はじめに
生成AIの「運用」を指す言葉は、今もって定まっていません。LLMOps、AgentOps、AIOps、AI Engineering、GenAIOps、PromptOps、呼び方は人や組織によってまちまちです。MLOpsという言葉が広く使われ始めてから10年近くが経ちますが、それでも組織における実践のあり方は今もって議論が続いています。
用語が乱立しているという事実そのものが、この分野がまだ黎明期にあることの証左です。 だからこそ、用語にこだわるよりも、その背後にある問題意識を整理することの方が今は重要だと感じています。
本記事では、私自身がLLMOps本を共著で執筆した立場から、便宜的に「LLMOps」という呼び方を選択します。これは「LLMOpsが正しい呼称だ」という主張ではなく、議論を始めるための仮の旗印です。読者の方が普段別の用語を使っているとしても、本記事で扱う問題意識の多くは共通するはずです。
AIエージェントブームの危うさ
まず現状認識から始めます。
エージェントを作れる人の裾野が、この1〜2年で一気に広がりました。これまで専門エンジニアの仕事だったAIアプリ開発が、ノーコードツール、簡易フレームワーク、コーディング支援AIの普及により、業務部門の担当者でも手を動かせる領域になっています。これ自体は喜ばしい変化です。
しかし副作用として、組織内で次のような状況が生まれつつあります。誰がどのエージェントを動かしているか把握できない。どのエージェントがどのデータにアクセスしているか追跡できない。コストが部署横断で予想を超えて積み上がる。品質が劣化しても誰も気付かない。問題が起きてから初めて存在を知る。
Microsoft ResearchのVictor Dibia氏が2025年に出版した『Designing Multi-Agent Systems: Principles, Patterns, and Implementation for AI Agents』では、多くの企業がマルチエージェント開発において評価を後回しにしていることを問題として指摘しています。フレームワーク選定や派手な機能実装には時間を割く一方で、「そのエージェントが実際にちゃんと動いているか」を測る仕組みは「後でやる」とされ、結果として後で取り返しがつかない技術的負債になる、という構造です。
この構造は、各企業内でも起きていることだと思います。とにかくエージェントを作って公開しろという号令が先にあり、評価・観測・改善の仕組みは後回しになる。数年経って、ガバナンスの効いていないエージェントが組織内に数百と乱立した時、それを一つひとつ評価・是正していくコストは、最初から評価駆動で進めた場合と比較にならないほど大きくなります。
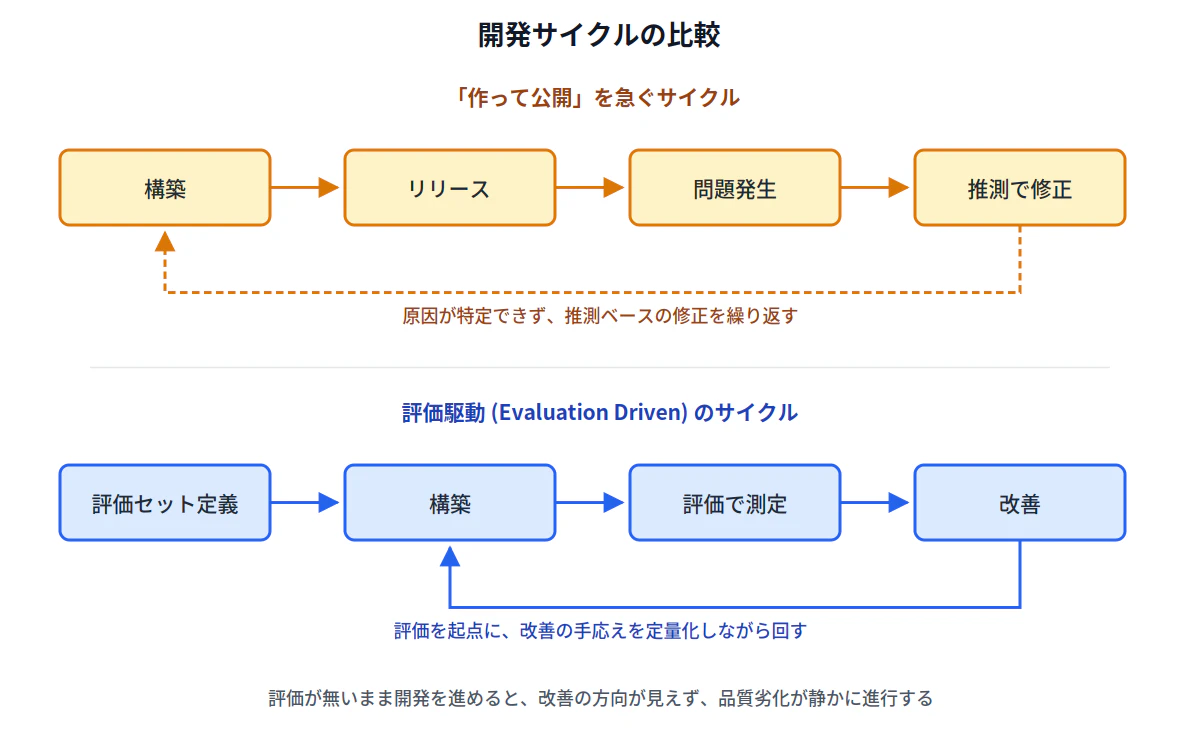
ここで描いた上下のサイクルは、似て非なるものです。前者は時間が経つほど技術的負債が累積し、後者は時間が経つほど評価セットと改善知見が累積していく。両者の差は、5年後の組織のAI活用能力に決定的な違いとして現れるはずです。
Evaluation-Driven Designという発想
ソフトウェア開発の世界には、Test Driven Development (TDD) という考え方が定着しています。テストを先に書き、そのテストを通すように実装を進める、という開発スタイルです。
生成AIの開発においても、これと同型の発想が必要だと考えています。Dibia氏は前掲書で "evaluation-driven design(評価駆動設計)" として、評価を起点に生成AIシステムを設計・運用することの重要性を繰り返し強調しています。本記事でもこの考え方を中心に据えて議論を進めます。
evaluation-driven designの核心は、評価を「あとから足すもの」ではなく「先に作るもの」として扱うことです。具体的には、まず何をもって「良い出力」とするかを言語化する。次に、それを測る評価セット (代表的な入力と、期待される性質のペア) を作る。その上で、評価セットに対するスコアを継続的に追いながら、プロンプトやパイプラインを改善していく、という流れになります。
このサイクルが回らないと、生成AIアプリの改善は「触ってみた感じが良い」という主観的判断に陥ります。何をどう変えると何が良くなるのか、定量的に確かめる手段がない。結果として、ある変更で改善された箇所と、引き換えに劣化した箇所のトレードオフを把握できないままリリースが続く。これが品質劣化の主因です。
評価設計で考えるべきことは、おおむね次の順序だと思います。
最初に、ユーザーにとっての「良い出力」を言語化する。これが曖昧なまま自動評価を作っても、何を最適化しているのか分からなくなります。次に、その言語化を分解可能な観点に落とす。正確性、簡潔さ、フォーマット遵守、安全性、それぞれを独立した評価軸として扱う。そして、各観点を測る評価器を実装する。ルールで測れるものはルールで、測れないものはモデルで (いわゆるLLM-as-a-Judge: LLMジャッジ)、最終的な妥当性は人手でサンプリング検証する、という三層構造が現実的です。
ここで強調したいのは、評価セットそのものが「アプリケーションと共に育つアーティファクト」だという点です。本番でユーザーが想定外の使い方をしたら、その失敗ケースを評価セットに追加する。評価セットが充実するほど、改善の手応えが定量化される。コードとデータと評価セットがセットで運用される、というのがこの発想の帰結です。
隣接する用語との関係を整理する
evaluation-driven designという発想を踏まえた上で、LLMOpsの位置付けをはっきりさせるため、隣接する用語を整理しておきます。
Context Engineering(コンテキストエンジニアリング)。 プロンプトという狭い概念ではなく、モデルに渡るコンテキスト全体、つまり検索結果、ツールの出力、過去の対話、メモリ、状態など、を意図的に設計するという考え方です。プロンプトエンジニアリングという言葉が個別のテキスト調整に矮小化されがちだったため、より広い設計領域を指す言葉として提唱されてきました。
Harness Engineering(ハーネスエンジニアリング)。 エージェントを支える「足場」、つまりツール群、評価器、安全装置、制御ループといった周辺装備をどう構築するかに焦点を当てた言葉です。モデルそのものではなく、モデルを取り囲む装備の方が結果を決める、という認識から生まれています。
これらは「作る側」の関心事です。LLMOpsが主に扱うのは「作ったものを動かし続ける側」の関心事ですが、両者は綺麗に分かれるものではありません。Context Engineeringで組み上げたコンテキスト設計が、本番環境で意図通り機能しているかを観測し、評価し、改善するのはLLMOpsの仕事です。Harness Engineeringで設計した評価器を、継続的に本番トラフィックに当て続けるのもLLMOpsの仕事です。
呼び方が違っても、生成AIアプリケーションを継続的に良くしていく営みのどこかの面を切り取っているに過ぎない、と捉えるのが健全だと思っています。
LLMOpsというコンセプトが狙っていること
LLMOpsが解こうとしているのは、煎じ詰めれば「生成AIを使ったシステムを、継続的に制御可能な状態に保つ」ことです。
「制御可能」というのは、観測できる、評価できる、改善できる、必要なら止められる、という四つの状態を指します。これらが揃っていないと、生成AIアプリは作った瞬間がピークで、運用するうちに何が起きているか分からなくなり、最終的にはユーザーの信頼を失います。
特徴的なのは、従来のソフトウェア運用と違って「正しく動いているかどうか」自体が自明ではない点です。出力は非決定的で、入力空間は事実上無限で、ユーザーは想定外の使い方をします。動いているように見えても、品質が静かに劣化していくことが起こり得ます。
LLMOpsの中心にある問いは、この「分からなさ」とどう付き合うかです。観測の解像度を上げ、評価を自動化し、変化を検知し、改善のループを回す。地味で愚直な営みですが、これを抜きに生成AIアプリを本番で運用することはできません。
現時点で確立されつつある手立て
では、現状のLLMOpsで「ここは固まってきた」と言える領域は何でしょうか。私の見立てでは、次の構成要素はほぼ共通理解になりつつあります。

トレーシング、つまり生成AIアプリの実行を構造化された軌跡として記録すること。各ステップの入力、出力、レイテンシ、トークン消費、コストを後から辿れる形で残す。これがなければ他のすべてが手探りになるため、最初に整備すべき層と言われています。
評価。データセットを使った開発時のオフライン評価と、本番トラフィックを対象としたオンライン評価の二軸。評価手段としてはルールベース、モデルベース (LLM-as-a-Judge)、人手評価の三層を組み合わせる構成が一般的です。
プロンプト管理。プロンプトをコードから分離し、バージョン管理し、評価結果と紐付けて比較できるようにする。エンジニア以外も改善サイクルに参加できるようにする狙いもあります。
実験管理。プロンプト、モデル、パイプライン構成のどれを変えたら何が改善したのかを体系的に記録する。MLOpsの実験管理の対象を生成AI向けに拡張したもの、と捉えると分かりやすいです。
ゲートウェイ的な提供層。複数のモデルプロバイダの抽象化、レート制限、コスト可視化、フォールバック。組織内に複数のAIアプリが立ち上がってきた段階で効いてきます。
ガードレール。入出力の安全性チェックを実行時に行う仕組み。リアルタイムに動く評価器、と理解すると見通しが良くなります。
これらは個別のプロダクトに依存せず、概念として「ここは押さえるべき」とコミュニティの共通認識になりつつある領域です。逆に言うと、これより細かいレベルの話、たとえば具体的なツール選定や実装パターンは、まだベストプラクティスが流動的です。
これから固まっていく方向性
LLMOpsの次の主戦場は、エージェントの軌跡 (trajectory) をどう扱うかにあると考えています。
単発の質問応答であれば、評価の対象は最終出力でした。しかしエージェントが普及すると、評価の対象は「最終的に正しい答えに辿り着いたか」だけでなく「どういうプロセスでそこに至ったか」に広がります。
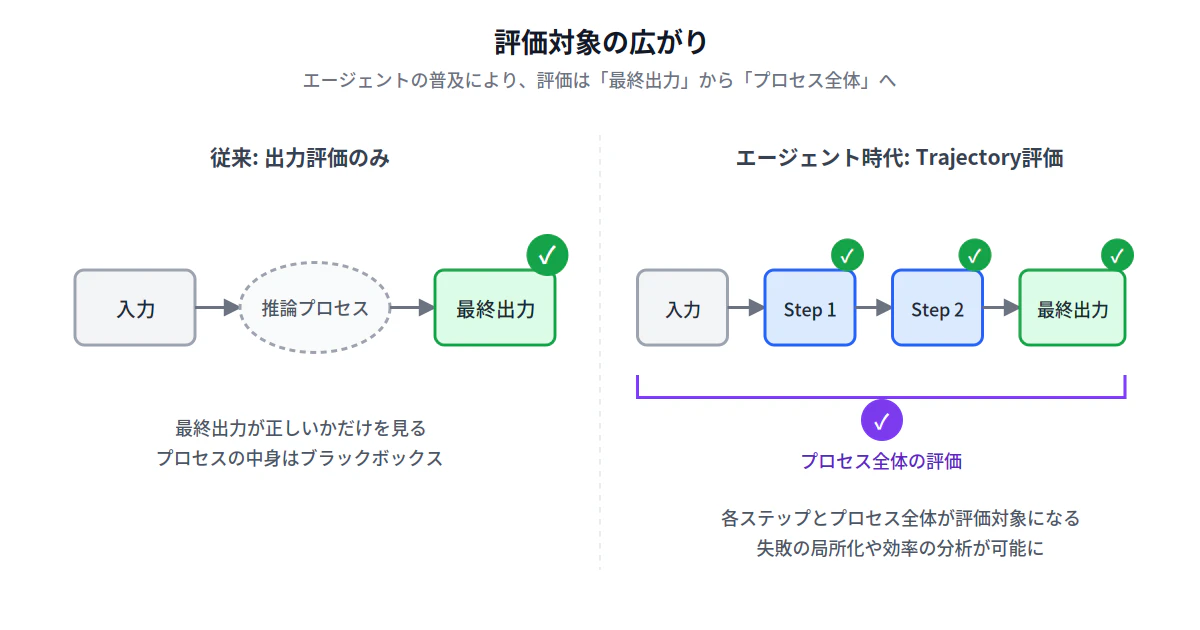
最終回答が正しくても、そこに至るまでに10回不要なツール呼び出しをしていたら効率が悪い。最終回答が間違っていたとしても、推論プロセスの大半は正しく、ある一箇所のミスだけが原因ということもある。プロセスの正しさを評価できなければ、エージェントを改善するための情報が決定的に不足します。
Dibia氏の本でも、Trajectory-based testingが重要なテーマとして扱われています。これを支えるのが、エージェントの軌跡を構造化された形で記録し、軌跡そのものを評価対象として扱える基盤です。軌跡のどの部分が問題だったかを特定する、似たパターンの軌跡をクラスタリングする、軌跡を入力としたLLM-as-a-Judgeで定型的な失敗パターンを検出する、といった営みがこれから一般的になっていくでしょう。
加えて、エージェント間の連携 (一つのタスクを複数のエージェントが分担して進める) が広がると、観測や評価の単位はさらに広がります。組織横断的なエージェントの動きをガバナンスする、という大きな問題が次に控えています。
その意味で、現在のLLMOpsは「単発の生成AIアプリを運用する」フェーズから「自律的に動くエージェント群を統制する」フェーズへの過渡期にあります。用語が固まらないのも、対象そのものが急速に変わっているからだと思います。
おわりに
「LLMOpsは何を解こうとしているのか」という問いに、現時点での自分なりの答えを書いてきました。
それは、生成AIを使ったシステムを継続的に制御可能な状態に保つことであり、その中核にはDibia氏が示すevaluation-driven designの実践があります。エージェント時代に入ってその対象は最終出力からプロセス全体へと広がりつつあり、組織横断的なガバナンスという次の課題もすでに見え始めています。
用語はこれからも変わっていくでしょうし、構成要素のどれかが大きく組み替えられる可能性もあります。しかし、観測し、評価し、制御可能にしておく、という根っこの問題意識は当面変わらないだろうと思っています。
「とにかくエージェントを作って公開しろ」という空気が強い時期だからこそ、評価を先に作るという地味で愚直な発想を、組織として持っておくことが重要だと感じています。数年経ってから「あのとき評価を整備しておけば」と振り返らずに済むように。
具体的なツールに沿った実装の話は、別の記事や書籍に譲ります。MLflowに焦点を当てた実践書として、共著で『MLflowで実践するLLMOps──生成AIアプリケーションの実験管理と品質保証』 (技術評論社、2026年) を出版しました。本記事で挙げた構成要素について、具体的にどう実装し運用するかを知りたい方は、そちらも併せて参照いただければ嬉しいです。
参考文献
- Victor Dibia, Designing Multi-Agent Systems: Principles, Patterns, and Implementation for AI Agents (2025)
- 弥生隆明、渡辺祐貴、大内山浩、平田東夢、河村春孝『MLflowで実践するLLMOps──生成AIアプリケーションの実験管理と品質保証』技術評論社、2026年