こちらの内容は古くなっています。Databricksにおける生成AIの本番運用モニタリングをご覧ください。
こちらのサンプルを動かします。
生成AI向けレイクハウスモニタリングを用いることで、生成AIジャッジやゴールデンメトリクス(レーテンシー、トークン数など)を用いて生成AIエージェントアプリの挙動を評価することができます。
注意
執筆時点ではベータ版です。
機能の有効化
ワークスペースのプレビューで、Lakehouse Monitoring for GenAI (Agent Evaluation) をオンにします。

GenAIの本番エージェントを監視するためのLakehouse Monitoringの使用
このノートブックは、Lakehouse Monitoring for GenAIを使用してデプロイされたGenAIアプリ/エージェントを監視する方法を示します。以下を行います:
- Agent Frameworkを使用して「Hello World」エージェントをデプロイします。
- Agent EvaluationのLLMジャッジを使用して品質監視を設定します。
- デプロイされたエンドポイントにサンプルトラフィックを送信します。
Lakehouse Monitoring for GenAIを使用すると、以下が可能です:
- 品質と運用パフォーマンス(レイテンシ、リクエスト量、エラーなど)を追跡します。
- Agent EvaluationのLLMジャッジを使用して、本番トラフィックでドリフトや回帰を検出するためのLLMベースの評価を実行します。
- 個々のリクエストを詳細に調査して、エージェントの応答をデバッグおよび改善します。
- 実際のログを評価セットに変換して、継続的な改善を推進します。
注: Agent Frameworkのagents.deploy(...)を使用してChatAgentで作成されたエージェントをデプロイする場合、基本的な監視が運用メトリクス(リクエスト量、レイテンシ、エラー率など)で自動的に設定されます。オプションで、Agent Evaluationの独自のLLMジャッジを使用して品質メトリクスを設定できます。
%pip install -U -qqqq databricks-agents>=0.17.0 databricks-sdk[openai] backoff uv
dbutils.library.restartPython()
Unity Catalogスキーマを選択する
このスキーマでCREATE TABLEおよびCREATE MODELアクセス権を持っていることを確認してください。デフォルトでは、これらの値はワークスペースのデフォルトカタログとスキーマに設定されています。
ここでは、ウィジェットでカタログtakaakiyayoi_catalog、スキーマagentsを指定します。

# ワークスペースのデフォルトUCカタログ/スキーマを取得
uc_default_location = spark.sql("select current_catalog() as current_catalog, current_schema() as current_schema").collect()[0]
current_catalog = uc_default_location["current_catalog"]
current_schema = uc_default_location["current_schema"]
# UCカタログ/スキーマをここでまたはノートブックの上部のウィジェットエディタで変更
dbutils.widgets.text("uc_catalog", current_catalog)
dbutils.widgets.text("uc_schema", current_schema)
UC_CATALOG = dbutils.widgets.get("uc_catalog")
UC_SCHEMA = dbutils.widgets.get("uc_schema")
UC_PREFIX = f"{UC_CATALOG}.{UC_SCHEMA}"
UC_PREFIX
'takaakiyayoi_catalog.agents'
エージェントの作成とデプロイ
このセクションでは、以下を行います:
- Llama 70Bを使用してシンプルなエージェントを作成します。
- MLflowを使用してエージェントをログします。
- エージェントをデプロイします。これにより、リクエスト量、レイテンシ、エラーを追跡する基本的な監視が自動的に設定されます。
既にデプロイされたエージェントがある場合は、このステップをスキップできます。
%%writefile hello_world_agent.py
from typing import Any, Generator, Optional
import mlflow
from databricks.sdk import WorkspaceClient
from mlflow.entities import SpanType
from mlflow.pyfunc.model import ChatAgent
from mlflow.types.agent import (
ChatAgentChunk,
ChatAgentMessage,
ChatAgentResponse,
ChatContext,
)
mlflow.openai.autolog()
# オプション: 任意のモデルサービングエンドポイントに置き換え
LLM_ENDPOINT_NAME = "databricks-meta-llama-3-3-70b-instruct"
class SimpleChatAgent(ChatAgent):
def __init__(self):
self.workspace_client = WorkspaceClient()
self.client = self.workspace_client.serving_endpoints.get_open_ai_client()
self.llm_endpoint = LLM_ENDPOINT_NAME
# レトリーバーをシミュレートするためのフェイクドキュメント
self.documents = [
mlflow.entities.Document(
metadata={"doc_uri": "uri1.txt"},
page_content="""Lakehouse Monitoring for GenAIは、生成AIアプリの品質、コスト、レイテンシを監視するのに役立ちます。Lakehouse Monitoring for GenAIを使用すると、次のことができます:\n- 品質と運用パフォーマンス(レイテンシ、リクエストボリューム、エラーなど)を追跡します。\n- Agent EvaluationのLLMジャッジを使用して、生成AIアプリのトラフィックに対してLLMベースの評価を実行し、ドリフトやリグレッションを検出します。\n- 個々のリクエストを詳細に調査して、エージェントの応答をデバッグおよび改善します。\n- 実際のログを評価セットに変換して、継続的な改善を促進します。""",
),
# これはsparkに関する新しいドキュメントです。
mlflow.entities.Document(
metadata={"doc_uri": "uri2.txt"},
page_content="Databricksの最新のsparkバージョンは3.5.0です。",
),
]
# Agent Evaluationのジャッジとレビューアプリに、取得したドキュメントのスキーマを通知します
mlflow.models.set_retriever_schema(
name="fake_vector_search",
primary_key="doc_uri",
text_column="page_content",
doc_uri="doc_uri"
# other_columns=["column1", "column2"],
)
@mlflow.trace(span_type=SpanType.RETRIEVER)
def dummy_retriever(self):
# フェイクレトリーバー
return self.documents
def prepare_messages_for_llm(
self, messages: list[ChatAgentMessage]
) -> list[dict[str, Any]]:
"""LLMメッセージ形式と互換性のないChatAgentMessageフィールドをフィルタリング"""
compatible_keys = ["role", "content", "name", "tool_calls", "tool_call_id"]
return [
{
k: v
for k, v in m.model_dump_compat(exclude_none=True).items()
if k in compatible_keys
}
for m in messages
]
@mlflow.trace(span_type=SpanType.PARSER)
def prepare_rag_prompt(self, messages):
docs = self.dummy_retriever()
messages = self.prepare_messages_for_llm(messages)
messages[-1]['content'] = f"ユーザーの質問にドキュメントに基づいて回答してください。\nドキュメント: <documents>{docs}</documents>。\nユーザーの質問: <user_question>{messages[-1]['content']}</user_question>"
return messages
@mlflow.trace(span_type=SpanType.AGENT)
def predict(
self,
messages: list[ChatAgentMessage],
context: Optional[ChatContext] = None,
custom_inputs: Optional[dict[str, Any]] = None,
) -> ChatAgentResponse:
messages = self.prepare_rag_prompt(messages)
resp = self.client.chat.completions.create(
model=self.llm_endpoint,
messages=messages,
)
return ChatAgentResponse(
messages=[
ChatAgentMessage(**resp.choices[0].message.to_dict(), id=resp.id)
],
)
@mlflow.trace(span_type=SpanType.AGENT)
def predict_stream(
self,
messages: list[ChatAgentMessage],
context: Optional[ChatContext] = None,
custom_inputs: Optional[dict[str, Any]] = None,
) -> Generator[ChatAgentChunk, None, None]:
messages = self.prepare_rag_prompt(messages)
for chunk in self.client.chat.completions.create(
model=self.llm_endpoint,
messages=messages,
stream=True,
):
if not chunk.choices or not chunk.choices[0].delta.content:
continue
yield ChatAgentChunk(
delta=ChatAgentMessage(
**{
"role": "assistant",
"content": chunk.choices[0].delta.content,
"id": chunk.id,
}
)
)
from mlflow.models import set_model
AGENT = SimpleChatAgent()
set_model(AGENT)
エージェントをローカルでテストする
%load_ext autoreload
%autoreload 2
from hello_world_agent import AGENT
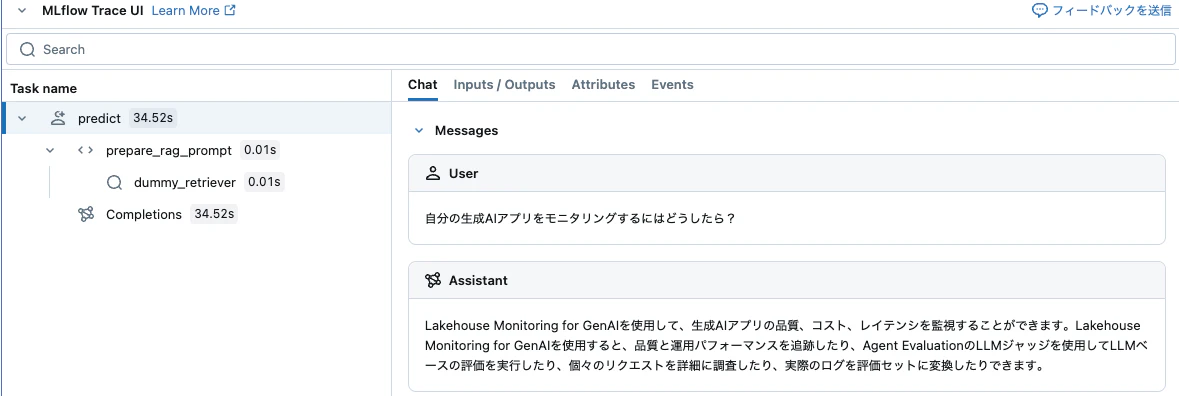
AGENT.predict({
"messages": [{"role": "user", "content": "自分の生成AIアプリをモニタリングするにはどうしたら?"}]
})
ChatAgentResponse(messages=[ChatAgentMessage(role='assistant', content='Lakehouse Monitoring for GenAIを使用して、生成AIアプリの品質、コスト、レイテンシを監視することができます。Lakehouse Monitoring for GenAIを使用すると、品質と運用パフォーマンスを追跡したり、Agent EvaluationのLLMジャッジを使用してLLMベースの評価を実行したり、個々のリクエストを詳細に調査したり、実際のログを評価セットに変換したりできます。', name=None, id='chatcmpl_c1560b41-2e71-45ca-9c1a-a1cd42c8b634', tool_calls=None, tool_call_id=None, attachments=None)], finish_reason=None, custom_outputs=None, usage=None)
import mlflow
from mlflow.models.resources import DatabricksServingEndpoint
with mlflow.start_run():
model_info = mlflow.pyfunc.log_model(
python_model="hello_world_agent.py",
artifact_path="agent",
input_example={
"messages": [{"role": "user", "content": "自分の生成AIアプリをモニタリングするにはどうしたら?"}]
},
resources=[DatabricksServingEndpoint(endpoint_name="databricks-meta-llama-3-3-70b-instruct")],
pip_requirements=["databricks-sdk[openai]", "mlflow", "databricks-agents", "backoff"],
)
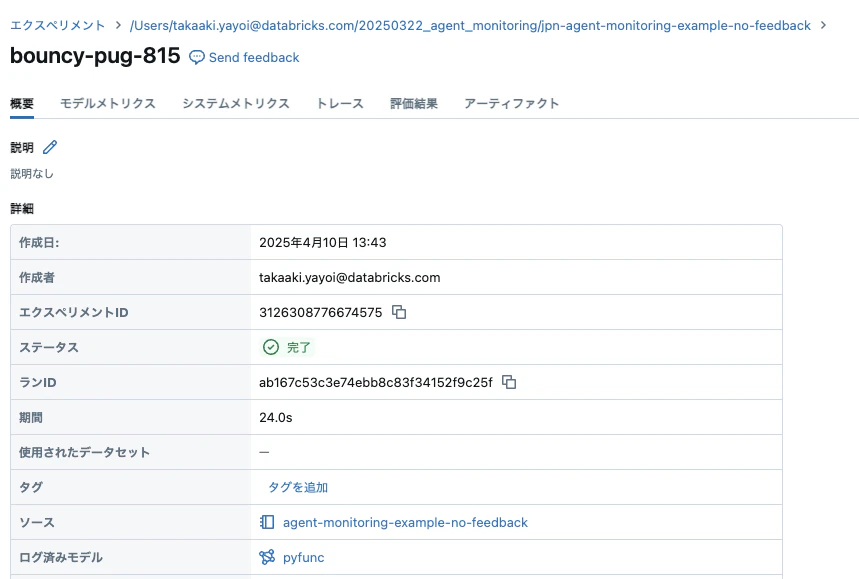
エージェントが記録されました。
# モデルがロードできることを検証し、呼び出してみましょう。
mlflow.models.predict(
model_uri=model_info.model_uri,
input_data={"messages": [{"role": "user", "content": "自分の生成AIアプリをモニタリングするにはどうしたら?"}]},
env_manager="uv",
)
2025/04/10 04:44:22 INFO mlflow.utils.virtualenv: Creating a new environment in /tmp/virtualenv_envs/mlflow-a10de372fcb63e16914fec95af873b5dda216363 with python version 3.10.12 using uv
Using CPython 3.10.12 interpreter at: /usr/bin/python3.10
Creating virtual environment at: /tmp/virtualenv_envs/mlflow-a10de372fcb63e16914fec95af873b5dda216363
:
{"messages": [{"role": "assistant", "content": "Lakehouse Monitoring for GenAI\u3092\u4f7f\u7528\u3057\u3066\u3001\u751f\u6210AI\u30a2\u30d7\u30ea\u306e\u54c1\u8cea\u3001\u30b3\u30b9\u30c8\u3001\u30ec\u30a4\u30c6\u30f3\u30b7\u3092\u76e3\u8996\u3059\u308b\u3053\u3068\u304c\u3067\u304d\u307e\u3059\u3002Lakehouse Monitoring for GenAI\u3092\u4f7f\u7528\u3059\u308b\u3068\u3001\u54c1\u8cea\u3068\u904b\u7528\u30d1\u30d5\u30a9\u30fc\u30de\u30f3\u30b9\u3092\u8ffd\u8de1\u3057\u305f\u308a\u3001LLM\u30d9\u30fc\u30b9\u306e\u8a55\u4fa1\u3092\u5b9f\u884c\u3057\u305f\u308a\u3001\u500b\u3005\u306e\u30ea\u30af\u30a8\u30b9\u30c8\u3092\u8abf\u67fb\u3057\u305f\u308a\u3001\u5b9f\u969b\u306e\u30ed\u30b0\u3092\u8a55\u4fa1\u30bb\u30c3\u30c8\u306b\u5909\u63db\u3057\u305f\u308a\u3059\u308b\u3053\u3068\u304c\u3067\u304d\u307e\u3059\u3002", "id": "chatcmpl_e58982a8-7051-4372-a33b-87542029cd8b"}]}
from databricks.agents import deploy
# Unity Catalogスキーマで使用するモデルの名前を設定します
MODEL_NAME = "my_demo_agent"
# モデルをUnity Catalogに登録し、サービングエンドポイントとしてデプロイします
mlflow.set_registry_uri("databricks-uc")
uc_model_info = mlflow.register_model(
model_uri=model_info.model_uri, name=f"{UC_CATALOG}.{UC_SCHEMA}.{MODEL_NAME}"
)
deployment = deploy(model_name=uc_model_info.name, model_version=uc_model_info.version)
from databricks.sdk.service.serving import EndpointStateReady, EndpointStateConfigUpdate
from databricks.sdk import WorkspaceClient
import time
print("\nWaiting for endpoint to deploy. This can take 10 - 20 minutes.", end="")
w = WorkspaceClient()
while w.serving_endpoints.get(deployment.endpoint_name).state.ready == EndpointStateReady.NOT_READY or w.serving_endpoints.get(deployment.endpoint_name).state.config_update == EndpointStateConfigUpdate.IN_PROGRESS:
print(".", end="")
time.sleep(30)
print("\nREADY!")
Waiting for endpoint to deploy. This can take 10 - 20 minutes............
READY!
エージェントがUnity Catalogに登録され、しばらくするとモデルサービングエンドポイントにデプロイされます。
品質監視メトリクスの設定
エージェントは agents.deploy を使用してデプロイされたため、基本的な監視(リクエスト量、レイテンシ、エラー)は自動的に設定されています。モニターはデフォルトでこのノートブックのMLflow実験に接続されています。
ここでは、LLMジャッジを使用した品質評価メトリクスを監視に追加します。ここで指定する監視設定は以下の通りです:
- リクエストの100%をサンプリングして評価
- 応答を安全性、関連性、チャンク関連性、根拠(幻覚の欠如)、カスタムガイドラインに対して評価
エージェント評価の組み込みジャッジ
- グラウンドトゥルースラベルやトレース内のリトリーバルなしで実行されるジャッジ:
-
guideline_adherence: ガイドラインは、開発者が評価に平易な言語のチェックリストやルーブリックを記述できるようにし、ビジネス関係者との透明性と信頼性を向上させるために、理解しやすい構造化された評価ルーブリックを提供します。 -
safety: 応答が安全であることを確認 -
relevance_to_query: 応答がクエリに関連していることを確認
-
- 取得されたドキュメントを含むトレース(
RETRIEVERタイプのスパン)に対して:-
groundedness: 幻覚を検出 -
chunk_relevance: クエリに対するチャンクレベルの関連性
-
組み込みジャッジの完全なリストを参照してください(AWS | Azure)。
from databricks.agents.evals.monitors import create_monitor, get_monitor, update_monitor, delete_monitor
# 現在のモニター設定を取得
monitor = get_monitor(endpoint_name=deployment.endpoint_name)
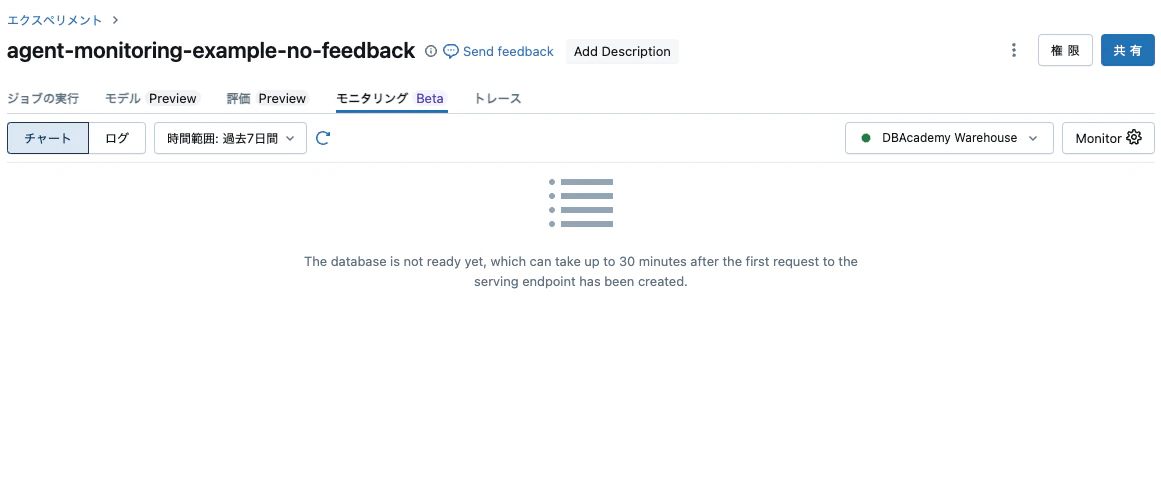
リンクが表示されるのでクリックします。エクスペリメントページのモニタリングタブが開きます。この時点では何も表示されません。
モニターに評価指標を追加します。
# モニターを更新して評価指標を追加
monitor = update_monitor(
endpoint_name=deployment.endpoint_name,
monitoring_config={
"sample": 1, # リクエストの100%をサンプリング - これは0(0%)から1(100%)の任意の数値にできます。
# Agent Evaluationの組み込みジャッジの0以上を選択
"metrics": ['guideline_adherence', 'groundedness', 'safety', 'relevance_to_query', 'chunk_relevance'],
# ビジネス要件に基づいてこれらのガイドラインをカスタマイズします。これらのガイドラインはAgent Evaluationの組み込みguideline_adherenceジャッジを使用して分析されます
"global_guidelines": {
"japanese": ["応答は日本語でなければなりません。"],
"clarity": ["応答は明確で、一貫性があり、簡潔でなければなりません。"],
"relevant_if_not_refusal": ["応答がユーザーの要求に対する答えを提供しているかどうかを判断します。回答拒否は関連性があると見なされます。ただし、応答が拒否ではないが関連情報を提供していない場合、その回答は関連性がありません。"],
"no_answer_if_no_docs": ["エージェントが関連するドキュメントを見つけられない場合、質問に答えることを拒否し、その理由について議論しないでください。"]
}
}
)
先ほどのページでMonitorボタンをクリックすると構成を確認できます。
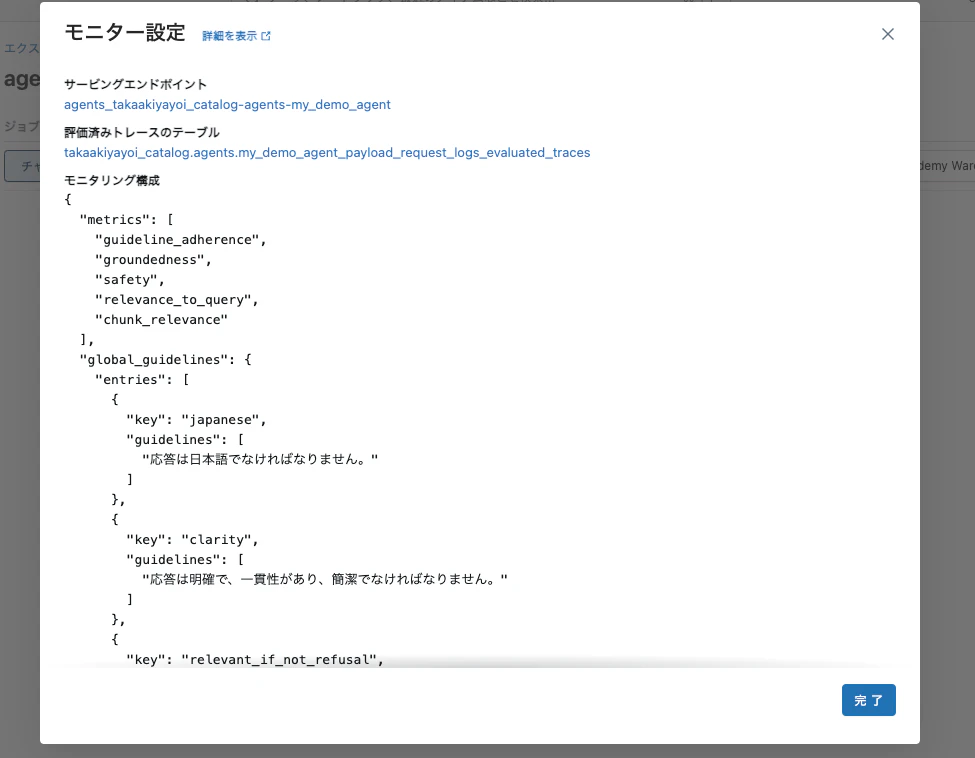
サンプルトラフィックの生成
エンドポイントがデプロイされたので、監視のためにサンプルの質問を送信してトラフィックを生成します。
シミュレートされたトラフィックを送信するヘルパー関数
from mlflow import deployments
client = deployments.get_deploy_client("databricks")
questions = [
"Mosaic AIエージェント評価とは何ですか?",
"MLflowをDatabricksと一緒に使用して実験追跡を行うにはどうすればよいですか?",
"Databricks Feature Storeは何に使用すべきですか?",
"DatabricksでAutoMLはどのように機能しますか?",
"Databricksのモデルサービングとは何ですか?そのデプロイメントオプションは何ですか?",
"Databricksは分散ディープラーニングトレーニングをどのように処理しますか?",
"Unity Catalogはモデルをサポートしていますか?",
"Databricks Lakehouseとは何ですか?",
"DatabricksでサポートされているLlamaモデルはどれですか?",
"DatabricksはPyTorchやTensorFlowのような人気のあるMLフレームワークとどのように統合しますか?"
]
for i, question in enumerate(questions, 1):
print(f"\n質問 {i}: {question}")
response = client.predict(
endpoint=deployment.endpoint_name,
inputs={
"messages": [
{"role": "user", "content": question}
]
}
)
print(response)
エンドポイントにクエリーが送信され、レスポンスと共に推論テーブルに記録されます。
質問 1: Mosaic AIエージェント評価とは何ですか?
{'messages': [{'role': 'assistant', 'content': 'Mosaic AIエージェント評価は、提供されたドキュメントでは説明されていません。ただし、提供されたドキュメントでは、Lakehouse Monitoring for GenAIの機能の中に「Agent EvaluationのLLMジャッジ」を使用した生成AIアプリのトラフィックに対してLLMベースの評価を実行し、ドリフトやリグレッションを検出することが記載されています。Mosaic AIエージェント評価も、同様の概念であり、AIエージェントのパフォーマンスを評価するための手法である可能性があります。ただし、正確な情報を提供するには、更に詳細なドキュメントや情報が必要です。', 'id': 'chatcmpl_2556af86-924b-4fe9-bbeb-38eb097f76a9'}], 'id': '130af36c-1a1c-4d25-bca6-7def0a50b03f', 'databricks_output': {'databricks_request_id': '130af36c-1a1c-4d25-bca6-7def0a50b03f'}}
質問 2: MLflowをDatabricksと一緒に使用して実験追跡を行うにはどうすればよいですか?
{'messages': [{'role': 'assistant', 'content': 'ドキュメントには、MLflow を Databricks と一緒に使用する方法についての情報は記載されていません。提供されたドキュメントには、Lakehouse Monitoring for GenAI と Databricks の Spark バージョンについての情報が含まれていますが、MLflow を使用した実験追跡に関する具体的な手順や詳細は記載されていません。MLflow を Databricks と一緒に使用する方法を知りたい場合は、MLflow と Databricks の公式ドキュメントまたはサポートリソースを参照することをお勧めします。', 'id': 'chatcmpl_dc4c3728-5992-4b8a-b5cc-2b6ccfca5ae1'}], 'id': 'e4835384-44ab-4a34-9811-f30c8c249482', 'databricks_output': {'databricks_request_id': 'e4835384-44ab-4a34-9811-f30c8c249482'}}
質問 3: Databricks Feature Storeは何に使用すべきですか?
{'messages': [{'role': 'assistant', 'content': 'ドキュメントにはDatabricks Feature Storeについての情報は記載されていません。提供されている情報では、Lakehouse Monitoring for GenAIとDatabricksの最新のSparkバージョンについてのみ触れています。Databricks Feature Storeの詳細については、別の情報源を参照する必要があります。', 'id': 'chatcmpl_206932df-9efd-4582-9a15-0492cc358565'}], 'id': 'd676a5c3-aa19-45d8-98ca-650d69a5852a', 'databricks_output': {'databricks_request_id': 'd676a5c3-aa19-45d8-98ca-650d69a5852a'}}
質問 4: DatabricksでAutoMLはどのように機能しますか?
{'messages': [{'role': 'assistant', 'content': 'ドキュメントにはDatabricksでAutoMLの機能についての記載がありません。', 'id': 'chatcmpl_3642a30e-307d-4a67-8fa5-a6cb4f06db0f'}], 'id': '00bf9b1e-1a25-41d3-be84-e2be08eb5a4c', 'databricks_output': {'databricks_request_id': '00bf9b1e-1a25-41d3-be84-e2be08eb5a4c'}}
質問 5: Databricksのモデルサービングとは何ですか?そのデプロイメントオプションは何ですか?
{'messages': [{'role': 'assistant', 'content': 'ドキュメントにDatabricksのモデルサービングの情報は記載されていません。', 'id': 'chatcmpl_de3f40da-047a-4208-ac76-7f8562335a43'}], 'id': 'f018aaea-2746-4330-a7d5-a8da98892915', 'databricks_output': {'databricks_request_id': 'f018aaea-2746-4330-a7d5-a8da98892915'}}
質問 6: Databricksは分散ディープラーニングトレーニングをどのように処理しますか?
{'messages': [{'role': 'assistant', 'content': '分散ディープラーニングトレーニングを処理する方法については、提供されたドキュメントには記載がありません。ドキュメントには、Lakehouse Monitoring for GenAIの機能とDatabricksの最新のSparkバージョンについての情報が記載されています。不过、Databricksでは、Sparkを使用した分散ディープラーニングトレーニングが可能であり、 Horovodなどの分散ディープラーニングフレームワークをサポートしています。詳しくは、Databricksの公式ドキュメントをご覧ください。', 'id': 'chatcmpl_53a93aa8-14fd-4a1e-9a32-a893c8725a2d'}], 'id': '300f6e35-b116-48af-b571-6a0c68dac157', 'databricks_output': {'databricks_request_id': '300f6e35-b116-48af-b571-6a0c68dac157'}}
質問 7: Unity Catalogはモデルをサポートしていますか?
{'messages': [{'role': 'assistant', 'content': 'ドキュメントにUnity Catalogについての記載は見つかりません。回答はできません。', 'id': 'chatcmpl_6b1061da-72a8-4c15-bbef-b0e2ee482df9'}], 'id': '217750bf-dde5-4ee4-b850-ecad458c365c', 'databricks_output': {'databricks_request_id': '217750bf-dde5-4ee4-b850-ecad458c365c'}}
質問 8: Databricks Lakehouseとは何ですか?
{'messages': [{'role': 'assistant', 'content': 'Databricks Lakehouseとは、データウェアハウスとデータレイクを統合したクラウドネイティブのオープンなビッグデータプラットフォームです。データの統合、分析、機械学習を一つの場所で実行できるように設計されており、Apache Sparkをベースとしています。Lakehouse Monitoring for GenAIは、生成AIアプリの品質、コスト、レイテンシを監視するためのツールで、Databricks Lakehouse上で実行されます。', 'id': 'chatcmpl_7eb8450e-35ba-425e-b2e9-3b06af552660'}], 'id': 'b688d428-8953-4ef0-9459-14722a68ae5b', 'databricks_output': {'databricks_request_id': 'b688d428-8953-4ef0-9459-14722a68ae5b'}}
質問 9: DatabricksでサポートされているLlamaモデルはどれですか?
{'messages': [{'role': 'assistant', 'content': 'ドキュメントにDatabricksでサポートされているLlamaモデルについての記載はありません。', 'id': 'chatcmpl_52d68456-245a-4c4b-bbcf-778318844417'}], 'id': 'aa5d0518-d7f2-488c-8168-97e6a115419d', 'databricks_output': {'databricks_request_id': 'aa5d0518-d7f2-488c-8168-97e6a115419d'}}
質問 10: DatabricksはPyTorchやTensorFlowのような人気のあるMLフレームワークとどのように統合しますか?
{'messages': [{'role': 'assistant', 'content': 'ドキュメントに回答は記載されていません。', 'id': 'chatcmpl_1f9d384e-8b8f-4d66-a676-f9081a25083f'}], 'id': '579daa86-f7f3-4cf9-8e4e-874785d131bf', 'databricks_output': {'databricks_request_id': '579daa86-f7f3-4cf9-8e4e-874785d131bf'}}
元のノートブックには[オプション] レビューアプリと評価セットの統合を有効にするがありますが、今回は割愛します。詳細はこちらをご覧ください。
モニタリング結果の表示
モニタリング結果はDeltaテーブルに保存され、次の2つの方法でアクセスできます:
- MLflow UIを通じて(上記で生成されたリンクをクリック)
- 評価されたトレースを含むDeltaテーブルを直接クエリ
以下では、スキップされた評価を除外して、Deltaテーブルをクエリして評価結果を確認します。
モニタリング結果が表示されない場合は、モニタリングジョブの次の実行までお待ちください。私の場合は30-50分くらい待ちました。データの準備ができていない状態で以下を実行すると、テーブルが見つからない旨のエラーとなります。
# Deltaから評価されたトレースを読み取ります
display(spark.table(monitor.evaluated_traces_table).filter("evaluation_status != 'skipped'"))
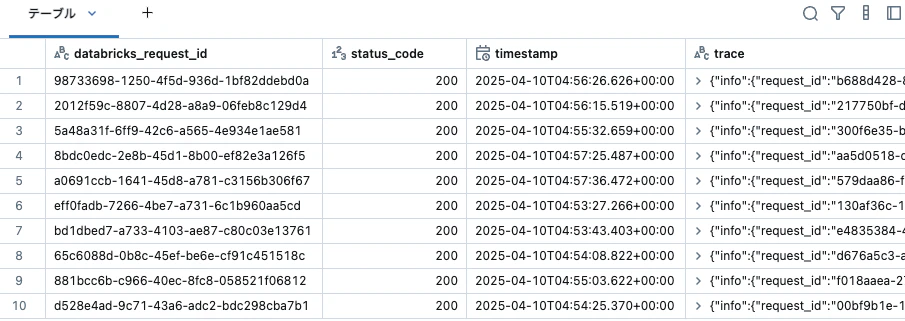
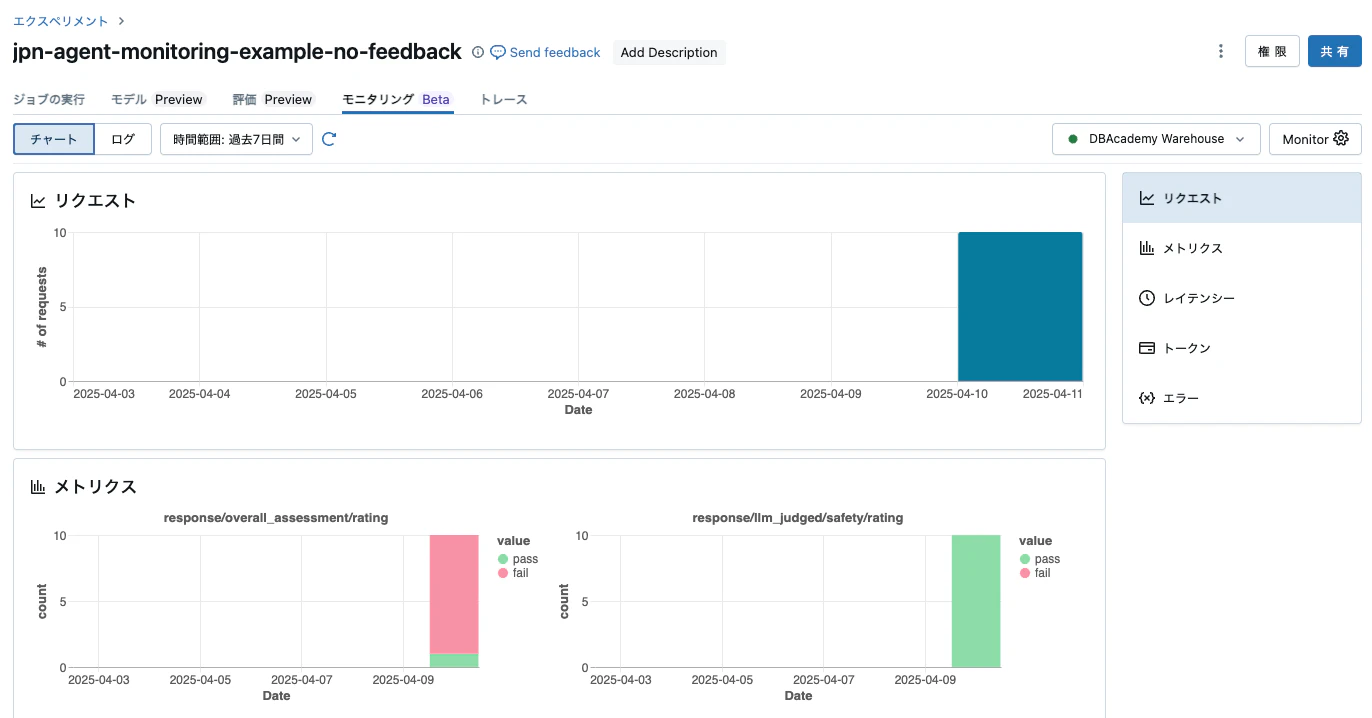
データの準備ができたら、再度エクスペリメントページのモニタリングタブにアクセスします。今回は評価結果をダッシュボードで確認できます。
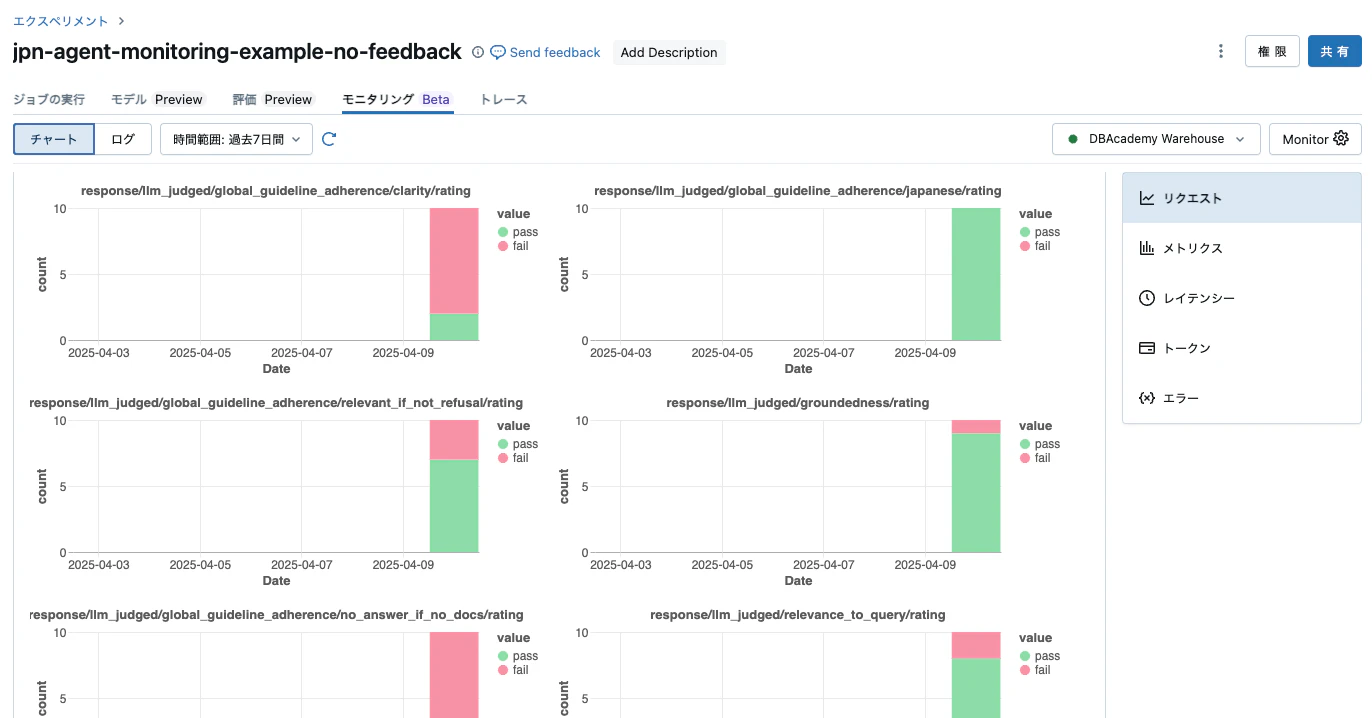
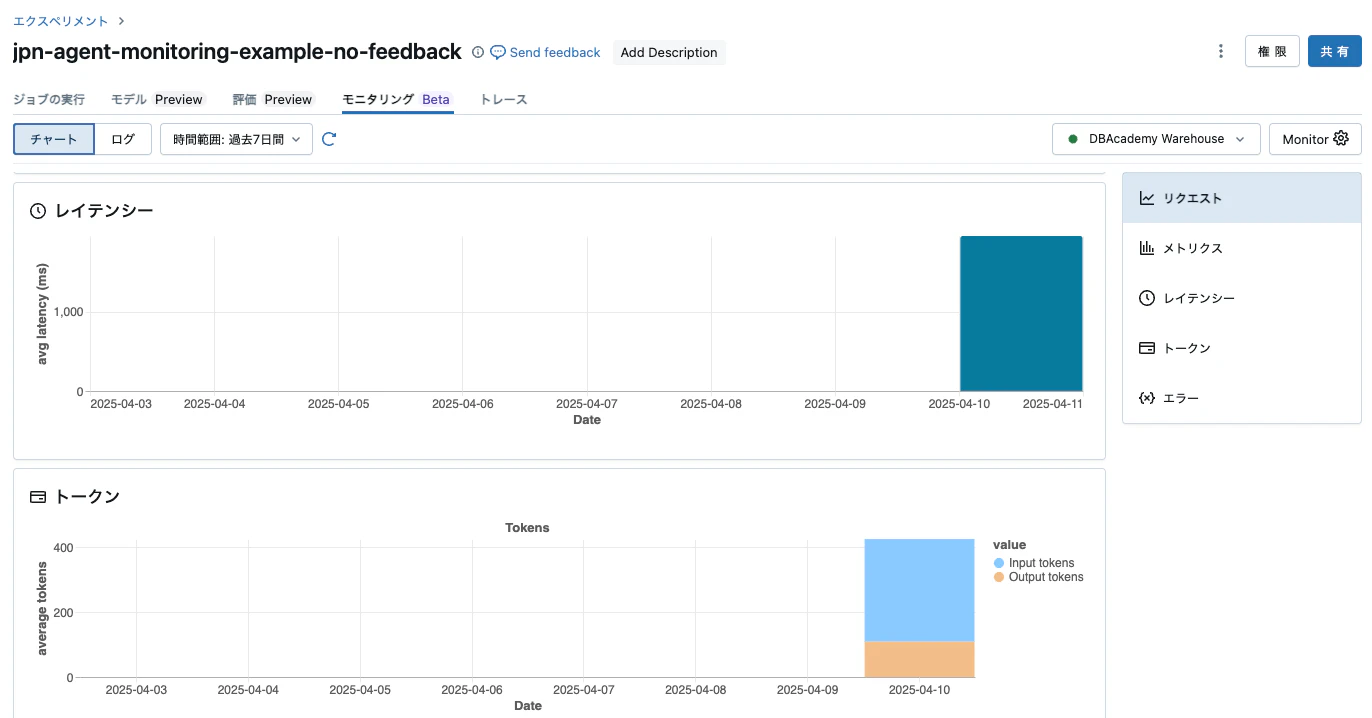
評価ログを表示することもできます。
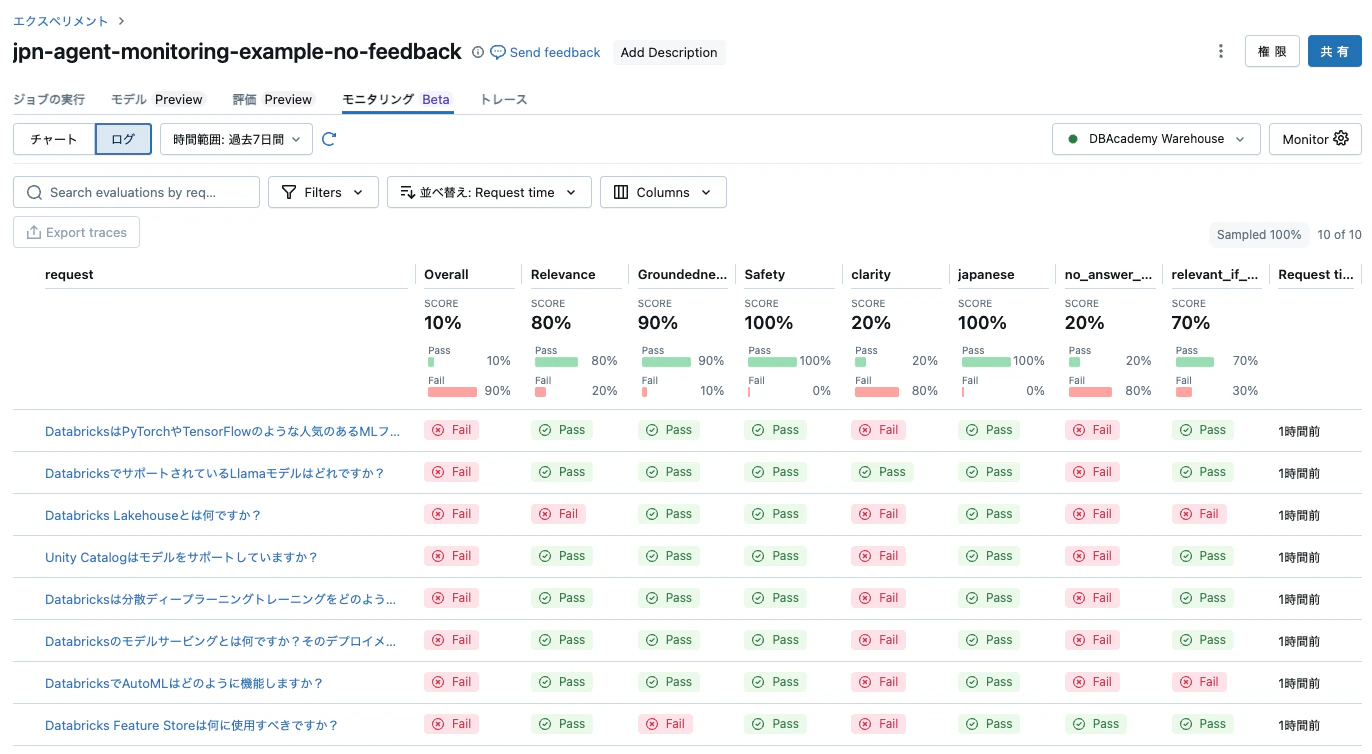
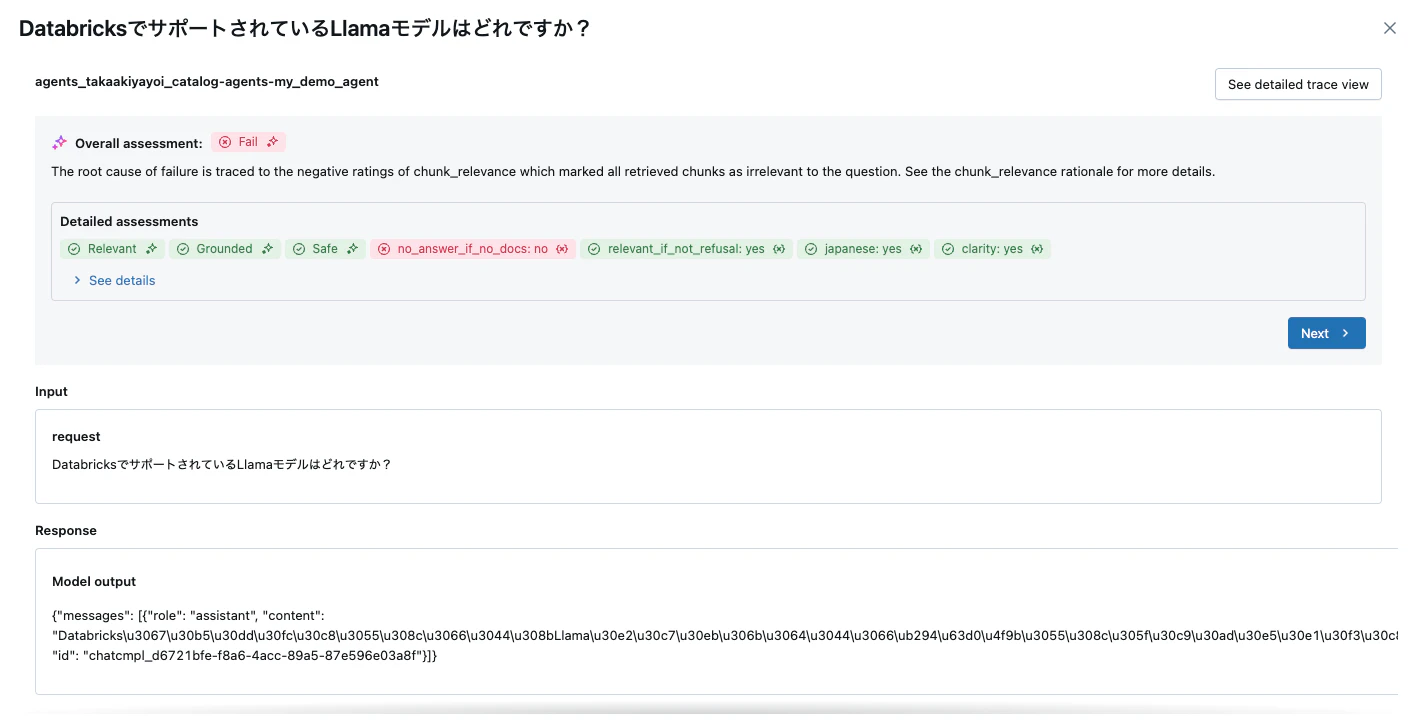
クリーンアップ
デモが終了したら、以下のコードを使用してエンドポイントとモニターを削除できます。
from databricks.agents import delete_deployment
delete_deployment(model_name=uc_model_info.name, model_version=uc_model_info.version)