以下の記事では類似画像をレコメンドするモデルをDockerで稼働しているStreamlitから呼び出しましたが、この記事ではもっとお手軽にGUIと機械学習モデルを連携できるようにStream Cloudを使用します。
本書で説明するアプリケーションはデモを目的としたものです。プロダクション環境で利用される際には、適切なセキュリティ対策を講じるようにしてください。
注意
GitHubのアカウントが必要となります。
モデルのトレーニング、デプロイメント
こちらの記事に従って、ワインの品質を予測する機械学習モデルをトレーニングし、モデルサービングを起動しREST API経由でモデルを呼び出せるようにします。サンプルノートブックへのリンクも掲載しています。
- モデルの呼び出しにはパーソナルアクセストークンが必要となるので生成しておきます。
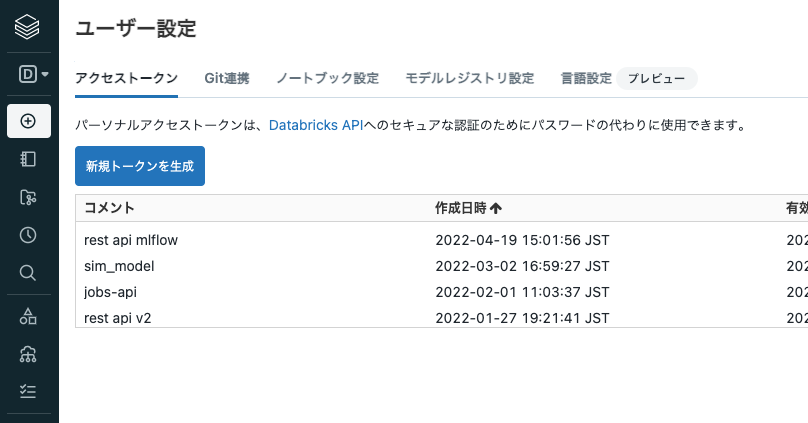
注意
パーソナルアクセストークンは厳重に管理してください。第三者に教えたりしないでください。
- モデルサービングを起動し、モデルが正常に稼働していることを確認します。Model URLをメモしておきます。
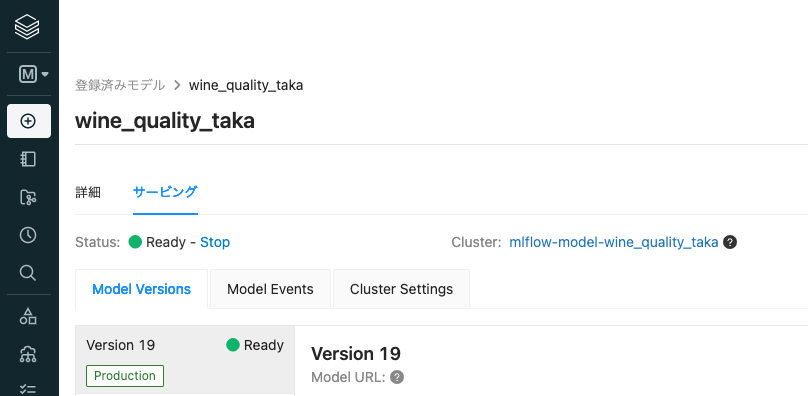
注意
モデルサービング用のクラスターを稼働させている際にも課金が発生します。モデルを使用しない場合には、Statusの右にあるStopをクリックして、モデルサービング用のクラスターを停止してください。
Streamlit Cloudのセットアップ
こちらの記事に従ってGitHubアカウントを使用してセットアップを行なってください。
GUIの実装
以下のようなディレクトリ構造としています。
wine
├── app.py
├── data
│ └── sample_data.csv
└── images
└── wine.jpg
fixed_acidity,volatile_acidity,citric_acid,residual_sugar,chlorides,free_sulfur_dioxide,total_sulfur_dioxide,density,pH,sulphates,alcohol,is_red
5,0.74,0,1.2,0.041,16,46,0.99258,4.01,0.59,12.5,1
7.2,0.2,0.38,1,0.037,21,74,0.9918,3.21,0.37,11,0
wine.jpg

これらのファイルは画面の体裁を整えるのに使用しているので、ソースを変更すれば不要です。
import streamlit as st
import numpy as np
from PIL import Image
import base64
import io
import os
import requests
import numpy as np
import pandas as pd
#st.title('Title')
st.header('ワイン品質予測モデル')
st.image("/app/streamlit/wine/images/wine.jpg", width=300)
st.write('[Databricksにおける機械学習モデル構築のエンドツーエンドのサンプル \- Qiita](https://qiita.com/taka_yayoi/items/f48ccd35e0452611d81b)') # markdown
# Copy and paste this code from the MLflow real-time inference UI. Make sure to save Bearer token from
def create_tf_serving_json(data):
return {'inputs': {name: data[name].tolist() for name in data.keys()} if isinstance(data, dict) else data.tolist()}
def score_model(dataset):
token = os.environ.get("DATABRICKS_TOKEN")
url = '<Model URL>'
headers = {'Authorization': f'Bearer {os.environ.get("DATABRICKS_TOKEN")}'}
#st.write(token)
data_json = dataset.to_dict(orient='split') if isinstance(dataset, pd.DataFrame) else create_tf_serving_json(dataset)
response = requests.request(method='POST', headers=headers, url=url, json=data_json)
if response.status_code != 200:
raise Exception(f'Request failed with status {response.status_code}, {response.text}')
return response.json()
st.subheader('予測結果サンプル')
# sample data result
df = pd.read_csv("/app/streamlit/wine/data/sample_data.csv")
response = score_model(df)
df['prediction'] = response
st.write(df)
st.subheader('テストデータのアップロード')
st.write('最初の1行目のみが処理されます。')
# data upload interface
csv_file_buffer_single = st.file_uploader('1レコードのみを含むCSVをアップロードしてください', type='csv')
if csv_file_buffer_single is not None:
df = pd.read_csv(csv_file_buffer_single)
#st.write(df)
response = score_model(df[:1])
df['prediction'] = response
st.write(df)
probability = int(df['prediction'][0] * 100)
st.metric(label="このワインが高品質である確率", value=f"{probability}%")
GitHubリポジトリにこれらをCommit & Pushします。
アプリケーションの設定
アプリケーションからモデルを呼び出せるように、上で生成したパーソナルアクセストークンをシークレットに設定します。
-
アプリケーションの右にある三点リーダーをクリックしてメニューを展開し、Settingsを選択します。
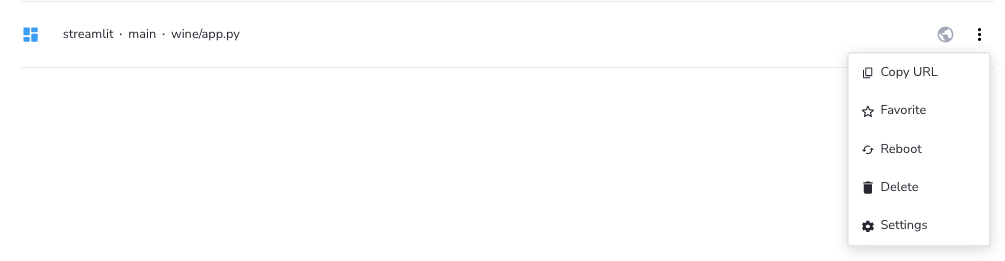
-
Secretsに以下の内容を入力します。
DATABRICKS_TOKEN="<パーソナルアクセストークン>"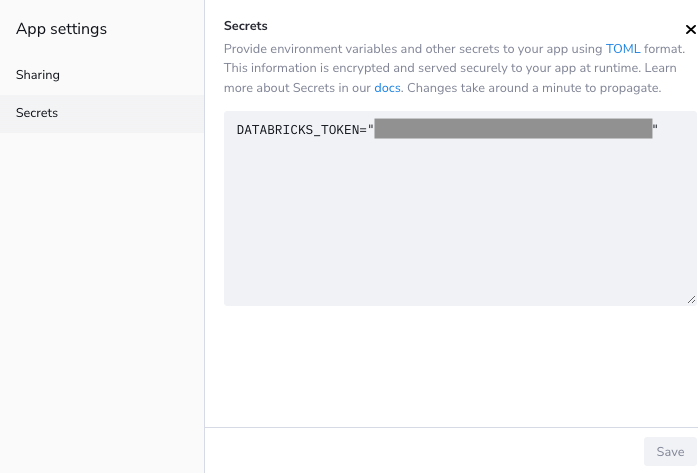
-
Saveをクリックします。
アプリケーションの動作確認
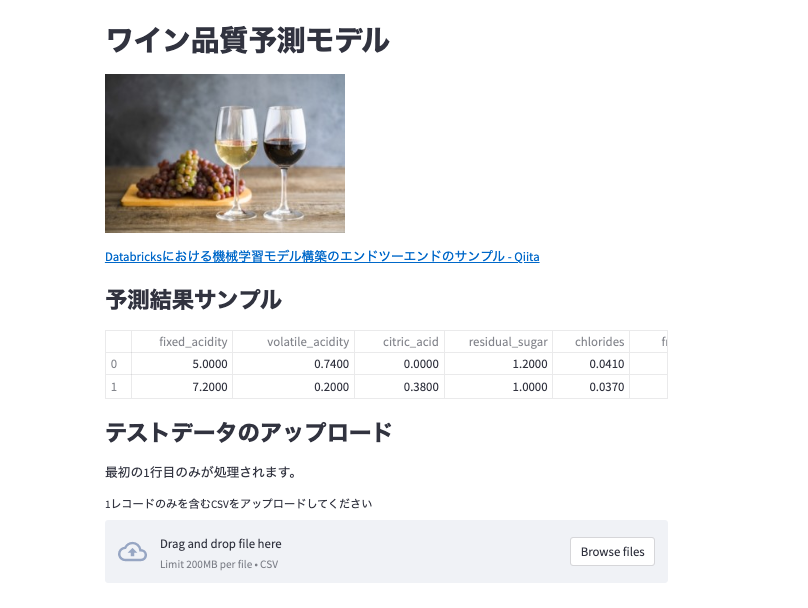
アプリケーションにアクセスすれば以下のような画面が表示されるはずです。
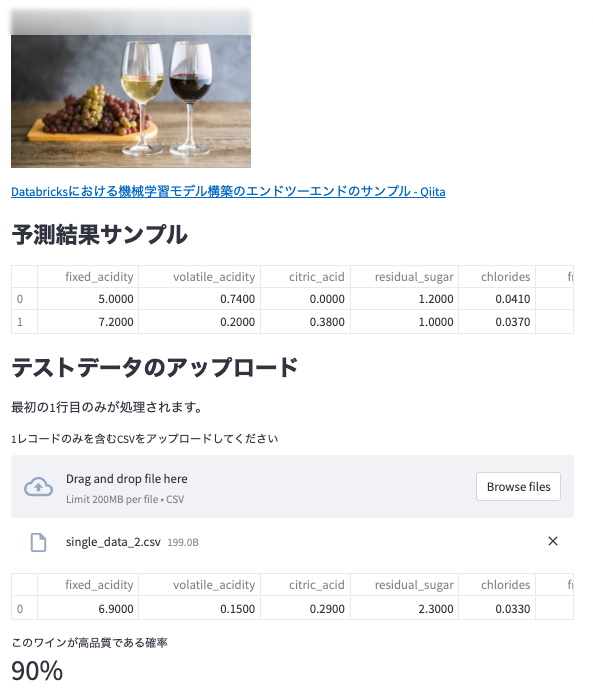
CSVファイルをアップロードすると予測結果が表示されます。
クリーンアップ
- モデルを呼び出さない場合にはモデルサービングをStopします。
- モデルを使わなくなったらStreamlit CloudのSecretsのアクセストークンを削除するか、パーソナルアクセストークンを無効化します。