Databricksで高品質、高パフォーマンスなETLパイプラインを構築できるソリューションがDelta Live Tables(略してDLT)です。
こちらの記事でクイックスタートを説明していますが、一年以上に書いたものなので改めてDLTの画面をウォークスルーしてみました。
Delta Live Tablesとは
Delta Live Tablesは、信頼性が高く、維持が容易でテスト可能なデータ処理パイプラインを構築するためのフレームワークです。データに対する変換処理を定義すると、Delta Live Tablesはタスクのオーケストレーション、クラスター管理、モニタリング、データ品質、エラー処理を行います。そして、Delta Live Tablesはそれぞれの処理ステップであなたが定義したターゲットスキーマに基づき、どのようにデータが変換されるのかを管理します。

また、Delta Live Tablesのエクスペクテーションを活用してデータ品質を維持することもできます。エクスペクテーションによって、期待されるデータ品質を定義し、エクスペクテーションに沿わないデータをどのように取り扱うのかを定義することができます。

Delta Live Tablesのパイプラインは、Databricksノートブックを使用して簡単に作成することができます。
なお、DLTはメダリオンアーキテクチャを前提としていますので、こちらのコンセプトを理解しておくことをお勧めします。
メダリオンアーキテクチャは、レイクハウスに格納されているデータの品質を示す一連のデータレイヤーを表現します。企業のデータプロダクトに対して信頼できる唯一の情報源(single source of truth)を構築するために、Databricksではマルチレイヤーのアプローチを取ることをお勧めしています。このアーキテクチャは、公立的な分析に最適化されたレイアウトでデータ格納される前の検証、変換を行う複数のレイヤーをデータが追加する際の、原子性、一貫性、分離性、耐久性を保証します。ブロンズ(生)、シルバー(検証済み)、ゴールド(拡張済み)という用語はそれぞれのレイヤーにおけるデータの品質を表現しています。
クイックスタートノートブックのウォークスルー
本記事ではDelta Live TablesパイプラインとWikipediaクリックストリームデータを用いてデモをお見せします。Wikipediaクリックストリームデータを用いて以下のことを行います。
- 生のJSONクリックストリームデータをテーブルに読み込みます。
- 生データテーブルからレコードを読み込み、Delta Live Tablesのエクスペクテーションを用いて、クレンジングされたデータを格納する新たなテーブルを作成します。
- Delta Live Tablesのクエリーを行い、クレンジングデータテーブルのレコードから新たなデータセットを作成します。
以下のノートブックを使用します。なお、Pythonのノートブックでも同様のことが可能です。
パイプラインの準備
上のノートブックだけでもDLTを実行することは可能ですが、追加のパラメーターを設定することで、DLTの取り回しがさらに楽になります。
ヘルパーノートブックの作成
./Includes/setupというノートブックを作成し、以下のロジックを記述します。こちらを実行することで、DLTパイプラインで使用するデータベースやストレージロケーションを設定します。
import pyspark.sql.functions as F
import re
course = "dlt"
username = spark.sql("SELECT current_user()").collect()[0][0]
userhome = f"dbfs:/user/{username}/{course}"
database = f"""{course}_{re.sub("[^a-zA-Z0-9]", "_", username)}_db"""
print(f"""
username: {username}
userhome: {userhome}
database: {database}""")
dbutils.widgets.text("mode", "setup")
mode = dbutils.widgets.get("mode")
if mode == "reset":
spark.sql(f"DROP DATABASE IF EXISTS {database} CASCADE")
dbutils.fs.rm(userhome, True)
spark.sql(f"CREATE DATABASE IF NOT EXISTS {database}")
spark.sql(f"USE {database}")
if mode == "cleanup":
spark.sql(f"DROP DATABASE IF EXISTS {database} CASCADE")
dbutils.fs.rm(userhome, True)
storage_location = userhome + "/output"
準備用ノートブックの作成、実行
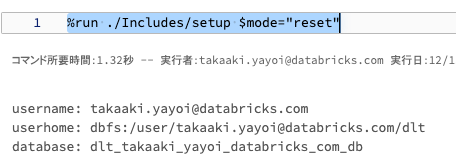
ワークスペースの現在フォルダにDLT-mainというPythonノートブックを作成します。名前は任意です。
%run ./Includes/setup $mode="reset"
上のコマンドを実行することで、ヘルパーノートブックが実行されます。
以下のコマンドを実行してストレージの場所を取得しておきます。
storage_location.split(':')[1]

パイプラインのノートブックの作成
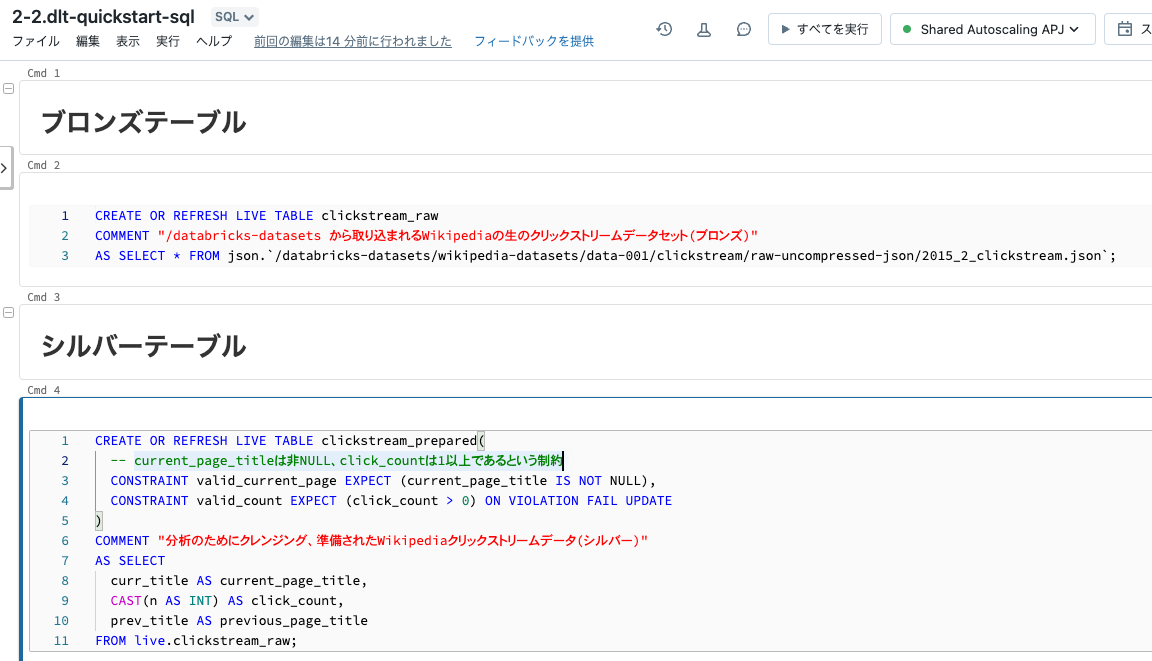
DLTでは、パイプラインの処理を記述するのではなく、パイプラインの各ステップを宣言するアプローチをとっています。これによって、各ステップの意味が明確になることに加え、間の処理はDLTが面倒を見てくれます。dlt-quickstart-sqlというSQLノートブックを作成し、以下のロジックを記述します。
ブロンズテーブル
ブロンズテーブルでは生のデータを保持します。
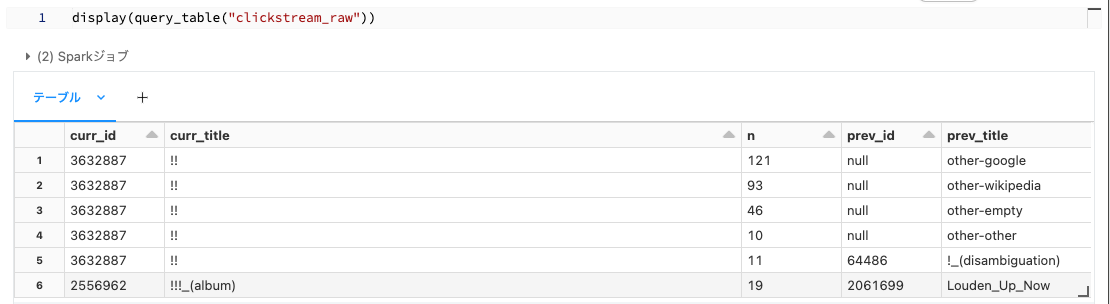
CREATE OR REFRESH LIVE TABLE clickstream_raw
COMMENT "/databricks-datasets から取り込まれるWikipediaの生のクリックストリームデータセット(ブロンズ)"
AS SELECT * FROM json.`/databricks-datasets/wikipedia-datasets/data-001/clickstream/raw-uncompressed-json/2015_2_clickstream.json`;
シルバーテーブル
ブロンズテーブルに対してクレンジングした結果をシルバーテーブルとして保持します。ここではエクスペクテーションを用いてデータの品質を担保しています。
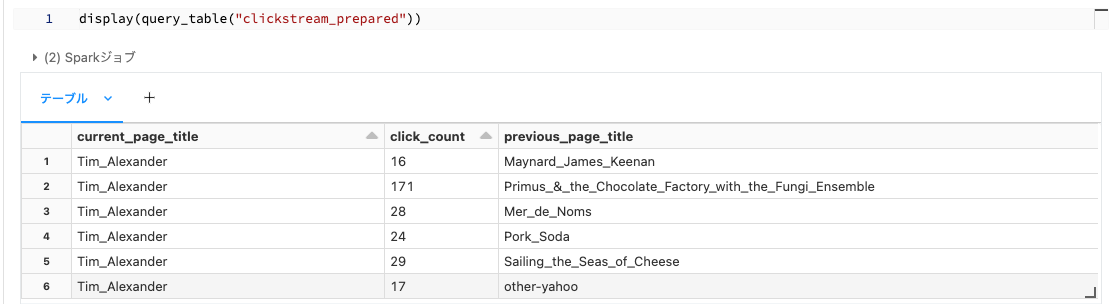
CREATE OR REFRESH LIVE TABLE clickstream_prepared(
-- current_page_titleは非NULL、click_countは1以上であるという制約
CONSTRAINT valid_current_page EXPECT (current_page_title IS NOT NULL),
CONSTRAINT valid_count EXPECT (click_count > 0) ON VIOLATION FAIL UPDATE
)
COMMENT "分析のためにクレンジング、準備されたWikipediaクリックストリームデータ(シルバー)"
AS SELECT
curr_title AS current_page_title,
CAST(n AS INT) AS click_count,
prev_title AS previous_page_title
FROM live.clickstream_raw;
ゴールドテーブル
BIや機械学習など最終的にビジネスで活用するデータを格納するのがゴールドテーブルです。
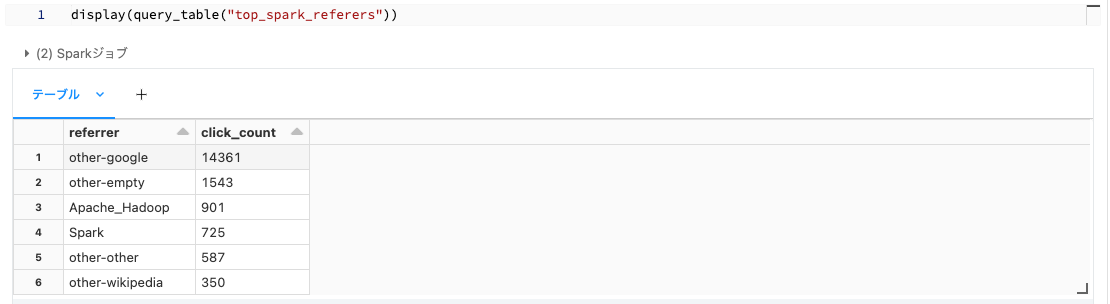
CREATE OR REFRESH LIVE TABLE top_spark_referers
COMMENT "Apacke Sparkページにリンクしているクリック数トップページを含むテーブル(ゴールド)"
AS SELECT
previous_page_title as referrer,
click_count
FROM live.clickstream_prepared
WHERE current_page_title = 'Apache_Spark'
ORDER BY click_count DESC
LIMIT 10;
このノートブックが完成したら、いよいよDLTパイプラインの作成と実行です。
DLTパイプラインの作成
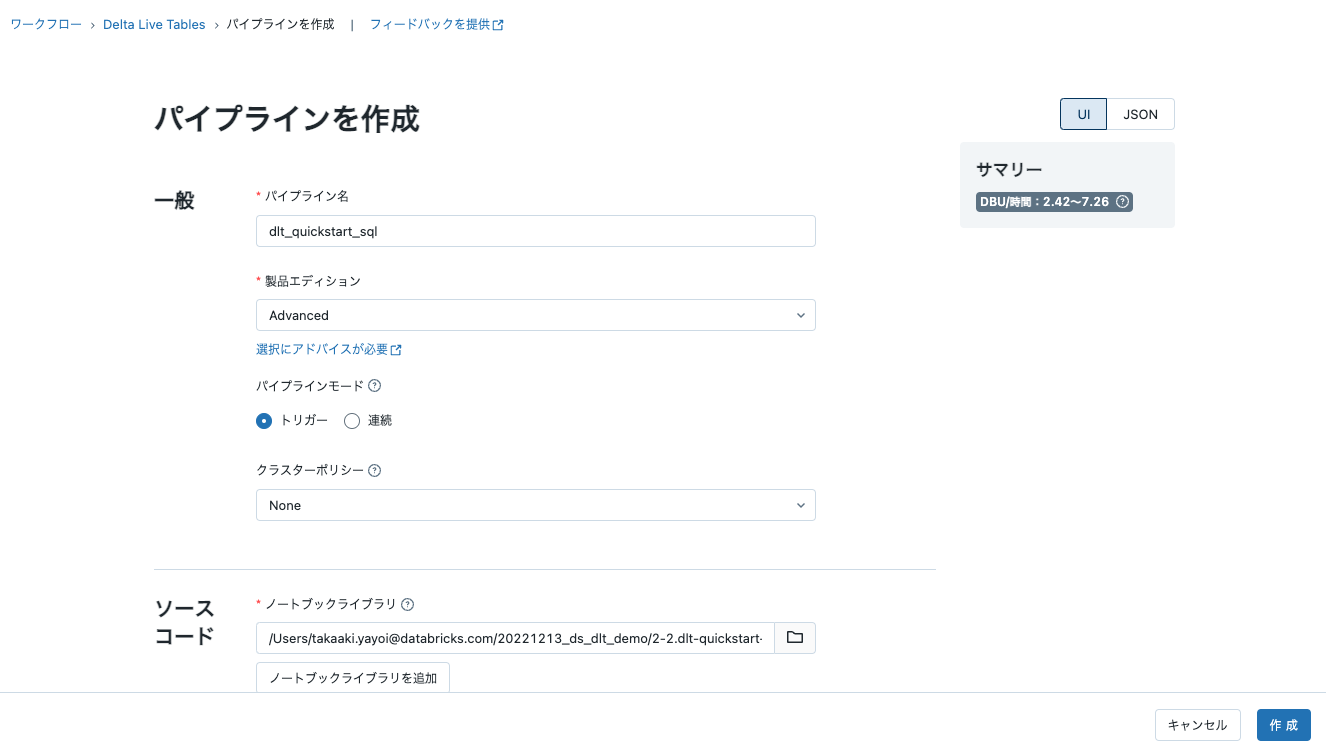
- 左のサイドメニューのワークフローボタンをクリックするところからスタートします。ページの上部にDelta Live Tablesタブが表示されます。
- パイプラインを作成をクリックします。
-
パイプライン名とノートブックライブラリは必須の値です。ノートブックセレクターを用いて、上で作成したdlt-quickstart-sqlのノートブックを選択してください。
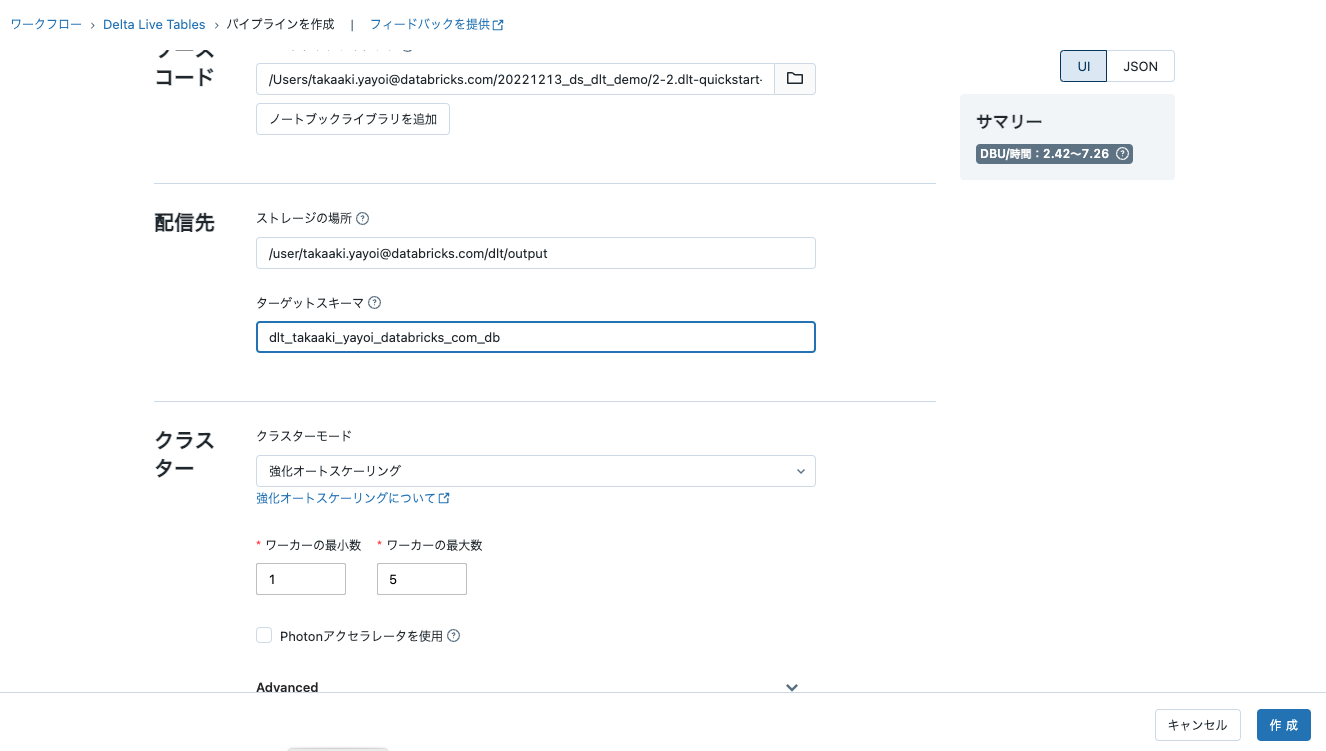
- 上で取得した
storage_locationをパイプラインのストレージの場所に貼り付けてください。- ストレージの場所は、パイプラインによって生成されるデータ、メタデータ、ログが記録される場所となります。実運用においては、セキュアな外部オブジェクトストレージを指定するようにしてください。
- 上のセルで表示された
databaseをターゲットスキーマに貼り付けてください。-
ターゲットスキーマは、パイプラインによって生成されたデータを格納するデータベースを保持します。データベースに格納することで、データに対して容易にクエリーを行えるようになります。
-
ターゲットスキーマは、パイプラインによって生成されたデータを格納するデータベースを保持します。データベースに格納することで、データに対して容易にクエリーを行えるようになります。
- 作成をクリックします。これでDLTパイプラインが作成されました。
DLTパイプラインの実行
-
DLTパイプラインが表示されます。
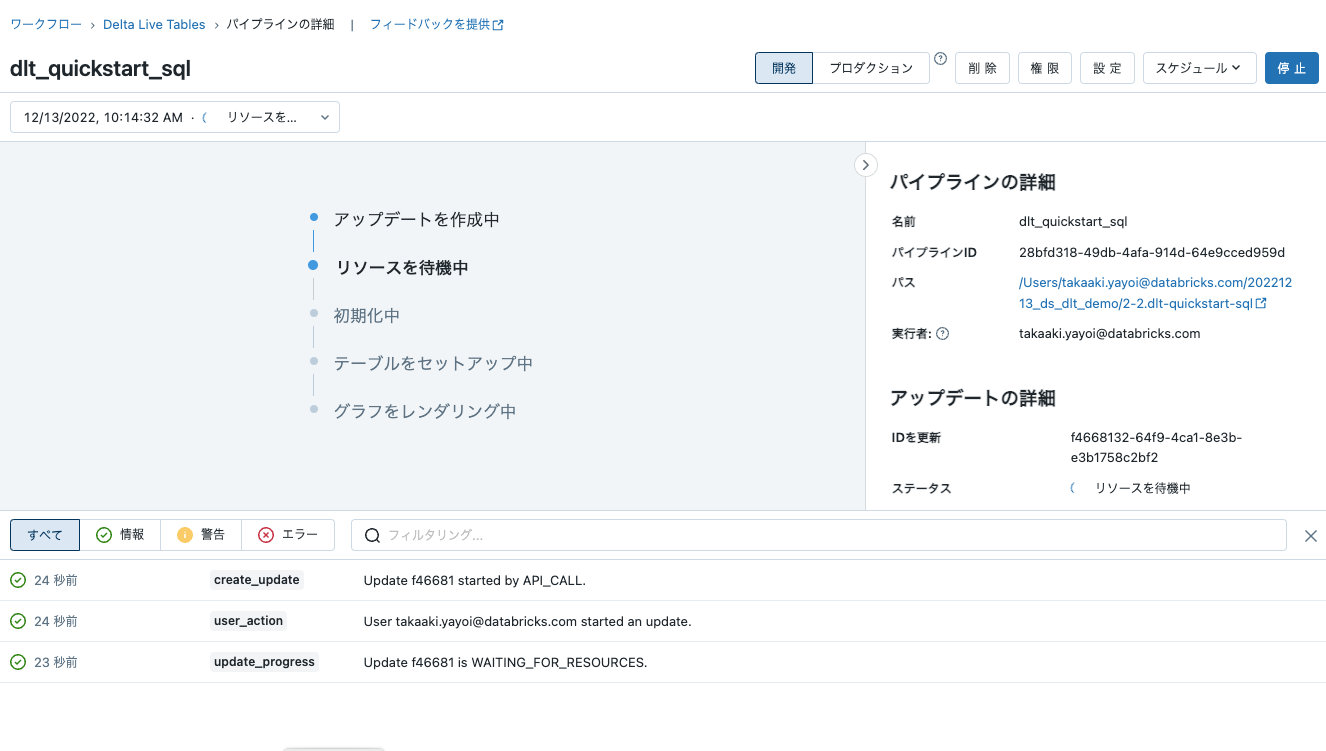
-
可能であればパイプラインを開発モードで実行します。これによって、実行の合間で同じクラスターを再利用でき、ジョブ失敗時の自動リトライを無効化しますので、デバッグが容易となります。
-
開始をクリックしてテーブルに対する最初の更新をスタートします。Delta Live Tablesは、必要な全てのインフラストラクチャーを自動でデプロイし、全てのデータセット間の依存関係を解決します。
注意
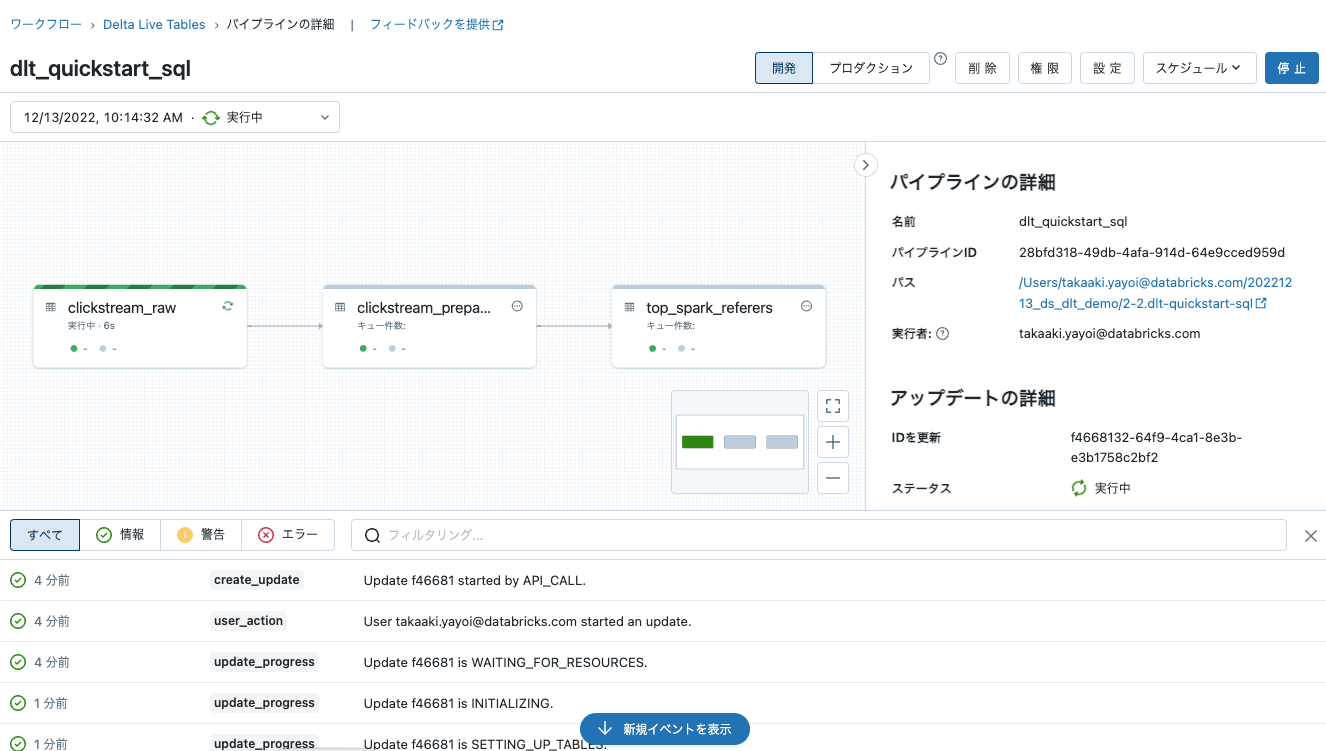
依存関係の解決とインフラストラクチャのデプロイのため、最初のテーブルアップデートは数分かかる場合があります。 -
数分経つとクラスターが配備され、パイプラインのDAG(有効非巡回グラフ)が表示され、パイプラインが実行されます。
-
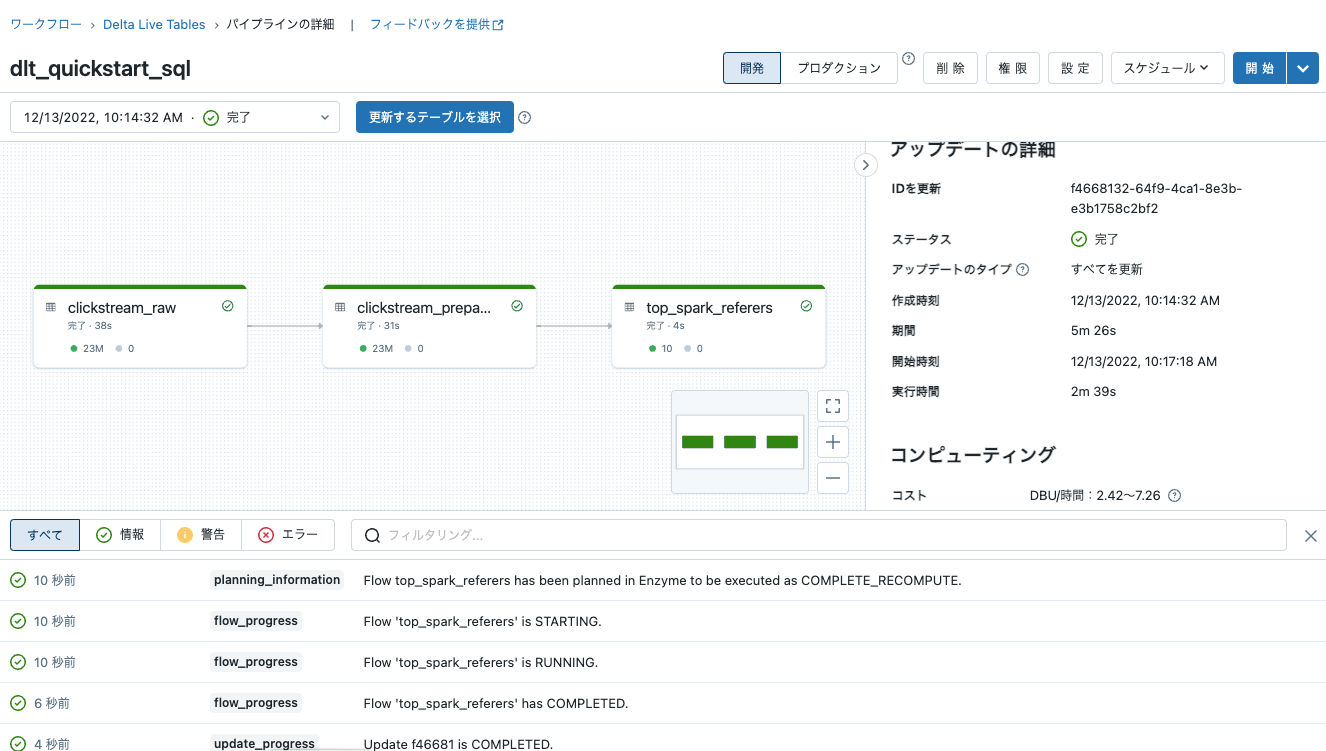
すべてのテーブルに完了と表示されたらパイプラインが完了したことを意味します。エラーが生じた際には、該当テーブルが赤くなります。
-
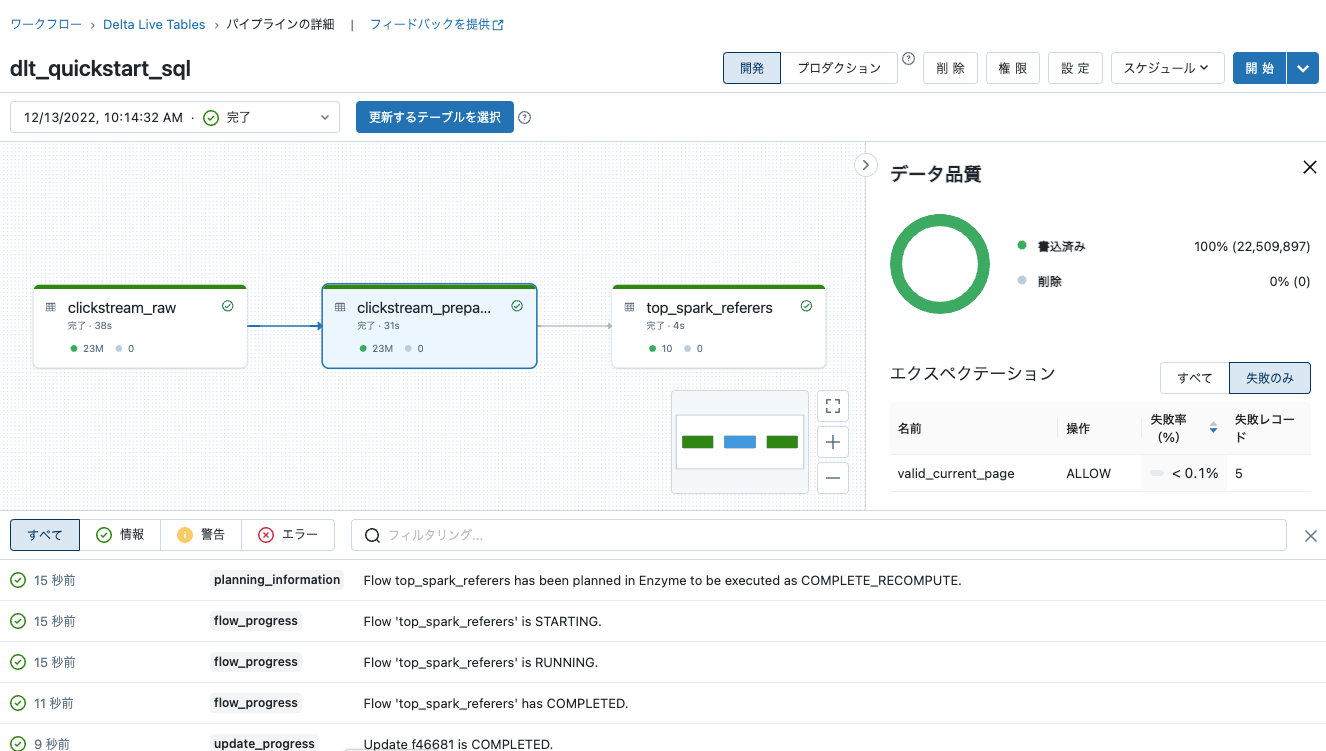
エクスペクテーションが設定されているテーブルをクリックすると、エクスペクテーションを手寄与した結果を確認することができます。
テーブルの確認
DLTの処理結果はすべてDeltaテーブルとして保持されます。DLT-mainノートブックに以下のような関数を作成することで、クイックにDeltaテーブルにアクセスすることができます。
def query_table(table_name):
return spark.sql(f"SELECT * FROM delta.`{storage_location}/tables/{table_name}`")
ブロンズテーブル
シルバーテーブル
ゴールドテーブル
まとめ
Delta Live Tables(DLT)は、背後でSparkの構造化ストリーミングとDelta Lakeを活用しています。DLTを用いることで、ユーザーはSparkやDeltaの詳細を意識することなしに、容易にデータパイプラインを開発、運用できるようになります。本書では触れませんでしたが、DLTの処理結果はすべてイベントログとして、これらもDeltaテーブルとして保持されますので、これらを解析、監視することも可能です。データエンジニアリングに課題を感じられているのであれば、是非DLTを御試しください。この他にも以下のような機能をサポートしています。
- Databricks Delta Live Tablesでチェンジデータキャプチャをシンプルに - Qiita
- Delta Live Tablesクックブック - Qiita
- Delta Live Tablesにおけるストリームデータ処理 - Qiita
- Delta Live TablesとApache Kafkaを用いた低レーテンシーストリーミングデータパイプライン - Qiita
- Delta Live Tablesのイベントログ - Qiita