6 Guiding Principles to Build an Effective Data Lakehouse - The Databricks Blogの翻訳です。
本書は抄訳であり内容の正確性を保証するものではありません。正確な内容に関しては原文を参照ください。
皆様の企業のデータ&AIの要望に応えるレイクハウスプラットフォームをどのようにデザインするのかに関する指導原則を学びましょう
このブログ記事では、皆様のビジネスゴールを達成するために必要な、モダンなデータとAIの要望に応える、高度に効果的かつ効率的なデータレイクハウスの構築の助けとなるいくつかの指導原則を議論します。新たなオープンなアーキテクチャであるデータレイクハウスに馴染みがないのであれば、こちらのブログ記事をご覧ください。
始める前に、指導原則とは何を意味するのかを定義すべきでしょう。指導原則とは、皆様のアーキテクチャを定義し影響を与えるレベルゼロのルールです。これらは、企業のさまざまなステークホルダーによるコンセンサスのレベルを反映し、将来的なデータとAIのアーキテクチャに対する意思決定における基礎を形成します。我々の観察そして、お客さまから直接得た洞察に基づいて確立した6つの指導原則を見ていきましょう。
原則1: データを整理し、信頼される製品としてのデータを提供しましょう
レイクハウスにおいてはレイヤー分けされた(マルチホップの)アーキテクチャを構築することが重要なベストプラクティスとなっています。これによって、データチームは品質レベルに基づいてデータを構造化することができ、レイヤーごとにロールと責任を定義することが可能となります。一般的なレイヤー分けのアプローチは以下のようになります。
- 生データのレイヤー(Raw Layer): ソースデータが最初のレイヤーに到着することで、レイクハウスに取り込まれ永続化されます。全ての後段のデータはこの生データレイヤーから作成され、必要に応じてこのレイヤーの後続のレイヤーを再構築することができます。
- 整理されたデータのレイヤー(Curated Layer): 2番目のレイヤーの目的は、クレンジングされ、精製され、フィルタリングされ集計されたデータを保持することです。このレイヤーのゴールは、優れた信頼できる分析の基盤を提供し、全てのロール、ファンクションに対してレポートを行うことです。
-
最終レイヤー(Final Layer): 3番目のレイヤーはビジネスやプロジェクトの要件に基づいて作成されます。データプロダクトとして、他のビジネスユニットやプロジェクトに異なるビューを提供し、セキュリティ要件やパフォーマンス最適化(事前集計済みのビューなど)の対応を行います。このレイヤーのデータプロダクトは、ビジネスにおける真実を表現するものと見做されます。
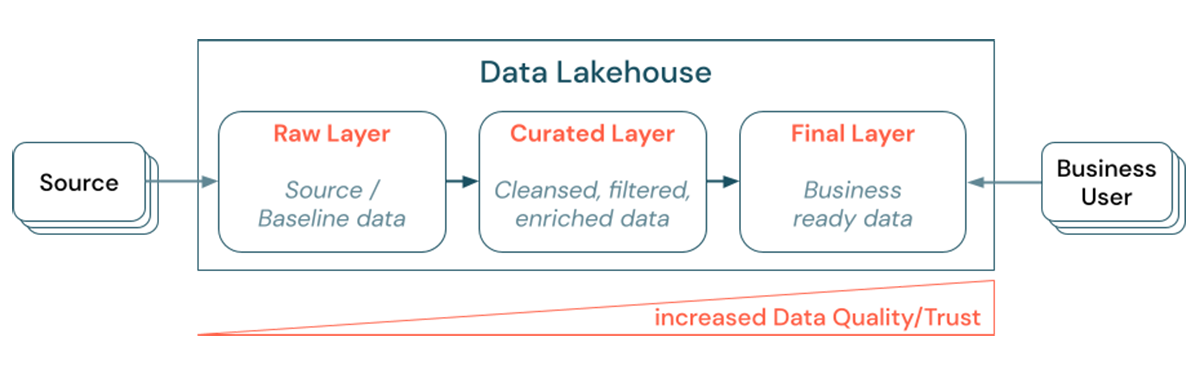
図1: レイヤーを経るごとにデータ品質およびデータの信頼性が増加していきます
全てのレイヤーを横断するパイプラインは、同時読み取り、同時書き込みがある場合においても、データ品質に対する制約を満足する必要があります。整理されたデータのレイヤーにデータエントリーが生成された際、あるいは以降のETLステップにおける検証処理は、このデータの品質を改善するために動作します。
また、データがレイヤーを経ることにデータ品質を改善する必要があり、ビジネス視点におけるデータの信頼性が増加していくということにも言及しておきます。
原則2: データのサイロを排除し、データの移動を最小限にしましょう
データの移動、コピー、複製には時間を要し、レイクハウスにおけるデータ品質を悪化させ、特にデータのサイロ化を引き起こします。データのコピーとデータサイロの違いを明確にしたいのですが、データのコピーそのもの、使い捨てのデータコピー自体は有害なものではありません。これらは、迅速性、実験、イノベーションが求められる場合には必要なものです。後段のビジネスデータプロダクトがこれらのコピーに依存して運用されるようになるとデータのサイロになります。
データのサイロを防ぐために、通常データチームはオリジナルと全てのコピーを同期し続けるデータパイプラインを構築しようとします。多くの場合、一貫性を持ってこれらを行うことは困難なので、データの品質は最終的には劣化します。そして、結局のところ膨大なコストとユーザーからの信頼を損なうことになります。一方でいくつかのビジネスユースケースにおいては、パートナーやサプライヤーなどとのデータ共有の要件が存在します。重要な観点は、セキュアかつ信頼性を持って最新のデータを共有するということです。データのコピーは多くの場合、すぐに同期されなくなるので十分なものではありません。そうではなく、データはエンタープライズデータ共有ツールを通じて共有されるべきです。

図2: レイクハウスではビジネスユーザーがデータに対するクエリーを実行し、パートナーと共有できる機能を提供しています
原則3: セルフサービス体験を通じて価値創出を民主化しましょう
現在、そして将来においては、データ・ドリブンの文化に移行できた企業が成功することでしょう。これは、全てのビジネスユニットが、分析モデルや集中管理されたデータから洞察を得ることで意思決定を行うことを意味します。データ利用者としては、データは容易に発見でき、セキュアにアクセスできるものであるべきです。データ生産者における良いコンセプトは「製品としてのデータ」です。あるビジネスユニットによってデータが製品のように提供、維持管理され、適切なアクセス権管理を通じて他の部門によって利用されます。中央のチームに依存し、潜在的に遅い申請プロセスに頼るのではなく、これらのデータプロダクトはセルフサービスの体験を通じて作成、提供、発見、利用されるべきです。
しかし、これはデータに関わる問題だけではありません。データの民主化には誰でもデータを作成、利用、理解するための適切なツールが必要となります。この中心には、別のツールスタックをセットアップする必要なしに、データプロダクトを作成するためのインフラストラクチャとツールを提供するモダンなデータ&AIプラットフォームであるデータレイクハウスが存在します。

図3: レイクハウスを用いることでデータチームはセルフサービス体験を通じて活用できるデータプロダクトを作成することができます
原則4: 企業規模のデータガバナンス戦略を導入しましょう
データガバナンスは別のブログ記事が書けるほど広い領域です。しかし、データ品質、データカタログ、アクセスコントロールは重要な役割を担います。これらの詳細を見ていきましょう。
データ品質
適切かつ意味のあるレポート、分析結果、機械学習モデルの最も重要な前提条件は高品質のデータです。品質保証(QA)は全てのパイプラインのステップに存在すべきです。どのようにこれを実行するのかの例には、データの契約、SLAへの対応、スキーマを安定に保つこと、制御された方法でスキーマを進化させることなどが含まれます。
データカタログ
別の重要な観点はデータの発見です。全てのビジネス領域のユーザーは特にセルフサービスのモデルにおいては、容易に適切なデータを発見できることが重要になります。このため、レイクハウスにはビジネスに必要な全てのデータをカバーするデータカタログが必要となります。データカタログの主要なゴールは以下のようなものとなります。
- 同じビジネスコンセプトが、ビジネスを通じて統一的に呼び出され、宣言されることを保証すること。整理されたデータレイヤーや最終的なレイヤーにおける意味論モデルとみなすこともできます。
- データがどのように現在の形態になったのかをユーザーが説明できるように、正確にデータの依存関係(データリネージュ)を追跡すること。
- データを適切に利用できるようにするために重要なメタデータを高品質に保つこと。
アクセスコントロール
レイクハウスにおいては、データからの価値創出は全てのビジネス領域で起こるので、セキュリティを最重要事項としてレイクハウスは構築されています。企業はよりオープンなデータアクセスポリシーを採用したり、厳密に最小権限の原則に従うかもしれません。それらに関係なく、全てのレイヤーにデータのアクセスコントロールが適用されるべきです。最初からきめ細かいアクセス権限管理のスキーム(行列レベルのアクセス管理、ロールベース、属性ベースのアクセス管理)を実装することが重要です。企業においては緩やかなルールからスタートすることができます。しかし、レイクハウスプラットフォームが成長するにつれて、全てのメカニズムとプロセスは、既に準備済みのより洗練されたセキュリティ体制に移行していきます。さらに、レイクハウスにおける全てのデータアクセスは最初から監査ログで管理される必要があります。

図4: レイクハウスにおけるガバナンスは、強力なアクセスコントロールだけでなくデータリネージュの追跡も行います
原則5: オープンなインタフェース、オープンなフォーマットの利用を促進しましょう
相互運用性を実現し、特定のベンダーに依存することを避けるためには、オープンなインタフェースが重要となります。これまでは、ベンダーはデータを格納、処理、共有するために、プロプライエタリな技術とクローズドなインタフェースを構築していました。
オープンなインタフェース上で構築することで、将来にわたって利用できるプラットフォームを構築する助けとなります。
- より多くのアプリケーション、ユースケースで活用できるようにデータの寿命と可搬性を高めることができます。
- オープンなインタフェースを活用することで、レイクハウスにパートナーのツールをクイックに連携できるようになりパートナーエコシステムの扉を開きます。
そして、データに対するオープンフォーマットで標準化することで、トータルコストが劇的に削減されます。高価な外向け通信コスト、計算コストを引き起こすプロプライエタリなプラットフォームを経由することなしに、直接クラウドストレージのデータにアクセスすることができます。

図5: サードパーティツールとのインテグレーションを容易にするために、レイクハウスはオープンソースとオープンなインタフェース上に構築されています
原則6: パフォーマンスとコストがスケールし最適化するように構築しましょう
標準的なETLプロセス、ビジネスレポート、ダッシュボードは多くの場合、メモリーと計算資源の観点で予測可能なリソースのニーズを持っています。しかし、新規のプロジェクトや季節性のあるタスク、(解約、予測、メンテナンス)モデルトレーニングのようなモダンなアプローチがリソース要求のピークを引き起こします。企業がこれら全てのワークロードを実施できるようにするためには、メモリーや計算資源がスケーラブルなプラットフォームが必要となります。要求に応じて新たなリソースが容易に追加され、実際に使用した分だけコストが発生すべきです。ピークを越えたらすぐに、再度リソースが解放され、それに応じてコストが削減されます。多くのケースでは、これは水平スケーリング(ノードの増減)や垂直スケーリング(ノードの大小)と呼ばれます。
また、スケーリングによって、より多くのリソースを持つノードや、より多くのノードを持つクラスターを選択することで、企業はクエリーの性能を改善することができます。しかし、大規模なマシンやクラスターを恒久的に配備するのではなく、コストに対する全体的な性能を最適化するために、必要な時だけリソースを配備することができます。最適化の別の観点には、ストレージ対計算リソースというものがあります。データのボリュームとこのデータを用いたワークロードの間には明確な関係性がない(データの一部のみを使用したり、小規模データに対して大量の計算を行うなど)ので、ストレージと計算リソースを分離するインフラストラクチャプラットフォームを使用することが良いプラクティスとなります。

図6: レイクハウスは計算資源とストレージを分離し、優れたスケーラビリティのために柔軟な計算資源を活用します
なぜDatabricksのレイクハウスなのか
Databricksのプラットフォームは、データチームがセルフサービスのデータプロダクトを効率的に提供できるようにするために必要な全ての機能を提供する目的で最初から構築されたネイティブのデータレイクハウスプラットフォームです。全ての主要なデータワークロードに対する単一のソリューションとしてデータウェアハウスとデータレイクの最高の機能を兼ね備えています。サポートするユースケースには、ストリーミング分析、BI、データサイエンスやAIが含まれます。Databricksのレイクハウスは3つの主要なゴールを目指しています。
- シンプル - 単一のプラットフォームでデータ、分析、AIユースケースを統合
- オープン - オープンソースとオープンスタンダードの上に構築
- マルチクラウド - クラウド横断で一貫性のあるデータプラットフォーム
これによって、チームは容易にコラボレーションすることができ、データ取り込み、データ処理、データガバナンス、データの公開/共有を含む、皆様のデータプロダクトの完全なライフサイクルをケアする組み込み機能を活用することができます。Databricksのレイクハウスの詳細に関してはこちらを参照ください。