復習も兼ねてこちらをウォークスルーします。
「Delta Lakeって結局なんだって」となることもあり、こちらの本でも復習してみました。無料でダウンロードできます。
Delta Lakeを理解するにはレイクハウスの概念の理解も重要です。
データウェアハウス、データレイクに次ぐアーキテクチャであるレイクハウス、上記書籍のP14に説明があります。
レイクハウスとは、ACIDトランザクション、データのバージョン管理、監査、インデックス、キャッシュ、クエリーの最適化のような分析DBMSの管理機能やパフォーマンス機能も提供する低コストかつ直接アクセス可能なストレージをベースにして構築されたデータ管理システムです。
ですので、レイクハウスのデータストアはストレージ、一般的にはクラウドのオブジェクトストレージです。データをオブジェクトストレージに格納しながらもDBMSの機能を活用できます。
では、このような仕組みをどのように実装するのか?となるわけですが、DatabricksではDelta Lakeを用いてこれを実現しています。
Delta Lakeの説明も上記書籍のP18にあります。
Delta Lakeは、データレイクのストレージフォーマットとメタデータ、キャッシュ機能、インデックス機能を組み合わせたオープンなテーブルフォーマットです。これらは、ACIDトランザクションやその他の管理機能を提供するための抽象化レベルを提供します。<中略>Delta Lakeは、ACIDトランザクション、スケーラブルなメタデータ操作、バッチからストリーミングをカバーする統合処理モデル、完全の監査履歴、SQLのデータ操作言語(DML)のサポートを提供します。
Delta Lake形式でデータを格納することで、上述の機能を活用することができ、データはオブジェクトストレージに格納しておきながらも、DBMSで必要となる機能を利用できるようになります。これによって、上述のレイクハウスを実現しているわけです。
このことから、以下のチュートリアルではテーブルを操作していく流れとなります。
テーブルの作成
# ソースからのデータロード
df = spark.read.load("/databricks-datasets/learning-spark-v2/people/people-10m.delta")
# テーブルへのデータの書き込み
table_name = "takaakiyayoi_catalog.delta_tutorial.people_10m"
df.write.saveAsTable(table_name)
テーブルが作成されました。
テーブルのメタデータの表示
SQLのDESCRIBE DETAILを使います。
display(spark.sql('DESCRIBE DETAIL takaakiyayoi_catalog.delta_tutorial.people_10m'))

テーブルのUPSERT
UPSERTはUPDATE + INSERTです。更新対象のテーブルにマッチするテーブルがあればUPDATE、マッチしない場合にはINSERTを行います。
以下の例では最初のブロックで一時ビューpeople_updatesを作成しています。一時ビューとはSparkセッションでのみ有効なビューです。その後のブロックでMERGE INTOでUPSERTを実行します。
%sql
CREATE OR REPLACE TEMP VIEW people_updates (
id, firstName, middleName, lastName, gender, birthDate, ssn, salary
) AS VALUES
(9999998, 'Billy', 'Tommie', 'Luppitt', 'M', '1992-09-17T04:00:00.000+0000', '953-38-9452', 55250),
(9999999, 'Elias', 'Cyril', 'Leadbetter', 'M', '1984-05-22T04:00:00.000+0000', '906-51-2137', 48500),
(10000000, 'Joshua', 'Chas', 'Broggio', 'M', '1968-07-22T04:00:00.000+0000', '988-61-6247', 90000),
(20000001, 'John', '', 'Doe', 'M', '1978-01-14T04:00:00.000+000', '345-67-8901', 55500),
(20000002, 'Mary', '', 'Smith', 'F', '1982-10-29T01:00:00.000+000', '456-78-9012', 98250),
(20000003, 'Jane', '', 'Doe', 'F', '1981-06-25T04:00:00.000+000', '567-89-0123', 89900);
MERGE INTO takaakiyayoi_catalog.delta_tutorial.people_10m
USING people_updates
ON people_10m.id = people_updates.id
WHEN MATCHED THEN UPDATE SET *
WHEN NOT MATCHED THEN INSERT *;
%sql
CREATE OR REPLACE TEMP VIEW people_updates (
id, firstName, middleName, lastName, gender, birthDate, ssn, salary
) AS VALUES
(9999998, 'Billy', 'Tommie', 'Luppitt', 'M', '1992-09-17T04:00:00.000+0000', '953-38-9452', 55250),
(9999999, 'Elias', 'Cyril', 'Leadbetter', 'M', '1984-05-22T04:00:00.000+0000', '906-51-2137', 48500),
(10000000, 'Joshua', 'Chas', 'Broggio', 'M', '1968-07-22T04:00:00.000+0000', '988-61-6247', 90000),
(20000001, 'John', '', 'Doe', 'M', '1978-01-14T04:00:00.000+0000', '345-67-8901', 55500),
(20000002, 'Mary', '', 'Smith', 'F', '1982-10-29T01:00:00.000+0000', '456-78-9012', 98250),
(20000003, 'Jane', '', 'Doe', 'F', '1981-06-25T04:00:00.000+0000', '567-89-0123', 89900);
MERGE INTO takaakiyayoi_catalog.delta_tutorial.people_10m
USING people_updates
ON people_10m.id = people_updates.id
WHEN MATCHED THEN UPDATE SET *
WHEN NOT MATCHED THEN INSERT *;
確認のために以下のSQLを実行します。
%sql
SELECT
firstName,
middleName,
lastName,
salary
FROM
takaakiyayoi_catalog.delta_tutorial.people_10m
WHERE
id in (
9999998,
9999999,
10000000,
20000001,
20000002,
20000003
)
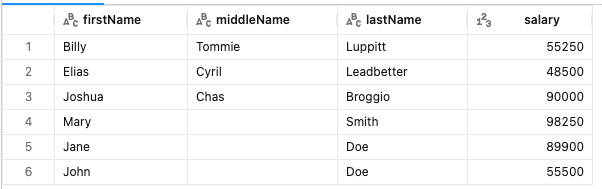
3行のみがヒットします。

上のMERGEを実行します。そして、再度SELECTを実行します。
%sql
SELECT
firstName,
middleName,
lastName,
salary
FROM
takaakiyayoi_catalog.delta_tutorial.people_10m
WHERE
id in (
9999998,
9999999,
10000000,
20000001,
20000002,
20000003
)
既存のレコードのsalaryが更新され、新たに3行が追加されました。
テーブルの読み込み
people_df = spark.read.table(table_name)
display(people_df)
SQLでも同じ結果を得ることができます。
%sql
SELECT * FROM takaakiyayoi_catalog.delta_tutorial.people_10m;
テーブルの更新
UPDATEで行けます。
%sql
UPDATE takaakiyayoi_catalog.delta_tutorial.people_10m SET gender = 'Female' WHERE gender = 'F';
UPDATE takaakiyayoi_catalog.delta_tutorial.people_10m SET gender = 'Male' WHERE gender = 'M';
gender列が置き換えられました。
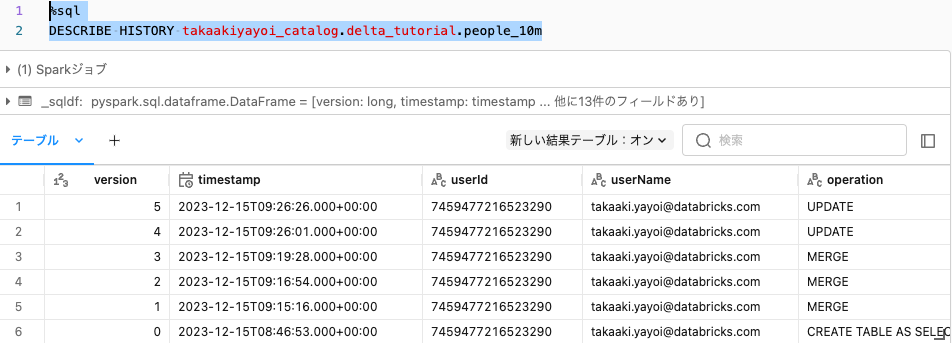
テーブル履歴の表示
Delta Lakeのテーブルでは更新処理がすべて記録されます。DESCRIBE HISTORYで履歴を表示できます。
%sql
DESCRIBE HISTORY takaakiyayoi_catalog.delta_tutorial.people_10m
特定バージョンのテーブルのクエリー(タイムトラベル)
バージョン番号を指定してクエリーを行うことができます。
%sql
SELECT
*
FROM
takaakiyayoi_catalog.delta_tutorial.people_10m VERSION AS OF 0
WHERE
id in (
9999998,
9999999,
10000000,
20000001,
20000002,
20000003
)
UPSERT前の状態が表示されます。

Optimizeによるテーブルの最適化
Delta Lakeの実態はオブジェクトストレージに保存されるファイルです。これに対して様々な更新処理を行うとファイルは小さいものに断片化していきます。この状態では複数ファイルにアクセスすることになり、検索性能の悪化につながります。
テーブルの更新で断片化したファイルをコンパクトにまとめることで検索性能を改善できます。OPTIMIZEコマンドを使います。
%sql
OPTIMIZE takaakiyayoi_catalog.delta_tutorial.people_10m;
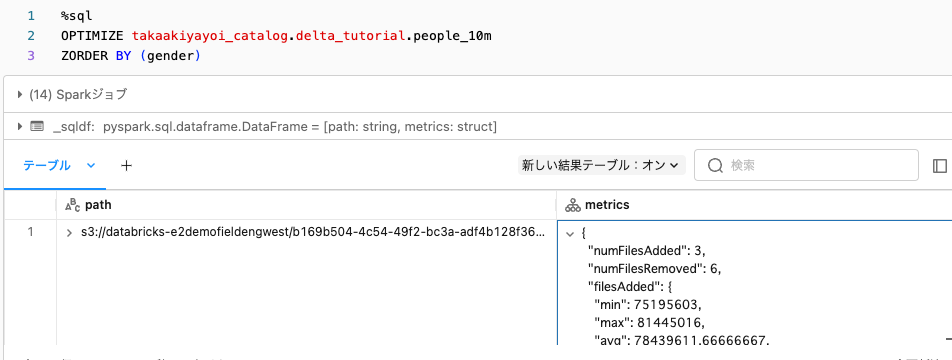
Z-orderによる検索性能改善
さらに検索性能を改善するために、検索キーの値が近しいファイルを局所化することができます。これがZ-orderingです。
%sql
OPTIMIZE takaakiyayoi_catalog.delta_tutorial.people_10m
ZORDER BY (gender)
OPTIMIZEコマンドも処理に時間を要しますので、深夜のバッチなどで動かすことが推奨となります。
Vacuumによるクリーンアップ
Delta Lakeテーブルを更新していくと、参照されないファイルなども発生します。これら古くなったファイルを削除するためにはVacuumコマンドを使用します。これによって、ストレージコストを削減できます。
%sql
VACUUM takaakiyayoi_catalog.delta_tutorial.people_10m
(理論上)容量無制限で低コストなオブジェクトストレージ上で様々なデータを効率にハンドリングできるようになるDelta Lake、ぜひお試しください!DatabricksではデフォルトフォーマットがDelta Lakeなので何も気にせずに活用いただけます。