2年前にこちらのマニュアルを翻訳しました。
今ではマニュアルも日本語化されているので、今回はサンプルノートブックをウォークスルーします。
ステップ1: 変数を定義し、 CSVファイルを読み込む
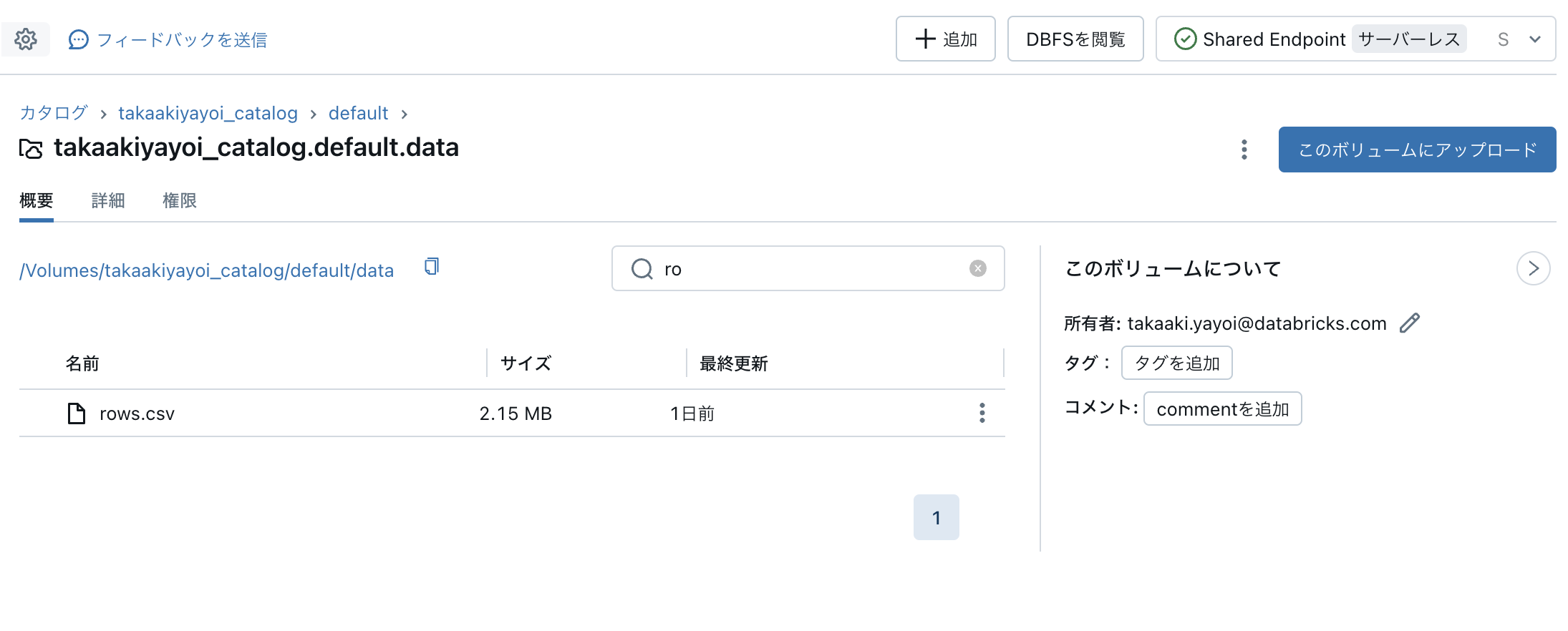
Unity CatalogのボリュームにCSVファイルを格納します。
catalog = "takaakiyayoi_catalog"
schema = "default"
volume = "data"
download_url = "https://health.data.ny.gov/api/views/jxy9-yhdk/rows.csv"
file_name = "rows.csv"
table_name = "health_data"
path_volume = "/Volumes/" + catalog + "/" + schema + "/" + volume
path_tables = catalog + "." + schema
print(path_tables) # 完全パスを表示
print(path_volume) # 完全パスを表示
takaakiyayoi_catalog.default
/Volumes/takaakiyayoi_catalog/default/data
dbutils.fs.cp(f"{download_url}", f"{path_volume}" + "/" + f"{file_name}")
CSVファイルが格納されました。
ステップ2: DataFrameを作成する
data = [[2021, "test", "Albany", "M", 42]]
columns = ["Year", "First_Name", "County", "Sex", "Count"]
df1 = spark.createDataFrame(data, schema="Year int, First_Name STRING, County STRING, Sex STRING, Count int")
display(df1) # display()メソッドはDatabricksノートブック固有のものであり、よりリッチなビジュアライゼーションを提供します。
# df1.show() show()メソッドはApache Spark DataFrame APIに含まれており、基本的なビジュアライゼーションを提供します。

ステップ3: CSVファイルからDataFrameにデータをロードする
# ボリュームに格納されているCSVファイルからデータフレームを作成
df_csv = spark.read.csv(f"{path_volume}/{file_name}",
header=True,
inferSchema=True,
sep=",")
display(df_csv)

ステップ4: DataFrameを表示して操作する
DataFrameのスキーマを表示する
# スキーマの表示
df_csv.printSchema()
df1.printSchema()
root
|-- Year: integer (nullable = true)
|-- First Name: string (nullable = true)
|-- County: string (nullable = true)
|-- Sex: string (nullable = true)
|-- Count: integer (nullable = true)
root
|-- Year: integer (nullable = true)
|-- First_Name: string (nullable = true)
|-- County: string (nullable = true)
|-- Sex: string (nullable = true)
|-- Count: integer (nullable = true)
DataFrameの列名を変更する
df_csv = df_csv.withColumnRenamed("First Name", "First_Name")
df_csv.printSchema
<bound method DataFrame.printSchema of DataFrame[Year: int, First_Name: string, County: string, Sex: string, Count: int]>
DataFramesを結合する
これは縦方向のunionになります。
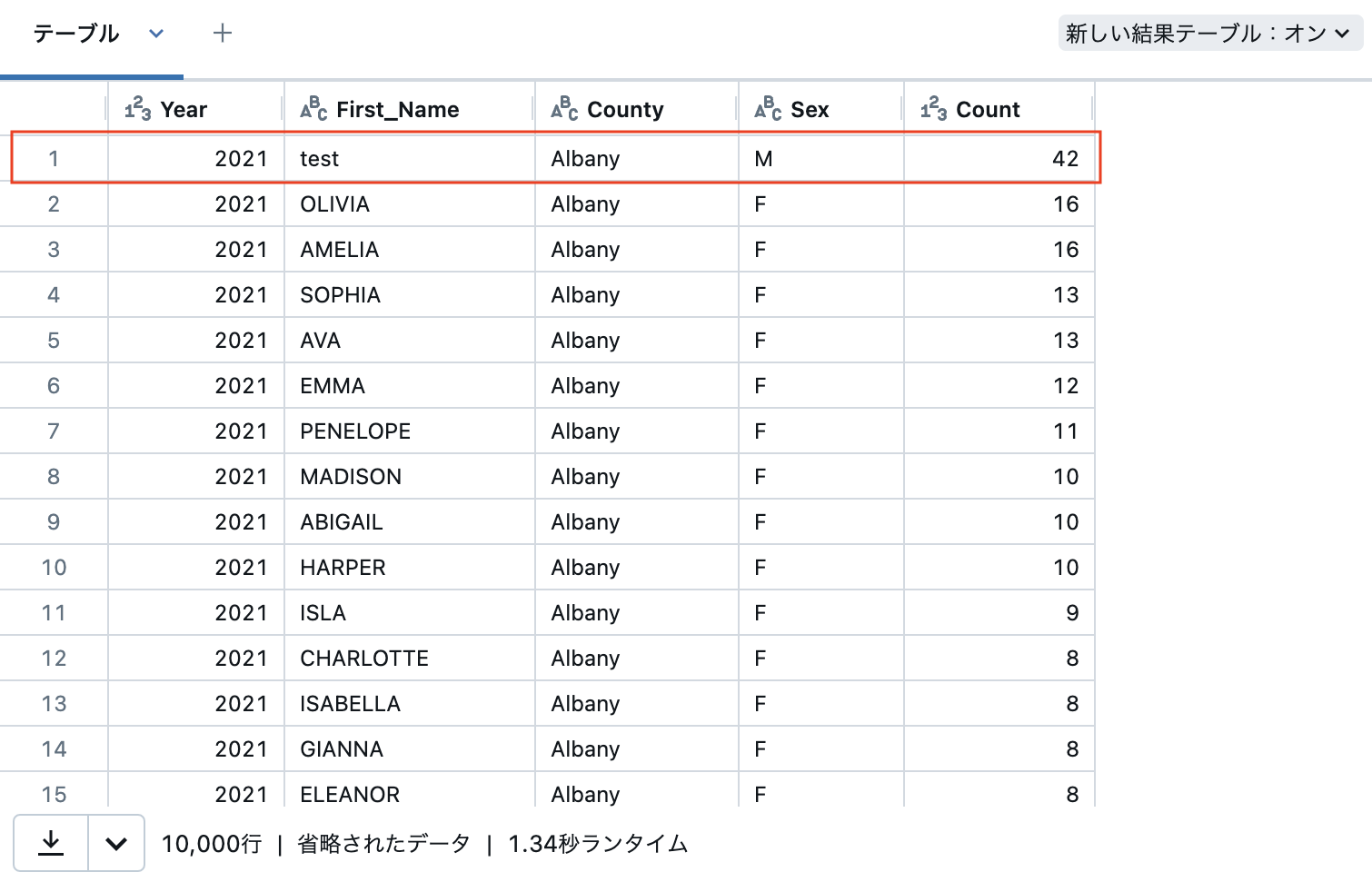
df = df1.union(df_csv)
display(df)
先頭にtestの行が追加されていることがわかります。
DataFrame内の行をフィルタリングする
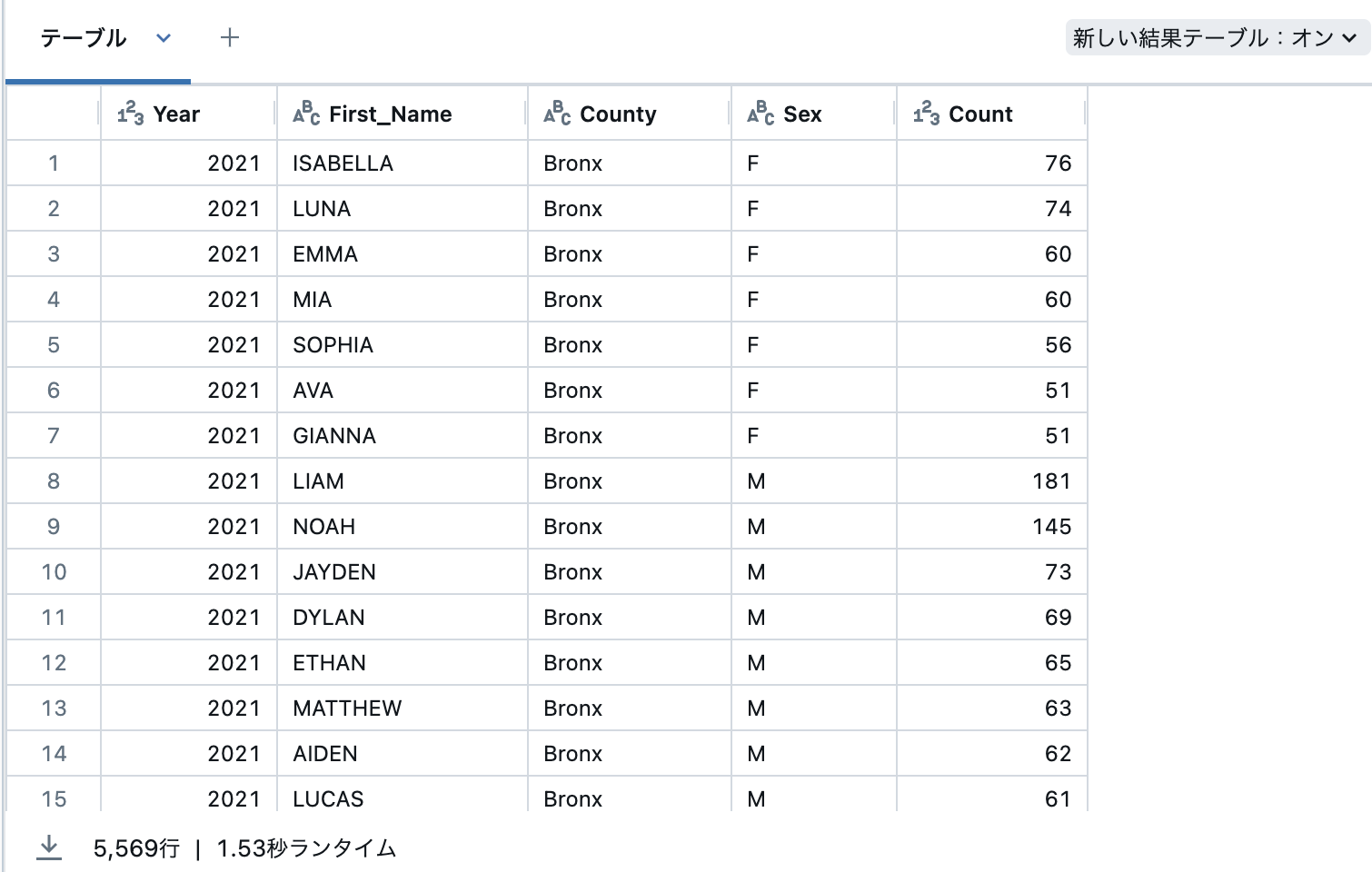
filterを用いてCount列の値が50よりも大きいものにフィルタリングします。
display(df.filter(df["Count"] > 50))
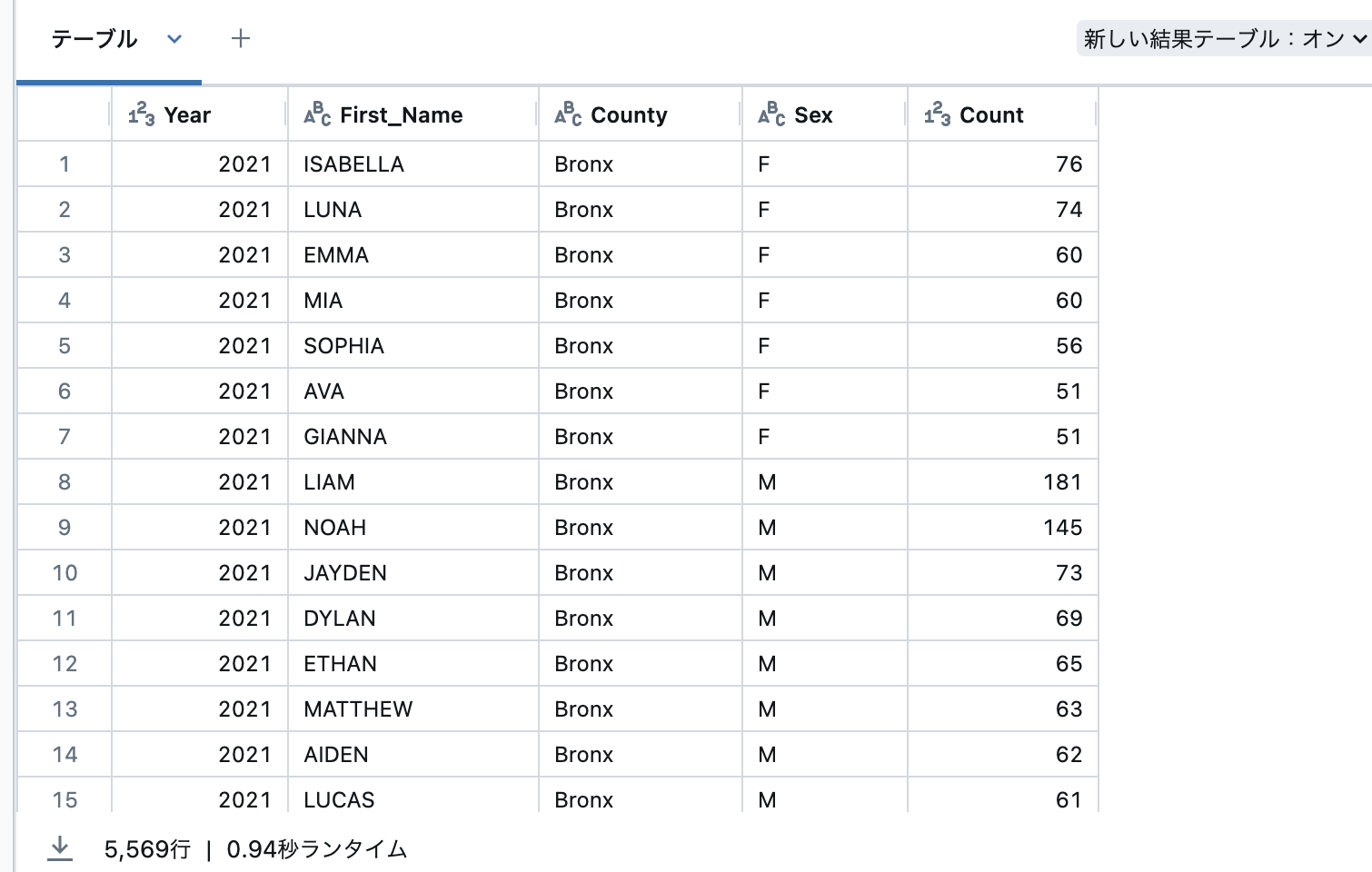
こちらも同じ挙動をします。
display(df.where(df["Count"] > 50))
DataFrame から列を選択し、頻度順に並べ替える
descでCountの降順、orderByでソートを支持します。selectはSQLと同じように列を選択しています。考え方自体、SQLと似ています。
from pyspark.sql.functions import desc
display(df.select("First_Name", "Count").orderBy(desc("Count")))
DataFrameのサブセットを作成する
filterで以下の条件をANDで指定しています。
-
Yearが
2009 -
Countが
100より大きい -
Sexが
F - 列はFirst_Name、County、Countを選択
- Countの降順でソート
subsetDF = (
df.filter((df["Year"] == 2009) & (df["Count"] > 100) & (df["Sex"] == "F"))
.select("First_Name", "County", "Count")
.orderBy(desc("Count"))
)
display(subsetDF)

ステップ5: DataFrameを保存する
df.write.saveAsTable(f"{path_tables}" + "." + f"{table_name}")
# 既存のテーブルを上書きするには以下のコードを使います:
# df.write.mode("overwrite").saveAsTable(f"{path_tables}" + "." + f"{table_name}")
上を実行するとデータフレームがテーブルとして保存されます。

DataFrameをJSONファイルに保存する
パスを指定して他のフォーマットで保存することもできます。
df.write.format("json").save("/tmp/json_data")
# 既存のファイルを上書きするには以下のコードを使います:
# df.write.format("json").mode("overwrite").save("/tmp/json_data")
JSONファイルからDataFrameを読み込む
display(spark.read.format("json").json("/tmp/json_data"))
追加タスク: PySparkでSQLクエリを実行する
注意
元のノートブックでは、Scala、RでのSQL実行もカバーされていますが、こちらでは割愛します。
SQLクエリとして列を指定する
selectExprやexprを用いることで、PySparkの中でSQLエクスプレッションを活用することができます。
display(df.selectExpr("Count", "upper(County) as big_name"))

from pyspark.sql.functions import expr
display(df.select("Count", expr("lower(County) as little_name")))

詳細はこちらをご覧ください。
spark.sql() を使用して任意の SQL クエリを 実行する
spark.sql()の引数にはSQL文を文字列として指定できます。Pythonの中でクイックにSQLを使いたい際には便利です。
display(spark.sql(f"SELECT * FROM {path_tables}" + "." + f"{table_name}"))
上の例ではf-stringを使ってパラメータを埋め込んでいますが、Spark 3.4からはネイティブのパラメータ化がサポートされています。詳細はこちらをご覧ください。