これは嬉しい。
ai_parse_documentのリージョン可用性の拡張
ai_parse_documentは以下のリージョンで利用できるようになりました:
- us-west-2
- us-east-1
- us-east-2
- ap-northeast-1 (東京!)
- ap-northeast-2
- ap-south-1
- ap-southeast-1
- ap-southeast-2
- ca-central-1
- eu-central-1
- eu-west-1
- eu-west-2
- sa-east-1
ai_parse_document functionをご覧ください。
ai_parse_document関数とは
Databricks SQL/Runtimeで利用可能なai_parse_document()関数は、PDFや画像ファイルなどの非構造化ドキュメントから、AIを使って構造化されたデータを自動抽出する機能です(Beta版)。Foundation Model APIsのLlama系モデルを活用し、ページ番号、ヘッダー、フッター、本文、表などの要素を認識して、Markdown形式で出力します。Unity Catalogボリュームに保存されたファイルを直接処理でき、SQLクエリやPython、Scalaから簡単に呼び出せるため、大量のドキュメント処理の自動化に役立ちます。
機能概要
ai_parse_document()関数は、Databricksが提供する生成AIモデルを活用して、非構造化ドキュメントから構造化されたコンテンツを抽出する関数です。
主な特徴
対応ファイル形式
- JPG/JPEG
- PNG
抽出可能な要素
| 要素タイプ | 説明 |
|---|---|
| ページ情報 | ページ番号、ヘッダー、フッター |
| コンテンツ要素 | テキスト(text)、表(table)、図(figure) |
| 出力形式 | Markdown形式で構造化 |
出力スキーマ構造
{
"document": {
"pages": [ // ページごとの情報
{
"id": INT,
"page_number": STRING,
"header": STRING,
"footer": STRING,
"content": STRING // Markdown形式のページ全体
}
],
"elements": [ // 個別要素の情報
{
"id": INT,
"type": STRING, // text, table, figure
"content": STRING,
"page_id": INT
}
]
},
"corrupted_data": [...], // エラーデータ
"error_status": [...], // エラー状態
"metadata": {...} // バージョン情報など
}
メリット、嬉しさ
1. 手動作業の大幅削減
従来、PDFや画像から情報を抽出するには、手動でのコピー&ペーストや専用ツールでの複雑な設定が必要でした。この関数を使えば、SQLやPythonの1行のコードで自動化できます。
2. 構造を保持した抽出
単純なテキスト抽出ではなく、以下の構造情報を維持します:
- ページ単位での管理
- ヘッダー/フッターの識別
- 表形式データの認識
- 図表要素の分離
3. 大規模処理への対応
Unity Catalogボリュームと連携し、大量のドキュメントを一括処理できます。Databricks Workflowsやジョブとも統合可能です。
4. セキュアな処理環境
ドキュメントデータはDatabricksのセキュリティ境界内で処理され、外部に送信されません。
注意点
1. Beta版の制限事項
- 機能は改善中のため、仕様が変更される可能性があります
- 処理時間が長くなる場合があります(特に高密度コンテンツや低解像度の場合)
2. 対応ファイル形式の制限
現在はJPG/JPEG、PNG、PDFのみ対応しています。Word文書やExcelファイルなどは直接処理できません。
3. 言語サポートの制限
- 非ラテン文字(日本語、韓国語など)を含む画像では、精度が低下する可能性があります
- デジタル署名を含むドキュメントは正確に処理されない場合があります
4. カスタマイズの制限
- 使用するAIモデルのカスタマイズはできません
- 独自モデルの使用もサポートされていません
5. 利用可能環境
-
プレビューでMosaic AI Agent Bricks Previewをオンにしてあること。なお、現時点では日本リージョンでこれをオンにしてもAgent Bricks自体は利用できるようにはなりません。

-
Databricksノートブック、SQLエディタ、Workflows、ジョブ、Lakeflow Declarative Pipelinesでのみ利用可能
-
サーバーレスコンピュートを使用する場合は、環境バージョン2が必要
使ってみる
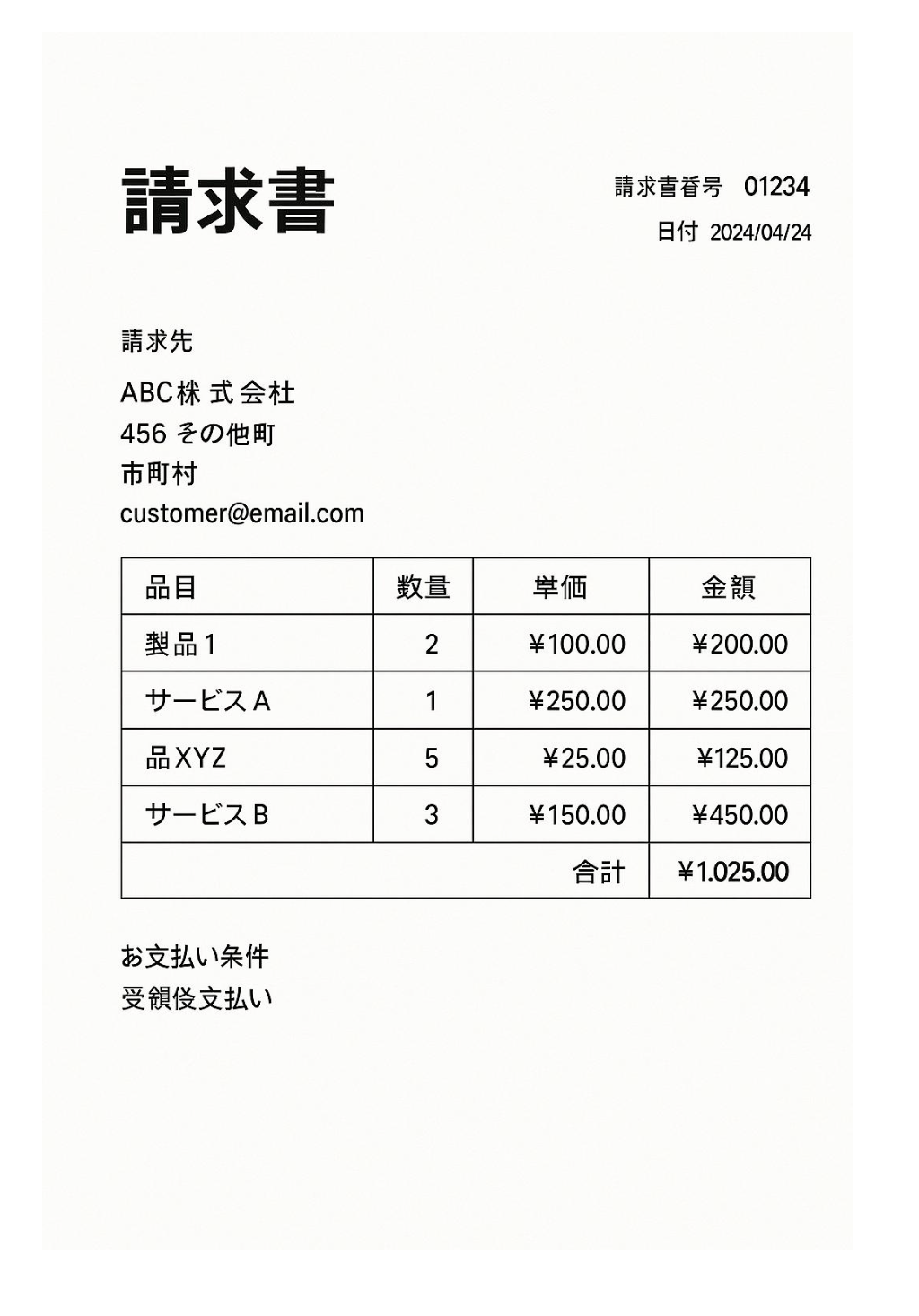
以下のようなPDFを準備してVol.にアップロードします。こちらで使ったものです。
SQLエディタで以下のSQLを実行します。
SELECT
path,
ai_parse_document(content)
FROM READ_FILES('/Volumes/takaakiyayoi_catalog/ai_functions/unstructured', format => 'binaryFile');
パーシングできています。
| path | ai_parse_document(content) |
|---|---|
| dbfs:/Volumes/takaakiyayoi_catalog/ai_functions/unstructured/japanese_invoice.pdf | {"corrupted_data":null,"document":{"elements":[{"content":"# 請求書","id":0,"page_id":0,"type":"text"},{"content":"請求先\nABC株式会社\n456 その他町\n市町村\ncustomer@email.com","id":1,"page_id":0,"type":"text"},{"content":"| 品目 | 数量 | 見積 | 金額 |\n| --- | --- | --- | --- |\n| 製品1 | 2 | ¥100.00 | ¥200.00 |\n| サービスA | 1 | ¥250.00 | ¥250.00 |\n| 品XYZ | 5 | ¥25.00 | ¥125.00 |\n| サービスB | 3 | ¥150.00 | ¥450.00 |\n| 合計 | | | ¥1,025.00 |","id":2,"page_id":0,"type":"table"},{"content":"お支払い条件\n受領後支払い","id":3,"page_id":0,"type":"text"}],"pages":[{"content":"# 請求書\n\n請求先\nABC株式会社\n456 その他町\n市町村\ncustomer@email.com\n\n| 品目 | 数量 | 見積 | 金額 |\n| --- | --- | --- | --- |\n| 製品1 | 2 | ¥100.00 | ¥200.00 |\n| サービスA | 1 | ¥250.00 | ¥250.00 |\n| 品XYZ | 5 | ¥25.00 | ¥125.00 |\n| サービスB | 3 | ¥150.00 | ¥450.00 |\n| 合計 | | | ¥1,025.00 |\n\nお支払い条件\n受領後支払い","footer":null,"header":null,"id":0,"page_number":"01234"}]},"error_status":null,"metadata":{"backend_id":"444f3bbf-f4b3-411c-a607-8d9ee784f75e","version":"1.0"}} |
抽出した要素を明示的に取り出します。
WITH corpus AS (
SELECT
path,
ai_parse_document(content) AS parsed
FROM
READ_FILES('/Volumes/takaakiyayoi_catalog/ai_functions/unstructured', format => 'binaryFile')
)
SELECT
path,
parsed:document:pages,
parsed:document:elements,
parsed:corrupted_data,
parsed:error_status,
parsed:metadata
FROM corpus;
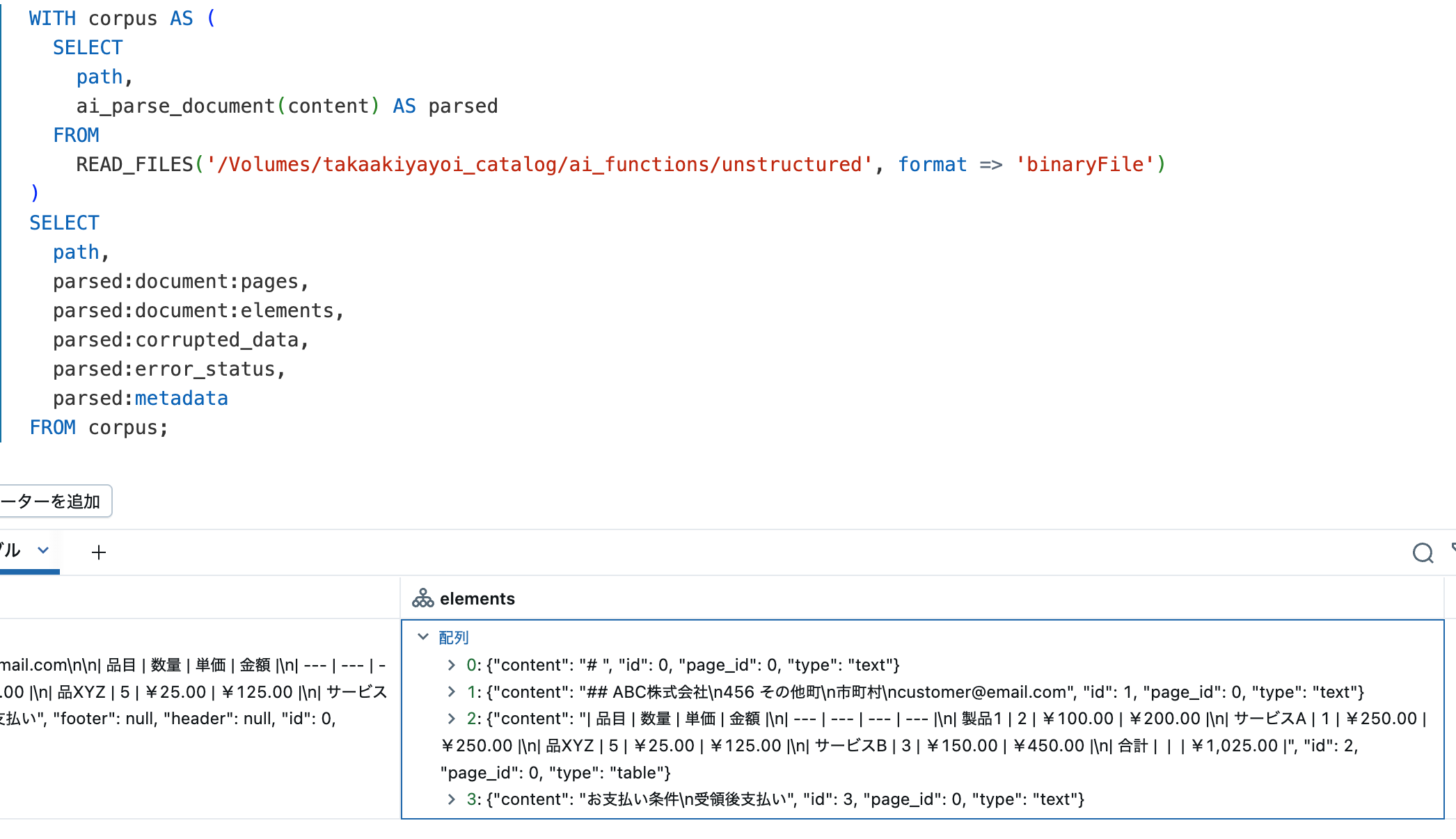
| path | pages | elements | corrupted_data | error_status | metadata |
|---|---|---|---|---|---|
| dbfs:/Volumes/takaakiyayoi_catalog/ai_functions/unstructured/japanese_invoice.pdf | [{"content":"# \n\n## ABC株式会社\n456 その他町\n市町村\ncustomer@email.com\n\n| 品目 | 数量 | 単価 | 金額 |\n| --- | --- | --- | --- |\n| 製品1 | 2 | ¥100.00 | ¥200.00 |\n| サービスA | 1 | ¥250.00 | ¥250.00 |\n| 品XYZ | 5 | ¥25.00 | ¥125.00 |\n| サービスB | 3 | ¥150.00 | ¥450.00 |\n| 合計 | | | ¥1,025.00 |\n\nお支払い条件\n受領後支払い","footer":null,"header":null,"id":0,"page_number":"01234"}] | [{"content":"# ","id":0,"page_id":0,"type":"text"},{"content":"## ABC株式会社\n456 その他町\n市町村\ncustomer@email.com","id":1,"page_id":0,"type":"text"},{"content":"| 品目 | 数量 | 単価 | 金額 |\n| --- | --- | --- | --- |\n| 製品1 | 2 | ¥100.00 | ¥200.00 |\n| サービスA | 1 | ¥250.00 | ¥250.00 |\n| 品XYZ | 5 | ¥25.00 | ¥125.00 |\n| サービスB | 3 | ¥150.00 | ¥450.00 |\n| 合計 | | | ¥1,025.00 |","id":2,"page_id":0,"type":"table"},{"content":"お支払い条件\n受領後支払い","id":3,"page_id":0,"type":"text"}] | null | null | {"backend_id":"3f3acd57-11cd-43b2-b125-63165a67153c","version":"1.0"} |
日本語でも問題ない感じです。
まとめ
ai_parse_document()関数は、PDFや画像ファイルから構造化データを簡単に抽出できる強力なツールです。SQLやPythonから簡単に呼び出せ、大量のドキュメント処理を自動化できます。現在はBeta版のため一部制限がありますが、契約書、報告書、請求書などの定型文書の処理や、大規模なドキュメントアーカイブのデジタル化プロジェクトで大きな価値を発揮します。Unity Catalogとの統合により、セキュアかつスケーラブルな処理が可能で、今後の機能拡張も期待されます。
是非ご活用ください!