Efficient Upserts into Data Lakes with Databricks Delta - The Databricks Blogの翻訳です。
チェンジデータキャプチャ(CDC)、GDPRユースケースのためのビッグデータパイプライン構築をシンプルに
Apache Spark™上に構築された次世代エンジンであるDatabricks Delta Lakeで、お使いのデータレイクのレコードのdelete、upsert(update + insert)を効率的に行うMERGEコマンドがサポートされました。MERGEを用いることで、数多くの一般的なデータパイプラインの構築が劇的にシンプルなものになります。非効率的に全てのパーティションに対する再書き込みを行なっていた全ての複雑なマルチホップの処理は、シンプルなMERGEクエリーに置き換えることができます。このきめ細かい更新機能によって、チェンジデータキャプチャからGDPRに至る様々なユースケースに対するビッグデータパイプラインの構築をシンプルなものにします。
様々なユースケースにおけるUPSERTの必要性
データレイク上の既存データを更新、削除しなくてはならない一般的なユースケースが数多く存在します。
- 一般データ保護規則(GDPR)準拠: GDPRにおいて忘れ去られる権利(データ消去)が導入されたことで、企業は要請に応じてユーザー情報を削除しなくてはなりません。このデータ消去には、データレイク上のユーザー情報の削除も含まれます。
- 従来型のデータベースからチェンジデータキャプチャ: サービス指向アーキテクチャにおいては、低レーテンシーに最適化された従来型のSQL/NoSQLデータベース上に構築されたマイクロサービスによって、ウェブアプリケーション、モバイルアプリケーションが提供されるのが一般的です。企業が直面する最大の課題は、サイロ化された様々なデータシステムのデータの結合であり、このため、データエンジニアは分析を円滑にするために、全てのデータソースから中央のデータレイクにデータを統合するパイプラインを構築します。これらのパイプラインは多くのケースで、従来型のSQL/NoSQLテーブル上の変更を定期的に読み取る必要があり、それらの変更をデータレイク上のテーブルに反映しなくてはなりません。このような変更は様々な形態をとります:緩やかに変化するディメンジョンを伴うテーブル、インサート、アップデート、デリートされた全ての行のチェンジデータキャプチャなどです。
- セッション化: 製品分析、ターゲティング広告、予兆保全などの様々領域において、複数のイベントを単一のセッションにグルーピングすることは一般的なユースケースです。データレイクは常にデータの追加に最適化されているため、セッションを追跡する継続的アプリケーションを構築し、データレイクに書き込まれた結果を記録することは困難です。
- 重複の排除: 一般的なデータパイプラインのユースケースは、テーブルにデータを追加することで、システムログをDatabricks Deltaテーブルに収集することです。しかし、多くのケースでデータソースは重複するレコードを生成し、下流における重複除外の処理においては、それらの面倒を見なくてはなりません。
データレイクに対するUPSERTの課題
データレイクは基本的にファイルベースであるため、常に既存データの変更よりもデータの追加に最適化されています。このため、上記のユースケースを構築することは常に課題となっています。通常ユーザーはテーブル全体(あるいはサブセットのパーティション)を読み込み、それらを上書きします。結果、全ての企業は、SQL、Sparkなどで複雑なクエリーを手書きすることで、要件に応えるために車輪の再発明に挑戦しています。このアプローチに以下の課題があります。
- 非効率: 数行の更新のために、パーティション全体(あるいはテーブル全体)の読み込み、再書き込みを行うことで、パイプラインを遅く、高コストにしてしまいます。手動によるテーブルレイアウトのチューニングと、クエリーの最適化は手間がかかるものであり、深いドメイン知識を必要とします。
- 不正確である可能性: データを更新する手書きのコードは、論理的、ヒューマンエラーの影響を受けやすいです。例えば、トランザクションサポートがない状態で、同じテーブルに対して複数のパイプラインが同時に更新を行うと、最悪の場合、予期しないデータの不整合を引き起こします。多くのケースでは、単一の手書きのパイプラインであっても、ビジネスロジックの実装上のエラーから容易にデータを破壊します。
- メンテナンスが困難: このような手書きのコードは基本的に理解しにくく、追跡、メンテナンスが困難です。長期的には、このことだけでも、企業、インフラストラクチャに関するコストを劇的に増加させます。
Databricks Delta LakeのMERGEのご紹介
DatabricksのDelta Lakeを活用することで、以下のMERGEコマンドを用いることで、上述した問題を回避して、上記のユースケースに容易に対応することができます。
MERGE INTO
USING
ON
[ WHEN MATCHED [ AND ] THEN ]
[ WHEN MATCHED [ AND ] THEN ]
[ WHEN NOT MATCHED [ AND ] THEN ]
where
=
DELETE |
UPDATE SET * |
UPDATE SET column1 = value1 [, column2 = value2 ...]
=
INSERT * |
INSERT (column1 [, column2 ...]) VALUES (value1 [, value2 ...])
文法の詳細に関してはドキュメントを参照ください。(Azure|AWS)
シンプルな例でMERGEをどのように使うのかを学びましょう。住所のようなユーザー情報を保持するslowly changing dimensionテーブルを持っていると仮定します。さらに、既存、新規ユーザーの新た住所を保持するテーブルを持っているとします。全ての新規住所をメインのユーザーテーブルにマージするために、以下のコマンドを実行します。
MERGE INTO users
USING updates
ON users.userId = updates.userId
WHEN MATCHED THEN
UPDATE SET address = updates.addresses
WHEN NOT MATCHED THEN
INSERT (userId, address) VALUES (updates.userId, updates.address)
これは、まさに文法が述べている通りのことを実行します。既存ユーザー(MATCHED句)に対しては、addressカラムを更新し、新規ユーザー(NOT MATCHED句)に対しては、全てのカラムをインサートします。テラバイト規模の大きなテーブルに対して、Databricks Delta LakeのMERGE処理は、Delta Lakeが適切なファイルのみを読み込んで更新を行うため、パーティション、テーブル全体を上書きするよりも数十倍高速です。特に、Delta LakeのMERGEには以下の優位性があります。
- きめ細かい: データの再書き込みは、パーティションではなくファイルの粒度で行われます。これによって、パーティションの再書き込み、MSCKによるHiveメタストアの更新などの複雑性を排除します。
- 効率的: Delta Lakeのデータスキッピングによって、MERGEが再書き込みを行うファイルの検索を効率的なものにするので、パイプラインを手動で最適化する必要はありません。さらに、Delta LakeにおけるすべてのI/O、処理の最適化によって、MERGEによるデータの読み込み、書き込みは、Apache Sparkにおける同等の処理よりも高速なものになります。
- トランザクションのサポート: Delta Lakeは、ACIDトランザクションを用いて同時更新処理が適切にアップデートすることを保証するために、楽観的同時性制御を活用しているので、同時に読み取りを行なっても、常に一貫性のあるデータのスナップショットを参照できます。
こちらが、手書きのパイプラインとMERGEの比較をビジュアルに説明したものとなります。
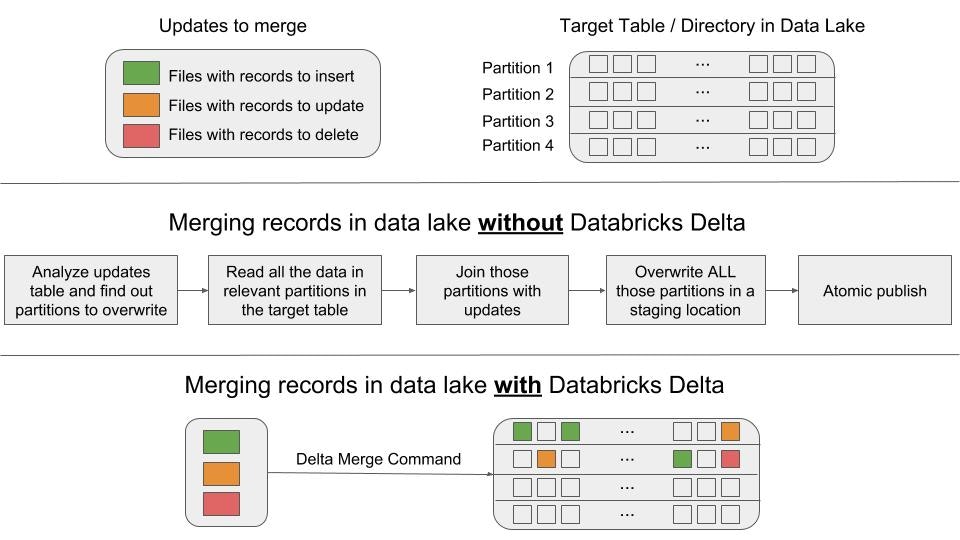
上の図では、Delta LakeのMERGEを用いた場合と、用いない場合に必要なステップを示しています。
MERGEでユースケースをシンプルに
GDPRに対応するためにデータを削除
データレイクのデータにおいて、GDPRの「忘れ去れる権利」に準拠することは容易ではありません。しかし、MERGEを用いることで、サービスをオプトアウトした全てのユーザーを削除するために、以下のようなサンプルコードを実行するシンプルなスケジュールジョブをセットアップすることができます。
MERGE INTO users
USING opted_out_users
ON opted_out_users.userId = users.userId
WHEN MATCHED THEN DELETE
データベースのデータ変更を適用
以下のMERGEを用いることで、外部データベースにおける全てのデータ変更、update、delte、insertを、容易にDatabricks Delta Lakeテーブルに適用することができます。
MERGE INTO users
USING (
SELECT userId, latest.address AS address, latest.deleted AS deleted FROM (
SELECT userId, MAX(struct(TIME, address, deleted)) AS latest
FROM changes GROUP BY userId
)
) latestChange
ON latestChange.userId = users.userId
WHEN MATCHED AND latestChange.deleted = TRUE THEN
DELETE
WHEN MATCHED THEN
UPDATE SET address = latestChange.address
WHEN NOT MATCHED AND latestChange.deleted = FALSE THEN
INSERT (userId, address) VALUES (userId, address)
ストリーミングパイプラインからのセッション情報の更新
ストリーミングとして流れ込んでくるイベンドデータがあり、このストリーミングイベントデータをセッション化し、Databricks Deltaテーブルに対して、インクリメンタルに更新、格納したいのであれば、構造化ストリーミングのforeachBatchとMERGEを用いることでこれを実現できます。例えば、それぞれのユーザーごとのセッション情報を計算する構造化ストリーミングデータフレームがあると想定します。以下のようにDeltaテーブルに対して全てのセッション情報の更新を行うストリーミングクエリー(Scala)をスタートすることができます。
streamingSessionUpdatesDF.writeStream
.foreachBatch { (microBatchOutputDF: DataFrame, batchId: Long) =>
microBatchOutputDF.createOrReplaceTempView("updates")
microBatchOutputDF.sparkSession.sql(s"""
MERGE INTO sessions
USING updates
ON sessions.sessionId = updates.sessionId
WHEN MATCHED THEN UPDATE SET *
WHEN NOT MATCHED THEN INSERT * """)
}.start()
foreachBatchとMERGEの動作例に関しては、サンプルノートブックを参照ください。(Azure|AWS)
まとめ
DatabrikcsのDelta Lakeにおけるきめ細かい更新機能によって、ビッグデータパイプラインの構築がシンプルなものになります。もはやテーブルを更新するために複雑なロジックを記述する必要はなく、スナップショット文理の欠如を克服できます。きめ細かい更新によって、テーブル全体を読み込んで更新する必要がなくなるので、パイプラインはより効率的になります。データを更新する際には、誤った更新を行った際にロールバックできる重要な機能が求められます。DatabricksのDelta Lakeはタイムトラベル機能によるロールバック機能も提供しているので、誤ったMERGEを行ったとしても容易にロールバックできます。
きめ細かい更新機能の詳細に関してはドキュメント(Azure|AWS)を参照ください。実際に機能を試したい場合には、Databricksのフリートライアルにサインアップしてみてください。