケーラブルなアプローチとは言えません。
データベースでなされた変更のみをキャプチャし、これらの変更をターゲットデータベースに適用するのがチェンジデータキャプチャです。CDCはオーバーヘッドを削減し、リアルタイム分析をサポートします。バルクロードによる更新をすることなしに、インクリメンタルなロードを実現します。
CDCのアプローチ
1 - 内製CDCプロセスの開発:
複雑なタスク: CDCのデータレプリケーションは、一度切りの簡単なソリューションではありません。データベースプロバイダーによる差異から、レコードのフォーマットは異なり、ログレコードへのアクセスが不便であることからCDCは困難なものとなります。
定期的なメンテナンス: CDCプロセスのスクリプトの記述は最初の一歩です。上述の変化を定期的にマッピングできるカスタマイズされたソリューションをメンテナンスしなくてはなりません。これには、多くの時間とリソースを必要とします。
過度の負担: 企業の開発者はすでに公式なクエリーの付加に晒されています。カスタムのCDCソリューションを構築する追加の工数は、既存の収益を生み出しているプロジェクトに影響を与えます。
2 - CDCツールの活用: Debezium, Hevo Data, IBM Infosphere, Qlik Replicate, Talend, Oracle GoldenGate, StreamSetsなど
このデモリポジトリでは、CDCツールから到着するCDCデータを活用します。CDCツールはデータベースログを読み込むので、特定カラムを更新する際に開発者を頼る必要がありません。
— DebeziumのようなCDCツールは変更されたすべての行をキャプチャします。Kafkaログにおいて、アプリケーションが利用し始めた以降のデータ変更履歴を記録します。
お使いのSQLデータベースをどのようにレイクハウスに同期するのか?
CDCツール、Auto Loader、DLTパイプラインを用いたCDCフロー:
- CDCツールがデータベースログを読み込み、変更を含むJSONメッセージを生成し、Kafkaに対して変更説明を伴うレコードをストリーミング
- KafkaがINSERT, UPDATE, DELETEオペレーションを含むメッセージをストリーミングし、クラウドオブジェクトストレージ(S3、ADLSなど)に格納
- Auto Loaderを用いてクラウドオブジェクトストレージからメッセージをインクリメンタルにロードし、生のメッセージとして保存するためにブロンズテーブルに格納
- 次に、クレンジングされたブロンズレイヤーテーブルに APPLY CHANGES INTO を実行し、後段のシルバーテーブルに最新の更新データを伝搬
外部データベースからCDCデータを処理するための実装を以下に示します。入力はKafkaのようなメッセージキューを含む任意のフォーマットになり得ることに注意してください。
DebeziumのようなCDCツールの出力はどのようなものか?
変更データを表現するJSONメッセージは、以下の一覧と同じような興味深いフィールドを持っています:
- operation: オペレーションのコード(DELETE, APPEND, UPDATE, CREATE)
- operation_date: それぞれのオペレーションのアクションがあった日付、タイムスタンプ
Debeziumの出力には以下のようなフィールドが含まれます(このデモには含めていません):
- before: 変更前の行
- after: 変更後の行
想定されるフィールドに関しては、こちらのリファレンスをチェックしてみてください。
Auto Loader(cloud_files)を用いたインクリメンタルなデータロード
スキーマの更新によって、外部システムとの連携は困難となり得ます。外部データベースではスキーマの更新やカラムの追加、更新があり、我々のシステムはこれらの変更に対して頑健である必要があります。DatabricksのAuto Loader(cloudFiles)は、すぐにスキーマ推定とスキーマ進化を取り扱うことができます。
Auto Loaderを用いることで、クラウドストレージから数百万のファイルを取り込むことができ、大規模なスキーマ推定や進化をサポートすることができます。このノートブックでは、ストリーミング(とバッチ)データを取り扱うためにAuto Loaderを活用します。
パイプラインを作成し、外部のプロバイダーによってデリバリーされる生のJSONデータを取り込むためにAuto Loaderを使いましょう。
DLT Pythonの構文
関連メソッドを使うには、dlt Pythonモジュールをインポートする必要があります。ここでは、pyspark.sql.functionsもインポートします。
DLTのテーブル、ビュー、関連設定はデコレーターを用いて設定されます。
Pythonのデコレーターを触ったことがない場合には、Pythonスクリプトで次に表現される関数とやり取りを行う、@で始まる関数やクラスであると考えてください。
@dlt.tableデコレーターは、Python関数をDelta Liveテーブルに変換する基本的なメソッドとなります。
以下では到着データを探索していきます。
ブロンズテーブル - Auto Loader & DLT
## ストレージパスから取得する生のJSONデータを含むブロンズテーブルの作成
import dlt
from pyspark.sql.functions import *
from pyspark.sql.types import *
source = spark.conf.get("source")
@dlt.table(name="customer_bronze",
comment = "クラウドオブジェクトストレージのランディングゾーンからインクリメンタルに取り込まれる新規顧客",
table_properties={
"quality": "bronze"
}
)
def customer_bronze():
return (
spark.readStream.format("cloudFiles") \
.option("cloudFiles.format", "json") \
.option("cloudFiles.inferColumnTypes", "true") \
.load(f"{source}/customers")
)
シルバーレイヤー - クレンジングされたテーブル (制約の適用)
@dlt.table(name="customer_bronze_clean",
comment="クレンジングされたブロンズ顧客ビュー(シルバーになるテーブルです)")
@dlt.expect_or_drop("valid_id", "id IS NOT NULL")
@dlt.expect("valid_address", "address IS NOT NULL")
@dlt.expect_or_drop("valid_operation", "operation IS NOT NULL")
def customer_bronze_clean():
return dlt.read_stream("customer_bronze") \
.select("address", "email", "id", "firstname", "lastname", "operation", "operation_date", "_rescued_data")
シルバーテーブルのマテリアライズ
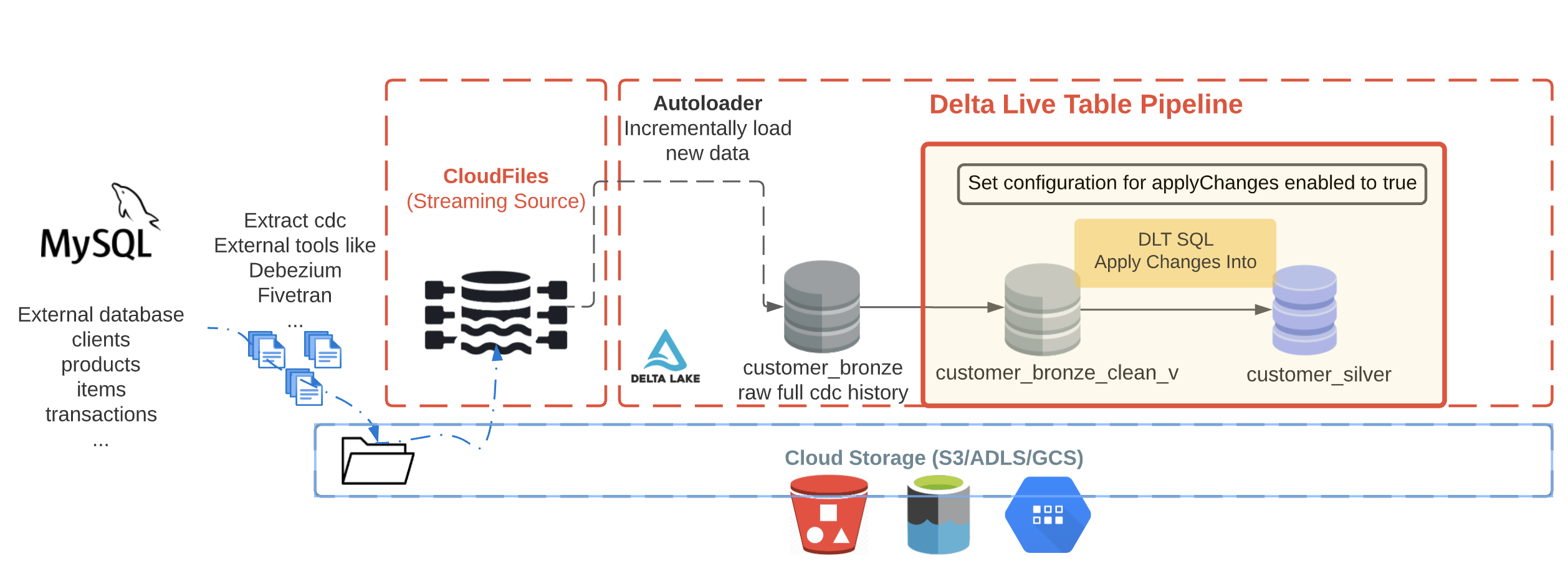
シルバーテーブルであるcustomer_silverには、最新のビューが含まれます。オリジナルテーブルの複製となります。
後段のシルバーレイヤーにApply Changes Intoオペレーションを伝播させるには、DLTパイプライン設定でapplyChanges設定を追加して有効化することで、明示的にこの機能を有効化する必要があります。
不要な顧客レコードの削除 - シルバーテーブル - DLT Python
dlt.create_target_table(name="customer_silver",
comment="クレンジング、マージされた顧客",
table_properties={
"quality": "silver"
}
)
dlt.apply_changes(
target = "customer_silver", # マテリアライズされる顧客テーブル
source = "customer_bronze_clean", # 入力のCDC
keys = ["id"], # upsert/deleteするために行をマッチする際の主キー
sequence_by = col("operation_date"), # 最新の値を取得するためにオペレーション日による重複排除
apply_as_deletes = expr("operation = 'DELETE'"), # DELETEの条件
except_column_list = ["operation", "operation_date", "_rescued_data"] # メタデータカラムの削除
)
パイプラインの作成
- サイドメニューのワークフローにアクセスし、Delta Live Tablesを選択し、パイプラインの作成をクリックします。
-
上のステップで作成したノートブックをノートブックライブラリで指定します。
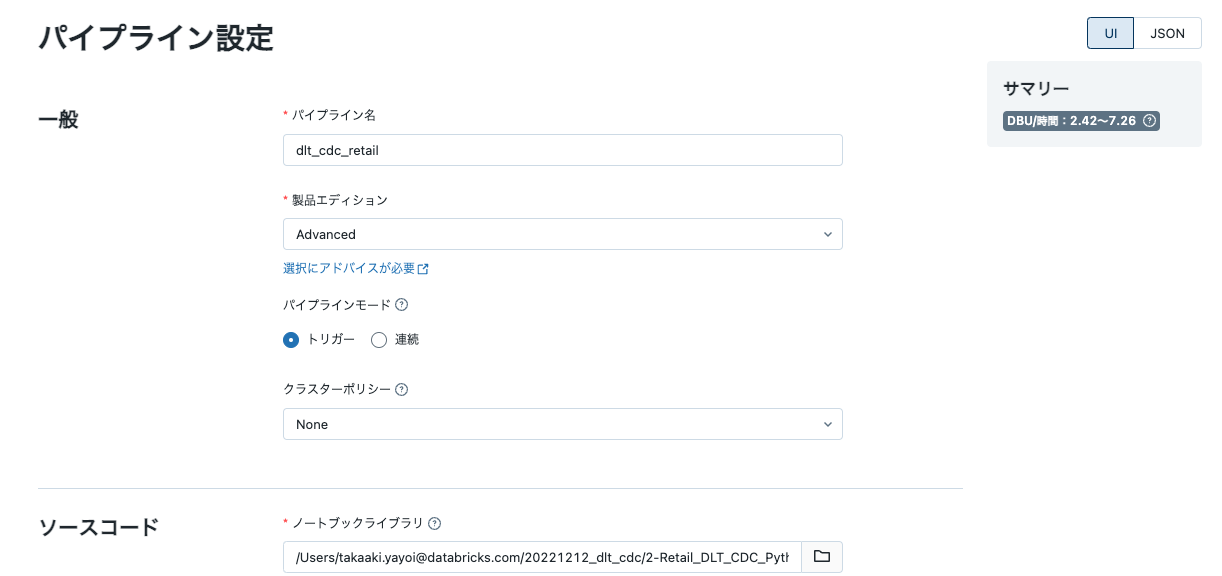
- データの準備で初期化したデータベースをターゲットスキーマ、ファイルパスをストレージの場所に指定します。これらの場所にDLTパイプラインの処理結果が保存されます。
- DLTパイプラインから変数を参照できるようにAdvancedの構成にキーバリューペアを追加します。
sourceにダミーデータの生成で指定したデータ格納パスを指定します。
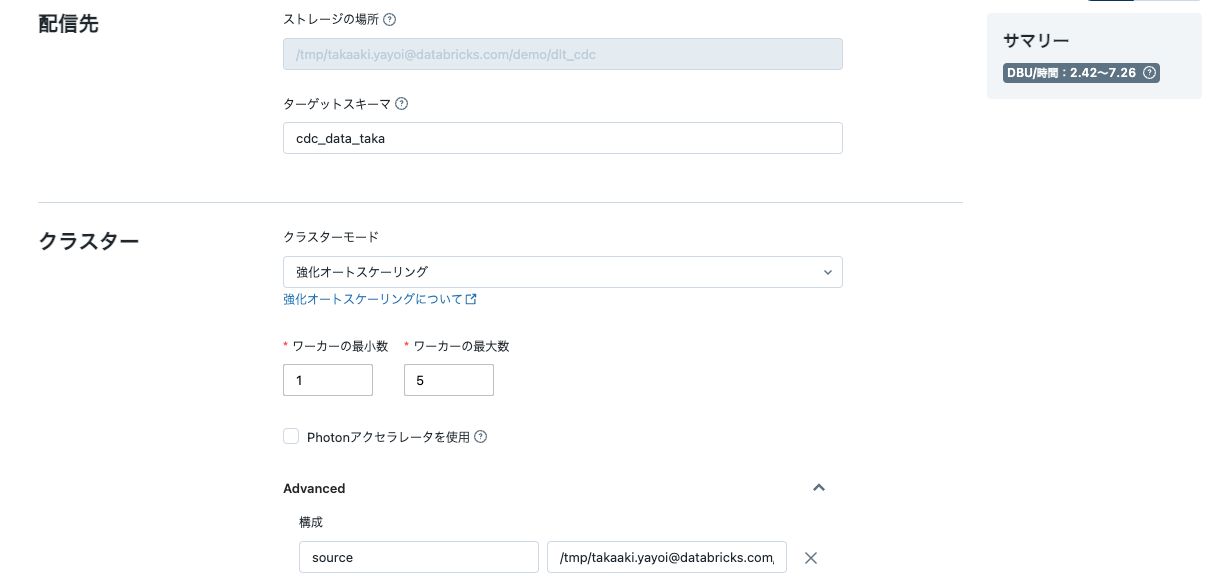
- 作成をクリックします。
今回の設定のJSONを以下に示します。
{
"id": "7c2607ec-47a2-48d9-8572-9e498656b573",
"clusters": [
{
"label": "default",
"autoscale": {
"min_workers": 1,
"max_workers": 5,
"mode": "ENHANCED"
}
}
],
"development": true,
"continuous": false,
"channel": "CURRENT",
"edition": "ADVANCED",
"photon": false,
"libraries": [
{
"notebook": {
"path": "/Users/takaaki.yayoi@databricks.com/20221212_dlt_cdc/2-Retail_DLT_CDC_Python"
}
}
],
"name": "dlt_cdc_retail",
"storage": "/tmp/takaaki.yayoi@databricks.com/demo/dlt_cdc",
"configuration": {
"source": "/tmp/takaaki.yayoi@databricks.com/demo/cdc_raw"
},
"target": "cdc_data_taka"
}
パイプラインの実行
開始をクリックしてパイプラインをスタートさせます。処理が完了するとパイプラインのボックスはすべてグリーンになります。
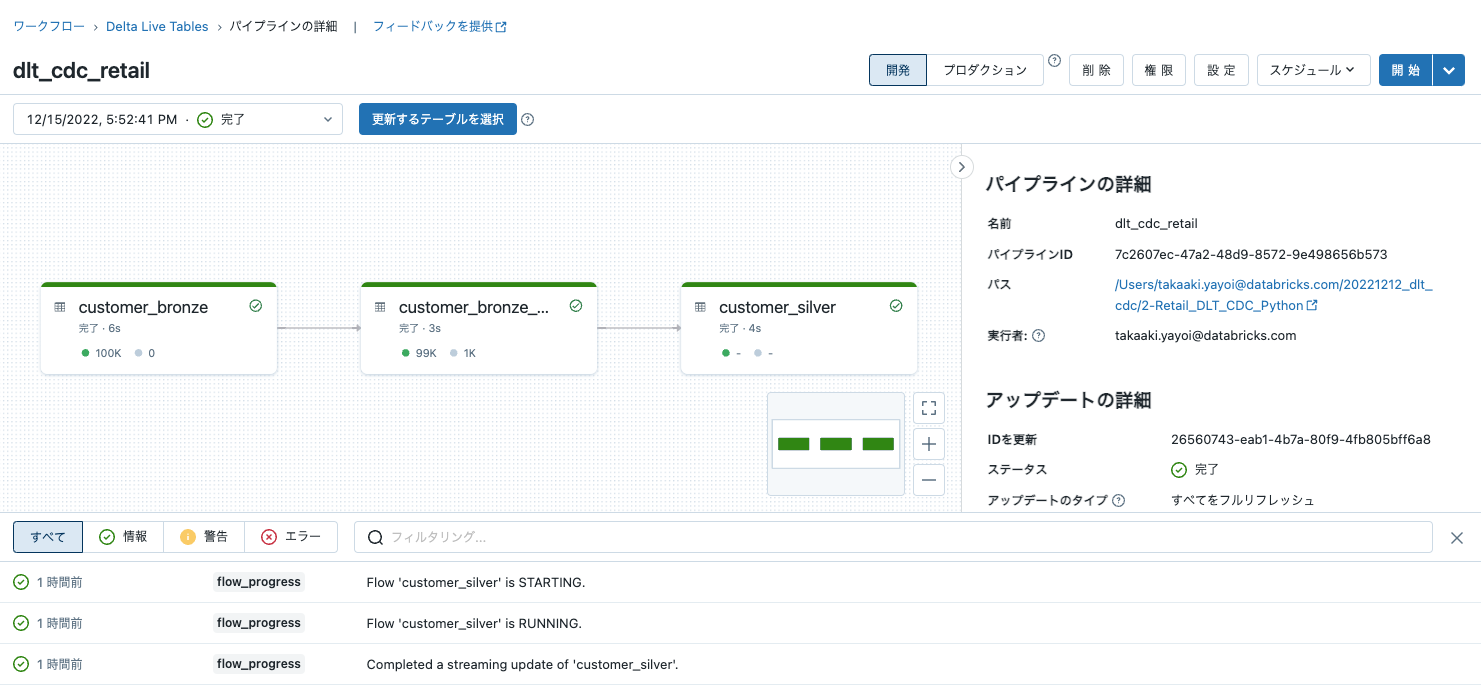
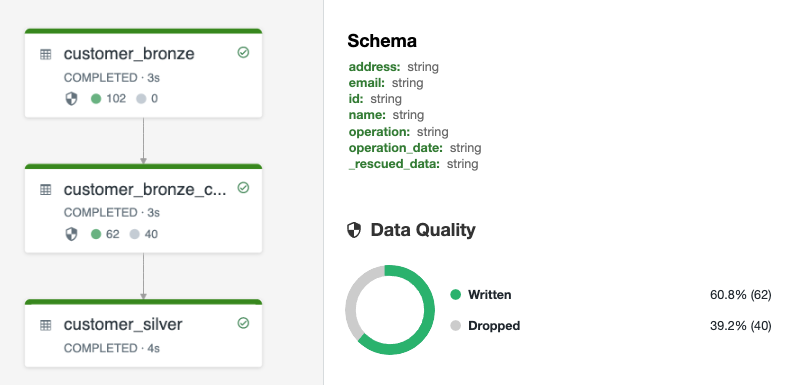
前段のテーブルに格納されていたoperationやoperation_dateに基づいてシルバーテーブルが更新されています。
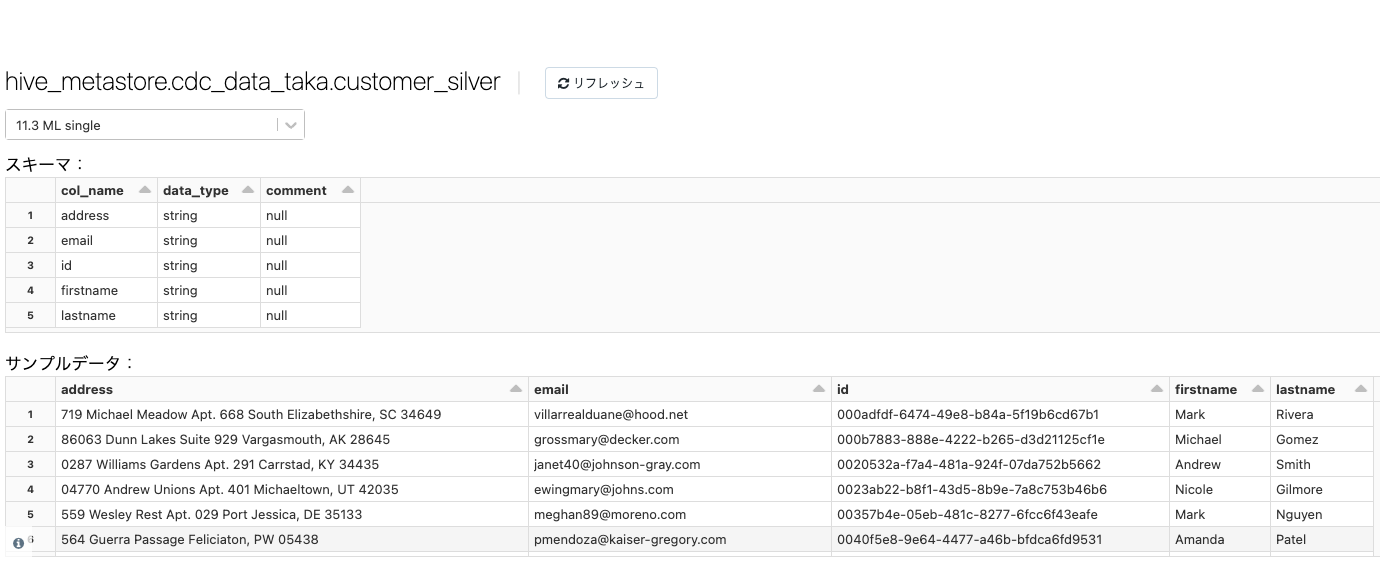
パイプラインを実行したら、イベントログとリネージュデータをモニタリングするために、イベントログを解析します。
イベントログの解析
それぞれのDLTパイプラインは、パイプラインで定義されたストレージロケーションに自身のイベントテーブルを持ちます。このテーブルから、何が起きているのか、パイプラインを通過するデータの品質を確認することができます。
セットアップ
%sql
-- 適宜データベースを指定してください
CREATE TABLE IF NOT EXISTS cdc_data_taka.demo_cdc_dlt_system_event_log_raw using delta LOCATION '$storage_path/system/events';
select * from cdc_data_taka.demo_cdc_dlt_system_event_log_raw;
Delta Live Tablesのエクスペクテーション分析
Delta Live Tablesはエクスペクテーションを通じてデータ品質を追跡します。これらのエクスペクテーションはDLTのログイベントとともに技術的なテーブルとして格納されます。この情報を分析するために、シンプルにビューを作成することができます。
1 - イベントログの分析
detailsカラムにはイベントログに送信されたイベントごとのメタデータが含まれています。イベントのタイプに応じてフィールドが異なります。行く疲れの例を示します:
| イベントのタイプ | 挙動 |
|---|---|
user_action |
パイプラインの作成のようなアクションが行われた際に生じるイベント |
flow_definition |
パイプラインのデプロイメントやアップデートが行われた際に生じるイベントであり、リネージュ、スキーマ、実行計画情報を持ちます |
output_dataset と input_datasets
|
出力のテーブル/ビュー、前段のテーブル/ビュー |
flow_type |
コンプリートフローか追加のフローか |
explain_text |
Sparkの実行計画 |
flow_progress |
データフローがデータバッチの処理を開始あるいは完了した際に生じるイベント |
metrics |
現在はnum_output_rowsが含まれています |
data_quality (dropped_records), (expectations: name, dataset, passed_records, failed_records) |
この特定のデータセットに対するデータ品質ルールの結果の配列が含まれます * expectations
|
イベントログ - タイムスタンプで並び替えられた生のイベント
-- 適宜データベースを指定してください
SELECT
id,
timestamp,
sequence,
event_type,
message,
level,
details
FROM cdc_data_taka.demo_cdc_dlt_system_event_log_raw
ORDER BY timestamp ASC

2 - DLTのリネージュ
%sql
-- タイプと最新の変更ごとに出力データセットを一覧します
-- 適宜データベースを指定してください
create or replace temp view cdc_dlt_expectations as (
SELECT
id,
timestamp,
details:flow_progress.metrics.num_output_rows as output_records,
details:flow_progress.data_quality.dropped_records,
details:flow_progress.status as status_update,
explode(from_json(details:flow_progress.data_quality.expectations
,'array<struct<dataset: string, failed_records: bigint, name: string, passed_records: bigint>>')) expectations
FROM cdc_data_taka.demo_cdc_dlt_system_event_log_raw
where details:flow_progress.data_quality.expectations is not null
ORDER BY timestamp);
select * from cdc_dlt_expectations

%sql
----------------------------------------------------------------------------------------
-- リネージュ
----------------------------------------------------------------------------------------
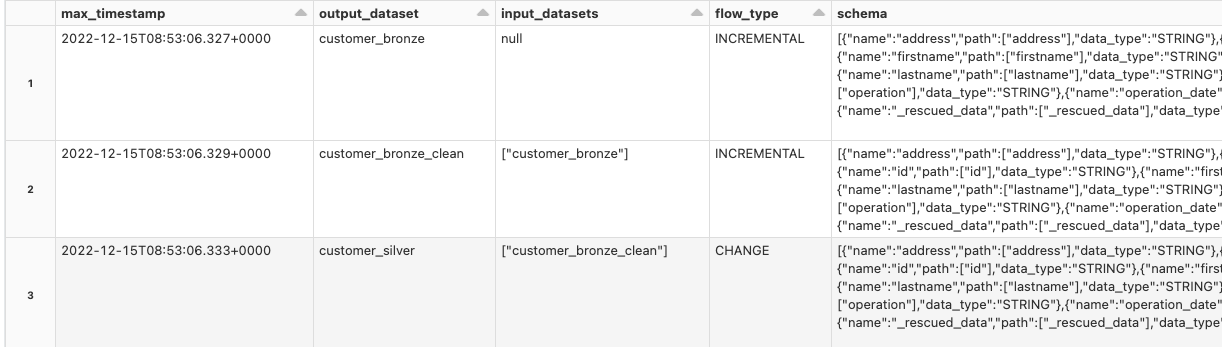
SELECT max_timestamp,
details:flow_definition.output_dataset,
details:flow_definition.input_datasets,
details:flow_definition.flow_type,
details:flow_definition.schema,
details:flow_definition.explain_text,
details:flow_definition
FROM cdc_data_taka.demo_cdc_dlt_system_event_log_raw e
INNER JOIN (
SELECT details:flow_definition.output_dataset output_dataset,
MAX(timestamp) max_timestamp
FROM cdc_data_taka.demo_cdc_dlt_system_event_log_raw
WHERE details:flow_definition.output_dataset IS NOT NULL
GROUP BY details:flow_definition.output_dataset
) m
WHERE e.timestamp = m.max_timestamp
AND e.details:flow_definition.output_dataset = m.output_dataset
-- AND e.details:flow_definition IS NOT NULL
ORDER BY e.details:flow_definition.output_dataset
;
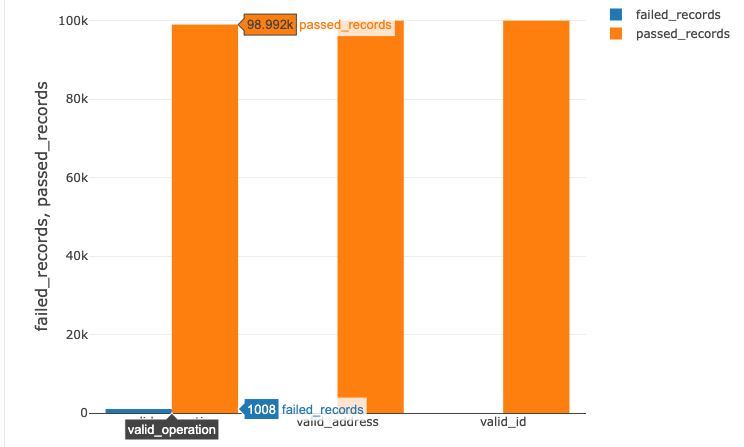
3 - 品質メトリクス
%sql
select sum(expectations.failed_records) as failed_records,
sum(expectations.passed_records) as passed_records,
expectations.name
from cdc_dlt_expectations
group by expectations.name
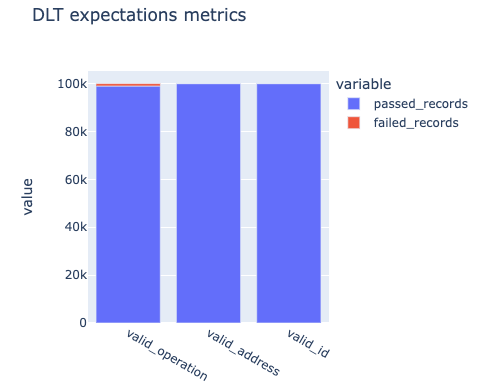
4 - ビジネス集計情報のチェック
%python
import plotly.express as px
expectations_metrics = spark.sql("""select sum(expectations.failed_records) as failed_records,
sum(expectations.passed_records) as passed_records,
expectations.name
from cdc_dlt_expectations
group by expectations.name""").toPandas()
px.bar(expectations_metrics, x="name", y=["passed_records", "failed_records"], title="DLT expectations metrics")
まとめ
Delta Live Tablesを用いることで、変更分のみを後段のテーブルに伝搬させるチェンジデータキャプチャを簡単に活用することができるようになります。そして、イベントログのデータを活用することで、パイプラインの処理状況のモニタリングを行うこともでき、データパイプラインの品質を保ちつつも多様な処理を行うパイプラインを構築できるようになります。是非、DLTでCDCを試してください!