Use dbt in a Databricks job | Databricks on AWS [2022/9/1時点]の翻訳です。
本書は抄訳であり内容の正確性を保証するものではありません。正確な内容に関しては原文を参照ください。
プレビュー
本機能はパブリックプレビューです。
Databricksジョブのタスクとしてdbt Coreのプロジェクトを実行することができます。ジョブのタスクとしてdbt Coreプロジェクトを実行することで、以下のDatabricksジョブクラスターのメリットを享受することができます。
- dbtタスクを自動化し、dbtタスクを含むワークフローをスケジュールします。
- dbtの変換処理を監視し、変換処理のステータスに基づいて通知を送信します。
- 他のタスクを含むワークフローにdbtプロジェクトを取り込みます。例えば、Auto Loaderを用いてデータを取り込み、dbtを用いてデータを変換し、ノートブックタスクでデータを分析するワークフローを構築することができます。
- ログ、結果、マニフェスト、設定を含むジョブ実行から得られるアーティファクトを自動でアーカイブします。
dbtコアに関しては、dbt documentationをご覧ください。
Databricksでは、AWSリージョンeu-west-1、ap-southeast-2、us-east-1、us-west-2でdbtタスクをサポートしています。Supported Databricks clouds and regionsをご覧ください。
ワークフローの開発と本格運用
DatabricksのSQLウェアハウスを用いてdbtプロジェクトを開発することをお勧めします。DatabricksのSQLウェアハウスを用いることで、dbtによって生成されたSQLをテストし、dbtによって生成されたクエリーをデバッグするためにSQLウェアハウスのクエリー履歴を活用することができます。お使いの開発環境でdbtプロジェクトを作成するためのdbt Coreやdbt-databricksパッケージの使い方に関しては、Connect to dbt Coreをご覧ください。
プロダクション環境でdbtの変換処理を実行する際には、Databricksジョブのdbtタスクを用いることをお勧めします。デフォルトでは、dbtタスクはシングルノードのジョブクラスター上のdbt Pythonプロセスで実行され、dbtが生成したSQLは選択されたSQLウェアハウスで実行されます。
dbtの変換処理をサーバレスSQLウェアハウス、all-purposeクラスター、その他のdbtがサポートされるウェアハウスで実行することができます。本書では最初の2つの選択肢をサンプルとともに説明します。
注意
SQLウェアハウスでdbtモデルを開発し、プロダクション環境のall-purposeクラスターで実行すると、パフォーマンスとサポート言語の点で若干の差異を体験することになります。all-purposeクラスターにしてもSQLウェアハウスにしても、同じDatabricksランタイムを使用することをお勧めします。
要件
- Databricksジョブでdbtプロジェクトを使用する際、Databricks ReposによるGit連携をセットアップする必要があります。DBFSからdbtプロジェクトを実行することはできません。
- サーバレスSQLウェアハウスを有効化する必要があります。
- Databricks SQLの資格を有している必要があります。
dbt-sparkパッケージではなくdbt-databricksパッケージを使うことをお薦めします。dbt-databricksパッケージは、Databricksに最適化されたdbt-sparkのforkです。
最初のdbtジョブを作成し実行する
以下の例では、コアのdbtのコンセプトをデモンストレーションするサンプルプロジェクトであるjaffle_shopプロジェクトを使用します。jaffle shopプロジェクトを実行するジョブを作成するには、以下のステップを実行します。
-
Databricksランディングページに移動し、以下のいずれかを行います。
- サイドバーの
 Workflowsをクリックし、
Workflowsをクリックし、 をクリックします。
をクリックします。 - サイドバーで
 Createをクリックし、メニューからJobを選択します。
Createをクリックし、メニューからJobを選択します。
- サイドバーの
-
Tasksタブに表示されるタスクダイアログボックスで、Add a name for your job… をジョブの名前で書き換えます。
-
Task nameにタスク名を入力します。
-
Typeでdbtタスクタイプを選択します。
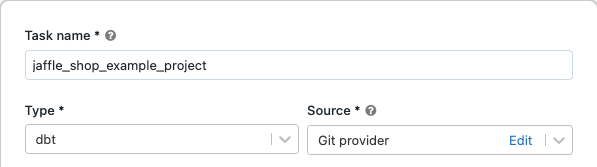
-
SourceでEditをクリックし、jaffle shop GitHubリポジトリの詳細を入力します。
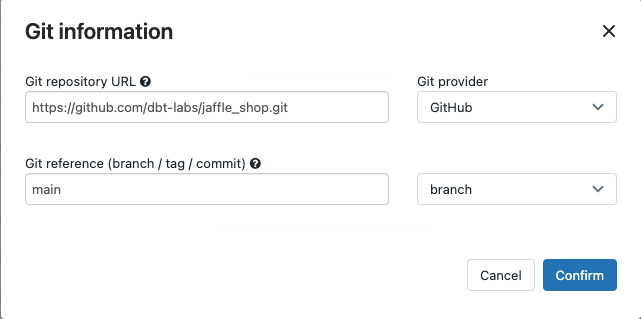
- Git repository URLでjaffle shopプロジェクトのURLを入力します。
-
Git reference (branch / tag / commit) で
mainを入力します。タグやSHAを使うこともできます。
-
Confirmをクリックします。
-
dbt commandsテキストボックスで、実行するdbtコマンド(deps, seed, run)を指定します。コマンドは指定された順序で実行されます。

-
Data warehouseで、dbtによって生成されるSQLを実行するSQLウェアハウスを選択します。Data warehouseドロップダウンメニューにはサーバレスSQLウェアハウスのみが表示されます。
-
(オプション)タスク出力のスキーマ(データベース)を指定することができます。デフォルトでは、スキーマ
defaultが使用されます。 -
(オプション)dbt Coreが実行されるクラスターを変更したい場合、dbt CLI clusterをクリックします。コストを最小化するために、クラスターのデフォルトは小規模かつシングルノードのクラスターとなります。
-
(オプション)タスクのdbt-databricksバージョンを指定することができます。例えば、開発用やプロダクションのdbtタスクを特定のバージョンに固定することができます。
-
Dependent librariesの下で、現在のdbt-databricksバージョンの隣の
 をクリックします。
をクリックします。 - Addをクリックします。
-
Add dependent libraryで、PyPIタブをクリックし、Packageテキストボックスでdbt-packageバージョンを入力します(
dbt-databricks==1.2.0など)。 -
Addをクリックします。

注意
開発と実運用では同じバージョンとなるように、dbtタスクでdbt-databricksのバージョンを固定することをお勧めします。バージョン1.2.0以降のdbt-databricksパッケージを使用することをお勧めします。 -
Dependent librariesの下で、現在のdbt-databricksバージョンの隣の
-
Createをクリックします。
-
すぐにジョブを実行するには、
 をクリックします。
をクリックします。
dbtジョブタスクの結果を参照する
ジョブが完了すると、ノートブックあるいはDatabricksウェハウスでクエリーを実行することによって、SQLクエリーを実行することで結果をテストすることができます。例えば、以下のサンプルクエリーをご覧ください。
SHOW tables IN <schema>;
SELECT * from <schema>.customers LIMIT 10;
<schema>をタスクの設定で指定したスキーマ名で置き換えてください。
APIサンプル
また、dbtタスクを含むジョブを作成、管理するためにJobs API 2.1を使用することができます。以下の例では、単一のdbtタスクを含むジョブを作成しています。
{
"name": "jaffle_shop dbt job",
"max_concurrent_runs": 1,
"git_source": {
"git_url": "https://github.com/dbt-labs/jaffle_shop",
"git_provider": "gitHub",
"git_branch": "main"
},
"job_clusters": [
{
"job_cluster_key": "dbt_CLI",
"new_cluster": {
"spark_version": "10.4.x-photon-scala2.12",
"node_type_id": "i3.xlarge",
"num_workers": 0,
"spark_conf": {
"spark.master": "local[*, 4]",
"spark.databricks.cluster.profile": "singleNode"
},
"custom_tags": {
"ResourceClass": "SingleNode"
}
}
}
],
"tasks": [
{
"task_key": "transform",
"job_cluster_key": "dbt_CLI",
"dbt_task": {
"commands": [
"dbt deps",
"dbt seed",
"dbt run"
],
"warehouse_id": "1a234b567c8de912"
},
"libraries": [
{
"pypi": {
"package": "dbt-databricks>=1.0.0,<2.0.0"
}
}
]
}
]
}
(上級)all-purposeクラスターを用いてdbtによって生成されたSQLを実行する
all-purposeクラスターでdbtタスクを実行するには、接続するクラスターを定義するカスタムのprofiles.ymlを使用します。all-purposeクラスターでjaffle shopプロジェクトを実行するジョブを作成するには、以下のステップを実行します。
-
jaffle_shopリポジトリのforkを作成します。
-
フォークしたリポジトリをデスクトップにコピーします。例えば、以下のようなコマンドを実行します。
Bashgit clone https://github.com/<username>/jaffle_shop.git<username>をあなたのGithubのハンドル名で置き換えてください。 -
jaffle_shopディレクトリに以下のコンテンツを含むprofiles.ymlを作成します。YAMLjaffle_shop: target: databricks_job outputs: databricks_job: type: databricks method: http schema: "<schema>" host: "<http_host>" http_path: "<http_path>/<cluster_id>" token: "{{ env_var('DBT_ACCESS_TOKEN') }}"-
<schema>をプロジェクトのテーブルのスキーマ名で置き換えます。 -
<http_host>を、お使いのSQLウェアハウスのConnection DetailsのServer Hostnameの値で置き換えます。 -
<http_path>を、お使いのSQLウェアハウスのConnection DetailsのHTTP Pathの値で置き換えます。 -
<cluster_id>を接続するクラスターのIDで置き換えます。
このファイルはソースコントロールにチェックインするので、アクセストークンのようなシークレットを指定しないでください。代わりに、このファイルは実行時に動的に認証情報を挿入するdbtのテンプレート機能を使用します。
-
-
Data warehouseでNone (Manual) を選択します。
-
Profiles Directoryでは、
profiles.ymlファイルを格納するディレクトリへの相対パスを入力します。デフォルトのリポジトリルートを使用する場合にはブランクのままとします。 -
このファイルをGitにチェックインし、フォークしたリポジトリにプッシュします。例えば、以下のようなコマンドを実行します。
Bashgit add profiles.yml git commit -m "adding profiles.yml for my Databricks job" git push -
Databricks UIのサイドバーの
Workflowsをクリックします。 -
dbtジョブを選択し、Tasksタブをクリックします。
-
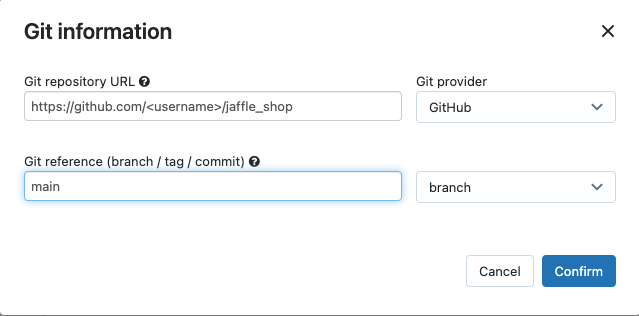
SourceでEditをクリックし、フォークしたjaffle shop GitHubリポジトリの詳細を入力します。
-
Data warehouseでNone (Manual) を選択します。
-
Profiles Directoryでは、
profiles.ymlファイルを格納するディレクトリへの相対パスを入力します。デフォルトのリポジトリルートを使用する場合にはブランクのままとします。
エラーとトラブルシューティング
プロファイルのファイルが存在しないというエラー
エラーメッセージ
dbt looked for a profiles.yml file in /tmp/.../profiles.yml, but did not find one.
可能性のある原因
指定された$PATHにprofiles.ymlファイルが見つかりませんでした。dbtプロジェクトのルートにprofiles.ymlファイルがあることを確認してください。