Introducing Apache Spark™ 3.3 for Databricks Runtime 11.0 - The Databricks Blogの翻訳です。
本書は抄訳であり内容の正確性を保証するものではありません。正確な内容に関しては原文を参照ください。
本日(2022/6/15)、Databricksランタイム 11.0の一部としてDatabricksでApache Spark™ 3.3を利用できるようになったことを発表できて嬉しく思います。Spark 3.3のリリースにおいて多大なる貢献をしたApache Sparkコミュニティに感謝の意を表します。
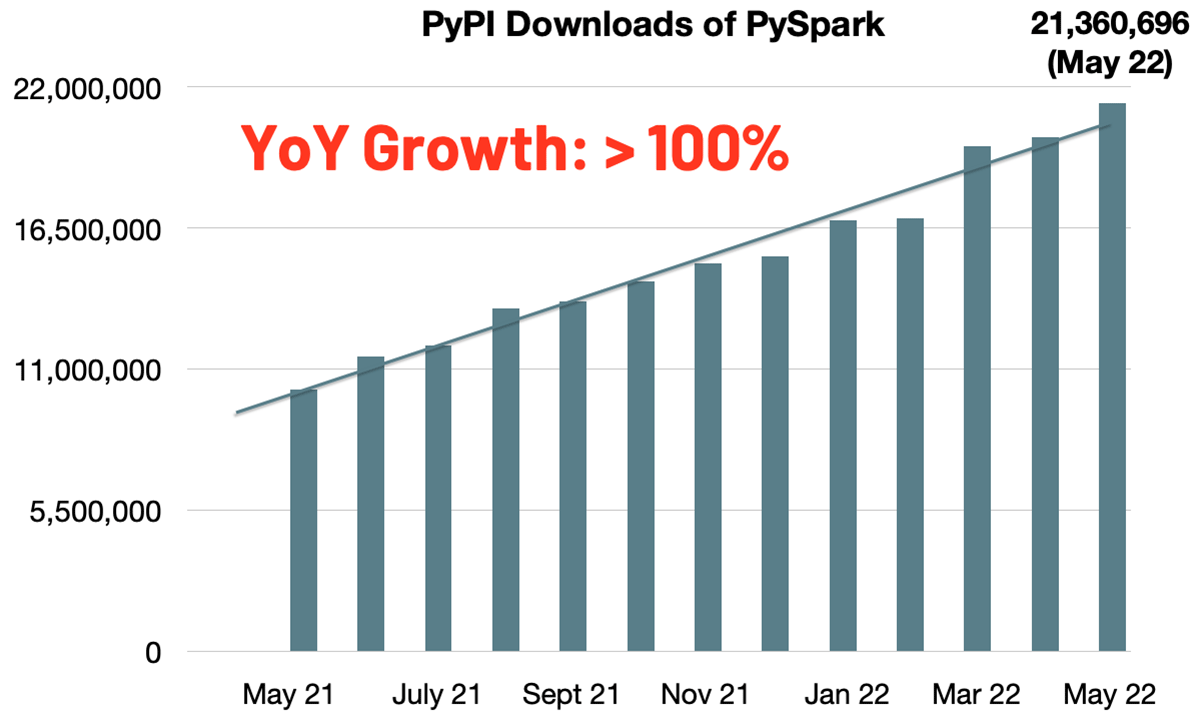
PySparkのPyPIでの月間ダウンロード数は急激に増加して2100万となり、今やPythonは最も人気のあるAPI言語となっています。今年の年度増加率は、昨年時点のPySparkの月間ダウンロードの倍増を示しています。また、Mavenの月間ダウンロード数は2400万を超えました。Sparkはスケーラブルな計算処理において最も広く使われるエンジンとなりました。
Sparkをさらに統合し、シンプルかつ高速、スケーラブルにするというゴールを追求し続けることで、以下の機能を用いてSpark 3.3はそのスコープを拡大しています。
- 最大10倍のスピードアップによるBloomフィルターを通じたjoinクエリー性能の改善
- datetime.timedeltaやmerge_asofのような人気のあるPandasの機能のサポートによるPandas APIカバレッジの増加
- ANSI準拠を改善し、数多くのビルトイン関数をサポートすることで、従来のデータウェアハウスからの移行をシンプルに
- 改善されたエラーハンドリング、オートコンプリート、パフォーマンス、プロファイリングによる開発生産性のブースト
パフォーマンスの改善
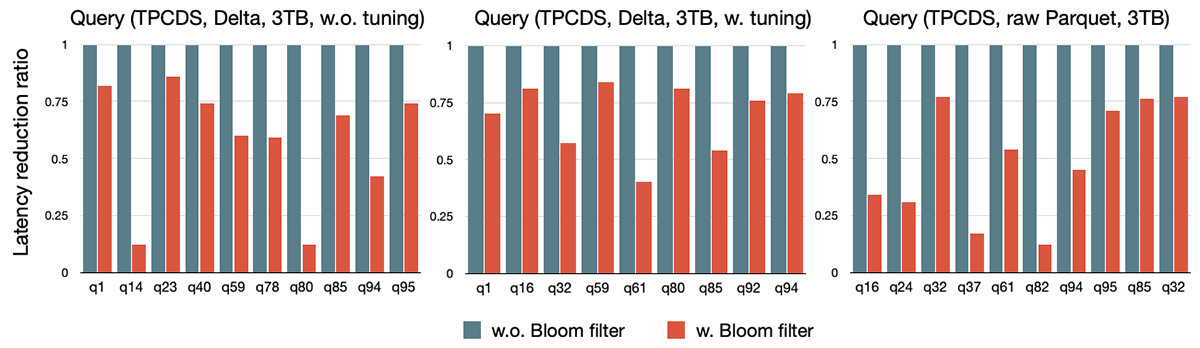
Bloomフィルターjoin(SPARK-32268): Sparkはシャッフルの中間データサイズと計算量を削減するために、初期段階でデータをフィルタリングできるように、適切な際にはクエリープランにBloomフィルターを注入し、プッシュダウンすることができます。Bloomフィルターは、動的ファルスキッピングが十分に適用できない場合に、動的パーティションプルーニング(刈り込み)(DPP)と動的ファイルプルーニング(DFP)を補完するために設計された行レベルの実行時フィルターです。以下のグラフに示すように、3つの異なるバリエーションのデータソース(チューニングなしのDelta Lake、チューニングしたDelta Lake、生のParquetファイル)に対してTPC-DSベンチマークを行い、このBloomフィルターの機能を有効化することで最大10倍のスピードアップを観測しました。パフォーマンス改善の割合は、チューニング前のDelta Lakeデータソースや生のParquetファイルベースのデータソースのように、ストレージのチューニングや正確な統計情報がない場合に顕著になります。このような場合、Bloomフィルターはストレージ/統計情報のチューニングに関係なくより堅牢なクエリーパフォーマンスを実現します。
クエリー実行のエンハンスメント: このリリースではAdaptive Query Execution(AQE)に幾つかの改善が加えられました。
- 集計/Unionを通じた中間の空のリレーションの伝播(SPARK-35442)
- 通常あるいはAQEオプティ魔座における1行のクエリープランの最適化(SPARK-38162)
- AQEにおける制限排除のサポート(SPARK-36424)
Whole-stage codegenのカバレッジが以下のように複数の領域で改善されます。
- Full outer merge join (SPARK-35352、20%~30%のスピードアップ)
- Full outer shuffled hash join (SPARK-32567、10%~20%のスピードアップ)
- Existence sort merge join (SPARK-37316)
- グルーピングキーなしのSort aggregate (SPARK-37564)
Parquetの複雑なデータタイプ(SPARK-34863): この改善では、 list、map、arrayのような複雑なタイプに対してSparkのベクトル化Parquetリーダーのサポートが追加されます。micro-benchmarksが示すように、Sparkではstructのフィールドをスキャンする際に最大15倍の性能改善を達成しており、struct、mapタイプの要素から構成されるarrayを読み込む際には最大1.5倍の性能改善が認められています。
Pandasをスケールさせる
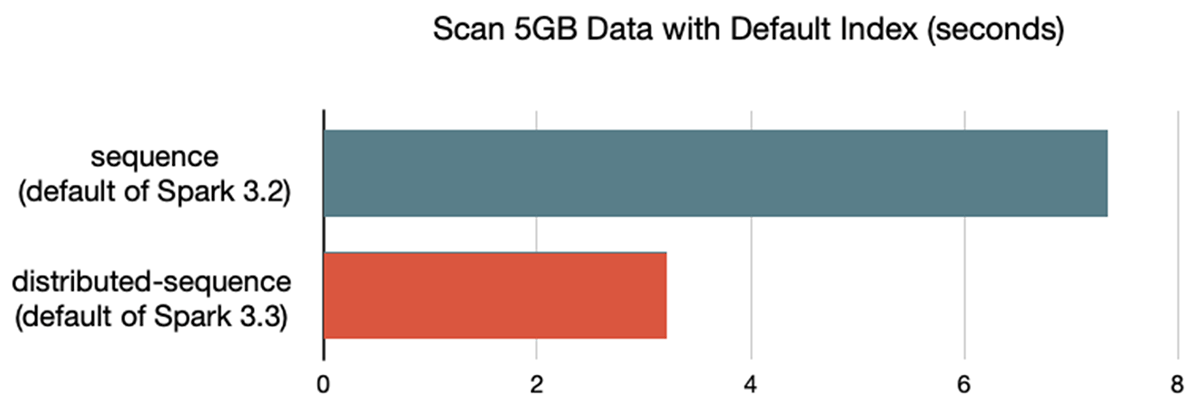
最適化されたデフォルトインデックス: このリリースでは、Pandas API on Spark(SPARK-37649)において、デフォルトのインデックスをsequenceからdistributed-sequenceに切り替えており、後者においてはCatalyst Optimizerによる最適化との親和性が高くなります。Pandas API on Sparkのデフォルトインデックスによるデータのスキャンは、i3.xlargeの5ノードのクラスターのベンチマークにおいて2倍高速になりました。
Pandas APIのカバレッジ: 今ではPySparkはネイティブでdatetime.timedeltaを理解することができます(SPARK-37275、SPARK-37525)。今では、このPython型はSpark SQLのdate-time interval型にマッピングされます。また、このリリースで、これまでPandas API on Sparkに欠けていたパラメーターや新たなAPIの機能がサポートされます。例としては、ps.merge_asof(SPARK-36813)、ps.timedelta_range(SPARK-37673)、ps.to_timedelta(SPARK-37701)のようなエンドポイントが挙げられます。
移行をシンプルに
ANSIのエンハンスメント: このリリースでは、ANSIのintervalデータタイプのサポートを完全なものとします(SPARK-27790)。今では、テーブルに対してintervalを読み書きし、集計や比較を含む日付/時間の計算処理を行うために多くの関数/オペレーターでintervalを使うことができます。ANSIモードでの明示的なキャストは、データの損失を防ぎつつも、タイプ間の安全なキャストをサポートします。try_addやtry_multiplyのようなtry関数のライブラリで追加されている関数において補完的なANSIモードにおいては、ユーザーはANSIモードの安全性を享受しつつも、耐障害性のあるクエリーを維持することができます。
ビルトインの関数: try_*関数以外にも(SPARK-35161)、このリリースでは、新たな9つの線形回帰関数や統計関数、4つの文字列処理関数、aes_encryptionと復号化関数、一般的なfloor、ceiling関数、"to_number"フォーマットなどが含まれています。
生産性をブーストする
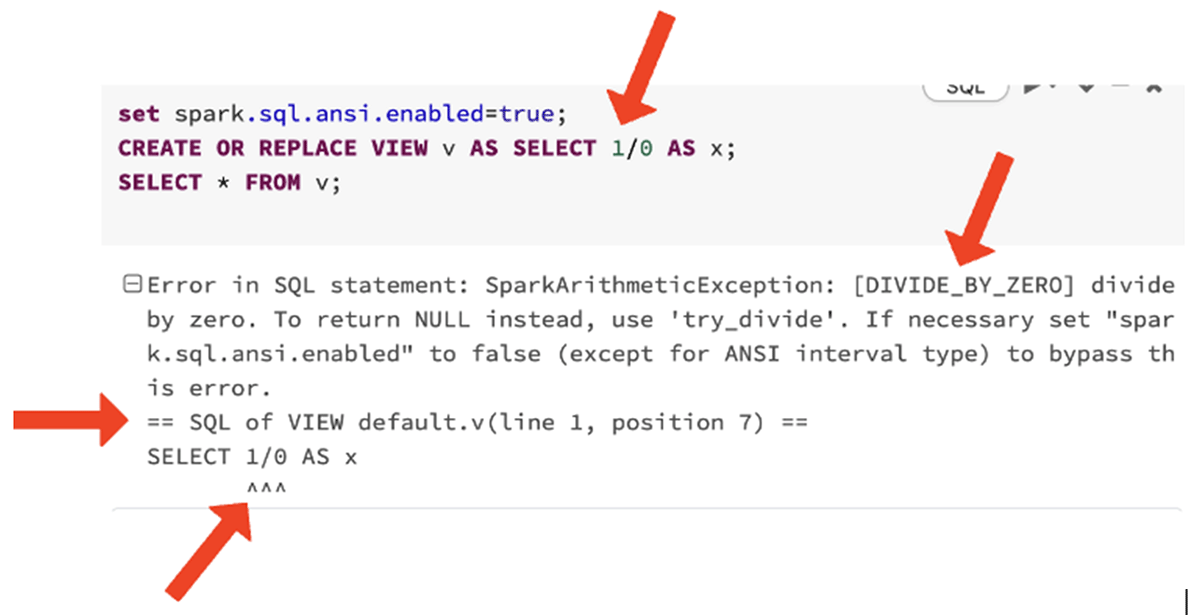
エラーメッセージの改善: このリリースでは、DIVIDE_BY_ZEROのような明示的なエラークラスの導入をユーザーが確認できる旅をスタートしました。これによって、より多くの文脈を踏まえて、正式なドキュメントを含むオンラインの情報を検索することが容易になります。
今では、Sparkが返却する多くの実行時エラーには、特定のネスト化された参照内容における行番号、列番号のように、どこでエラーが発生したのかがわかるように正確な文脈を返却します。
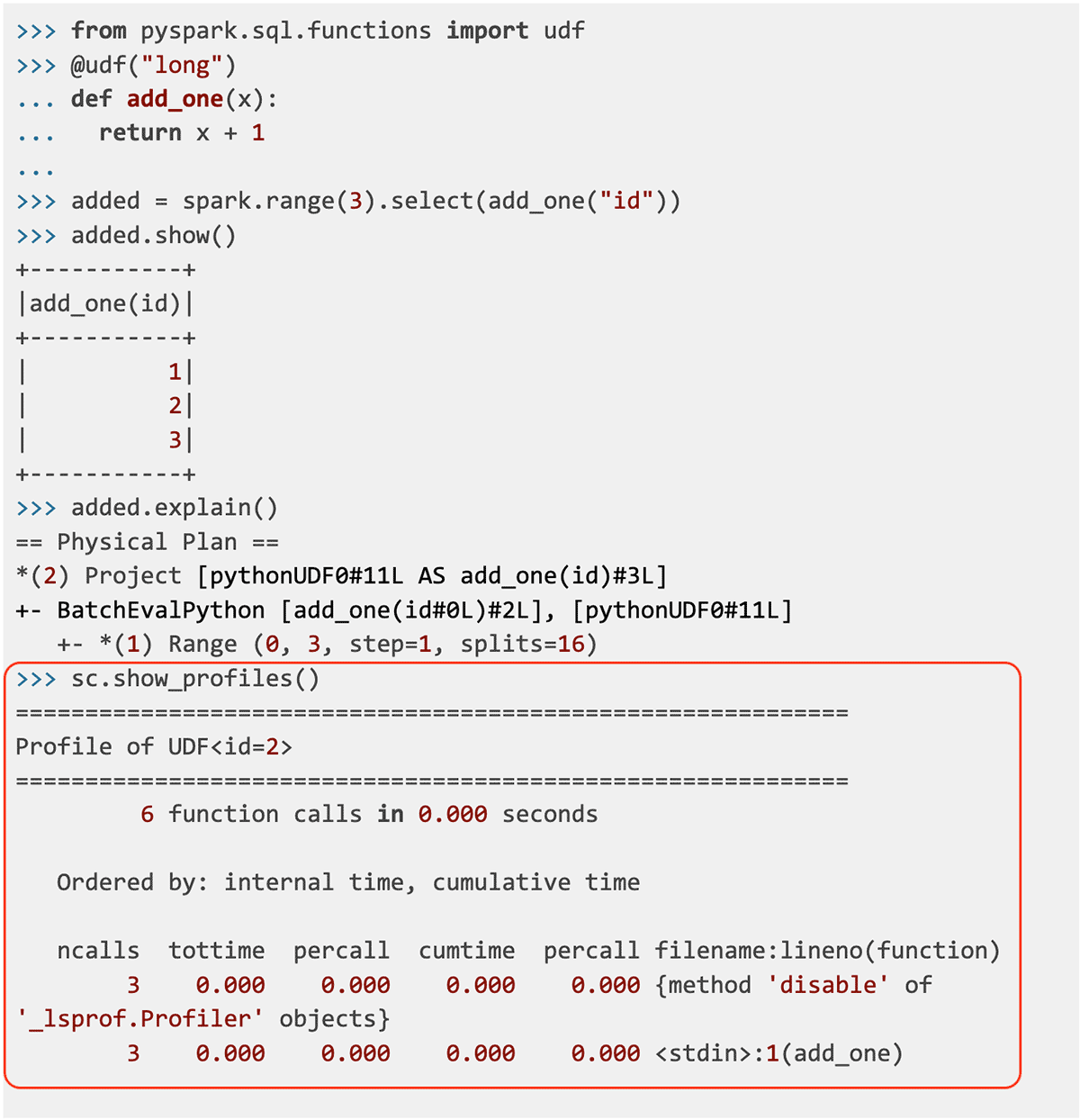
Python/Pandas UDF向けのプロファイラー(SPARK-37443): このリリースでは、有用な統計情報を示す決定論的なUDFのプロファイリングを行う、新たなPython/Pandas UDFプロファイラーを導入します。新たなインフラストラクチャを用いてPySparkを実行する例を示します。

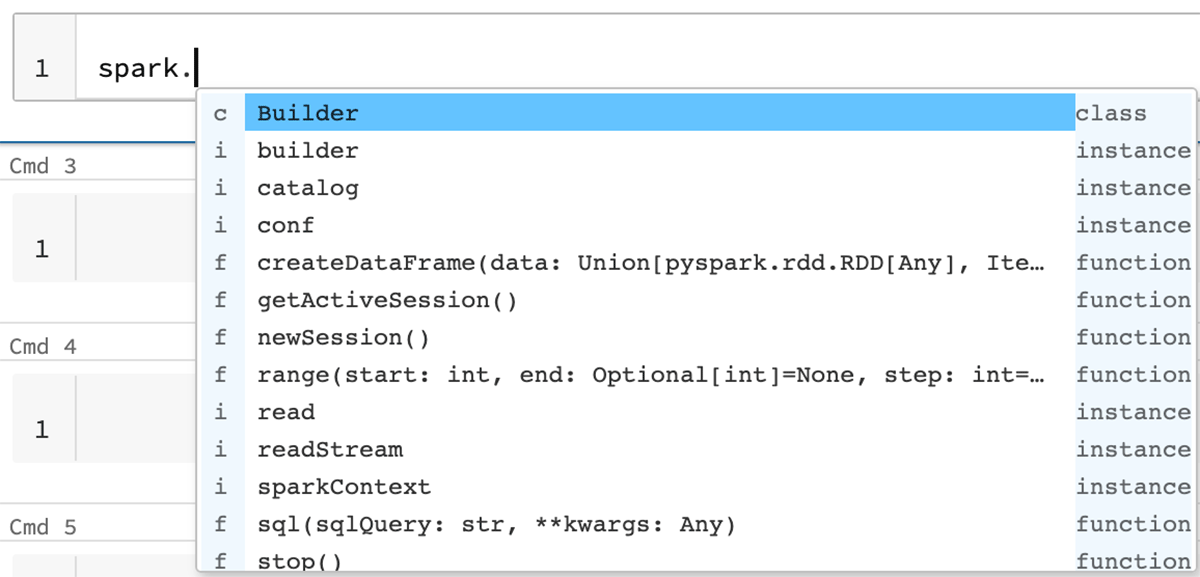
型ヒントのインラインコンプリートによるオートコンプリートの改善(SPARK-39370): より改善されたオートコンプリートを提供するために、このリリースでは全ての型ヒントはstubファイルからインラインの型ヒントに移行されました。例えば、パラメーターの型を表示することで有用なコンテキストを提供する助けになります。
この記事では、Apache Spark 3.3.0におけるハイレベルの機能と改善をまとめました。これらの機能にディープダイブする今後の記事を楽しみにしていてください。全てのSparkコンポーネントにおける主要な機能の包括的なリストや解決されたJIRAチケットに関しては、Apache Spark 3.3.0のリリースノートをご覧ください。
今からSpark 3.3を使い始める
Databricksランタイム11.0でApache Spark 3.3を試すには、Databricks Community EditionかDatabricksのトライアルにサインアップしてください。両方とも無料ですぐにスタートすることができます。Spark 3.3を使用するには、クラスターを起動する際にランタイムでバージョン11.0以降を選ぶだけです。
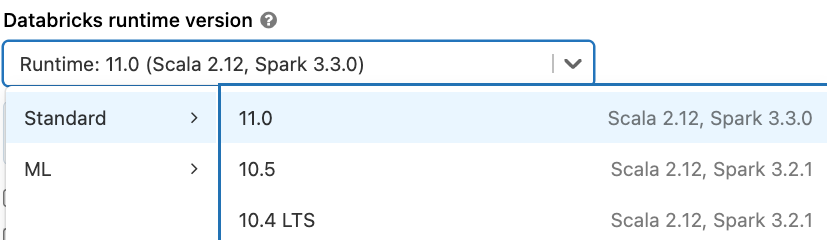
Databrikcsランタイム11.0