どちらもSQLを用いてテーブルに対するUPSERT(UPDATE + INSERT)をするのですが、用途や仕様が異なるのでこちらにまとめます。
MERGE INTO
目的
ターゲットのDeltaテーブルにソーステーブルからのデータをマージするための汎用SQL文です。UPSERT処理という観点では、後述のAPPLY CHANGES INTOよりも汎用的です。
用途
マッチング条件に基づいたUPSERT、DELETE、UPDATEのように様々なオペレーションで使用することができます。
複雑性
順番がバラバラなデータを適切に適用するにはより複雑なロジックを必要とし、適切に対応しない場合には不適切な結果を生成することがあります。
柔軟性
マージの条件やアクションに対してよりきめ細かいコントロールが可能であり、重複排除は条件に基づく更新のような複雑な操作が可能です。
構文
MERGE INTO target_table_name [target_alias]
USING source_table_reference [source_alias]
ON merge_condition
WHEN MATCHED [ AND matched_condition ] THEN matched_action
WHEN NOT MATCHED [BY TARGET] [ AND not_matched_condition ] THEN not_matched_action
WHEN NOT MATCHED BY SOURCE [ AND not_matched_by_source_condition ] THEN not_matched_by_source_action;
SQLリファレンス
APPLY CHANGES INTO
目的
Delta Live Tablesパイプラインにおけるチェンジデータキャプチャ(CDC)のために特別に設計されたSQL文です。Delta Live Tables外では使用できません。
用途
チェンジデータフィード(CDF)やスナップショットからの変更点を処理するために活用されます。
順番がバラバラのデータの取り扱い
CDCシナリオにおいてよくある問題である順番がバラバラのレコードを取り扱えるのように最適化されています。
シンプルさ
変更点を適用するために、より分かりやすく宣言型であるアプローチを提供しており、CDCロジックの実装を容易にします。
SCDタイプのサポート
Slowly Changing Dimensions (SCD)のタイプ1とタイプ2をサポートしており、直接的なアップデートと変更点の履歴追跡を可能にします。
構文
CREATE OR REFRESH STREAMING TABLE target;
APPLY CHANGES INTO live.target
FROM stream(cdc_data.users)
KEYS (userId)
APPLY AS DELETE WHEN operation = "DELETE"
SEQUENCE BY sequenceNum
COLUMNS * EXCEPT (operation, sequenceNum)
STORED AS SCD TYPE 1;
2つの違いを表にまとめます。
| MERGE INTO | CHANGE APPLY INTO | |
|---|---|---|
| 用途 | 汎用的なマージ処理 | チェンジデータキャプチャ(CDC) |
| どこで利用できるか | Delta Live Tables以外 | Delta Live Tables |
| 長所 |
|
|
| 短所 |
|
|
例
上述の違いを体験するために、ここではまずはMERGE INTOでUPSERTを実装し、同様の処理をAPLLY CHANGE INTOで実装します。
MERGE INTOの実装
以下のようなソーステーブルを作成します。
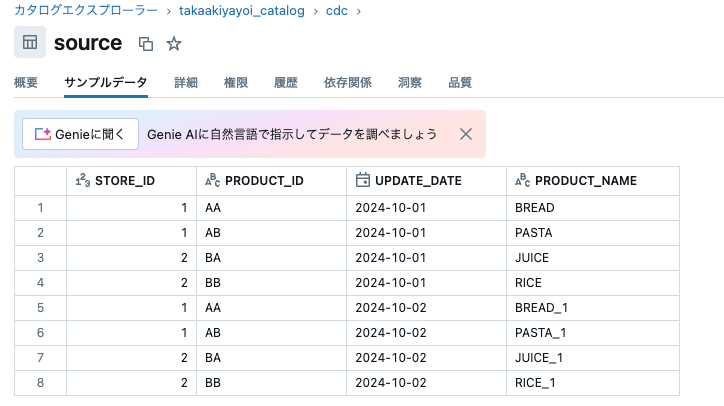
STORE_IDとPRODUCT_IDに基づいてターゲットテーブルを更新するシナリオを考えます。ただし、ターゲットテーブルでは異なる列名を用いており、TENPO_IDとSEIHIN_IDとなっています。
基本的なMERGE INTOの構文の用法は以下のようになります。
CREATE TABLE takaakiyayoi_catalog.cdc.target(TENPO_ID INT, SEIHIN_ID STRING, SEIHIN_MEI STRING)
MERGE INTO takaakiyayoi_catalog.cdc.target AS target USING (
SELECT
*
FROM
takaakiyayoi_catalog.cdc.source
) AS source ON target.TENPO_ID = source.STORE_ID
AND target.SEIHIN_ID = source.PRODUCT_ID
WHEN matched then
update
set
target.TENPO_ID = source.STORE_ID,
target.SEIHIN_ID = source.PRODUCT_ID,
target.SEIHIN_MEI = source.PRODUCT_NAME
WHEN NOT matched then
insert
(TENPO_ID, SEIHIN_ID, SEIHIN_MEI)
VALUES
(
source.STORE_ID,
source.PRODUCT_ID,
source.PRODUCT_NAME
)
ソーステーブルとターゲットテーブルでマッチングする列が異なっていてもON句で吸収することができます。しかし、この例ではこのSQLを実行するとすべての行がINSERTされます。
このため、複数一致が発生しないように以下のようにWHERE UPDATE_DATE = "2024-10-01"を追加します。
MERGE INTO takaakiyayoi_catalog.cdc.target AS target USING (
SELECT
*
FROM
takaakiyayoi_catalog.cdc.source
WHERE
UPDATE_DATE = "2024-10-01"
) AS source ON target.TENPO_ID = source.STORE_ID
AND target.SEIHIN_ID = source.PRODUCT_ID
WHEN matched then
update
set
target.TENPO_ID = source.STORE_ID,
target.SEIHIN_ID = source.PRODUCT_ID,
target.SEIHIN_MEI = source.PRODUCT_NAME
WHEN NOT matched then
insert
(TENPO_ID, SEIHIN_ID, SEIHIN_MEI)
VALUES
(
source.STORE_ID,
source.PRODUCT_ID,
source.PRODUCT_NAME
)
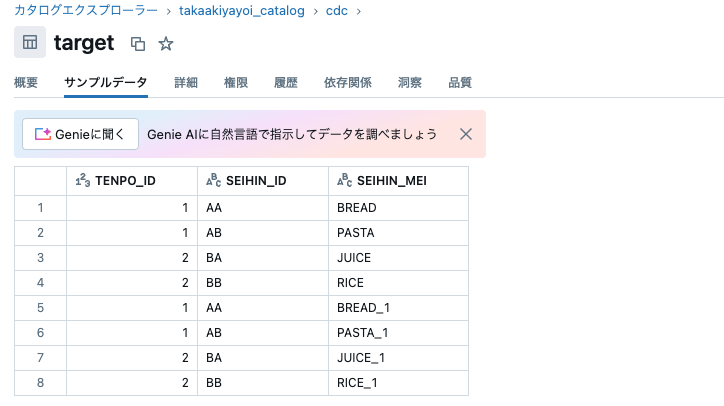
これで、2024-10-01のみのデータに基づいてUPSERT(実際にはINSERT)が行われました。
日付を変えて再度実行します。
MERGE INTO takaakiyayoi_catalog.cdc.target AS target USING (
SELECT
*
FROM
takaakiyayoi_catalog.cdc.source
WHERE
UPDATE_DATE = "2024-10-02"
) AS source ON target.TENPO_ID = source.STORE_ID
AND target.SEIHIN_ID = source.PRODUCT_ID
WHEN matched then
update
set
target.TENPO_ID = source.STORE_ID,
target.SEIHIN_ID = source.PRODUCT_ID,
target.SEIHIN_MEI = source.PRODUCT_NAME
WHEN NOT matched then
insert
(TENPO_ID, SEIHIN_ID, SEIHIN_MEI)
VALUES
(
source.STORE_ID,
source.PRODUCT_ID,
source.PRODUCT_NAME
)
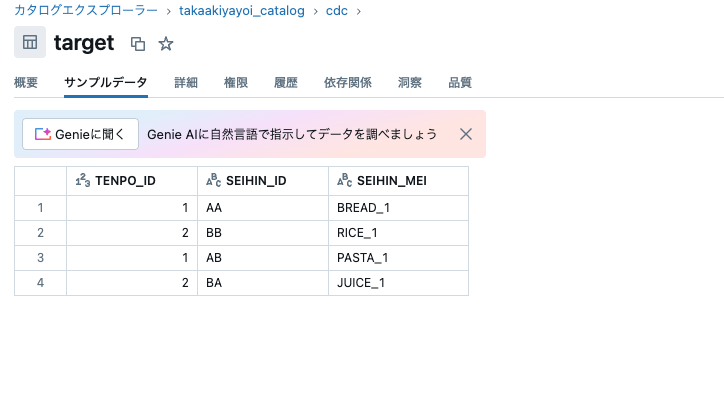
このように、単にマージ(UPSERT)処理を行いたいというケースであれば、柔軟なMERGE INTOを使った方が優れていると言えます。
では、APPLY CHANGES INTOの例を見てみましょう。
APPLY CHANGES INTOの実装
こちらは、Delta Live Tablesで実装するので、ノートブックを作成し、以下を記述します。
CREATE OR REFRESH STREAMING TABLE dlt_target;
APPLY CHANGES INTO
live.dlt_target
FROM
stream(takaakiyayoi_catalog.cdc.source)
KEYS
(STORE_ID, PRODUCT_ID) -- sourceのキー
SEQUENCE BY
UPDATE_DATE -- 更新順序を表す列
STORED AS
SCD TYPE 1 -- SCDタイプ
このノートブックを指定してパイプラインを作成し、実行します。
これで、UPDATE_DATEに基づいてUPSERTが行われます。
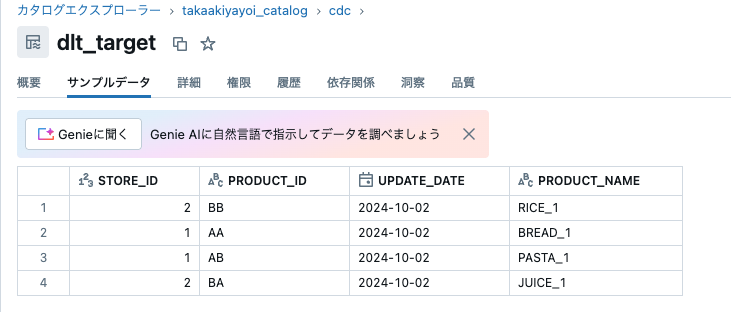
しかし、この状態ではソーステーブルとターゲットテーブルの列名が同じままとなっています。APPLY CHANGES INTOでは、列名が異なるテーブル同士のマッチングができないため、APPLY CHANGES INTOの前段に一時ビューを挟んで列名を変更します。
CREATE OR REFRESH STREAMING TABLE dlt_target;
CREATE TEMPORARY STREAMING LIVE VIEW dlt_intermediate AS
SELECT
STORE_ID AS TENPO_ID,
PRODUCT_ID AS SEIHIN_ID,
PRODUCT_NAME,
UPDATE_DATE
FROM
stream(takaakiyayoi_catalog.cdc.source)
APPLY CHANGES INTO
live.dlt_target
FROM
stream(live.dlt_intermediate)
KEYS
(TENPO_ID, SEIHIN_ID) -- sourceのキー
SEQUENCE BY
UPDATE_DATE -- 更新順序を表す列
STORED AS
SCD TYPE 1 -- SCDタイプ
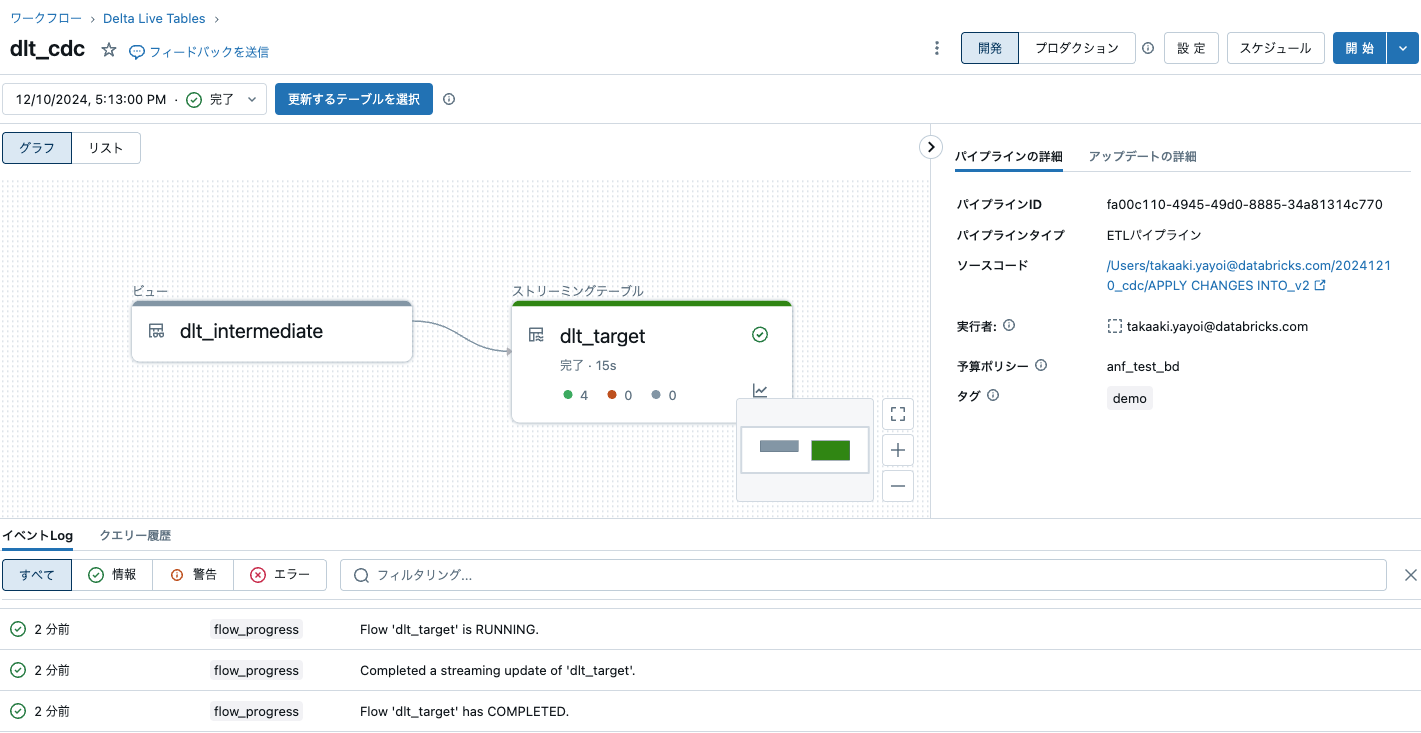
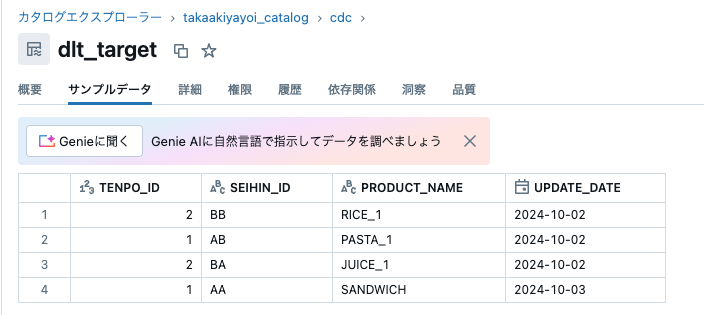
期待した通りの挙動になりました。
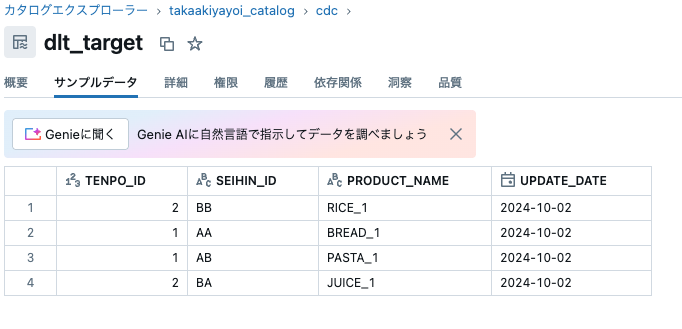
さらに以下のSQLを実行して、ソーステーブルにINSERTします。
INSERT INTO takaakiyayoi_catalog.cdc.source VALUES(1, "AA", "2024-10-3", "SANDWICH")
Delta Live Tablesのパイプラインを再度実行します。すると、1行のみが処理されます。
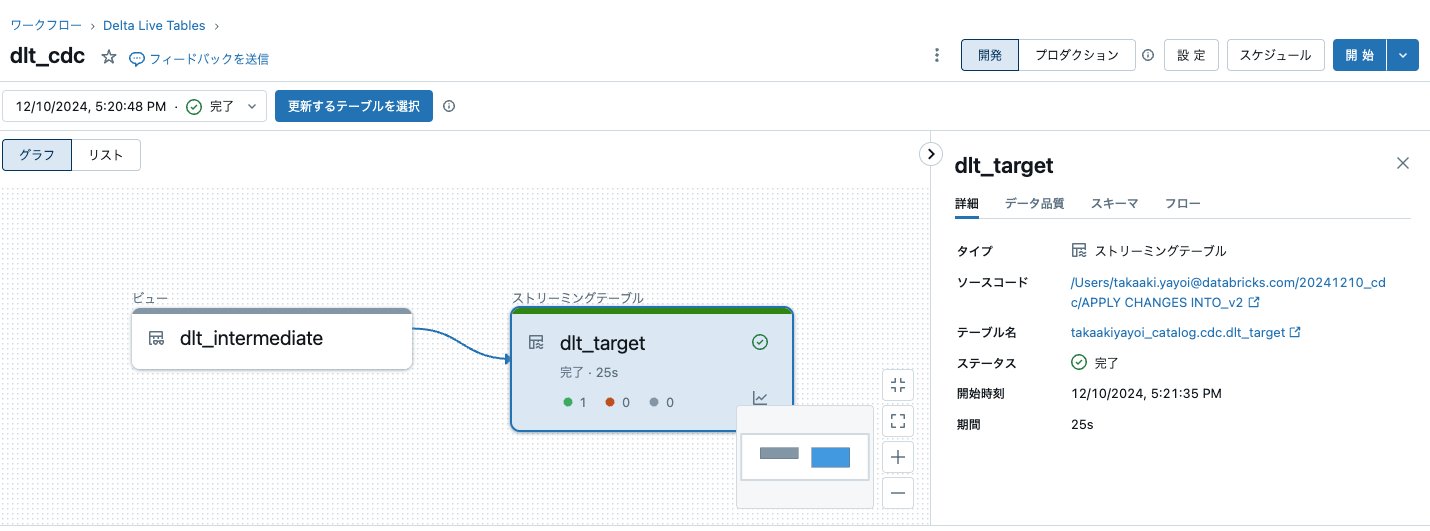
結果を確認すると、INSERTしたレコードに基づいてUPSERTが行われていることを確認できます。これが、ソーステーブルの変更データ(CHANGE DATA)のみを捕捉(CAPTURE)して更新を行う、CHANGE DATA CAPTURE(CDC) という訳です。データ量が多くなってくると、テーブル洗い替えのコストも無視できなくなってきますので、CDCの価値が出て来ると思います。
まとめ
MERGE INTOとAPPLY CHANGES INTOの主な違いをまとめます。
-
CDCへの最適化:
APPLY CHANGES INTOはCDCに最適化されています。ソーステーブルから絶え間なく流れ込むチェンジデータフィード(CDF)をインクリメンタルに処理し、ターゲットテーブルに適切に反映させる必要があるシナリオではAPPLY CHANGES INTOが適しています。MERGE INTOでこのような処理に対応しようとすると、追加のロジック実装が必要となります。 -
シンプルさ vs. 柔軟性:
APPLY CHANGES INTOはCDCに特化している分、仕様はシンプルです。一方、MERGE INTOは複雑なデータ操作のための柔軟性とコントロールを提供しています。