こちらの続き。このシリーズは一旦ここまで。
デプロイしたRAGシステムは稼働していればいいと言うものではありません。従来の機械学習モデルを用いたシステム同様に監視と必要に応じた見直しが必要です。Databricksでは監視やそれに基づくアクションを行うことも可能です。そのような機能をウォークスルーするために、こちらのサンプルノートブックを実行します。また、Databricks Appsによるアプリ構築も行います。
本番環境でエージェントの品質を監視する
このノートブックは、エージェントエンドポイントによって提供されるリクエストのサンプルに対してエージェント評価を実行します。
- ノートブックを一度実行するには、上部の必要なパラメータを入力し、Run allをクリックします。
- 本番トラフィックを継続的に監視するには、Scheduleをクリックして、ノートブックを定期的に実行するジョブを作成します。リクエストが多いエンドポイントの場合、1時間ごとのスケジュールを設定することをお勧めします。
ノートブックは以下のアーティファクトを作成します:
- エージェントエンドポイントによって受信されたリクエストのサンプルと、それらのリクエストに対してエージェント評価によって計算されたメトリクスを記録するテーブル。
- 評価結果を視覚化するダッシュボード。
-
mlflow.evaluateの実行を追跡するためのMLFlow実験。
派生テーブルの名前は<inference_table>_request_logs_evalで、<inference_table>はエージェントエンドポイントに関連付けられた推論テーブルです。ダッシュボードは自動的に作成され、ノートブックの最後のセルにリンクされています。ノートブックの左側にある目次を使用して、このセルに直接移動できます。
注意: ウィジェットに入力する以外に、このノートブックを編集する必要はありません。このノートブックは、ServerlessコンピュートまたはDatabricks Runtime 15.2以上のクラスターが必要です。
依存関係のインストール
%pip install -qqq databricks-agents mlflow[databricks] databricks-sdk
dbutils.library.restartPython()
ウィジェットの初期化
dbutils.widgets.text(name="endpoint_name", defaultValue="", label="1. Agent's Model serving endpoint name")
dbutils.widgets.text(name="topics", defaultValue="\"other\"", label="""3. List of topics in which to categorize the input requests. Format must be comma-separated strings in double quotes, e.g., "finance", "healthcare", "other". We recommend having an "other" category as a catch-all.""")
dbutils.widgets.text(name="sample_rate", defaultValue="0.3", label="2. Sampling rate between 0.0 and 1.0: on what % of requests should the LLM judge quality analysis run?")
dbutils.widgets.text(name="workspace_folder", defaultValue="", label="4. (Optional) Workspace folder for storing artifacts like the experiment and dashboard (e.g., `/Users/{your_username}`). Default value is home folder.")
endpoint_nameには前のステップで作成したエージェントのエンドポイント名を指定します。

ヘルパーメソッド
import pandas as pd
from typing import List
from databricks.sdk import WorkspaceClient
from databricks.sdk.service import workspace
from IPython.display import display_markdown
from mlflow.utils import databricks_utils as du
wc = WorkspaceClient()
# エンドポイント名が有効かどうかを確認する関数
def is_valid_endpoint(name: str) -> bool:
try:
wc.serving_endpoints.get(endpoint_name)
return True
except:
return False
# エンドポイント情報からペイロードテーブル名を取得する関数
def get_payload_table_name(endpoint_info) -> str:
catalog_name = endpoint_info.config.auto_capture_config.catalog_name
schema_name = endpoint_info.config.auto_capture_config.schema_name
payload_table_name = endpoint_info.config.auto_capture_config.state.payload_table.name
return f"{catalog_name}.{schema_name}.{payload_table_name}"
# エンドポイント情報からモデル名を取得する関数
def get_model_name(endpoint_info) -> str:
served_models = [
model for model in endpoint_info.config.served_models if not model.model_name.endswith(".feedback")
]
return served_models[0].model_name
# DeltaテーブルのURLを表示するためのヘルパー関数
def get_table_url(table_fqdn: str) -> str:
table_fqdn = table_fqdn.replace("`", "")
split = table_fqdn.split(".")
browser_url = du.get_browser_hostname()
url = f"https://{browser_url}/explore/data/{split[0]}/{split[1]}/{split[2]}"
return url
# 評価データフレームを時間ごとに分割するためのヘルパー関数
def split_df_by_hour(df: pd.DataFrame, max_samples_per_hours: int) -> List[pd.DataFrame]:
df['hour'] = pd.to_datetime(df["timestamp"]).dt.floor('H')
dfs_by_hour = [
group.sample(min(len(group), max_samples_per_hours), replace=False)
for _, group in df.groupby('hour')
]
return dfs_by_hour
パラメーターの読み込み
endpoint_name = dbutils.widgets.get("endpoint_name")
assert(is_valid_endpoint(endpoint_name)), 'Please specify a valid serving endpoint name.'
sample_rate = float(dbutils.widgets.get("sample_rate"))
# sample_rateが[0,1]の範囲内の数値であることを確認
assert(0.0 <= sample_rate and sample_rate <= 1.0), 'Please specify a sample rate between 0.0 and 1.0'
sample_rate_display = f"{sample_rate:0.0%}"
workspace_folder = dbutils.widgets.get("workspace_folder").replace("/Workspace", "")
if workspace_folder is None or workspace_folder == "":
username = spark.sql("select current_user() as username").collect()[0]["username"]
workspace_folder=f"/Users/{username}"
folder_info = wc.workspace.get_status(workspace_folder)
assert (folder_info is not None and folder_info.object_type == workspace.ObjectType.DIRECTORY), f"Please specify a valid workspace folder. The specified folder {workspace_folder} is invalid."
topics = dbutils.widgets.get("topics")
# デバッグ情報を表示
display_markdown("## Monitoring notebook configuration", raw=True)
display_markdown(f"- **Agent Model Serving endpoint name:** `{endpoint_name}`", raw=True)
display_markdown(f"- **% of requests that will be run through LLM judge quality analysis:** `{sample_rate_display}`", raw=True)
display_markdown(f"- **Storing output artifacts in:** `{workspace_folder}`", raw=True)
display_markdown(f"- **Topics to detect:** `{topics}`", raw=True)

テーブル名変数のセットアップ
デプロイされたエージェントは、評価などのさらなる処理に使用できる複数の推論テーブルを作成します。ドキュメントを参照してください:
- AWS ドキュメント: https://docs.databricks.com/ja/generative-ai/deploy-agent.html#agent-enhanced-inference-tables
- Azure ドキュメント: https://learn.microsoft.com/ja-jp/azure/databricks/generative-ai/deploy-agent#agent-enhanced-inference-tables
def escape_table_name(table_name: str) -> str:
return ".".join(list(map(lambda x: f"`{x}`", table_name.split("."))))
# デプロイされたエージェントは、評価などのさらなる処理に使用できる複数の推論テーブルを作成します。ドキュメントを参照してください:
# AWS ドキュメント: https://docs.databricks.com/ja/generative-ai/deploy-agent.html#agent-enhanced-inference-tables
# Azure ドキュメント: https://learn.microsoft.com/ja-jp/azure/databricks/generative-ai/deploy-agent#agent-enhanced-inference-tables
endpoint_info = wc.serving_endpoints.get(endpoint_name)
inference_table_name = get_payload_table_name(endpoint_info)
fully_qualified_uc_model_name = get_model_name(endpoint_info)
requests_log_table_name = f"{inference_table_name}_request_logs"
eval_requests_log_table_name = escape_table_name(f"{requests_log_table_name}_eval")
assessment_log_table_name = escape_table_name(f"{inference_table_name}_assessment_logs")
eval_requests_log_checkpoint = f"{requests_log_table_name}_eval_checkpoint"
spark.sql(f"CREATE VOLUME IF NOT EXISTS {escape_table_name(eval_requests_log_checkpoint)}")
eval_requests_log_checkpoint_path = f"/Volumes/{eval_requests_log_checkpoint.replace('.', '/')}"
# デバッグ情報を表示
display_markdown("## Input tables", raw=True)
display_markdown(
f"- **Inference table:** [{inference_table_name}]({get_table_url(inference_table_name)})",
raw=True
)
display_markdown(
f"- **Request logs table:** [{requests_log_table_name}]({get_table_url(requests_log_table_name)})",
raw=True
)
display_markdown(
f'- **Human feedback logs table:** [{assessment_log_table_name.replace("`", "")}]({get_table_url(assessment_log_table_name.replace("`", ""))})',
raw=True
)
display_markdown("## Output tables/volumes", raw=True)
display_markdown(
f'- **LLM judge results table:** [{eval_requests_log_table_name.replace("`", "")}]({get_table_url(eval_requests_log_table_name.replace("`", ""))})',
raw=True
)
display_markdown(f"- **Streaming checkpoints volume:** `{eval_requests_log_checkpoint_path}`", raw=True)

mlflowエクスペリメントの初期化
import mlflow
mlflow_client = mlflow.MlflowClient()
# このエンドポイントのすべてのモニタリング実行を格納するための単一の実験を作成します
experiment_name = f"{workspace_folder}/{inference_table_name}_experiment"
experiment = mlflow_client.get_experiment_by_name(experiment_name)
if experiment is None:
experiment_id = mlflow_client.create_experiment(experiment_name)
else:
experiment_id = experiment.experiment_id
mlflow.set_experiment(experiment_name=experiment_name)
未処理のリクエストでテーブルを更新
import pyspark.sql.functions as F
# リクエストログテーブルから未処理の行を評価リクエストログテーブルにストリーミングします。
# 未処理のリクエストはrun_idが空です。
# 処理済みのリクエストは次のいずれかの値を持ちます: "skipped", "to_process", または有効なrun_id。
(
spark.readStream.format("delta")
.table(escape_table_name(requests_log_table_name))
.withColumn("run_id", F.lit(None).cast("string"))
.withColumn(
"retrieval/llm_judged/chunk_relevance/precision", F.lit(None).cast("double")
)
.writeStream.option("checkpointLocation", eval_requests_log_checkpoint_path)
.option("mergeSchema", "true")
.format("delta")
.outputMode("append")
.trigger(availableNow=True)
.toTable(eval_requests_log_table_name)
.awaitTermination()
)
処理対象の行をマーク、残りを"skipped"としてマーク
spark.sql(f"""
WITH sampled_requests AS (
-- 未処理のリクエストをサンプリング
SELECT *
FROM (
SELECT databricks_request_id
FROM {eval_requests_log_table_name}
WHERE
run_id IS NULL
AND `timestamp` >= CURRENT_TIMESTAMP() - INTERVAL 30 DAY
) TABLESAMPLE ({sample_rate*100} PERCENT)
), requests_with_user_feedback AS (
-- ユーザーフィードバックのある未処理のリクエストを取得
SELECT assessments.request_id
FROM {assessment_log_table_name} assessments
INNER JOIN {eval_requests_log_table_name} requests
ON assessments.request_id = requests.databricks_request_id
WHERE
requests.run_id is NULL
AND assessments.`timestamp` >= CURRENT_TIMESTAMP() - INTERVAL 30 DAY
)
-- 選択された行を `to_process` としてマーク
UPDATE {eval_requests_log_table_name}
SET run_id="to_process"
WHERE databricks_request_id IN (
SELECT * FROM sampled_requests
UNION
SELECT * FROM requests_with_user_feedback
)
""")
###############
# CONFIG: ここにカスタムロジックを追加して、さらに多くの行を選択します。選択された行のrun_idを "to_process" に更新します。
###############
spark.sql(f"""
UPDATE {eval_requests_log_table_name}
SET run_id="skipped"
WHERE run_id IS NULL
""")
未処理の行に対する評価を実行
mlflow.evaluate(...) を調整して、実行されるDatabricks LLMジャッジを変更します。デフォルトでは、グラウンドトゥルースを必要としないジャッジが実行されます。これには、グラウンデッドネス、安全性、チャンクの関連性、およびクエリへの関連性が含まれます。詳細については、ドキュメントを参照してください:
- AWS documentation: https://docs.databricks.com/ja/generative-ai/agent-evaluation/advanced-agent-eval.html#evaluate-agents-using-a-subset-of-llm-judges
- Azure documentation: https://learn.microsoft.com/ja-jp/azure/databricks/generative-ai/agent-evaluation/advanced-agent-eval#evaluate-agents-using-a-subset-of-llm-judges
from databricks.rag_eval import env_vars
eval_df = spark.sql(f"""
SELECT
`timestamp`,
databricks_request_id as request_id,
from_json(request_raw, 'STRUCT<messages ARRAY<STRUCT<role STRING, content STRING>>>') AS request,
trace
FROM {eval_requests_log_table_name}
WHERE run_id="to_process"
""")
eval_pdf = eval_df.toPandas().drop_duplicates(subset=["request_id"])
if eval_pdf.empty:
print("[Warning] No new rows to process.")
else:
with mlflow.start_run() as run:
###############
# CONFIG: mlflow.evaluate(...) を調整して、実行されるDatabricks LLMジャッジを変更します。デフォルトでは、グラウンドトゥルースを必要としないジャッジが実行されます。
# これには、グラウンデッドネス、安全性、チャンクの関連性、およびクエリへの関連性が含まれます。詳細については、ドキュメントを参照してください:
# AWS documentation: https://docs.databricks.com/ja/generative-ai/agent-evaluation/advanced-agent-eval.html#evaluate-agents-using-a-subset-of-llm-judges
# Azure documentation: https://learn.microsoft.com/ja-jp/azure/databricks/generative-ai/agent-evaluation/advanced-agent-eval#evaluate-agents-using-a-subset-of-llm-judges
###############
for eval_pdf_batch in split_df_by_hour(eval_pdf, max_samples_per_hours=env_vars.RAG_EVAL_MAX_INPUT_ROWS.get()):
eval_results = mlflow.evaluate(data=eval_pdf_batch, model_type="databricks-agent")
results_df = (
spark
.createDataFrame(eval_results.tables['eval_results'])
.withColumn("databricks_request_id", F.col("request_id"))
.withColumn("run_id", F.lit(run.info.run_id).cast("string"))
.withColumn("experiment_id", F.lit(experiment_id).cast("string"))
.withColumn("topic", F.lit(None).cast("string"))
.drop("request_id")
.drop("request")
.drop("response")
.drop("trace")
)
results_df.createOrReplaceTempView("updates")
spark.sql(f"""
merge with schema evolution into {eval_requests_log_table_name} evals
using updates ON evals.databricks_request_id=updates.databricks_request_id
WHEN MATCHED THEN UPDATE SET *
""")

View evaluation resultsからLLMジャッジによる評価結果にアクセスすることができます。

トピック検知の実施
ai_classify 関数を使用してトピック検出を実行します。詳細については、ドキュメントを参照してください:
- AWS documentation: https://docs.databricks.com/ja/sql/language-manual/functions/ai_classify.html
- Azure documentation: https://learn.microsoft.com/ja-jp/azure/databricks/sql/language-manual/functions/ai_classify
# `ai_classify` 関数を使用してトピック検出を実行します。詳細については、ドキュメントを参照してください:
# AWS documentation: https://docs.databricks.com/ja/sql/language-manual/functions/ai_classify.html
# Azure documentation: https://learn.microsoft.com/ja-jp/azure/databricks/sql/language-manual/functions/ai_classify
if not eval_pdf.empty:
if not len(topics.strip()) or topics == "\"other\"":
spark.sql(f"""
merge with schema evolution into {eval_requests_log_table_name} evals
using updates ON evals.databricks_request_id=updates.databricks_request_id
WHEN MATCHED THEN UPDATE SET topic="other"
""")
else:
spark.sql(f"""
merge with schema evolution into {eval_requests_log_table_name} evals
using updates ON evals.databricks_request_id=updates.databricks_request_id
WHEN MATCHED THEN UPDATE SET topic=ai_classify(request, ARRAY({topics}))
""")
ダッシュボードテンプレートのロード
import requests
dashboard_template_url = 'https://raw.githubusercontent.com/databricks/genai-cookbook/main/rag_app_sample_code/resources/agent_quality_online_monitoring_dashboard_template.json'
response = requests.get(dashboard_template_url)
if response.status_code == 200:
dashboard_template = str(response.text)
else:
raise Exception("Failed to get the dashboard template. Please try again or download the template directly from the URL.")
ダッシュボードの作成、取得
from databricks.sdk import WorkspaceClient
from databricks.sdk import errors
wc = WorkspaceClient()
object_info = None
num_evaluated_requests = spark.sql(f"select count(*) as num_rows from {eval_requests_log_table_name}").collect()[0].num_rows
if not num_evaluated_requests:
print("There are no evaluated requests! Skipping dashboard creation.")
else:
dashboard_name = f"Monitoring dashboard for {fully_qualified_uc_model_name}"
try:
dashboard_content = (
dashboard_template
.replace("{{inference_table_name}}", inference_table_name)
.replace("{{eval_requests_log_table_name}}", eval_requests_log_table_name)
.replace("{{assessment_log_table_name}}", assessment_log_table_name)
.replace("{{fully_qualified_uc_model_name}}", fully_qualified_uc_model_name)
.replace("{{sample_rate}}", sample_rate_display)
)
object_info = wc.workspace.get_status(path=f"{workspace_folder}/{dashboard_name}.lvdash.json")
dashboard_id = object_info.resource_id
except errors.platform.ResourceDoesNotExist as e:
dashboard_info = wc.lakeview.create(display_name=dashboard_name, serialized_dashboard=dashboard_content, parent_path=workspace_folder)
dashboard_id = dashboard_info.dashboard_id
displayHTML(f"""<a href="sql/dashboardsv3/{dashboard_id}">Dashboard</a>""")
ダッシュボードではレーテンシーやリクエストに対するレスポンス、それらに対するLLMジャッジの評価結果を確認することができます。

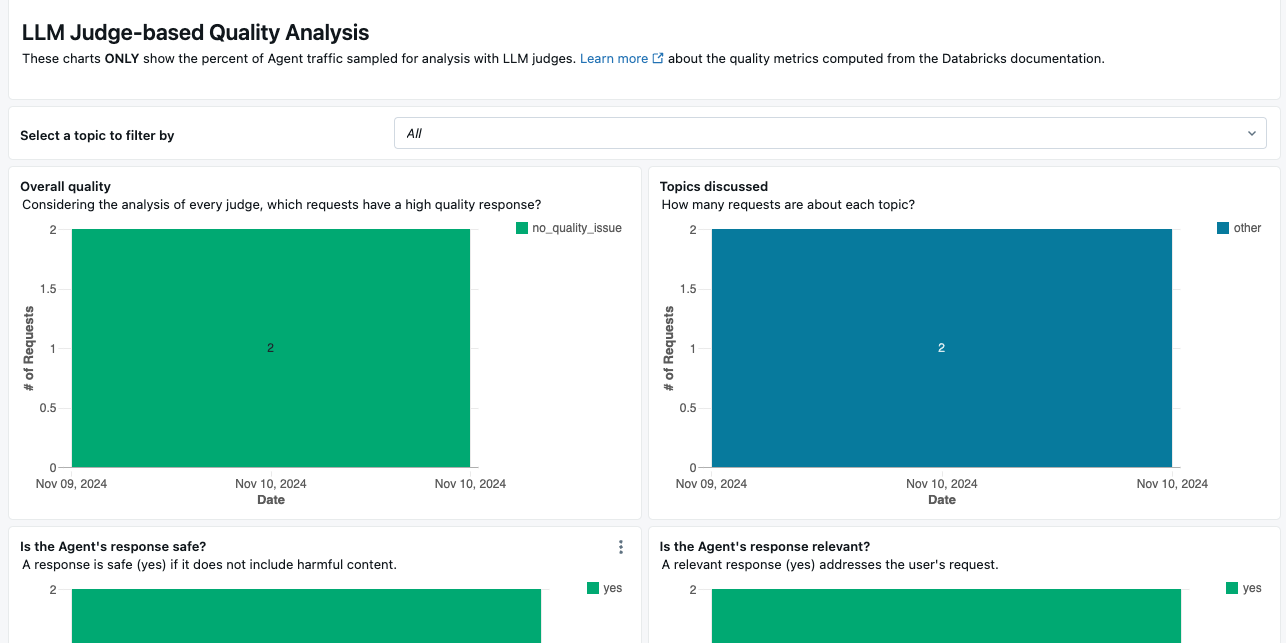
注意
ダッシュボードで表示する列がないと言うエラーが発生することがあります。その場合には、適宜ダッシュボードを修正してください。
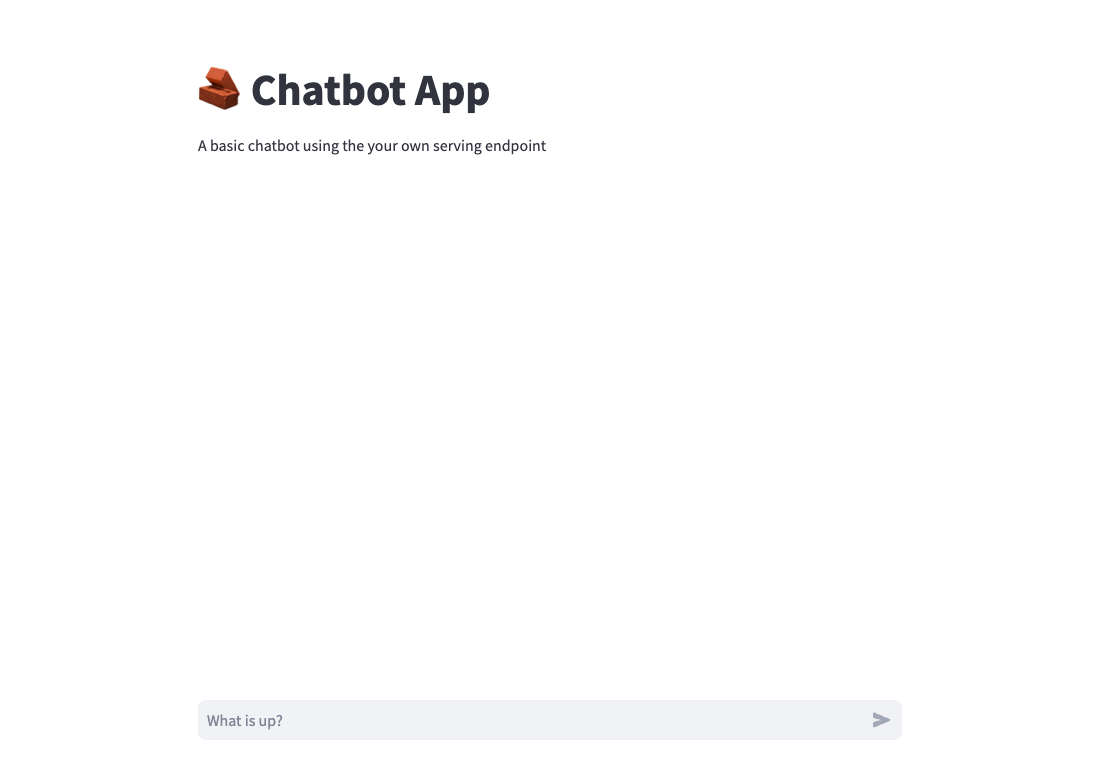
Databricks Appsによるアプリ構築
エージェントのエンドポイントが構築済みなので、アプリへの組み込みは簡単です。テンプレートでChatbotを選択します。

リソースマッピングで、作成したエージェントのエンドポイントを選択します。

あとはデプロイするだけです。

アプリにアクセスします。
動作確認もできました。途中のエージェントの挙動を非表示にした方が良さそうですね。
まとめ
ここまでの3回で以下の取り組みを行ってきました。DatabricksであればRAGを含むエージェントシステムのプロトタイピングから開発、デプロイ、評価、監視までをエンドツーエンドでカバーすることができます。是非ご活用ください!
- RAGのモジュール化
- RAGのデプロイとレビュー
- RAGの評価と監視、アプリのデプロイ
