はじめに
Databricks Runtime 17.1から、外部ライブラリなしでExcelファイル(.xls、.xlsx)を直接読み込めるようになりました。これまでは pandas や openpyxl などを使う必要がありましたが、spark.read.excel() だけでシンプルに読み込めます。
本記事では、この新機能の使い方を一通り試してみます。
この機能は2025年12月時点でベータ版です。ワークスペース管理者がプレビュー機能を有効化する必要があります。
前提条件
- Databricks Runtime 17.1 以上
- ワークスペースでプレビュー機能が有効化されていること
プレビュー機能の有効化は、管理コンソールの「プレビュー」ページから行えます。

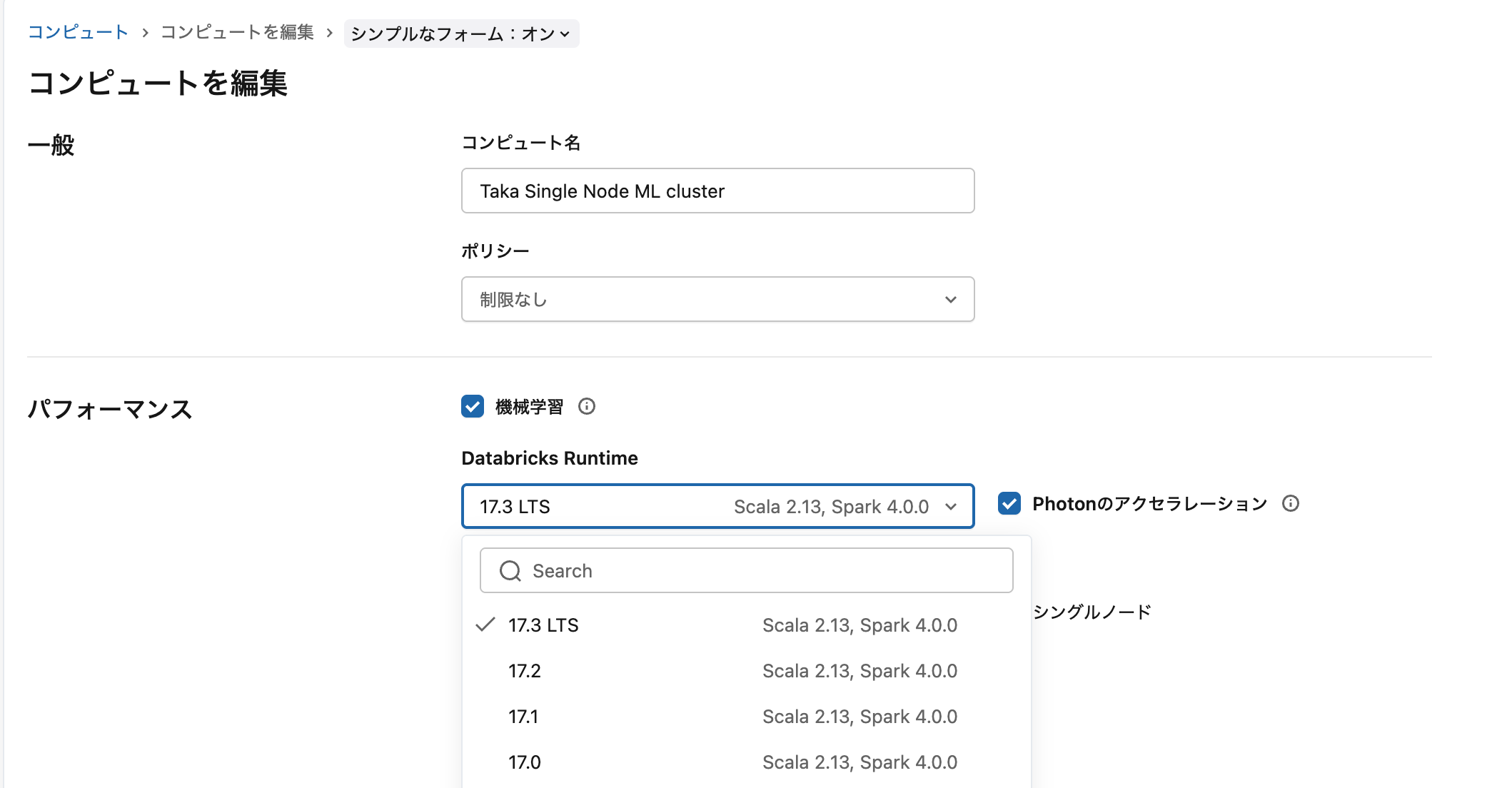
クラスターを作成してランタイムは17.1以降を選択します。
主な特徴
-
spark.read.excel()でExcelファイルを直接読み込み - 複数シートのファイルから任意のシートを読み取り
- セル範囲の指定が可能
- スキーマ、ヘッダー、データ型を自動推論
- 数式は計算済みの値として取り込み
- Auto Loaderによるストリーミング対応
基本的な使い方
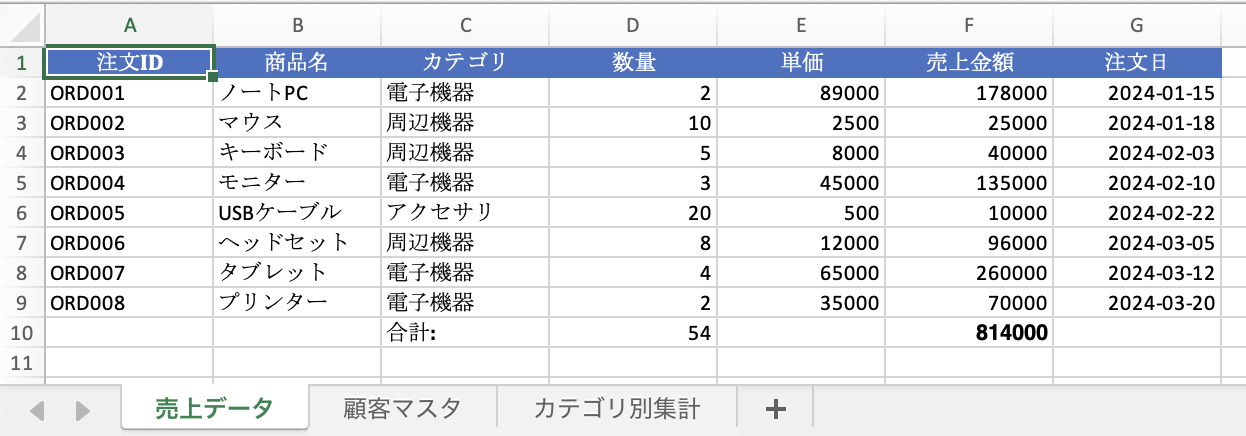
こちらのExcelファイルを使用します。ボリュームにアップロードしておきます。
サンプルノートブックはこちらに。
シンプルな読み込み
df = spark.read.excel("/Volumes/catalog/schema/volume/sample.xlsx")
display(df)
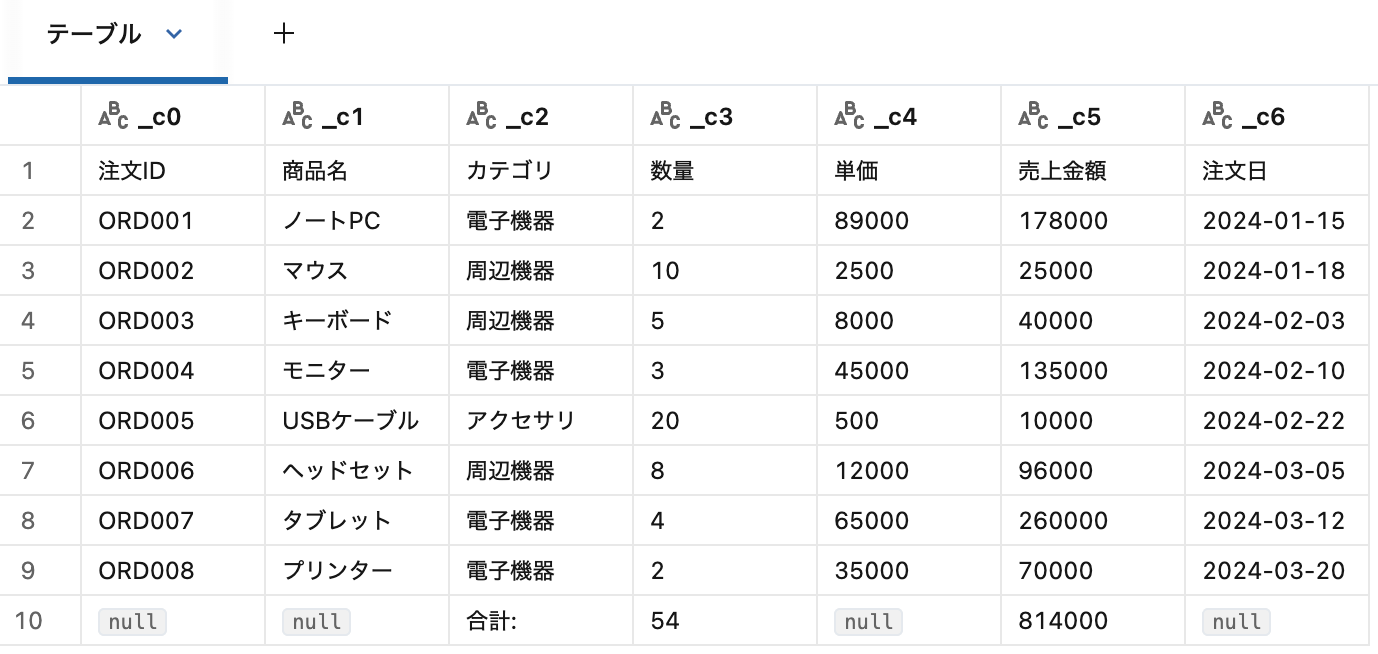
デフォルトでは最初のシートの左上から右下の空でないセルまでを読み込みます。
ヘッダー行の指定
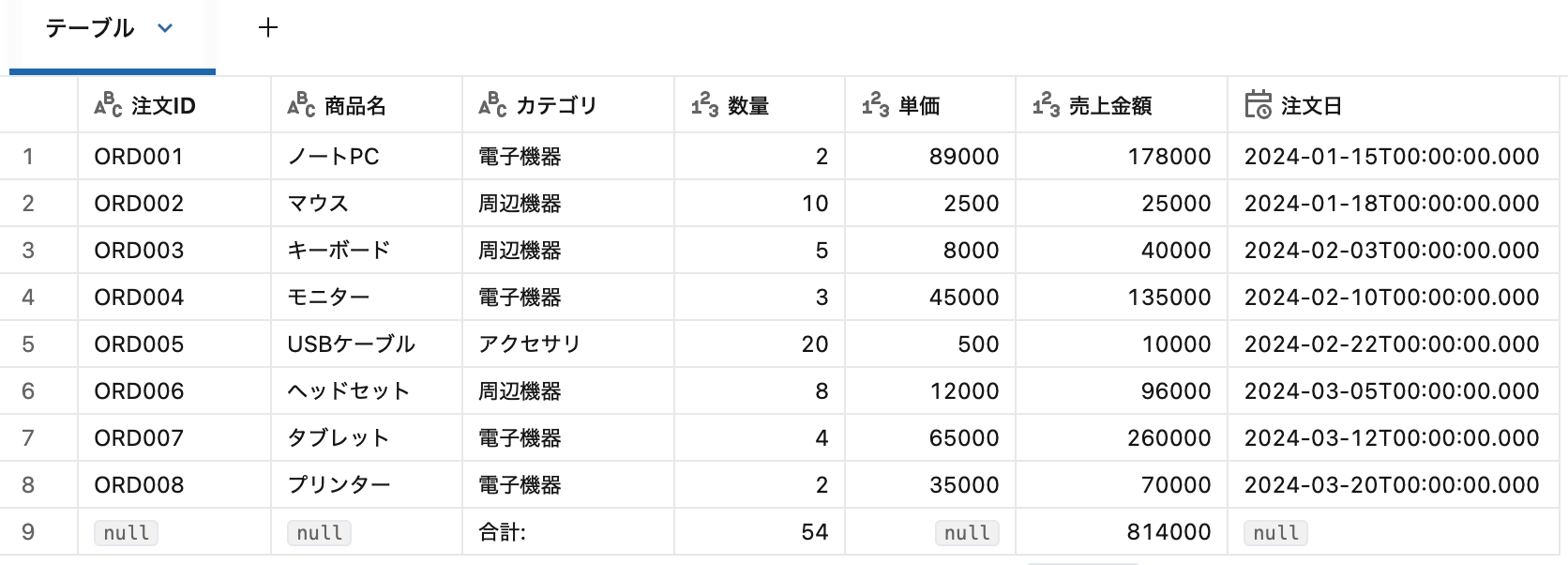
headerRows オプションで1行目を列名として認識させます。
df = (
spark.read
.option("headerRows", 1)
.excel("/Volumes/catalog/schema/volume/sample.xlsx")
)
headerRows=0(デフォルト)の場合、列名は _c1、_c2、_c3 ... と自動生成されます。
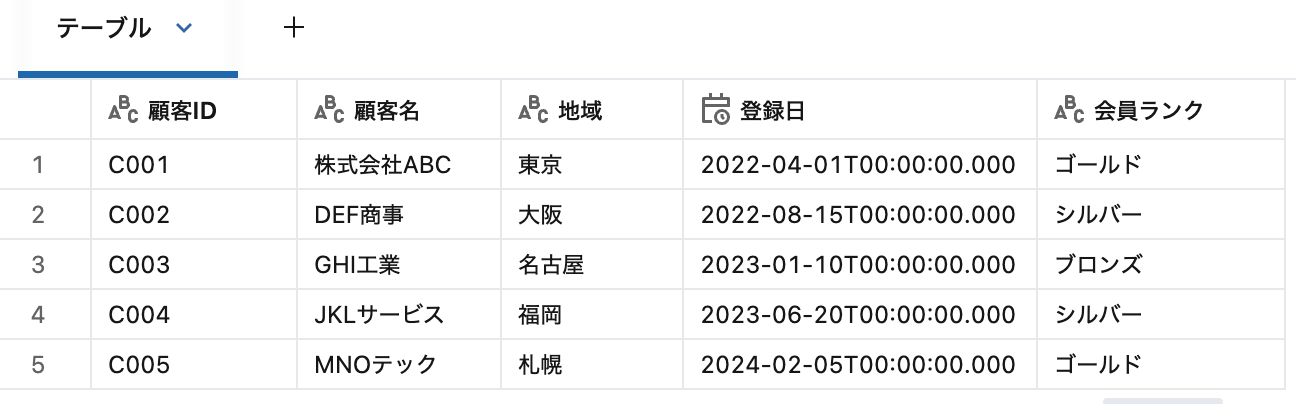
特定シートの読み込み
dataAddress オプションでシート名を指定します。
df = (
spark.read
.option("headerRows", 1)
.option("dataAddress", "顧客マスタ")
.excel("/Volumes/catalog/schema/volume/sample.xlsx")
)
セル範囲の指定
dataAddress でExcel形式のセル範囲を指定できます。
df = (
spark.read
.option("headerRows", 1)
.option("dataAddress", "Sheet1!A1:E10")
.excel("/Volumes/catalog/schema/volume/sample.xlsx")
)
タイトル行などをスキップしたい場合に便利です。
シート一覧の取得
operation オプションを listSheets にすると、ファイル内のシート一覧を取得できます。
df_sheets = (
spark.read
.option("operation", "listSheets")
.excel("/Volumes/catalog/schema/volume/sample.xlsx")
)
display(df_sheets)
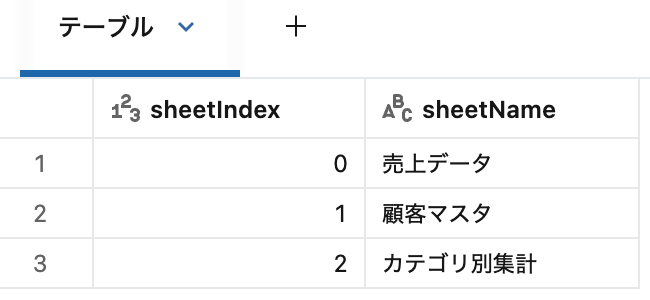
返却されるスキーマは sheetIndex(Long)と sheetName(String)の2カラムです。
複数シートの処理
シート一覧を取得して、ループで各シートを処理できます。
sheets_df = (
spark.read
.option("operation", "listSheets")
.excel(EXCEL_FILE_PATH)
)
sheet_names = [row.sheetName for row in sheets_df.collect()]
for sheet_name in sheet_names:
print(f"\n=== {sheet_name} ===")
df = (
spark.read
.option("headerRows", 1)
.option("dataAddress", sheet_name)
.excel(EXCEL_FILE_PATH)
)
df.show(truncate=False)
=== 売上データ ===
+------+------------+----------+----+-----+--------+-------------------+
|注文ID| 商品名| カテゴリ|数量| 単価|売上金額| 注文日|
+------+------------+----------+----+-----+--------+-------------------+
|ORD001| ノートPC| 電子機器| 2|89000| 178000|2024-01-15 00:00:00|
|ORD002| マウス| 周辺機器| 10| 2500| 25000|2024-01-18 00:00:00|
|ORD003| キーボード| 周辺機器| 5| 8000| 40000|2024-02-03 00:00:00|
|ORD004| モニター| 電子機器| 3|45000| 135000|2024-02-10 00:00:00|
|ORD005| USBケーブル|アクセサリ| 20| 500| 10000|2024-02-22 00:00:00|
|ORD006|ヘッドセット| 周辺機器| 8|12000| 96000|2024-03-05 00:00:00|
|ORD007| タブレット| 電子機器| 4|65000| 260000|2024-03-12 00:00:00|
|ORD008| プリンター| 電子機器| 2|35000| 70000|2024-03-20 00:00:00|
| NULL| NULL| 合計:| 54| NULL| 814000| NULL|
+------+------------+----------+----+-----+--------+-------------------+
=== 顧客マスタ ===
+------+-----------+------+-------------------+----------+
|顧客ID| 顧客名| 地域| 登録日|会員ランク|
+------+-----------+------+-------------------+----------+
| C001|株式会社ABC| 東京|2022-04-01 00:00:00| ゴールド|
| C002| DEF商事| 大阪|2022-08-15 00:00:00| シルバー|
| C003| GHI工業|名古屋|2023-01-10 00:00:00| ブロンズ|
| C004|JKLサービス| 福岡|2023-06-20 00:00:00| シルバー|
| C005| MNOテック| 札幌|2024-02-05 00:00:00| ゴールド|
+------+-----------+------+-------------------+----------+
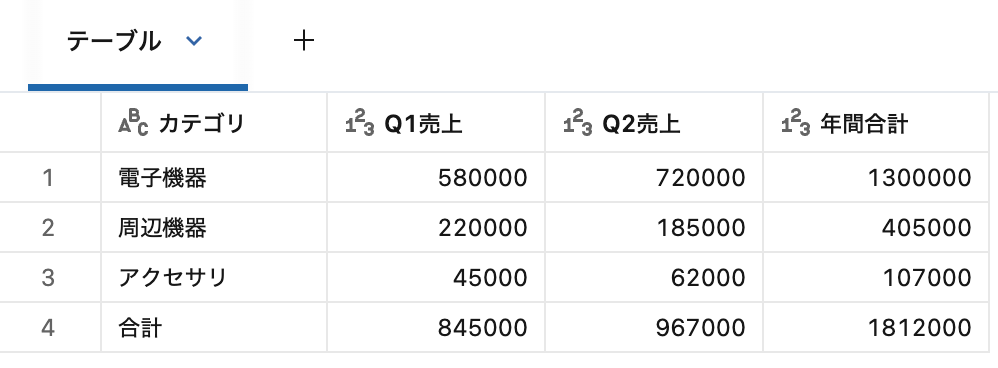
=== カテゴリ別集計 ===
+-------------------------------+------+------+--------+
|【2024年度 カテゴリ別売上集計】| _c1| _c2| _c3|
+-------------------------------+------+------+--------+
| NULL| NULL| NULL| NULL|
| カテゴリ|Q1売上|Q2売上|年間合計|
| 電子機器|580000|720000| 1300000|
| 周辺機器|220000|185000| 405000|
| アクセサリ| 45000| 62000| 107000|
| 合計|845000|967000| 1812000|
+-------------------------------+------+------+--------+
SQLでの読み込み
基本
read_files テーブル値関数を使ってSQLからも読み込めます。
SELECT * FROM read_files(
'/Volumes/catalog/schema/volume/sample.xlsx',
format => 'excel',
headerRows => 1,
schemaEvolutionMode => 'none'
)
シート・範囲指定
SELECT * FROM read_files(
'/Volumes/catalog/schema/volume/sample.xlsx',
format => 'excel',
headerRows => 1,
dataAddress => '顧客マスタ!A1:E6',
schemaEvolutionMode => 'none'
)
テーブル作成
CREATE TABLE my_table AS
SELECT * FROM read_files(
'/Volumes/catalog/schema/volume/sample.xlsx',
format => 'excel',
headerRows => 1,
schemaEvolutionMode => 'none'
)
COPY INTO
CREATE TABLE IF NOT EXISTS excel_demo_table;
COPY INTO excel_demo_table
FROM '/Volumes/catalog/schema/volume/sample.xlsx'
FILEFORMAT = EXCEL
FORMAT_OPTIONS ('headerRows' = '1', 'mergeSchema' = 'true')
COPY_OPTIONS ('mergeSchema' = 'true');
Auto Loaderでのストリーミング
cloudFiles.format を excel に設定することで、Excelファイルをストリーミング処理できます。
df_stream = (
spark.readStream
.format("cloudFiles")
.option("cloudFiles.format", "excel")
.option("cloudFiles.inferColumnTypes", True)
.option("headerRows", 1)
.option("cloudFiles.schemaLocation", "/path/to/schema")
.option("cloudFiles.schemaEvolutionMode", "none")
.load("/path/to/excel/files/")
)
(
df_stream.writeStream
.format("delta")
.option("mergeSchema", "true")
.option("checkpointLocation", "/path/to/checkpoint")
.table("catalog.schema.excel_streaming_table")
)
ストリーミングではスキーマ進化がサポートされていないため、schemaEvolutionMode="none" を明示的に設定する必要があります。
オプション一覧
| オプション | 説明 | デフォルト |
|---|---|---|
dataAddress |
読み取るシート名またはセル範囲(Excel形式) | 最初のシート全体 |
headerRows |
ヘッダー行の数(0 または 1) | 0 |
operation |
実行する操作(readSheet または listSheets) |
readSheet |
timestampNTZFormat |
タイムゾーンなしタイムスタンプのフォーマット | yyyy-MM-dd'T'HH:mm:ss[.SSS] |
dateFormat |
日付フォーマット | yyyy-MM-dd |
制限事項
- パスワードで保護されたファイルは非対応
- ヘッダー行は1行のみ対応
- 結合セルは左上のセルにのみ値が入り、他は
NULL - Auto Loaderでのスキーマ進化は非対応
- Strict Open XML スプレッドシート(Strict OOXML)は非対応
-
.xlsmファイルのマクロ実行は非対応 -
ignoreCorruptFilesオプションは非対応
まとめ
Databricks Runtime 17.1の組み込みExcel読み込み機能を試してみました。
これまでExcelファイルの取り込みには外部ライブラリが必要でしたが、spark.read.excel() で直接読み込めるようになり、ETLパイプラインがシンプルになります。特にビジネスユーザーからExcelで受け取るデータの取り込みには便利そうです。
ベータ版なので本番利用には注意が必要ですが、GAが楽しみな機能です。
参考