ハマることがあるのでメモ。
initスクリプトを設定することで、クラスター起動時にシェルスクリプトを実行することができますので、ソフトウェアのインストールやネットワーク設定を行うことができます。便利ですが、デバッグする際には注意が必要です。
エラー発生時にクラスターのイベントログを見ても、initスクリプトが失敗したことしか確認できません。
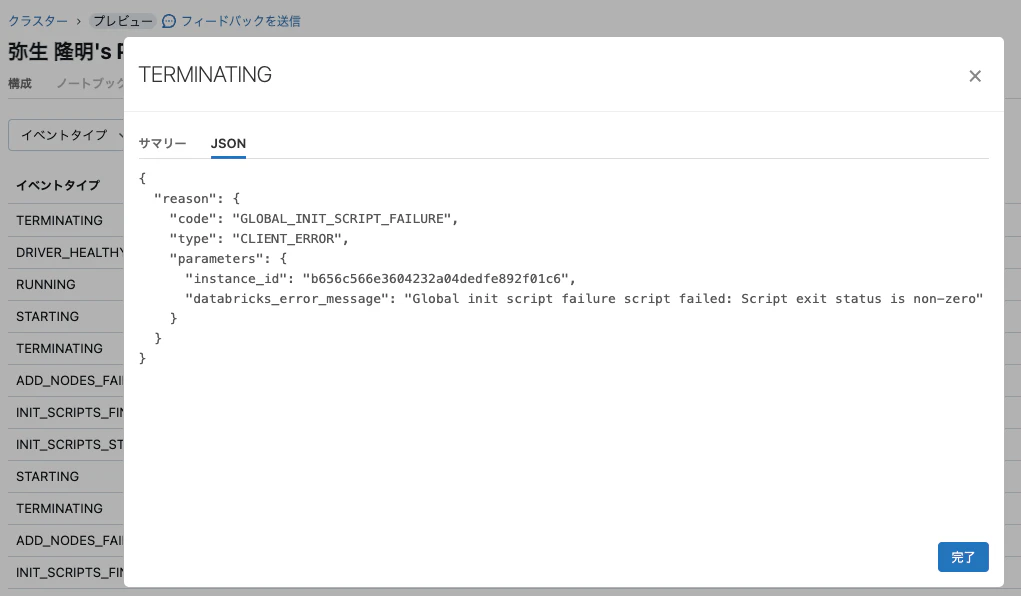
以下の手順を踏む必要があります。
- クラスターのログ配信を有効化します。
- initスクリプトが有効化されている状態でクラスターを起動します。
- initスクリプトのログが記録されます。
- initスクリプトを無効化してクラスターを起動します。
- initスクリプトのログを確認して問題を特定します。
- initスクリプトを修正して有効化します。
- クラスターが起動することを確認します。
クラスターログ配信の有効化
原因を特定するには、クラスターログのデリバリーを有効化する必要があります。
クラスター ログの配信にあるように、クラスターの設定を行います。

initスクリプトが有効化されている状態でクラスターを起動
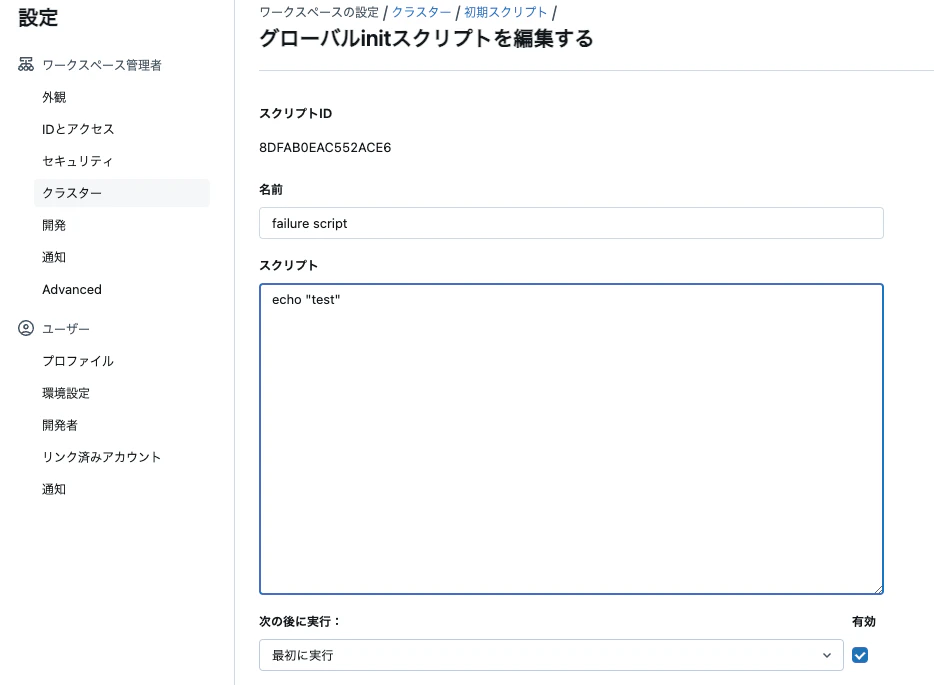
今回はグローバルinitスクリプトを使います。以下のように意図的に間違ったスクリプトを記述します。
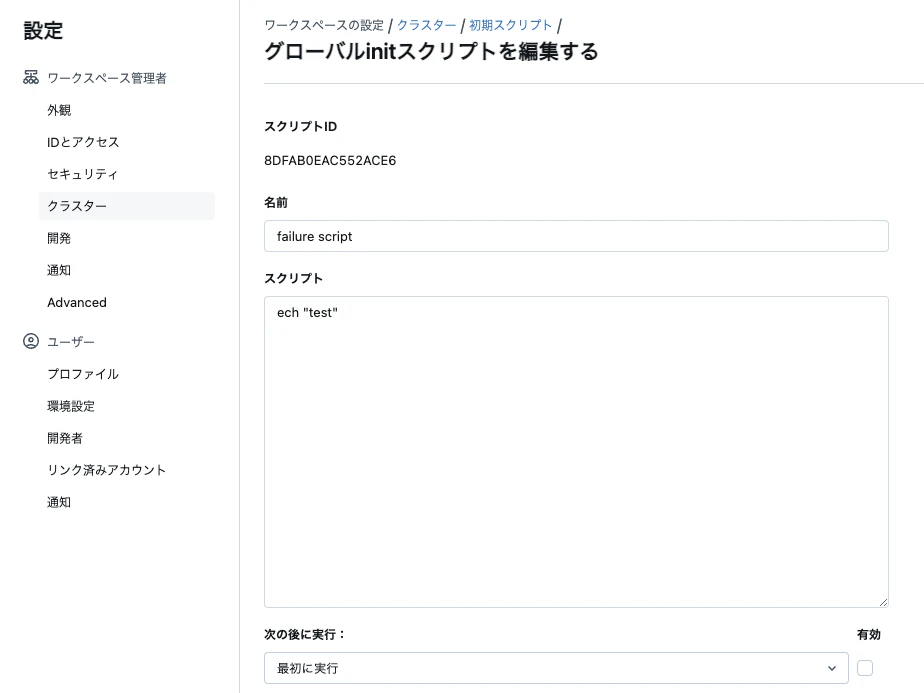
これでクラスターを起動すると冒頭のエラーでクラスターの起動に失敗します。
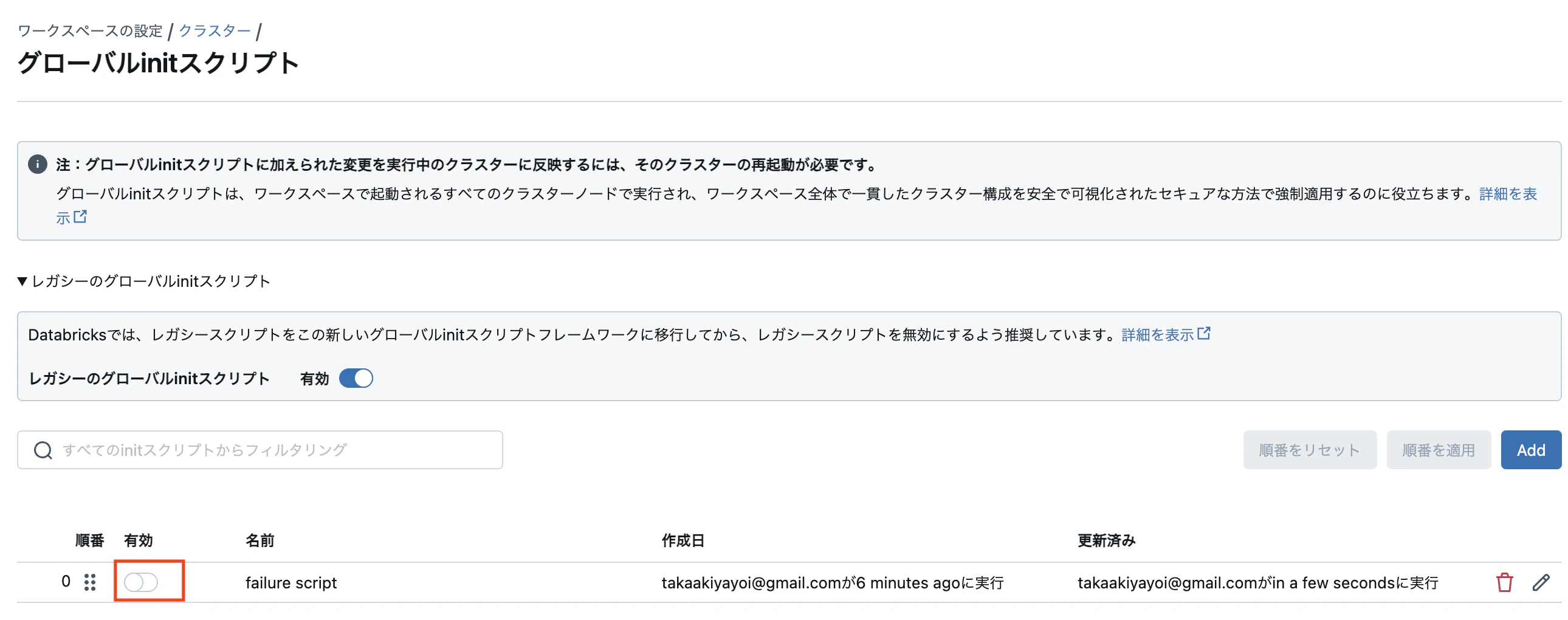
initスクリプトを無効化してクラスターを起動
クラスターが起動するように、initスクリプトを無効化します。
initスクリプトのログを確認して問題を特定
クラスターログのパスにはクラスターIDが使用されるので、クラスターIDを特定します。
# クラスターIDを取得
current_cluster_id = spark.conf.get("spark.databricks.clusterUsageTags.clusterId")
print(current_cluster_id)
0206-052938-gctb3cax
パスに埋め込んでログファイルを一覧します。
# 当該クラスターのinit scriptのログを一覧
dir_list = dbutils.fs.ls(f"/cluster-logs/{current_cluster_id}/init_scripts")
display(dbutils.fs.ls(dir_list[0].path))
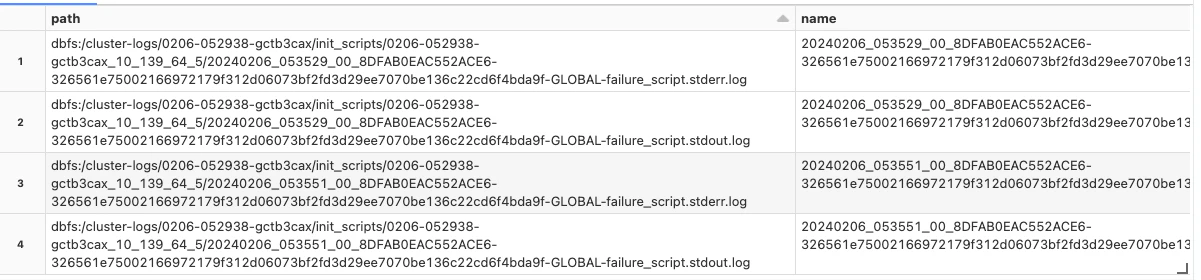
エラーは...stderr.logに記録されるので中身を確認します。こちらは自動化してないので上のセルをコピーして以下のセルに貼り付けてます。
# 末尾が .stderr.log のファイルの内容を表示
dbutils.fs.head("dbfs:/cluster-logs/0206-052938-gctb3cax/init_scripts/0206-052938-gctb3cax_10_139_64_5/20240206_053551_00_8DFAB0EAC552ACE6-326561e75002166972179f312d06073bf2fd3d29ee7070be136c22cd6f4bda9f-GLOBAL-failure_script.stderr.log")
'bash: line 1: ech: command not found\n'
当たり前ですがechoではなくechにしているので、そのようなコマンドがないと怒られています。問題が特定できました。
initスクリプトを修正して有効化
直します。そして、有効化します。
クラスターが起動することを確認
起動しました!

デバッグが完了したら、クラスターログ配信の有効化で有効化したログ配信はオフにして問題ありません。