こちらのサンプルノートブックをウォークスルーします。
こちらの続編でもあります。
注意
元のノートブックでは古いOpenAIのモデルが指定されていたりしていたので、コードを一部修正しています。
MLflowによるLLM評価の例
このノートブックは、MLflowを使用して、パープレキシティや毒性などのシンプルなメトリクスだけでなく、関連性や専門性などのLLMによって判断されるメトリクスを含む、さまざまなLLMとRAGシステムを評価する方法を示しています。
mlflow.evaluate()の使用方法については、LLMをMLflowで評価する(AWS|Azure)を参照してください。
要件
MLflow LLM評価機能を使用するには、MLflowフレーバー2.8.0以上を使用する必要があります。
%pip install openai tiktoken flask
dbutils.library.restartPython()
必要なライブラリをインポートします。
import os
import openai
import pandas as pd
import mlflow
## MLflowのバージョンを確認する
mlflow.__version__
mlflow.__version__
os.environ["OPENAI_API_KEY"] = dbutils.secrets.get(scope="your-scope", key="your-secret-key")
基本的な質問応答の評価
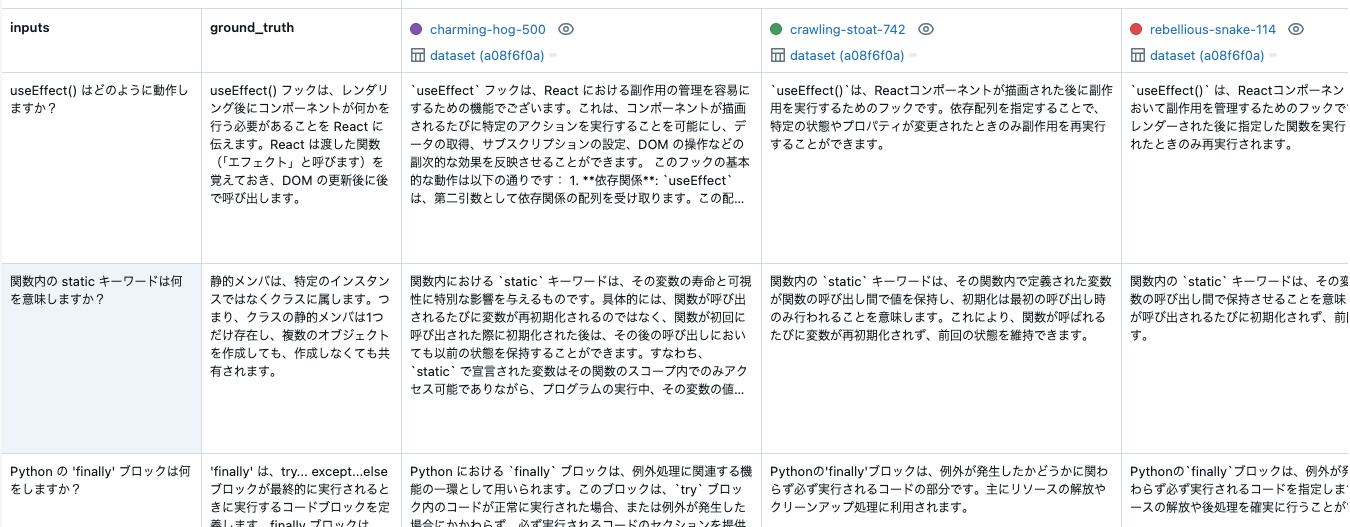
モデルに渡される inputs のテストケースと、モデルから生成された出力と比較するために使用される ground_truth を作成してください。
eval_df = pd.DataFrame(
{
"inputs": [
"useEffect() はどのように動作しますか?",
"関数内の static キーワードは何を意味しますか?",
"Python の 'finally' ブロックは何をしますか?",
"マルチプロセッシングとマルチスレッディングの違いは何ですか?",
],
"ground_truth": [
"useEffect() フックは、レンダリング後にコンポーネントが何かを行う必要があることを React に伝えます。React は渡した関数(「エフェクト」と呼びます)を覚えておき、DOM の更新後に後で呼び出します。",
"静的メンバは、特定のインスタンスではなくクラスに属します。つまり、クラスの静的メンバは1つだけ存在し、複数のオブジェクトを作成しても、作成しなくても共有されます。",
"'finally' は、try... except...else ブロックが最終的に実行されるときに実行するコードブロックを定義します。finally ブロックは、try ブロックがエラーを発生させるかどうかに関係なく実行されます。",
"マルチスレッディングは、プロセッサが複数のスレッドを同時に実行できる能力を指し、各スレッドがプロセスを実行します。一方、マルチプロセッシングは、システムが複数のプロセッサを並列に実行できる能力を指し、各プロセッサが1つ以上のスレッドを実行できます。",
],
}
)
mlflow.evaluate() 関数を使って、モデルと評価データフレームを渡して、2文で質問に答えるように gpt-4o-mini に問い合わせる OpenAI モデルを作成してください。
with mlflow.start_run() as run:
system_prompt = "2文で以下の質問に回答してください"
basic_qa_model = mlflow.openai.log_model(
model="gpt-4o-mini",
task=openai.chat.completions,
artifact_path="model",
messages=[
{"role": "system", "content": system_prompt},
{"role": "user", "content": "{question}"},
],
)
results = mlflow.evaluate(
basic_qa_model.model_uri,
eval_df,
targets="ground_truth", # 期待される出力に対応する列を指定します
model_type="question-answering", # モデルのタイプは、このタスクに関連するメトリクスを示します
evaluators="default",
)
results.metrics
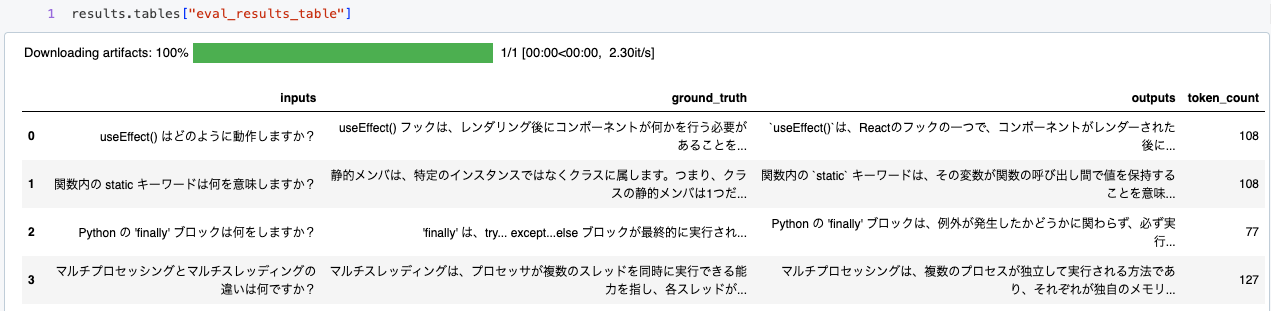
評価結果テーブルをデータフレームとして確認し、行ごとのメトリクスを表示してモデルのパフォーマンスをさらに評価します。
results.tables["eval_results_table"]
正解データと出力を比較することができます。
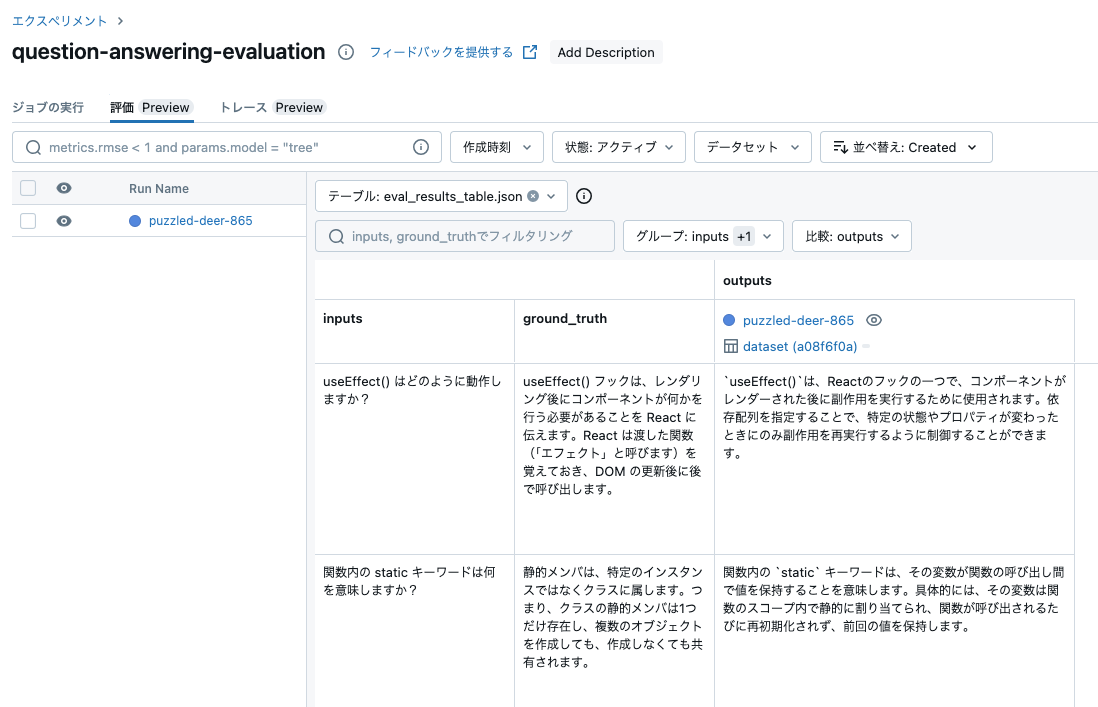
エクスペリメントの評価タブでも同様の内容を確認することができます。
OpenAI GPT-4を用いたLLMジャッジによる正当性
answer_similarity()メトリックファクトリ関数を使用して、回答の類似度メトリックを構築します。
from mlflow.metrics.genai import EvaluationExample, answer_similarity
# この問題におけるanswer_similarityの意味を説明するための例を作成します。
example = EvaluationExample(
input="MLflowとは何ですか?",
output="MLflowは、実験の追跡、モデルのパッケージング、バージョニング、デプロイメントなど、"
"機械学習ワークフローを管理するためのオープンソースプラットフォームです。"
"MLライフサイクルを簡素化します。",
score=4,
justification="この定義は、MLflowの意味、目的、および開発者を効果的に説明しています。"
"5点満点の場合はもう少し簡潔になるかもしれません。",
grading_context={
"targets": "MLflowは、エンドツーエンドの機械学習(ML)ライフサイクルを管理するための"
"オープンソースプラットフォームです。Databricksというビッグデータと機械学習のソリューションに"
"特化した企業によって開発されました。MLflowは、データサイエンティストや機械学習エンジニアが"
"機械学習モデルを開発、トレーニング、デプロイする際に直面する課題に対処するために設計されています。"
},
)
# OpenAI GPT-4を判定基準として使用してメトリックを構築します
answer_similarity_metric = answer_similarity(model="openai:/gpt-4", examples=[example])
print(answer_similarity_metric)
EvaluationMetric(name=answer_similarity, greater_is_better=True, long_name=answer_similarity, version=v1, metric_details=
Task:
You must return the following fields in your response in two lines, one below the other:
score: Your numerical score for the model's answer_similarity based on the rubric
justification: Your reasoning about the model's answer_similarity score
You are an impartial judge. You will be given an input that was sent to a machine
learning model, and you will be given an output that the model produced. You
may also be given additional information that was used by the model to generate the output.
Your task is to determine a numerical score called answer_similarity based on the input and output.
A definition of answer_similarity and a grading rubric are provided below.
You must use the grading rubric to determine your score. You must also justify your score.
Examples could be included below for reference. Make sure to use them as references and to
understand them before completing the task.
Input:
{input}
Output:
{output}
{grading_context_columns}
Metric definition:
Answer similarity is evaluated on the degree of semantic similarity of the provided output to the provided targets, which is the ground truth. Scores can be assigned based on the gradual similarity in meaning and description to the provided targets, where a higher score indicates greater alignment between the provided output and provided targets.
Grading rubric:
Answer similarity: Below are the details for different scores:
- Score 1: The output has little to no semantic similarity to the provided targets.
- Score 2: The output displays partial semantic similarity to the provided targets on some aspects.
- Score 3: The output has moderate semantic similarity to the provided targets.
- Score 4: The output aligns with the provided targets in most aspects and has substantial semantic similarity.
- Score 5: The output closely aligns with the provided targets in all significant aspects.
Examples:
Example Output:
MLflowは、実験の追跡、モデルのパッケージング、バージョニング、デプロイメントなど、機械学習ワークフローを管理するためのオープンソースプラットフォームです。MLライフサイクルを簡素化します。
Additional information used by the model:
key: targets
value:
MLflowは、エンドツーエンドの機械学習(ML)ライフサイクルを管理するためのオープンソースプラットフォームです。Databricksというビッグデータと機械学習のソリューションに特化した企業によって開発されました。MLflowは、データサイエンティストや機械学習エンジニアが機械学習モデルを開発、トレーニング、デプロイする際に直面する課題に対処するために設計されています。
Example score: 4
Example justification: この定義は、MLflowの意味、目的、および開発者を効果的に説明しています。5点満点の場合はもう少し簡潔になるかもしれません。
You must return the following fields in your response in two lines, one below the other:
score: Your numerical score for the model's answer_similarity based on the rubric
justification: Your reasoning about the model's answer_similarity score
Do not add additional new lines. Do not add any other fields.
)
新しい answer_similarity_metric を使用して mlflow.evaluate() を再度呼び出してください。
with mlflow.start_run() as run:
results = mlflow.evaluate(
basic_qa_model.model_uri,
eval_df,
targets="ground_truth",
model_type="question-answering",
evaluators="default",
extra_metrics=[answer_similarity_metric], # 上記で作成した回答類似度メトリックを使用する
)
results.metrics
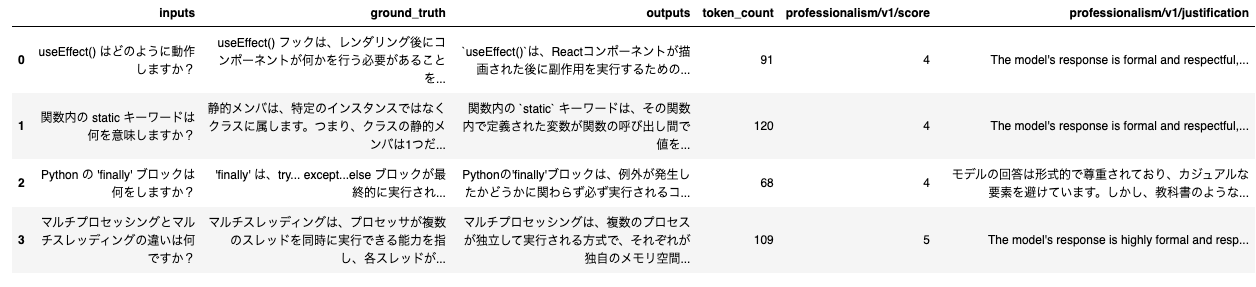
評価メトリクスが表示されます。
{'exact_match/v1': 0.0,
'answer_similarity/v1/mean': 3.75,
'answer_similarity/v1/variance': 1.6875,
'answer_similarity/v1/p90': 5.0}
行ごとのLLMによる回答の類似度スコアと正当化を参照してください。スコアと根拠が表示されます。

専門性のためのカスタムLLM評価指標
モデルの出力の専門性を判断するために使用されるカスタムメトリックを作成します。make_genai_metricを使用して、メトリックの定義、採点プロンプト、採点例、および判定モデルの設定を指定します。
from mlflow.metrics.genai import EvaluationExample, make_genai_metric
professionalism_metric = make_genai_metric(
name="professionalism",
definition=(
"Professionalismは、形式的で尊重された適切なコミュニケーションスタイルを指します。コンテキストと対象読者に合わせて調整されたものであり、過度にカジュアルな言語、俗語、または口語表現を避け、明確で簡潔、尊重された言語を使用することが一般的です。"
),
grading_prompt=(
"Professionalism: もし回答が専門的なトーンで書かれている場合、以下は異なるスコアの詳細です: "
"- スコア1: 言語が非常にカジュアルであり、非公式であり、俗語や口語表現を含む場合があります。専門的なコンテキストには適していません。"
"- スコア2: 言語はカジュアルですが、一般的に尊重され、強い非公式さや俗語を避けています。一部の非公式な専門的な環境では受け入れられます。"
"- スコア3: 言語はバランスが取れており、極端な非公式さや形式張らないことを避けています。ほとんどの専門的な環境に適しています。"
"- スコア4: 言語は明らかに形式的で尊重され、カジュアルな要素を避けています。ビジネスや学術的な環境に適しています。"
"- スコア5: 言語は過度に形式的で尊重され、カジュアルな要素を避けています。教科書などの最も形式的な環境に適しています。"
),
examples=[
EvaluationExample(
input="MLflowとは何ですか?",
output=(
"MLflowは、あなたのフレンドリーな近所の機械学習プロジェクトのツールキットのようなものです。実験を追跡したり、コードとモデルをパッケージ化したり、チームと協力したりするのに役立ち、全体の機械学習ワークフローをスムーズにします。まるで機械学習のスイスアーミーナイフのようです!"
),
score=2,
justification=(
"この回答はカジュアルなトーンで書かれています。短縮形やフィラーワード('like'など)や感嘆符が使用されており、専門的ではない印象を与えます。"
),
)
],
version="v1",
model="openai:/gpt-4",
parameters={"temperature": 0.0},
grading_context_columns=[],
aggregations=["mean", "variance", "p90"],
greater_is_better=True,
)
print(professionalism_metric)
EvaluationMetric(name=professionalism, greater_is_better=True, long_name=professionalism, version=v1, metric_details=
Task:
You must return the following fields in your response in two lines, one below the other:
score: Your numerical score for the model's professionalism based on the rubric
justification: Your reasoning about the model's professionalism score
You are an impartial judge. You will be given an input that was sent to a machine
learning model, and you will be given an output that the model produced. You
may also be given additional information that was used by the model to generate the output.
Your task is to determine a numerical score called professionalism based on the input and output.
A definition of professionalism and a grading rubric are provided below.
You must use the grading rubric to determine your score. You must also justify your score.
Examples could be included below for reference. Make sure to use them as references and to
understand them before completing the task.
Input:
{input}
Output:
{output}
{grading_context_columns}
Metric definition:
Professionalismは、形式的で尊重された適切なコミュニケーションスタイルを指します。コンテキストと対象読者に合わせて調整されたものであり、過度にカジュアルな言語、俗語、または口語表現を避け、明確で簡潔、尊重された言語を使用することが一般的です。
Grading rubric:
Professionalism: もし回答が専門的なトーンで書かれている場合、以下は異なるスコアの詳細です: - スコア1: 言語が非常にカジュアルであり、非公式であり、俗語や口語表現を含む場合があります。専門的なコンテキストには適していません。- スコア2: 言語はカジュアルですが、一般的に尊重され、強い非公式さや俗語を避けています。一部の非公式な専門的な環境では受け入れられます。- スコア3: 言語はバランスが取れており、極端な非公式さや形式張らないことを避けています。ほとんどの専門的な環境に適しています。- スコア4: 言語は明らかに形式的で尊重され、カジュアルな要素を避けています。ビジネスや学術的な環境に適しています。- スコア5: 言語は過度に形式的で尊重され、カジュアルな要素を避けています。教科書などの最も形式的な環境に適しています。
Examples:
Example Input:
MLflowとは何ですか?
Example Output:
MLflowは、あなたのフレンドリーな近所の機械学習プロジェクトのツールキットのようなものです。実験を追跡したり、コードとモデルをパッケージ化したり、チームと協力したりするのに役立ち、全体の機械学習ワークフローをスムーズにします。まるで機械学習のスイスアーミーナイフのようです!
Example score: 2
Example justification: この回答はカジュアルなトーンで書かれています。短縮形やフィラーワード('like'など)や感嘆符が使用されており、専門的ではない印象を与えます。
You must return the following fields in your response in two lines, one below the other:
score: Your numerical score for the model's professionalism based on the rubric
justification: Your reasoning about the model's professionalism score
Do not add additional new lines. Do not add any other fields.
)
新しい専門性メトリックを使用してmlflow.evaluateを呼び出します。
with mlflow.start_run() as run:
results = mlflow.evaluate(
basic_qa_model.model_uri,
eval_df,
model_type="question-answering",
evaluators="default",
extra_metrics=[professionalism_metric], # 上記で作成した専門性の評価指標を使用する
)
print(results.metrics)
カスタムメトリクスが表示されます。フォーマルさを評価するメトリクスに対して、システムプロンプトでよりフォーマルになるように指示することで先ほどよりもメトリクスが改善しています。
{'professionalism/v1/mean': 5.0, 'professionalism/v1/variance': 0.0, 'professionalism/v1/p90': 5.0}
results.tables["eval_results_table"]
basic_qa_modelを改善するために、システムプロンプトを変更してより良いパフォーマンスを発揮する新しいモデルを作成できるか試してみましょう。
新しいモデルを使用してmlflow.evaluate()を呼び出します。専門性のスコアが向上していることに注意してください!
with mlflow.start_run() as run:
system_prompt = "極度なフォーマルさを持って以下の質問に回答してください。"
professional_qa_model = mlflow.openai.log_model(
model="gpt-4o-mini",
task=openai.chat.completions,
artifact_path="model",
messages=[
{"role": "system", "content": system_prompt},
{"role": "user", "content": "{question}"},
],
)
results = mlflow.evaluate(
professional_qa_model.model_uri,
eval_df,
model_type="question-answering",
evaluators="default",
extra_metrics=[professionalism_metric],
)
print(results.metrics)

そして、ここまでの評価をすべてエクスペリメントの画面で比較することも可能です。