2024/4/12に翔泳社よりApache Spark徹底入門を出版します!

書籍のサンプルノートブックをウォークスルーしていきます。Python/Chapter10/10-3 Baseline Modelと10-4 One Hot Encoding、10-5 Log Scaleの内容となります。
翻訳ノートブックのリポジトリはこちら。
ノートブックはこちら
ベースラインモデルの構築
トレーニングデータセットの平均priceを計算して、テストデータセットに対する予測カラムとして使用し、結果を評価します。
from pyspark.sql.functions import avg, lit
filePath = "/databricks-datasets/learning-spark-v2/sf-airbnb/sf-airbnb-clean.parquet"
airbnbDF = spark.read.parquet(filePath)
trainDF, testDF = airbnbDF.randomSplit([.8, .2], seed=42)
avgPrice = float(trainDF.select(avg("price")).first()[0])
predDF = testDF.withColumn("avgPrediction", lit(avgPrice))
from pyspark.ml.evaluation import RegressionEvaluator
regressionMeanEvaluator = RegressionEvaluator(predictionCol="avgPrediction", labelCol="price", metricName="rmse")
print(f"The RMSE for predicting the average price is: {regressionMeanEvaluator.evaluate(predDF):.2f}")
The RMSE for predicting the average price is: 240.71
ワンホットエンコーディング
このノートブックでは、モデルの追加の特徴量を追加し、カテゴリー型の特徴量をどのように取り扱うのかを議論します。
filePath = "/databricks-datasets/learning-spark-v2/sf-airbnb/sf-airbnb-clean.parquet"
airbnbDF = spark.read.parquet(filePath)
Train/Testの分割
アップルツーアップルで比較できるように、前回のノートブックと同じシードを用いて同じように80/20の分割を行いましょう(クラスター構成を変更していない場合に限ります!)。
trainDF, testDF = airbnbDF.randomSplit([.8, .2], seed=42)
オプション1: StringIndexer, OneHotEncoder, VectorAssembler
ここでは、カテゴリー型の変数に対してワンホットエンコーディング(OHE)を行います。使用する最初のアプローチでは、StringIndexer, OneHotEncoder, VectorAssemblerを組み合わせます。
最初に、文字列ラベルのカラムを、ラベルインデックスのMLカラムにマッピングするためにStringIndexerを使用する必要があります Python/Scala。
そして、StringIndexerのアウトプットにOneHotEncoderを適用します Python/Scala。
from pyspark.ml.feature import OneHotEncoder, StringIndexer
categoricalCols = [field for (field, dataType) in trainDF.dtypes
if dataType == "string"]
indexOutputCols = [x + "Index" for x in categoricalCols]
oheOutputCols = [x + "OHE" for x in categoricalCols]
stringIndexer = StringIndexer(inputCols=categoricalCols,
outputCols=indexOutputCols,
handleInvalid="skip")
oheEncoder = OneHotEncoder(inputCols=indexOutputCols,
outputCols=oheOutputCols)
これで、数値特徴量とOHEされたカテゴリー型の特徴量を組み合わせることができます。
from pyspark.ml.feature import VectorAssembler
numericCols = [field for (field, dataType) in trainDF.dtypes
if ((dataType == "double") & (field != "price"))]
assemblerInputs = oheOutputCols + numericCols
vecAssembler = VectorAssembler(inputCols=assemblerInputs,
outputCol="features")
オプション2: RFormula
StringIndexerとOneHotEncoderに手動でどのカラムがカテゴリー型かを指定するのではなく、RFormulaは自動でこれらのことを行います Python/Scala。
RFormulaを用いることで、文字列型のカラムがある場合、カテゴリー型の特徴量としてそれらを取り扱い、文字列のインデックスの作成とワンホットエンコーディングを行います。それ以外の場合は何もしません。そして、ワンホットエンコーディングされた特徴量と数値特徴量を、featuresと呼ばれる単一のベクトルにまとめます。
from pyspark.ml.feature import RFormula
rFormula = RFormula(formula="price ~ .", featuresCol="features", labelCol="price", handleInvalid="skip")
線形回帰
すべての特徴量に対応したので、線形回帰モデルを構築しましょう。
from pyspark.ml.regression import LinearRegression
lr = LinearRegression(labelCol="price", featuresCol="features")
パイプライン
これらすべてのステージをパイプラインにまとめます。Pipelineはすべてのトランスフォーマーとエスティメーターを整理するための手段です Python/Scala。
オプション1(StringIndexer, OneHotEncoderEstimator, VectorAssembler)とオプション2(RFormula)で同じ結果になることを検証します。
# オプション 1: StringIndexer + OHE + VectorAssembler
from pyspark.ml import Pipeline
stages = [stringIndexer, oheEncoder, vecAssembler, lr]
pipeline = Pipeline(stages=stages)
pipelineModel = pipeline.fit(trainDF)
predDF = pipelineModel.transform(testDF)
predDF.select("features", "price", "prediction").show(5)
+--------------------+-----+------------------+
| features|price| prediction|
+--------------------+-----+------------------+
|(98,[0,3,6,22,43,...| 85.0| 55.86406437022288|
|(98,[0,3,6,22,43,...| 45.0| 22.87558895398388|
|(98,[0,3,6,22,43,...| 70.0|27.382602888721067|
|(98,[0,3,6,12,42,...|128.0|-91.50712171182795|
|(98,[0,3,6,12,43,...|159.0| 94.66621817641771|
+--------------------+-----+------------------+
only showing top 5 rows
# オプション 2: RFormula
from pyspark.ml import Pipeline
pipeline = Pipeline(stages = [rFormula, lr])
pipelineModel = pipeline.fit(trainDF)
predDF = pipelineModel.transform(testDF)
predDF.select("features", "price", "prediction").show(5)
+--------------------+-----+------------------+
| features|price| prediction|
+--------------------+-----+------------------+
|(98,[0,3,6,7,23,4...| 85.0| 55.40518338251741|
|(98,[0,3,6,7,23,4...| 45.0|22.558643930734434|
|(98,[0,3,6,7,23,4...| 70.0|27.035891181432817|
|(98,[0,3,6,7,13,4...|128.0|-91.29310091873367|
|(98,[0,3,6,7,13,4...|159.0| 94.66473870534765|
+--------------------+-----+------------------+
only showing top 5 rows
モデルの評価: RMSE
from pyspark.ml.evaluation import RegressionEvaluator
regressionEvaluator = RegressionEvaluator(predictionCol="prediction", labelCol="price", metricName="rmse")
rmse = round(regressionEvaluator.evaluate(predDF), 2)
print(f"RMSE is {rmse}")
RMSE is 220.69
R2
R2はどうなっているでしょうか?
r2 = round(regressionEvaluator.setMetricName("r2").evaluate(predDF), 2)
print(f"R2 is {r2}")
R2 is 0.16
pipelinePath = "/tmp/sf-airbnb/lr-pipeline-model"
pipelineModel.write().overwrite().save(pipelinePath)
モデルのロード
モデルでロードする際、ロードし直すモデルのタイプを知っている必要があります(線形回帰、あるいはロジスティック回帰モデル?)。
このため、常に汎用的なPipelineModelをロードできるように、お使いのトランスフォーマーとエスティメーターをパイプラインに組み込むことをお勧めします。
from pyspark.ml import PipelineModel
savedPipelineModel = PipelineModel.load(pipelinePath)
分散環境
分散環境において線形回帰がどのように実装されているのか、ボトルネックが何かを学ぶことに興味があるのであれば、以下の講義スライドをチェックしてください:
ログスケール
このラボでは、ラベルをログスケールに変換し、ログスケールで予測を行い、結果を評価するために指数関数を取るようにすることでモデルのパフォーマンスを改善します。
filePath = "/databricks-datasets/learning-spark-v2/sf-airbnb/sf-airbnb-clean.parquet"
airbnbDF = spark.read.parquet(filePath)
(trainDF, testDF) = airbnbDF.randomSplit([.8, .2], seed=42)
display(trainDF)
priceのヒストグラムを表示してみます。
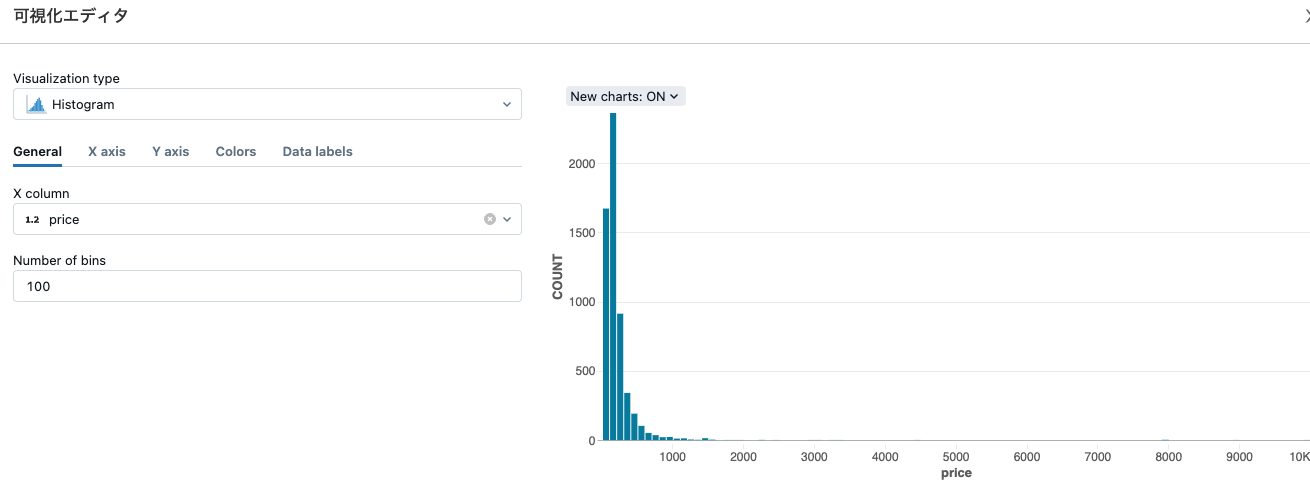
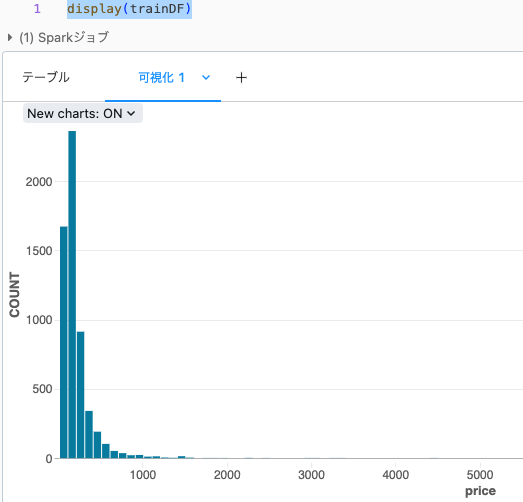
対数分布しているようですので、ログスケールに変換します。
from pyspark.sql.functions import col, log
from pyspark.ml import Pipeline
from pyspark.ml.feature import RFormula
from pyspark.ml.regression import LinearRegression
logTrainDF = trainDF.withColumn("log_price", log(col("price")))
logTestDF = testDF.withColumn("log_price", log(col("price")))
rFormula = RFormula(formula="log_price ~ . - price", featuresCol="features", labelCol="log_price", handleInvalid="skip")
lr = LinearRegression(labelCol="log_price", predictionCol="log_pred")
pipeline = Pipeline(stages = [rFormula, lr])
pipelineModel = pipeline.fit(logTrainDF)
predDF = pipelineModel.transform(logTestDF)
指数関数
RMSEを解釈するためには、予測結果をログスケールから戻す必要があります。
from pyspark.ml.evaluation import RegressionEvaluator
from pyspark.sql.functions import col, exp
expDF = predDF.withColumn("prediction", exp(col("log_pred")))
regressionEvaluator = RegressionEvaluator(labelCol="price", predictionCol="prediction")
rmse = regressionEvaluator.setMetricName("rmse").evaluate(expDF)
r2 = regressionEvaluator.setMetricName("r2").evaluate(expDF)
print(f"RMSE is {rmse}")
print(f"R2 is {r2}")
RMSE is 208.41093081345025
R2 is 0.25039912467770375
先ほどはRMSEは220.69だったので、精度が改善されていることがわかります。