こちらをDatabricksで動かします。playwrightを初めて触りました。面白い。
クラスターは16.3 MLシングルノードです。サーバレスだとplaywrightのインストールがうまくいきませんでした。
Web Voyager
WebVoyager by He, et. al., は、マウスとキーボードを制御できるビジョン対応のウェブブラウジングエージェントです。
このエージェントは、各ターンごとに注釈付きのブラウザスクリーンショットを見て、次に取るべきステップを選択します。エージェントのアーキテクチャは基本的な推論とアクション(ReAct)ループです。このエージェントのユニークな点は次の通りです:
- エージェントのUIアフォーダンスとしてSet-of-Marksのような画像注釈を使用すること
- マウスとキーボードの両方を制御するツールを使用してブラウザに適用すること
全体的なデザインは次のようになります:

セットアップ
%%capture --no-stderr
%pip install -U --quiet langgraph langsmith langchain_openai langchain
%restart_python
エージェントの要件をインストール
唯一の追加要件はplaywrightブラウザです。
%pip install --upgrade --quiet playwright > /dev/null
!playwright install
!playwright install-deps
今回はLangSmithでトレースを見ます。
import os
os.environ["OPENAI_API_KEY"] = dbutils.secrets.get(scope="demo-token-takaaki.yayoi", key="openai_api_key")
os.environ["LANGCHAIN_TRACING"]="true"
os.environ["LANGCHAIN_API_KEY"]="<LangSmithのAPIキー>"
import nest_asyncio
# Jupyterノートブックで非同期playwrightを実行するために必要です
nest_asyncio.apply()
ヘルパーファイル
このチュートリアルでは、いくつかのJSコードを使用します。これをmark_page.jsというファイルに保存し、このチュートリアルを実行しているノートブックと同じディレクトリに配置してください。
const customCSS = `
::-webkit-scrollbar {
width: 10px;
}
::-webkit-scrollbar-track {
background: #27272a;
}
::-webkit-scrollbar-thumb {
background: #888;
border-radius: 0.375rem;
}
::-webkit-scrollbar-thumb:hover {
background: #555;
}
`;
const styleTag = document.createElement("style");
styleTag.textContent = customCSS;
document.head.append(styleTag);
let labels = [];
function unmarkPage() {
// Unmark page logic
for (const label of labels) {
document.body.removeChild(label);
}
labels = [];
}
function markPage() {
unmarkPage();
var bodyRect = document.body.getBoundingClientRect();
var items = Array.prototype.slice
.call(document.querySelectorAll("*"))
.map(function (element) {
var vw = Math.max(
document.documentElement.clientWidth || 0,
window.innerWidth || 0
);
var vh = Math.max(
document.documentElement.clientHeight || 0,
window.innerHeight || 0
);
var textualContent = element.textContent.trim().replace(/\s{2,}/g, " ");
var elementType = element.tagName.toLowerCase();
var ariaLabel = element.getAttribute("aria-label") || "";
var rects = [...element.getClientRects()]
.filter((bb) => {
var center_x = bb.left + bb.width / 2;
var center_y = bb.top + bb.height / 2;
var elAtCenter = document.elementFromPoint(center_x, center_y);
return elAtCenter === element || element.contains(elAtCenter);
})
.map((bb) => {
const rect = {
left: Math.max(0, bb.left),
top: Math.max(0, bb.top),
right: Math.min(vw, bb.right),
bottom: Math.min(vh, bb.bottom),
};
return {
...rect,
width: rect.right - rect.left,
height: rect.bottom - rect.top,
};
});
var area = rects.reduce((acc, rect) => acc + rect.width * rect.height, 0);
return {
element: element,
include:
element.tagName === "INPUT" ||
element.tagName === "TEXTAREA" ||
element.tagName === "SELECT" ||
element.tagName === "BUTTON" ||
element.tagName === "A" ||
element.onclick != null ||
window.getComputedStyle(element).cursor == "pointer" ||
element.tagName === "IFRAME" ||
element.tagName === "VIDEO",
area,
rects,
text: textualContent,
type: elementType,
ariaLabel: ariaLabel,
};
})
.filter((item) => item.include && item.area >= 20);
// Only keep inner clickable items
items = items.filter(
(x) => !items.some((y) => x.element.contains(y.element) && !(x == y))
);
// Function to generate random colors
function getRandomColor() {
var letters = "0123456789ABCDEF";
var color = "#";
for (var i = 0; i < 6; i++) {
color += letters[Math.floor(Math.random() * 16)];
}
return color;
}
// Lets create a floating border on top of these elements that will always be visible
items.forEach(function (item, index) {
item.rects.forEach((bbox) => {
newElement = document.createElement("div");
var borderColor = getRandomColor();
newElement.style.outline = `2px dashed ${borderColor}`;
newElement.style.position = "fixed";
newElement.style.left = bbox.left + "px";
newElement.style.top = bbox.top + "px";
newElement.style.width = bbox.width + "px";
newElement.style.height = bbox.height + "px";
newElement.style.pointerEvents = "none";
newElement.style.boxSizing = "border-box";
newElement.style.zIndex = 2147483647;
// newElement.style.background = `${borderColor}80`;
// Add floating label at the corner
var label = document.createElement("span");
label.textContent = index;
label.style.position = "absolute";
// These we can tweak if we want
label.style.top = "-19px";
label.style.left = "0px";
label.style.background = borderColor;
// label.style.background = "black";
label.style.color = "white";
label.style.padding = "2px 4px";
label.style.fontSize = "12px";
label.style.borderRadius = "2px";
newElement.appendChild(label);
document.body.appendChild(newElement);
labels.push(newElement);
// item.element.setAttribute("-ai-label", label.textContent);
});
});
const coordinates = items.flatMap((item) =>
item.rects.map(({ left, top, width, height }) => ({
x: (left + left + width) / 2,
y: (top + top + height) / 2,
type: item.type,
text: item.text,
ariaLabel: item.ariaLabel,
}))
);
return coordinates;
}
グラフの定義
グラフの状態を定義
状態はグラフ内の各ノードへの入力を提供します。
この場合、エージェントはウェブページオブジェクト(ブラウザ内)、注釈付き画像とバウンディングボックス、ユーザーの初期リクエスト、およびエージェントのスクラッチパッド、システムプロンプト、その他の情報を含むメッセージを追跡します。
from typing import List, Optional
from typing_extensions import TypedDict
from langchain_core.messages import BaseMessage, SystemMessage
from playwright.async_api import Page
class BBox(TypedDict):
x: float
y: float
text: str
type: str
ariaLabel: str
class Prediction(TypedDict):
action: str
args: Optional[List[str]]
# これはエージェントの状態を表します
# 実行を進める際の状態
class AgentState(TypedDict):
page: Page # Playwrightのウェブページはウェブ環境と対話することを可能にします
input: str # ユーザーリクエスト
img: str # b64エンコードされたスクリーンショット
bboxes: List[BBox] # ブラウザの注釈機能からのバウンディングボックス
prediction: Prediction # エージェントの出力
# 中間ステップを含むシステムメッセージ(またはメッセージ)
scratchpad: List[BaseMessage]
observation: str # ツールからの最新の応答
ツールの定義
エージェントには6つのシンプルなツールがあります:
- (ラベル付きボックスで)クリック
- 入力
- スクロール
- 待機
- 戻る
- Databricksマニュアルページに移動
以下に関数として定義します:
元々はGoogleを使っていますが、CAPTHAが出るのでDatabricksマニュアルページにしています。
import asyncio
import platform
async def click(state: AgentState):
# - クリック [数値ラベル]
page = state["page"]
click_args = state["prediction"]["args"]
if click_args is None or len(click_args) != 1:
return f"数値ラベル {click_args} のバウンディングボックスをクリックできませんでした"
bbox_id = click_args[0]
bbox_id = int(bbox_id)
try:
bbox = state["bboxes"][bbox_id]
except Exception:
return f"エラー: バウンディングボックスがありません: {bbox_id}"
x, y = bbox["x"], bbox["y"]
await page.mouse.click(x, y)
# TODO: 論文では、ダウンロードされたPDFを自動的に解析しています
# ここでも同様の機能を追加し、応答形式を改善することができます。
return f"{bbox_id} をクリックしました"
async def type_text(state: AgentState):
page = state["page"]
type_args = state["prediction"]["args"]
if type_args is None or len(type_args) != 2:
return (
f"数値ラベル {type_args} のバウンディングボックスにテキストを入力できませんでした"
)
bbox_id = type_args[0]
bbox_id = int(bbox_id)
bbox = state["bboxes"][bbox_id]
x, y = bbox["x"], bbox["y"]
text_content = type_args[1]
await page.mouse.click(x, y)
# MacOSかどうかをチェック
select_all = "Meta+A" if platform.system() == "Darwin" else "Control+A"
await page.keyboard.press(select_all)
await page.keyboard.press("Backspace")
await page.keyboard.type(text_content)
await page.keyboard.press("Enter")
return f"{text_content} を入力して送信しました"
async def scroll(state: AgentState):
page = state["page"]
scroll_args = state["prediction"]["args"]
if scroll_args is None or len(scroll_args) != 2:
return "引数が正しくないためスクロールできませんでした。"
target, direction = scroll_args
if target.upper() == "WINDOW":
# 最適な値が不明です:
scroll_amount = 500
scroll_direction = (
-scroll_amount if direction.lower() == "up" else scroll_amount
)
await page.evaluate(f"window.scrollBy(0, {scroll_direction})")
else:
# 特定の要素内でスクロール
scroll_amount = 200
target_id = int(target)
bbox = state["bboxes"][target_id]
x, y = bbox["x"], bbox["y"]
scroll_direction = (
-scroll_amount if direction.lower() == "up" else scroll_amount
)
await page.mouse.move(x, y)
await page.mouse.wheel(0, scroll_direction)
return f"{'window' if target.upper() == 'WINDOW' else 'element'} 内を {direction} にスクロールしました"
async def wait(state: AgentState):
sleep_time = 5
await asyncio.sleep(sleep_time)
return f"{sleep_time}秒待ちました。"
async def go_back(state: AgentState):
page = state["page"]
await page.go_back()
return f"{page.url} に戻りました。"
async def to_databricks_doc(state: AgentState):
page = state["page"]
await page.goto("https://docs.databricks.com/aws/ja/")
return "docs.databricks.com に移動しました。"
エージェントの定義
エージェントはマルチモーダルモデルによって駆動され、各ステップで取るべきアクションを決定します。いくつかの実行可能なオブジェクトで構成されています:
- 現在のページにバウンディングボックスを注釈する
mark_page関数 - ユーザーの質問、注釈付き画像、およびエージェントのスクラッチパッドを保持するプロンプト
- 次のステップを決定するための gpt-4o
- アクションを抽出するための解析ロジック
まず注釈ステップを定義しましょう:
ブラウザ注釈
この関数は、すべてのボタン、入力、テキストエリアなどに番号付きバウンディングボックスを注釈します。gpt-4o はアクションを取る際にバウンディングボックスを参照するだけで済み、全体のタスクの複雑さが軽減されます。
import base64
from langchain_core.runnables import chain as chain_decorator
# 各ステップで実行するJavaScript
# ページのスクリーンショットを撮り、注釈を付ける要素を選択し、
# バウンディングボックスを追加します
with open("mark_page.js") as f:
mark_page_script = f.read()
@chain_decorator
async def mark_page(page):
await page.evaluate(mark_page_script)
for _ in range(10):
try:
bboxes = await page.evaluate("markPage()")
break
except Exception:
# 読み込み中かもしれません...
asyncio.sleep(3)
screenshot = await page.screenshot()
# バウンディングボックスが残らないようにします
await page.evaluate("unmarkPage()")
return {
"img": base64.b64encode(screenshot).decode(),
"bboxes": bboxes,
}
エージェントの定義
次に、この関数をプロンプト、llm、および出力パーサーと組み合わせてエージェントを完成させます。
from langchain import hub
from langchain_core.output_parsers import StrOutputParser
from langchain_core.runnables import RunnablePassthrough
from langchain_openai import ChatOpenAI
async def annotate(state):
marked_page = await mark_page.with_retry().ainvoke(state["page"])
return {**state, **marked_page}
def format_descriptions(state):
labels = []
for i, bbox in enumerate(state["bboxes"]):
text = bbox.get("ariaLabel") or ""
if not text.strip():
text = bbox["text"]
el_type = bbox.get("type")
labels.append(f'{i} (<{el_type}/>): "{text}"')
bbox_descriptions = "\nValid Bounding Boxes:\n" + "\n".join(labels)
return {**state, "bbox_descriptions": bbox_descriptions}
def parse(text: str) -> dict:
action_prefix = "Action: "
if not text.strip().split("\n")[-1].startswith(action_prefix):
return {"action": "retry", "args": f"Could not parse LLM Output: {text}"}
action_block = text.strip().split("\n")[-1]
action_str = action_block[len(action_prefix) :]
split_output = action_str.split(" ", 1)
if len(split_output) == 1:
action, action_input = split_output[0], None
else:
action, action_input = split_output
action = action.strip()
if action_input is not None:
action_input = [
inp.strip().strip("[]") for inp in action_input.strip().split(";")
]
return {"action": action, "args": action_input}
# この画像プロンプトテンプレートを取得するために新しいバージョンのlangchainが必要
prompt = hub.pull("wfh/web-voyager")
llm = ChatOpenAI(model="gpt-4o", max_tokens=4096)
agent = annotate | RunnablePassthrough.assign(
prediction=format_descriptions | prompt | llm | StrOutputParser() | parse
)
グラフのコンパイル
ほとんどの重要なロジックを作成しました。ツールが呼び出された後にグラフの状態を更新するのに役立つもう1つの関数を定義する必要があります。
import re
def update_scratchpad(state: AgentState):
"""ツールが呼び出された後、エージェントが以前のステップを認識できるようにスクラッチパッドを更新します"""
old = state.get("scratchpad")
if old:
txt = old[0].content
last_line = txt.rsplit("\n", 1)[-1]
step = int(re.match(r"\d+", last_line).group()) + 1
else:
txt = "以前のアクションの観察結果:\n"
step = 1
txt += f"\n{step}. {state['observation']}"
return {**state, "scratchpad": [SystemMessage(content=txt)]}
これで、すべてをグラフにまとめることができます:
from langchain_core.runnables import RunnableLambda
from langgraph.graph import END, START, StateGraph
graph_builder = StateGraph(AgentState)
graph_builder.add_node("agent", agent)
graph_builder.add_edge(START, "agent")
graph_builder.add_node("update_scratchpad", update_scratchpad)
graph_builder.add_edge("update_scratchpad", "agent")
tools = {
"Click": click,
"Type": type_text,
"Scroll": scroll,
"Wait": wait,
"GoBack": go_back,
"Databricks": to_databricks_doc,
}
for node_name, tool in tools.items():
graph_builder.add_node(
node_name,
# ラムダは関数の文字列出力がAgentStateの"observation"キーにマッピングされることを保証します
RunnableLambda(tool) | (lambda observation: {"observation": observation}),
)
# 常にエージェントに戻る(update-scratchpadノードを介して)
graph_builder.add_edge(node_name, "update_scratchpad")
def select_tool(state: AgentState):
# エージェントが完了するたびに、この関数が呼び出され、
# 出力をツールまたはエンドユーザーにルーティングします。
action = state["prediction"]["action"]
if action == "ANSWER":
return END
if action == "retry":
return "agent"
return action
graph_builder.add_conditional_edges("agent", select_tool)
graph = graph_builder.compile()
グラフを可視化します。
from IPython.display import Image, display
from langchain_core.runnables.graph import CurveStyle, MermaidDrawMethod, NodeStyles
display(
Image(
graph.get_graph().draw_mermaid_png(
draw_method=MermaidDrawMethod.API,
)
)
)

グラフの使用
エージェントエグゼキュータ全体を作成したので、いくつかの質問で実行してみましょう!最初に docs.databricks.com/aws/ja/ でブラウザを起動し、その後はそれが残りを制御します。
以下は、ノートブックにステップを印刷し(および中間スクリーンショットを表示)するのに役立つヘルパー関数です。
from IPython import display
from playwright.async_api import async_playwright
import random
browser = await async_playwright().start()
# Databricksの場合、ヘッドレスモードをTrueにしないと動きませんでした。
browser = await browser.chromium.launch(headless=True, args=None)
page = await browser.new_page()
_ = await page.goto("https://docs.databricks.com/aws/ja/")
async def call_agent(question: str, page, max_steps: int = 150):
event_stream = graph.astream(
{
"page": page,
"input": question,
"scratchpad": [],
},
{
"recursion_limit": max_steps,
},
)
final_answer = None
steps = []
async for event in event_stream:
# ここでイベントストリームを表示します
if "agent" not in event:
continue
pred = event["agent"].get("prediction") or {}
action = pred.get("action")
action_input = pred.get("args")
display.clear_output(wait=False)
steps.append(f"{len(steps) + 1}. {action}: {action_input}")
print("\n".join(steps))
display.display(display.Image(base64.b64decode(event["agent"]["img"])))
if "ANSWER" in action:
final_answer = action_input[0]
break
return final_answer
res = await call_agent("Delta Lakeを説明してください", page)
print(f"Final response: {res}")
1. Click: ['33']
2. ANSWER;: ['Delta Lakeは、Databricksのレイクハウスの基盤を提供するストレージレイヤーで、Parquetデータファイルを使ったACIDトランザクションとスケーラブルなメタデータ処理を実現します。Apache Spark APIとも互換性があり、大規模な増分処理が可能です。']

LangSmithでのトレースでも挙動を確認できます。
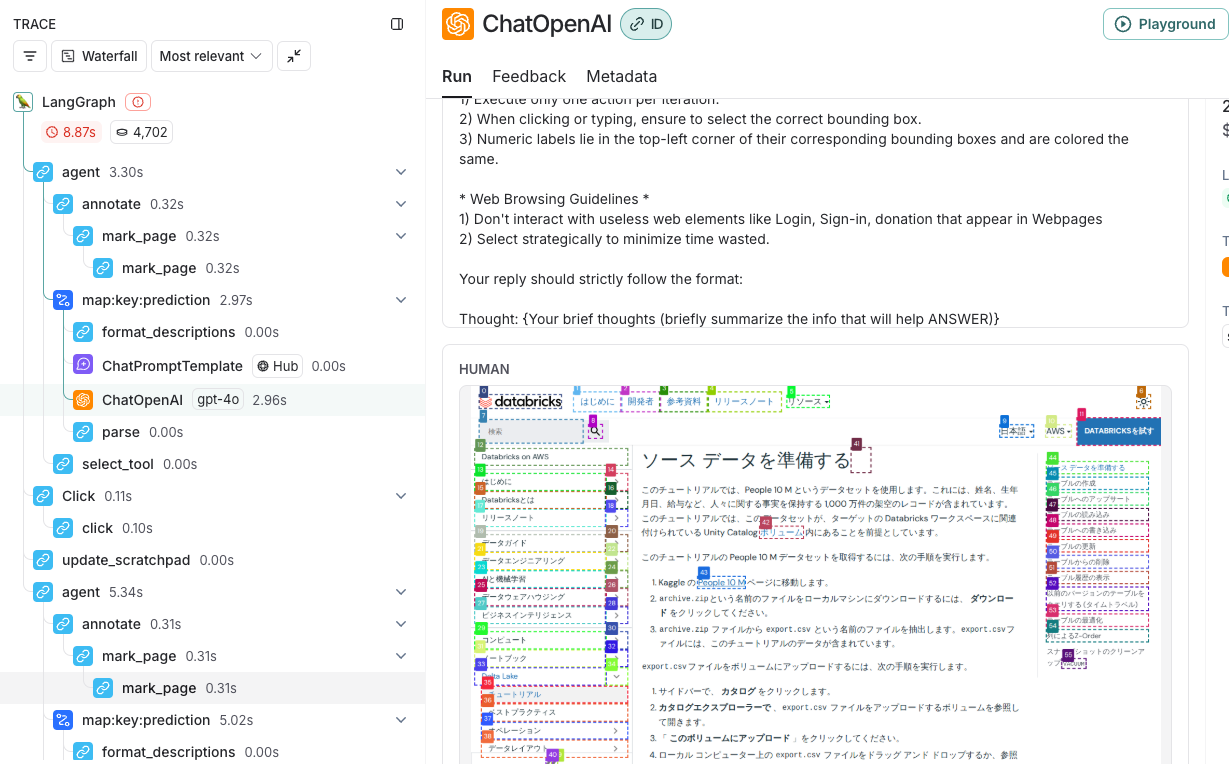
面白い。色々活用できそうです