Change Data Capture With Delta Live Tables - The Databricks Blogの翻訳です。
本書は抄訳であり内容の正確性を保証するものではありません。正確な内容に関しては原文を参照ください。
このガイドでは、データレイクにおける新規レコードを特定し、データへの変更を補足するために、どのようにDelta Live Tablesパイプラインのチェンジデータキャプチャを活用できるのかを説明します。Delta Live Tablesを用いることで、スケーラブル、高信頼、低レーテンシーのデータパイプラインを構築できることに加え、最低限の計算リソースとシームレスな遅延データハンドリングを用いたデータレイクに対するチェンジデータキャプチャを実行することができます。
注意
Delta Live Tables (DLT)と宣言型ETL定義にを用いたスケーラブルかつ高信頼なパイプラインの作成方法を説明しているDelta Live Tablesを使ってみるを試すことをお勧めします。
チェンジデータキャプチャの背景
チェンジデータキャプチャ(CDC)は、ニアリアルタイムのデータアプリケーションにおける顧客の追跡、注文・商品のステータスの追跡の様に、データベースにおけるインクリメンタルな変更(データの削除、追加、更新)を特定、補足するプロセスです。CDCでは、新規イベントが生じるのに合わせて継続的かつインクリメンタルな方法でデータを処理することで、リアルタイムのデータ進化を実現しています。2025年までには企業の80%がマルチクラウドの戦略を実施しようとしていることから、複数の環境におけるETLパイプラインにおけるすべてのデータの変更をリアルタイムかつシームレスに集中管理することが重要となります。
CDCイベントを補足することで、Databricksユーザーは外部システムとデータを結合できつつも、レイクハウスのDeltaテーブルとしてソーステーブルを再マテリアライズでき、分析を実行できる様になります。DatabricksにおけるDelta LakeのMERGE INTOコマンドによって、お客様は自分のデータレイクで効率的にレコードのupsert、deleteを行うことができます。以前ディープダイブしたこちらのトピックをチェックすることもできます。これは、リアルタイムのビジネスデータでデータレイクを最新の状態に保っている数多くのDatabricksのお客様においては一般的なユースケースとなっています。
Delta LakeはデータレイクにおけるリアルタイムCDC同期に対する完全なソリューションを提供しますが、みなさまのアーキテクチャをさらにシンプルに、さらに効率的、スケーラブルにするDelta Live Tablesにおけるチェンジデータキャプチャを発表できることを嬉しく思っています。DLTによって、ユーザーはSQLやPythonを用いてシームレスにCDCデータを取り込める様になります。
Deltaテーブルによる初期のCDCソリューションでは、ソースデータセットの複数行がターゲットDeltaテーブルに存在する同じ行にマッチし、アップデートしようとした際に処理が失敗することを避けるために、手動でのデータの並び替えを必要とするMERGE INTOオペレーションを使用していました。並び順を守らないデータに対応するためには、複数マッチの可能性を排除し、それぞれのキーの最新の変更のみを保持するためにforeachBatch実装を用いてソーステーブルを前処理する追加のステップが必要でした。DLTにおける新たなAPPLY CHANGES INTOオペレーションは、手動でのデータエンジニアリングの作業を必要とせず、自動かつシームレスに順序を守らないデータをハンドリングします。
Databricks Delta Live TablesによるCDC
この記事では、CDCデータが外部システムから到着する一般的なCDCユースケースにおけるDelta Live TablesパイプラインにおけるAPPLY CHANGES INTOコマンドの使い方をデモします。Debezium、Fivetran、Qlik Replicate、Talend、StreamSetsのように数多くのCDCツールが存在しています。固有の実装は異なりますが、これらのツールは一般的には、データ変更の履歴を補足してログに記録します。後段のアプリケーションがこのログを活用します。我々のサンプルでは、Debezium、FivetranのようなCDCツールからクラウドオブジェクトストレージにデータが到着します。
クラウドオブジェクトストレージにデータを提供するさまざまなCDCツールや、Apache Kafkaのようなメッセージキューからデータが到着します。多くの場合、取り込みに用いられるCDCは我々がメダリオンアーキテクチャというものに流入します。メダリオンアーキテクチャでは、アーキテクチャの各レイヤーを通じて、データの構造と品質を改善していくために用いられるデータデザインパターンです。Delta Live Tablesを用いることで、シームレスにCDCフィードからレイクハウスのテーブルに変更を適用することができます。この機能とメダリオンアーキテクチャを組み話せることで、大規模な分析ワークロードを通じて容易に変更をインクリメンタルに適用できる様になります。CDCとメダリオンアーキテクチャを組み合わせて活用することで、変更データ、追加データのみを処理すればよいので、ユーザーに対して複数のメリットを提供します。つまり、ユーザーは最新のビジネスデータを用いて、ゴールドテーブルをコスト効率高く最新の状態に保つことができます。
注意
ここでのサンプルはCDCのSQLパージョン、Pythonバージョンの両方に適用でき、バリエーションの評価、オペレーション固有の方法にも適用することができます。こちらの公式ドキュメントをご覧ください。
前提条件
このガイドの大部分を実行するには、以下の点に慣れ親しんでいる必要があります。
- SQLあるいはPython
- Delta Live Tables
- ビッグデータシステムの操作、ETLパイプラインの開発
- Databricksのインタラクティブノートブック、クラスター
- Databrikcsワークスペースにおける、新規クラスター作成、ジョブ実行、外部クラウドオブジェクトストレージあるいはDBFSにデータを保存する権限。
- 本記事で作成するパイプラインにおいては、データ品質制約の強制をサポートしている
Advanced製品エディションを選択する必要があります。
データセット
ここでは、外部データベースからの現実的なデータに模したCDCデータを消費していきます。このパイプラインでは、DebeziumのようなCDCツールが生成するデータセットを生成するためにFakerライブラリを使用し、Databricksにおける初期取り込みのためにクラウドストレージに持ってきます。Auto Loaderを用いて、クラウドオブジェクトストレージからのメッセージをインクリメンタルにロードし、生のメッセージを格納するために、これらをブロンズテーブルに格納します。ブロンズテーブルは、信頼できる唯一の情報源へのクイックなアクセスを実現するためのデータ取り込みを意図したものです。次に、後段のシルバーテーブルに変更を伝播させるためにクレンジングされたブロンズレイヤーテーブルからAPPLY CHANGES INTOを実行します。シルバーテーブルにデータが流れ込むと一般的には、企業にキーとなるビジネスエンティティのビューを提供する、より洗練され最適化された状態になります。以下の図をご覧ください。
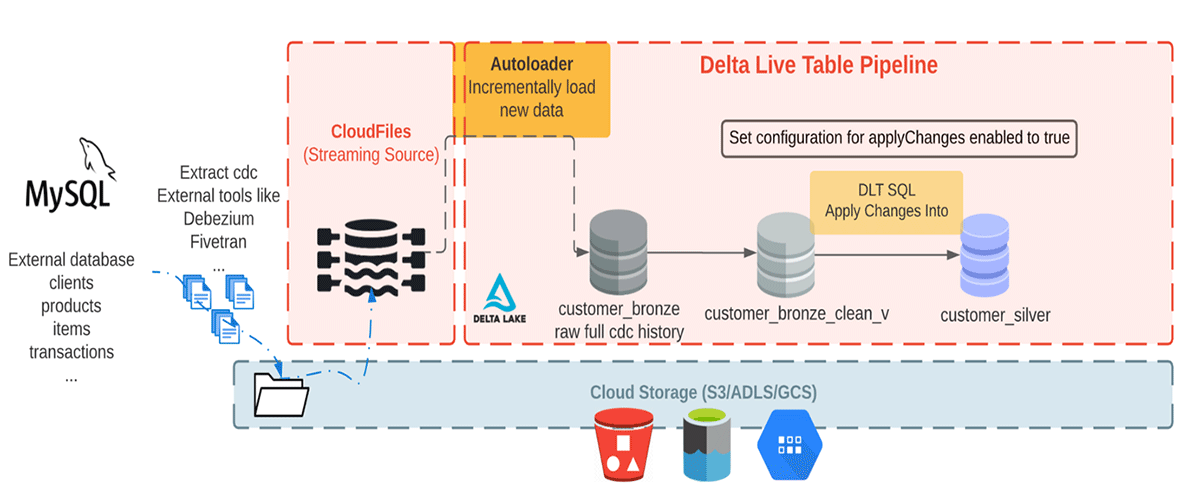
本記事では、顧客名、メールアドレス、住所、IDと、変更データを説明するための2つのフィールド: オペレーションのコード(DELETE, APPEND, UPDATE, CREATE)を格納するoperation、それぞれのオペレーションのアクションに対応するレコードが到着した日付とタイムスタンプを格納するoperation_dateを持つJSONを必要とするシンプルな例にフォーカスします。
上述のフィールドを持つサンプルデータセットを生成するために、フェイクデータを生成するPythonパッケージであるFakerを使用します。こちらからこのデータ生成セクションに関連するノートブックを参照することができます。Databricksの機能であるDBFSを使用します。詳細に関してはDBFSのドキュメントを参照ください。そして、それぞれのフィールドごとに合成データセットを生成し、他のノートブックから合成データセットを参照できる様に、定義されたストレージロケーションに保存するために、PySparkのユーザー定義関数を使います。
Auto Loaderによる生のデータセットの取り込み
メダリオンアーキテクチャパラダイムによると、ブロンズレイヤーでは最も生のデータ品質を保持します。このステージでは、Auto Loaderを用いてクラウドストレージのロケーションからインクリメンタルに新規データを読み込みます。ここでは、パイプライン設定のconfigurationセクションに生成されたデータセットへのパスを追加し、変数としてソースパスを読み込める様にします。パイプライン設定のconfigurationは以下の様になります。
"configuration": {
"source": "/tmp/demo/cdc_raw"
}
次に、ノートブックからこの設定をロードします。
取り込みを行うブロンズテーブルのSQLバージョンとPythonバージョンを見ていきましょう。
SET spark.source;
CREATE STREAMING LIVE TABLE customer_bronze
(
address string,
email string,
id string,
firstname string,
lastname string,
operation string,
operation_date string,
_rescued_data string
)
TBLPROPERTIES ("quality" = "bronze")
COMMENT "New customer data incrementally ingested from cloud object storage landing zone"
AS
SELECT *
FROM cloud_files("${source}/customers", "json", map("cloudFiles.inferColumnTypes", "true"));
import dlt
from pyspark.sql.functions import *
from pyspark.sql.types import *
source = spark.conf.get("source")
@dlt.table(name="customer_bronze",
comment = "New customer data incrementally ingested from cloud object storage landing zone",
table_properties={
"quality": "bronze"
}
)
def customer_bronze():
return (
spark.readStream.format("cloudFiles") \
.option("cloudFiles.format", "json") \
.option("cloudFiles.inferColumnTypes", "true") \
.load(f"{source}/customers")
)
上の文では、JSONファイルからcustomer_bronzeというストリーミングLIVEテーブルを作成するためにAuto Loaderを使用しています。Delta Live TablesでAuto Loaderを使う際、DLTによってロケーションは自動で管理されるので、スキーマやチェックポイントのロケーションを指定する必要はありません。
Auto Loaderでは、SQLならcloud_files、PythonならcloudFilesというパラメーターとしてストレージパスとフォーマットを受け取る構造化ストリーミングソースを提供しています。計算コストを削減するために、低レーテンシーの要件がない場合にはマイクロバッチとしてTriggeredモードでDLTパイプラインを実行することをお勧めします。
エクスペクテーションと高品質データ
次のステップでは、高品質、多様かつアクセス可能なデータセットを作成するために、Constraints(制約)を用いたエクスペクテーションの評価基準による品質チェックを行います。現時点では、制約は保持、削除、処理の失敗を行うことができます。詳細はこちらを参照ください。合理的な品質モニタリングを行うために、全ての制約は記録されます。
CREATE TEMPORARY STREAMING LIVE TABLE customer_bronze_clean_v(
CONSTRAINT valid_id EXPECT (id IS NOT NULL) ON VIOLATION DROP ROW,
CONSTRAINT valid_address EXPECT (address IS NOT NULL),
CONSTRAINT valid_operation EXPECT (operation IS NOT NULL) ON VIOLATION DROP ROW
)
TBLPROPERTIES ("quality" = "silver")
COMMENT "Cleansed bronze customer view (i.e. what will become Silver)"
AS SELECT *
FROM STREAM(LIVE.customer_bronze);
@dlt.view(name="customer_bronze_clean_v",
comment="Cleansed bronze customer view (i.e. what will become Silver)")
@dlt.expect_or_drop("valid_id", "id IS NOT NULL")
@dlt.expect("valid_address", "address IS NOT NULL")
@dlt.expect_or_drop("valid_operation", "operation IS NOT NULL")
def customer_bronze_clean_v():
return dlt.read_stream("customer_bronze") \
.select("address", "email", "id", "firstname", "lastname", "operation", "operation_date", "_rescued_data")
後段のターゲットテーブルに変更を伝播させるためにAPPLY CHANGES INTO文を使用
APPLY CHANGES INTOクエリーを実行する前に、最新のデータを保持したいと考えているターゲットストリーミングテーブルが存在していることを確認する必要があります。存在しない場合には作成する必要があります。以下のセルは、ターゲットストリーミングテーブルのサンプルです。本記事の公開時点では、APPLY CHANGES INTOクエリーではターゲットストリーミングテーブルの作成が必要であり、両方ともパイプラインに存在する必要があることに注意してください。そうでない場合にはテーブル作成のクエリーは失敗します。
CREATE STREAMING LIVE TABLE customer_silver
TBLPROPERTIES ("quality" = "silver")
COMMENT "Clean, merged customers";
dlt.create_target_table(name="customer_silver",
comment="Clean, merged customers",
table_properties={
"quality": "silver"
}
)
これでターゲットのストリーミングテーブルが作成されたので、APPLY CHANGES INTOクエリーを用いて後段のターゲットテーブルに変更を伝播させることができます。CDCフィードはINSERT、UPDATE、DELETEイベント共に到着しますが、DLTのデフォルトの挙動では主キーでマッチし、イベント順を特定するフィールドで並び替えられたソースデータセットのすべてのレコードのINSERT、UPDATEイベントを適用します。より具体的には、ターゲットテーブルで主キーがマッチするすべての行を更新し、存在しないレコードは新規の行を挿入します。DELETEイベントを取り扱うには、SQLではAPPLY AS DELETE WHEN、Pythonではapply_as_deletesを使用します。
この例では、顧客を一意に識別するidを主キーとして用い、ターゲットストリーミングテーブルで識別された顧客にCDCイベントを適用します。operation_dateはソースデータセットでCDCイベントの論理的順序を保持しているので、順序を守らず到着したイベントを取り扱うために、SQLではSEQUENCE BY operation_date、Pythonではsequence_by = col("operation_date")を使用します。SEQUENCE BY (あるいはsequence_by)で使用するフィールドの値は同じキーに対するすべてのアップデートでユニークになっている必要があることに注意してください。多くの場合、タイムスタンプの情報をもつカラムによって並び替えられます。最後に、ターゲットストリーミングテーブルでoperation、operation_date、_rescued_dataの3つのカラムを除外するために、SQLではCOLUMNS * EXCEPT (operation, operation_date, _rescued_data)、Pythonでは"except_column_list"= ["operation", "operation_date", "_rescued_data"]を使用しています。COLUMNS句を指定しない場合、デフォルトではすべてのカラムがターゲットストリーミングテーブルに含まれます。
APPLY CHANGES INTO LIVE.customer_silver
FROM stream(LIVE.customer_bronze_clean_v)
KEYS (id)
APPLY AS DELETE WHEN operation = "DELETE"
SEQUENCE BY operation_date
COLUMNS * EXCEPT (operation, operation_date,
_rescued_data);
dlt.apply_changes(
target = "customer_silver",
source = "customer_bronze_clean_v",
keys = ["id"],
sequence_by = col("operation_date"),
apply_as_deletes = expr("operation = 'DELETE'"),
except_column_list = ["operation", "operation_date", "_rescued_data"])
利用できる句の完全なリストに関しては、こちらをチェックしてください。本記事の発行時点では、APPLY CHANGES INTOクエリーやapply_changes関数のターゲットテーブルから読み込むテーブルはLIVEテーブルである必要があり、ストリーミングLIVEテーブルではあってはいけません。
このセクションのリファレンスとしてSQLノートブックとpythonノートブックを利用することができます。すべてのセルの準備ができたので、クラウドオブジェクトストレージからデータを取り込むパイプラインを作成しましょう。ワークスペースで新規タブや新規ウィンドウでジョブを開き、Delta Live Tablesを選択します。
この記事のパイプラインでは、以下のDLTパイプライン設定を行なっています。
{
"clusters": [
{
"label": "default",
"num_workers": 1
}
],
"development": true,
"continuous": false,
"edition": "advanced",
"photon": false,
"libraries": [
{
"notebook": {
"path":"/Repos/mojgan.mazouchi@databricks.com/Delta-Live-Tables/notebooks/1-CDC_DataGenerator"
}
},
{
"notebook": {
"path":"/Repos/mojgan.mazouchi@databricks.com/Delta-Live-Tables/notebooks/2-Retail_DLT_CDC_sql"
}
}
],
"name": "CDC_blog",
"storage": "dbfs:/home/mydir/myDB/dlt_storage",
"configuration": {
"source": "/tmp/demo/cdc_raw",
"pipelines.applyChangesPreviewEnabled": "true"
},
"target": "my_database"
}
- 新規パイプラインを作成するためにCreate Pipelineを選択します。
-
Retail CDC Pipelineの様な名前をつけます。 - ここまで作成したFakerパッケージspark用いて生成したデータセットのノートブック、DLTで生成データの取り込みを行うノートブックのパスを指定します。2つ目のノートブックパスについては、お好みの言語に応じてSQLあるいはPythonのノートブックのパスを指定することができます。
- 1つ目のノートブックで生成されたデータにアクセスするために、設定にデータセットのパスを追加します。ここでは、データを
/tmp/demo/cdc_raw/customersに格納しているので、2つ目のノートブックでsource/customersを参照するために、sourceを/tmp/demo/cdc_raw/に設定します。 - パイプラインの結果生成されるテーブルをクエリーできる様に
Target(オプションと指定指定できるターゲットのデータベース)を指定します。 - DLTが生成したデータセットやパイプラインのメタデータログにアクセスできる様に、オブジェクトストレージのストレージロケーションを指定します(オプション)。
- パイプラインのモードをTriggeredに設定します。トリガーモードでは、DLTパイプラインはソースのすべての新規データを一度に処理し、処理が完了すると自動で計算リソースを停止します。パイプライン設定を編集する際にTriggeredとContinuousモードを切り替えることができます。JSONで
"continuous": falseを設定するのとパイプラインをトリガーモードに設定することは等価です。 - このワークロードでは、オートパイロットオプンションのオートスケーリングを無効にすることができ、1ワーカーのみのクラスターを使用することができます。プロダクションのワークロードにおいては、オートスケーリングを有効にし、クラスターサイズに必要な最大ワーカー数を設定することをお勧めします。
- Startを選択します。
- パイプラインが作成され実行されます!
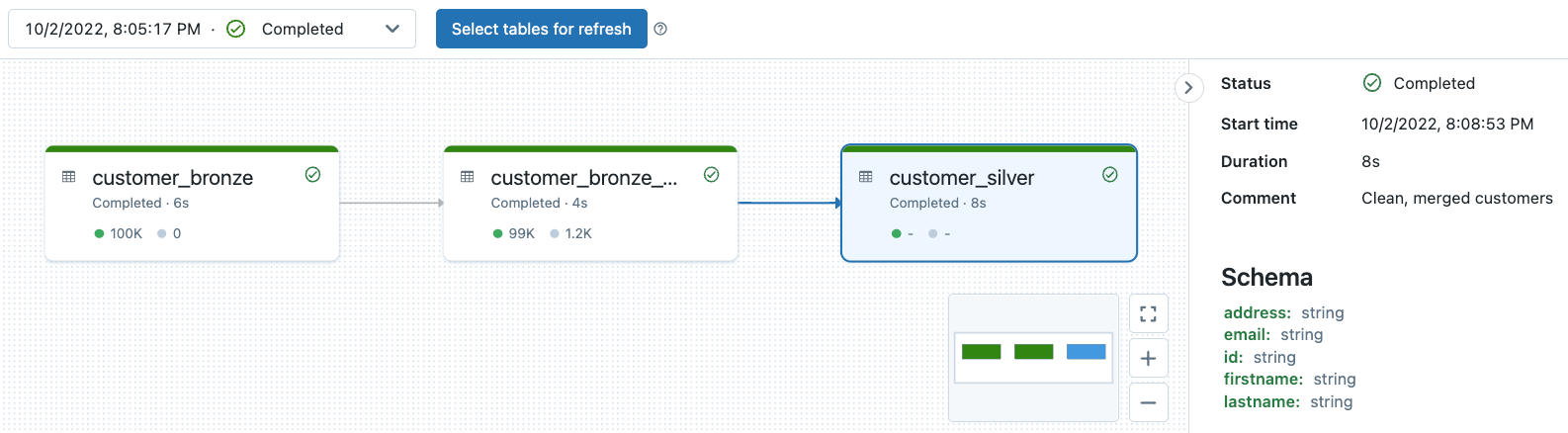
クリックすると新規タブで動画が開きます。
DLTパイプラインのリネージュ観測可能性、データ品質モニタリング
すべてのDLTパイプラインのログはパイプラインのストレージロケーションに格納されます。パイプラインを作成する際にのみストレージロケーションを指定することができます。パイプラインを作成した後はストレージロケーションを変更できないことに注意してください。
こちらから以前のディープダイブをチェックすることができます。この記事に関連するサンプルDLTパイプラインにおける、パイプラインの観測可能性やデータ品質モニタリングを確認するためにこちらのノートブックを試してみてください。
まとめ
この記事では、Delta Live Tables(DLT)を用いることで、ユーザーがどのようにレイクハウスにチェンジデータキャプチャ(CDC)を効率的かつシームレスに実装できるのかを説明しました。DLTはパイプラインオペレーションに対する深いカケハシと、パイプラインリネージュの観察可能性、スキーマのモニタリング、パイプラインの各ステップにおける品質チェックを提供します。DLTは自動エラーハンドリングと、ストリーミングワークロードに対する最高クラスのオートスケーリング機能をサポートしており、ユーザーは自身のワークロードに必要な最適リソースを用いて高品質なデータを入手することができます。
データエンジニアは、SQLやPythonで宣言型のAPPLY CHANGES INTO APIを用いて容易にCDCを実装することができます。この新機能によって、お使いのETLパイプラインは容易に変更を特定し、これらの変更を低レーテンシーで数万のテーブルに適用することが可能となります。
Delta Live TablesでCDCをトライする準備はできましたか?
Delta Live Tablesがどのようにデータの変換とETLをシンプルにするのかを学ぶにはこちらのウェビナーを視聴してください。そして、ドキュメントDelta Live Tablesによるチェンジデータキャプチャ(CDC)や公式のgithubをご覧ください。ご自身でパイプラインを作成するためにはこちらの動画のステップに従ってください!