DatabricksのAuto Loaderに記載されているサンプルはCSVが対象のものでしたが、Parquetを対象としたものが見当たらなかったのでサンプルを作成しました。
このサンプルでは、ファイルのアップロード先となるディレクトリにファイルが格納されると差分ファイルのみを読み込み、Delta Lake形式で書き込みを行うパイプラインを構築しています。
サンプルの説明
セットアップ
# ファイルのアップロード先を作成
user_dir = 'takaaki.yayoi@databricks.com'
upload_path = "/FileStore/shared_uploads/" + user_dir + "/parquet_data_upload"
dbutils.fs.mkdirs(upload_path)
ここでは、Sparkの構造化ストリーミング(Structured Streaming)を活用しており、差分のみを処理するようにチェックポイントを作成するように設定します。チェックポイントを作成することで、Sparkがどこまで処理を行なったのかを常に記録し、クラスターを停止し、再度起動した後でも差分ファイルのみを処理するように動作します。
# チェックポイントのパス
checkpoint_path = '/tmp/delta/parquet_data/_checkpoints'
# 書き込み先のパス
write_path = '/tmp/delta/parquet_data'
ファイルのアップロード
1つのParquetファイルを上記upload_pathにアップロードしておきます。ここでは、以下のParquetファイルを使用しています。
parquet-dotnet/postcodes.plain.parquet at master · elastacloud/parquet-dotnet
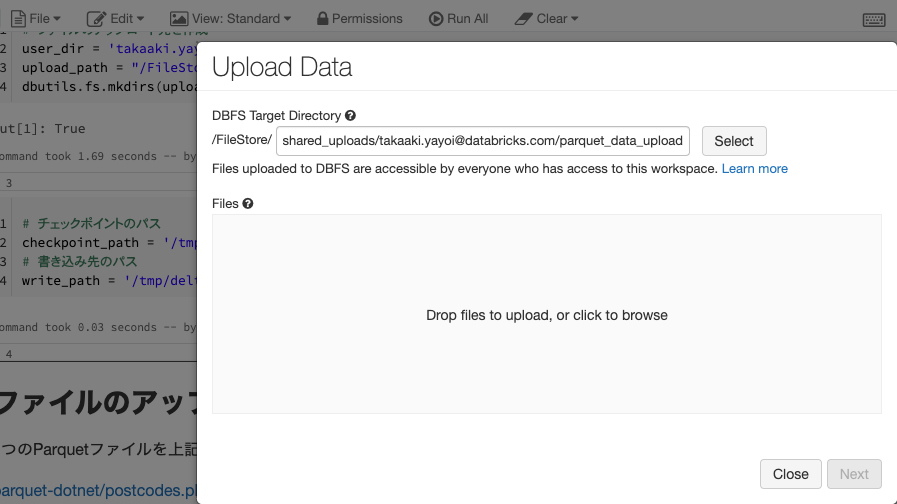
ファイルをアップロードするには、画面上部のメニューFile > Upload Dataで上記のupload_pathを選択し、ファイルをドラッグ&ドロップします。
スキーマの取得
Parquetに対する構造化ストリーミングでは、明示的なスキーマの指定が必要となるので、先ほどアップロードしたParquetファイルを読み込み、スキーマを取得します。
# Parquetファイルのスキーマを取得するために一旦読み込みます
parquetFile = spark.read.parquet(f"{upload_path}/postcodes_plain_1.parquet")
parquetFile.schema
Auto Loaderの起動
upload_pathの場所にアップロードされたファイルを読み込むストリームと、write_pathにDelta Lake形式で書き込むストリームを起動します。
# upload_pathの場所に到着するファイルを読み込むストリームのセットアップ
df = spark.readStream.format('cloudFiles') \
.option('cloudFiles.format', 'parquet') \
.option('header', 'true') \
.schema(parquetFile.schema) \
.load(upload_path)
# ストリームを起動します。
# upload_pathにアップロード済みの全てのファイルの記録を保持するためにcheckpoint_pathを使用します。
# 最後のチェック以降のファイルに対して、新規にアップロードされたファイルのデータをwrite_pathに書き込みます
df.writeStream.format('delta') \
.option('checkpointLocation', checkpoint_path) \
.start(write_path)
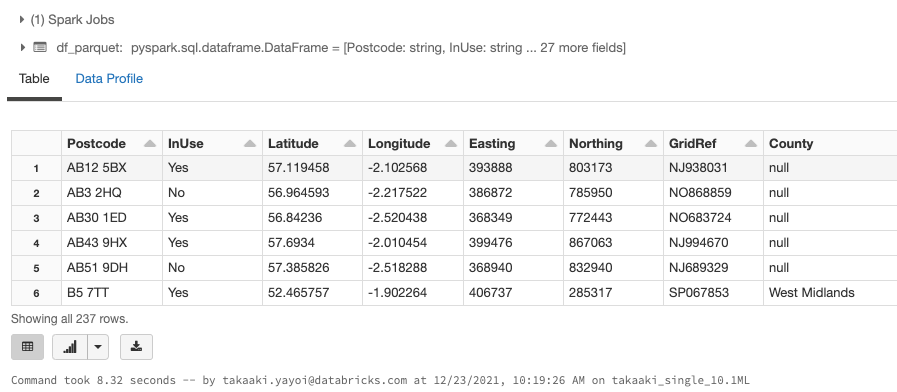
Delta Lakeの読み込み
Delta Lake形式でデータが書き込まれていることを確認します。
df_parquet = spark.read.format('delta').load(write_path)
display(df_parquet)
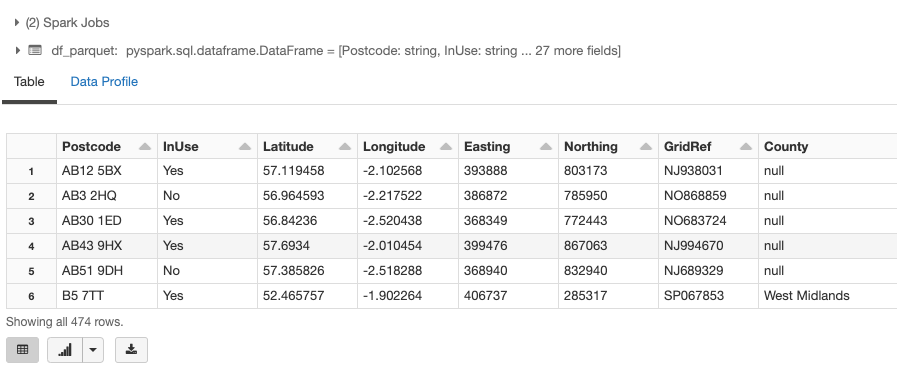
クラスターの停止・起動
一度、クラスターを停止します。クラスターを再起動後、上のストリームを起動し、追加のParquetファイル(上のファイルのコピー)をupload_pathにアップロードします。上でAuto Loaderのチェックポイントを作成しているので、Auto Loaderは新たにアップロードされたファイルのみを処理します。
df_parquet = spark.read.format('delta').load(write_path)
display(df_parquet)
サンプル