気づいたらサンプルノートブックが追加されていました。世はまさにエージェント時代
Mosaic AIエージェントフレームワーク: ツール呼び出しOpenAI Responses APIエージェントの作成とデプロイ
このノートブックでは、Mosaic AIエージェントフレームワークの機能と互換性のあるOpenAIエージェントの作成方法を示します。このノートブックで学ぶこと:
- ツール呼び出し
ChatAgentを作成し、Open AI Responses APIを使用する - エージェントの出力を手動でテストする
- Mosaic AIエージェント評価を使用してエージェントを評価する
- エージェントをログに記録し、デプロイする
注意: このノートブックはOpenAI REST APIを直接クエリします。ガバナンス、ペイロードロギング、その他のDatabricks AIゲートウェイ機能については、Databricks外部モデル(AWS | Azure)を使用してください。OpenAIモデルをクエリするためにDatabricks外部モデルを使用する例については、OpenAIツール呼び出しエージェントノートブックを参照してください。
Mosaic AIエージェントフレームワークを使用してエージェントを作成する方法の詳細については、Databricksドキュメント(AWS | Azure)を参照してください。
前提条件
%pip install -U -qqqq mlflow backoff databricks-openai openai databricks-agents uv
dbutils.library.restartPython()
エージェントをコードで定義
以下のセルにエージェントコードを定義します。これにより、%%writefileマジックコマンドを使用してエージェントコードをローカルPythonファイルに簡単に書き込み、その後のログ記録とデプロイが可能になります。
エージェントツール
このエージェントコードには、組み込みのUnity Catalog関数system.ai.python_execが追加されています。また、非構造化データの検索を行うためのベクトル検索インデックスを追加するサンプルコードもコメントアウトされています。
エージェントに追加するツールの詳細については、Databricksドキュメント(AWS | Azure)を参照してください。
%%writefile agent.py
import json
from typing import Any, Callable, Generator, Optional, Union
from uuid import uuid4
import backoff
import mlflow
import openai
from databricks_openai import UCFunctionToolkit, VectorSearchRetrieverTool
from mlflow.entities import SpanType
from mlflow.pyfunc import ChatAgent
from mlflow.types.agent import (
ChatAgentChunk,
ChatAgentMessage,
ChatAgentResponse,
ChatContext,
)
from openai import OpenAI
from openai.types.chat import ChatCompletionToolParam
from openai.types.responses import (
ResponseFunctionToolCall,
ResponseOutputItem,
ResponseOutputMessage,
)
from pydantic import BaseModel
from unitycatalog.ai.core.base import get_uc_function_client
############################################
# LLMエンドポイントとシステムプロンプトを定義
############################################
# TODO: 使用するOpenAIモデルを指定
# DatabricksはまだResponses APIをサポートしていません
LLM_ENDPOINT_NAME = "gpt-4o"
# TODO: システムプロンプトを更新
SYSTEM_PROMPT = """
あなたは役に立つアシスタントです。
"""
###############################################################################
## エージェントのためのツールを定義し、テキスト生成以外のデータ取得やアクションを可能にする
## さらに多くのツールの作成と使用例については
## https://docs.databricks.com/en/generative-ai/agent-framework/agent-tool.html を参照
###############################################################################
class ToolInfo(BaseModel):
"""
エージェントのためのツールを表すクラス。
- "name" (str): ツールの名前。
- "spec" (dict): ツールのJSON説明(OpenAI Responses形式に一致)
- "exec_fn" (Callable): ツールのロジックを実装する関数
"""
name: str
spec: dict
exec_fn: Callable
def convert_chat_completion_tool_to_tool_info(
spec: ChatCompletionToolParam, exec_fn: Optional[Callable] = None
):
"""ChatCompletionToolParamをToolInfoオブジェクトに変換します。"""
spec |= spec.pop("function")
if exec_fn is None:
def exec_fn(**kwargs):
udf_name = spec["name"].replace("__", ".")
function_result = uc_function_client.execute_function(udf_name, kwargs)
if function_result.error is not None:
return function_result.error
else:
return function_result.value
return ToolInfo(name=spec["name"], spec=spec, exec_fn=exec_fn)
TOOL_INFOS = []
# Unity CatalogのUDFをエージェントツールとして使用できます
# 以下では、エージェントにPythonコードインタープリターツールを提供する`system.ai.python_exec` UDFを追加します
# TODO: 追加のツールを追加
UC_TOOL_NAMES = ["system.ai.python_exec"]
uc_toolkit = UCFunctionToolkit(function_names=UC_TOOL_NAMES)
uc_function_client = get_uc_function_client()
for tool_spec in uc_toolkit.tools:
TOOL_INFOS.append(convert_chat_completion_tool_to_tool_info(tool_spec))
# Databricksベクトル検索インデックスをツールとして使用
# 詳細は https://docs.databricks.com/ja/generative-ai/agent-framework/unstructured-retrieval-tools.html#locally-develop-vector-search-retriever-tools-with-ai-bridge を参照
VECTOR_SEARCH_TOOLS = []
# TODO: ベクトル検索インデックスを追加
# VECTOR_SEARCH_TOOLS.append(
# VectorSearchRetrieverTool(
# index_name="",
# # filters="..."
# )
# )
for vs_tool in VECTOR_SEARCH_TOOLS:
TOOL_INFOS.append(
convert_chat_completion_tool_to_tool_info(vs_tool.tool, vs_tool.execute)
)
class ToolCallingAgent(ChatAgent):
"""
ツール呼び出しエージェントを表すクラス
"""
def __init__(self, llm_endpoint: str, tools: list[ToolInfo]):
"""
ツールを使用してToolCallingAgentを初期化します。
"""
super().__init__()
self.llm_endpoint = llm_endpoint
self.client: OpenAI = OpenAI()
self._tools_dict = {tool.name: tool for tool in tools}
def get_tool_specs(self) -> list[dict]:
"""
OpenAIが期待する形式でツール仕様を返します。
"""
return [tool_info.spec for tool_info in self._tools_dict.values()]
@mlflow.trace(span_type=SpanType.TOOL)
def execute_tool(self, tool_name: str, args: dict) -> Any:
"""
指定されたツールを指定された引数で実行します。
"""
if tool_name not in self._tools_dict:
raise ValueError(f"Unknown tool: {tool_name}")
return self._tools_dict[tool_name].exec_fn(**args)
def prepare_messages_for_llm(
self,
messages: list[Union[ChatAgentMessage, ResponseOutputItem, dict[str, Any]]],
) -> list[Union[dict[str, Any], ResponseOutputItem]]:
"""LLMメッセージ形式と互換性のないChatAgentMessageフィールドをフィルタリング"""
compatible_keys = ["role", "content", "name", "tool_calls", "tool_call_id"]
return [
{
k: v
for k, v in m.model_dump_compat(exclude_none=True).items()
if k in compatible_keys
}
if isinstance(m, ChatAgentMessage)
else m
for m in messages
]
def convert_openai_response_output_to_chat_agent_msg(
self, output: ResponseOutputItem
) -> ChatAgentMessage:
"""OpenAI ResponseOutputItemをChatAgentMessageに変換します。"""
if isinstance(output, ResponseFunctionToolCall):
return ChatAgentMessage(
**{
"role": "assistant",
"id": output.id,
"content": "",
"tool_calls": [
{
"id": output.call_id,
"type": "function",
"function": {
"name": output.name,
"arguments": output.arguments,
},
}
],
}
)
elif isinstance(output, ResponseOutputMessage):
return ChatAgentMessage(
role=output.role, content=output.content[0].text, id=output.id
)
else:
raise NotImplementedError("他の出力タイプの解析を追加してください")
@backoff.on_exception(backoff.expo, openai.RateLimitError)
@mlflow.trace(span_type=SpanType.LLM)
def chat_completion(
self, messages: list[Union[ChatAgentMessage, ResponseOutputItem, dict]]
) -> ResponseOutputItem:
return self.client.responses.create(
model=self.llm_endpoint,
input=self.prepare_messages_for_llm(messages),
tools=self.get_tool_specs(),
).output[0]
def handle_tool_call(
self,
llm_output: ResponseFunctionToolCall,
current_msg_history: list[
Union[ChatAgentMessage, ResponseOutputItem, dict[str, Any]]
],
) -> ChatAgentMessage:
"""
ツール呼び出しを実行し、それらを実行中のメッセージ履歴に追加し、ツールChatAgentMessageを返します
"""
args = json.loads(llm_output.arguments)
result = str(self.execute_tool(tool_name=llm_output.name, args=args))
# ステップ4からのフォーマット https://platform.openai.com/docs/guides/function-calling#function-calling-steps
openai_response_tool_msg = {
"type": "function_call_output",
"call_id": llm_output.call_id,
"output": result,
}
current_msg_history.append(openai_response_tool_msg)
return ChatAgentMessage(
role="tool",
name=llm_output.name,
tool_call_id=llm_output.call_id,
content=result,
id=str(uuid4()),
)
def call_and_run_tools(
self,
messages: list[Union[ChatAgentMessage, ResponseOutputItem, dict[str, Any]]],
max_iter: int = 10,
) -> Generator[ChatAgentMessage, None, None]:
for i in range(max_iter):
llm_output = self.chat_completion(messages=messages)
messages.append(llm_output)
yield self.convert_openai_response_output_to_chat_agent_msg(llm_output)
if not isinstance(llm_output, ResponseFunctionToolCall):
return # ツール呼び出しが必要ない場合、ストリーミングを停止
yield self.handle_tool_call(llm_output, messages)
yield ChatAgentMessage(
content=f"申し訳ありませんが、{max_iter}回試行しても答えを見つけることができませんでした。",
role="assistant",
id=str(uuid4()),
)
@mlflow.trace(span_type=SpanType.AGENT)
def predict(
self,
messages: list[ChatAgentMessage],
context: Optional[ChatContext] = None,
custom_inputs: Optional[dict[str, Any]] = None,
) -> ChatAgentResponse:
"""
ユーザーのリクエストを受け取り、応答を生成する主要な関数。
"""
# 注: self.call_and_run_toolsによってストリーミングされる各チャンクが完全なメッセージを含むことを前提としています
# これは実装が簡単ですが、predict_streamから部分的な応答メッセージをストリーミングし、
# メッセージIDでそれらを集約することもできます
response_messages = [
chunk.delta
for chunk in self.predict_stream(messages, context, custom_inputs)
]
return ChatAgentResponse(messages=response_messages)
@mlflow.trace(span_type=SpanType.AGENT)
def predict_stream(
self,
messages: list[ChatAgentMessage],
context: Optional[ChatContext] = None,
custom_inputs: Optional[dict[str, Any]] = None,
) -> Generator[ChatAgentChunk, None, None]:
if len(messages) == 0:
raise ValueError("`messages`には少なくとも1つのメッセージが含まれている必要があります")
all_messages = [
ChatAgentMessage(role="system", content=SYSTEM_PROMPT)
] + messages
for message in self.call_and_run_tools(messages=all_messages):
yield ChatAgentChunk(delta=message)
# MLflowを使用してモデルを記録
mlflow.openai.autolog()
AGENT = ToolCallingAgent(llm_endpoint=LLM_ENDPOINT_NAME, tools=TOOL_INFOS)
mlflow.models.set_model(AGENT)
エージェントをテストする
エージェントと対話してその出力をテストします。ChatAgent内のメソッドを手動でトレースしたので、エージェントが行う各ステップのトレースを表示できます。OpenAI SDKを介して行われるLLM呼び出しは、自動ロギングによって自動的にトレースされます。
このプレースホルダー入力を、エージェントに適したドメイン固有の例に置き換えてください。
dbutils.library.restartPython()
import os
# TODO: OpenAI APIキーにアクセスするためのsecret_scope_nameとsecret_key_nameを設定
secret_scope_name = "demo-token-takaaki.yayoi"
secret_key_name = "openai_api_key"
os.environ["OPENAI_API_KEY"] = dbutils.secrets.get(
scope=secret_scope_name, key=secret_key_name
)
assert os.environ["OPENAI_API_KEY"] is not None, ("OPENAI_API_KEY環境変数が正しく設定されていません")
from agent import AGENT
AGENT.predict({"messages": [{"role": "user", "content": "Pythonで4*3は何ですか?"}]})
ChatAgentResponse(messages=[ChatAgentMessage(role='assistant', content='', name=None, id='fc_67e3be731ea081919a9d944d6a0595c100717f296e49982f', tool_calls=[ToolCall(id='call_FweprTrP6BShdbe9xbKAdAax', type='function', function=Function(name='system__ai__python_exec', arguments='{"code":"result = 4 * 3\\nprint(result)"}'))], tool_call_id=None, attachments=None), ChatAgentMessage(role='tool', content='12\n', name='system__ai__python_exec', id='c8091194-9563-41d5-a338-99b950f8256a', tool_calls=None, tool_call_id='call_FweprTrP6BShdbe9xbKAdAax', attachments=None), ChatAgentMessage(role='assistant', content='Pythonで計算すると、4×3は12です。', name=None, id='msg_67e3be7fbaa88191831bef7b9fa6ec6100717f296e49982f', tool_calls=None, tool_call_id=None, attachments=None)], finish_reason=None, custom_outputs=None, usage=None)

for chunk in AGENT.predict_stream(
{"messages": [{"role": "user", "content": "Pythonで4*3は何ですか?"}]}
):
print(chunk, "-----------\n")
delta=ChatAgentMessage(role='assistant', content='', name=None, id='fc_67e3bea175508191b5ae862de8ead41c090463029e69ba9b', tool_calls=[ToolCall(id='call_FAePYOVpblJRqVlxcfJ3uqwQ', type='function', function=Function(name='system__ai__python_exec', arguments='{"code":"result = 4 * 3\\nprint(result)"}'))], tool_call_id=None, attachments=None) finish_reason=None custom_outputs=None usage=None -----------
delta=ChatAgentMessage(role='tool', content='12\n', name='system__ai__python_exec', id='6ebf19bd-dc2e-40ea-b786-241a04989f9f', tool_calls=None, tool_call_id='call_FAePYOVpblJRqVlxcfJ3uqwQ', attachments=None) finish_reason=None custom_outputs=None usage=None -----------
delta=ChatAgentMessage(role='assistant', content='Pythonでの計算結果、4 * 3は12です。', name=None, id='msg_67e3bea3b9148191be77ca34b474a710090463029e69ba9b', tool_calls=None, tool_call_id=None, attachments=None) finish_reason=None custom_outputs=None usage=None -----------
エージェントをMLflowモデルとしてログに記録
agent.pyファイルからコードとしてエージェントをログに記録します。詳細はMLflow - Models from Codeを参照してください。
Databricksリソースの自動認証を有効にする
最も一般的なDatabricksリソースタイプに対して、Databricksはエージェントのログ記録時にリソース依存関係を事前に宣言することをサポートおよび推奨しています。これにより、エージェントをデプロイする際に自動認証パススルーが有効になります。自動認証パススルーを使用すると、Databricksはこれらのリソース依存関係に安全にアクセスするための短命の資格情報を自動的にプロビジョニング、ローテーション、および管理します。
自動認証を有効にするには、mlflow.pyfunc.log_model()を呼び出す際に依存するDatabricksリソースを指定します。
- TODO: Unity Catalogツールがベクトル検索インデックスをクエリする場合や外部関数)を利用する場合、依存するベクトル検索インデックスおよびUC接続オブジェクトをリソースとして含める必要があります。詳細はドキュメントを参照してください (AWS | Azure)。
# デプロイ時に自動認証パススルーを指定するためのDatabricksリソースを決定
from agent import UC_TOOL_NAMES, VECTOR_SEARCH_TOOLS
import mlflow
from mlflow.models.resources import DatabricksFunction
resources = []
for tool in VECTOR_SEARCH_TOOLS:
resources.extend(tool.resources)
for tool_name in UC_TOOL_NAMES:
resources.append(DatabricksFunction(function_name=tool_name))
with mlflow.start_run():
logged_agent_info = mlflow.pyfunc.log_model(
artifact_path="agent",
python_model="agent.py",
pip_requirements=[
"mlflow",
"backoff",
"databricks-openai",
],
resources=resources,
)
Agent Evaluationによるエージェントの評価
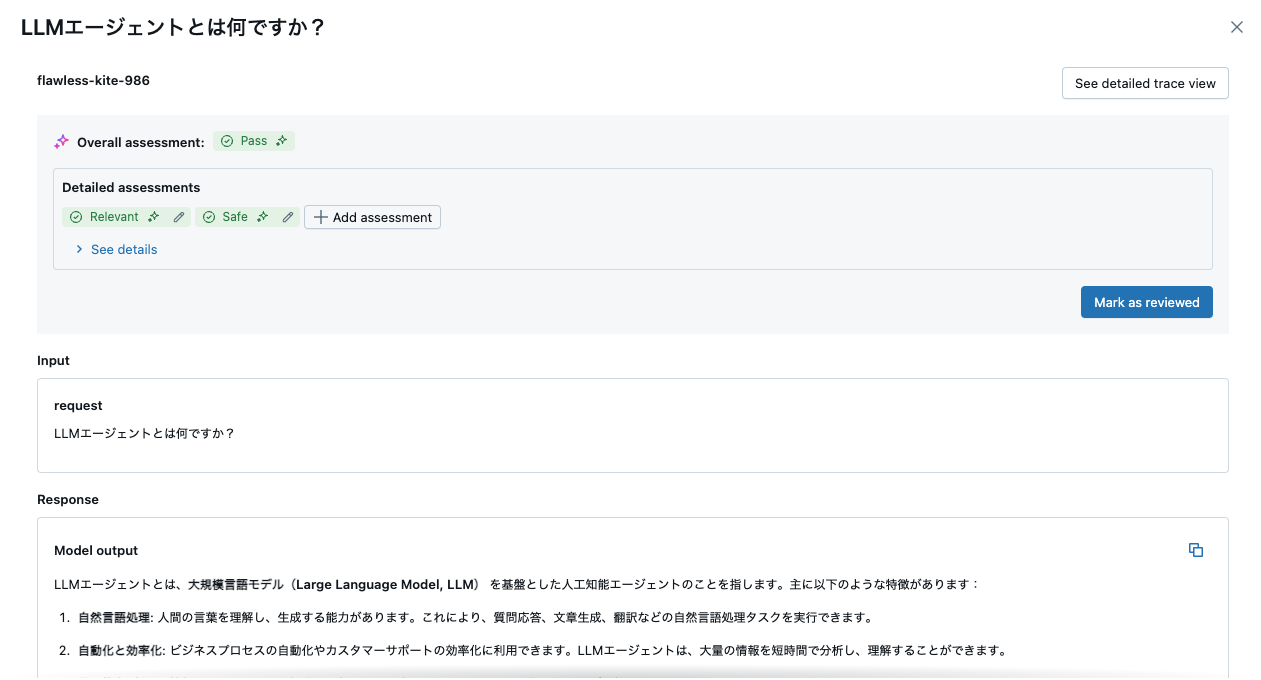
Mosaic AIエージェント評価を使用して、期待される応答やその他の評価基準に基づいてエージェントの応答を評価します。指定した評価基準を使用して反復をガイドし、MLflowを使用して計算された品質指標を追跡します。
Databricksのドキュメントを参照してください (AWS | Azure)。
ツール呼び出しを評価するには、カスタムメトリクスを追加します。Databricksのドキュメントを参照してください (AWS | Azure)。
import pandas as pd
eval_examples = [
{
"request": {"messages": [{"role": "user", "content": "LLMエージェントとは何ですか?"}]},
"expected_response": None,
}
]
eval_dataset = pd.DataFrame(eval_examples)
display(eval_dataset)
| request | expected_response |
|---|---|
| {"messages":[{"content":"LLMエージェントとは何ですか?","role":"user"}]} | null |
import mlflow
with mlflow.start_run(run_id=logged_agent_info.run_id):
eval_results = mlflow.evaluate(
f"runs:/{logged_agent_info.run_id}/agent",
data=eval_dataset, # 評価データセット
model_type="databricks-agent", # Mosaic AIエージェント評価を有効にする
)
# MLflow UIで評価結果を確認するか、以下でアクセス:
display(eval_results.tables["eval_results"])
評価結果が記録されます。

デプロイ前のエージェント検証
エージェントを登録およびデプロイする前に、mlflow.models.predict() APIを使用してデプロイ前のチェックを実行します。Databricksのドキュメントを参照してください (AWS | Azure)。
mlflow.models.predict(
model_uri=f"runs:/{logged_agent_info.run_id}/agent",
input_data={"messages": [{"role": "user", "content": "こんにちは!"}]},
env_manager="uv",
)
2025/03/26 08:49:02 INFO mlflow.models.flavor_backend_registry: Selected backend for flavor 'python_function'
2025/03/26 08:49:04 INFO mlflow.utils.virtualenv: Creating a new environment in /tmp/virtualenv_envs/mlflow-86684cf95ca21de4ff2e1888221fa2971a07b98b with python version 3.10.12 using uv
Using CPython 3.10.12 interpreter at: /usr/bin/python3.10
Creating virtual environment at: /tmp/virtualenv_envs/mlflow-86684cf95ca21de4ff2e1888221fa2971a07b98b
Activate with: source /tmp/virtualenv_envs/mlflow-86684cf95ca21de4ff2e1888221fa2971a07b98b/bin/activate
2025/03/26 08:49:06 INFO mlflow.utils.virtualenv: Installing dependencies
Using Python 3.10.12 environment at: /tmp/virtualenv_envs/mlflow-86684cf95ca21de4ff2e1888221fa2971a07b98b
Resolved 3 packages in 76ms
Downloading setuptools (1.2MiB)
Downloading pip (2.0MiB)
Downloaded setuptools
Downloaded pip
Prepared 3 packages in 131ms
Installed 3 packages in 23ms
+ pip==22.3.1
+ setuptools==78.1.0
+ wheel==0.38.4
Using Python 3.10.12 environment at: /tmp/virtualenv_envs/mlflow-86684cf95ca21de4ff2e1888221fa2971a07b98b
Resolved 109 packages in 948ms
Downloading sqlalchemy (2.9MiB)
Downloading scikit-learn (12.9MiB)
Downloading mlflow (26.9MiB)
Downloading grpcio (5.7MiB)
Downloading pillow (4.3MiB)
Downloading aiohttp (1.5MiB)
Downloading pandas (12.5MiB)
Downloading numpy (17.4MiB)
Downloading pyarrow (40.1MiB)
Downloading scipy (35.9MiB)
Downloading databricks-connect (2.3MiB)
Downloading fonttools (4.4MiB)
Downloading pydantic-core (1.9MiB)
Downloading kiwisolver (1.6MiB)
Downloading tiktoken (1.1MiB)
Downloading matplotlib (8.2MiB)
Downloading mlflow-skinny (5.9MiB)
Downloaded tiktoken
Downloaded kiwisolver
Downloaded aiohttp
Downloaded pydantic-core
Downloaded sqlalchemy
Downloaded databricks-connect
Downloaded fonttools
Downloaded pillow
Downloaded grpcio
Downloaded mlflow-skinny
Downloaded matplotlib
Downloaded pandas
Downloaded numpy
Downloaded scikit-learn
Downloaded mlflow
Downloaded pyarrow
Downloaded scipy
Prepared 108 packages in 4.85s
Installed 108 packages in 312ms
+ aiohappyeyeballs==2.6.1
+ aiohttp==3.11.14
+ aiohttp-retry==2.9.1
+ aiosignal==1.3.2
+ alembic==1.15.1
+ annotated-types==0.7.0
+ anyio==4.9.0
+ async-timeout==5.0.1
+ attrs==25.3.0
+ backoff==2.2.1
+ blinker==1.9.0
+ cachetools==5.5.2
+ certifi==2025.1.31
+ charset-normalizer==3.4.1
+ click==8.1.8
+ cloudpickle==3.1.1
+ contourpy==1.3.1
+ cycler==0.12.1
+ databricks-ai-bridge==0.4.0
+ databricks-connect==16.1.2
+ databricks-openai==0.3.0
+ databricks-sdk==0.47.0
+ databricks-vectorsearch==0.53
+ deprecated==1.2.18
+ deprecation==2.1.0
+ distro==1.9.0
+ docker==7.1.0
+ exceptiongroup==1.2.2
+ fastapi==0.115.12
+ flask==3.1.0
+ fonttools==4.56.0
+ frozenlist==1.5.0
+ gitdb==4.0.12
+ gitpython==3.1.44
+ google-auth==2.38.0
+ googleapis-common-protos==1.69.2
+ graphene==3.4.3
+ graphql-core==3.2.6
+ graphql-relay==3.2.0
+ greenlet==3.1.1
+ grpcio==1.71.0
+ grpcio-status==1.71.0
+ gunicorn==23.0.0
+ h11==0.14.0
+ httpcore==1.0.7
+ httpx==0.28.1
+ idna==3.10
+ importlib-metadata==8.6.1
+ itsdangerous==2.2.0
+ jinja2==3.1.6
+ jiter==0.9.0
+ joblib==1.4.2
+ kiwisolver==1.4.8
+ mako==1.3.9
+ markdown==3.7
+ markupsafe==3.0.2
+ matplotlib==3.10.1
+ mlflow==2.21.1
+ mlflow-skinny==2.21.1
+ multidict==6.2.0
+ nest-asyncio==1.6.0
+ numpy==1.26.4
+ openai==1.68.2
+ opentelemetry-api==1.31.1
+ opentelemetry-sdk==1.31.1
+ opentelemetry-semantic-conventions==0.52b1
+ packaging==24.2
+ pandas==2.2.3
+ pillow==11.1.0
+ propcache==0.3.1
+ protobuf==5.29.4
+ py4j==0.10.9.7
+ pyarrow==19.0.1
+ pyasn1==0.6.1
+ pyasn1-modules==0.4.1
+ pydantic==2.11.0b2
+ pydantic-core==2.32.0
+ pyparsing==3.2.3
+ python-dateutil==2.9.0.post0
+ pytz==2025.2
+ pyyaml==6.0.2
+ regex==2024.11.6
+ requests==2.32.3
+ rsa==4.9
+ scikit-learn==1.6.1
+ scipy==1.15.2
+ six==1.17.0
+ smmap==5.0.2
+ sniffio==1.3.1
+ sqlalchemy==2.0.39
+ sqlparse==0.5.3
+ starlette==0.46.1
+ tabulate==0.9.0
+ threadpoolctl==3.6.0
+ tiktoken==0.9.0
+ tqdm==4.67.1
+ typing-extensions==4.13.0
+ typing-inspection==0.4.0
+ tzdata==2025.2
+ unitycatalog-ai==0.3.0
+ unitycatalog-client==0.2.1
+ unitycatalog-openai==0.2.0
+ urllib3==2.3.0
+ uvicorn==0.34.0
+ werkzeug==3.1.3
+ wrapt==1.17.2
+ yarl==1.18.3
+ zipp==3.21.0
2025/03/26 08:49:12 INFO mlflow.utils.environment: === Running command '['bash', '-c', 'source /tmp/virtualenv_envs/mlflow-86684cf95ca21de4ff2e1888221fa2971a07b98b/bin/activate && python -c ""']'
2025/03/26 08:49:12 INFO mlflow.utils.environment: === Running command '['bash', '-c', 'source /tmp/virtualenv_envs/mlflow-86684cf95ca21de4ff2e1888221fa2971a07b98b/bin/activate && python /local_disk0/.ephemeral_nfs/envs/pythonEnv-0a523b25-13fa-49fa-a76a-f7587b350ee3/lib/python3.10/site-packages/mlflow/pyfunc/_mlflow_pyfunc_backend_predict.py --model-uri file:///local_disk0/user_tmp_data/spark-0a523b25-13fa-49fa-a76a-f7/tmp9w3ldfw1/agent --content-type json --input-path /local_disk0/user_tmp_data/spark-0a523b25-13fa-49fa-a76a-f7/tmprgq9vt1a/input.json']'
UC function client is not set.
{"messages": [{"role": "assistant", "content": "\u3053\u3093\u306b\u3061\u306f\uff01\u4eca\u65e5\u306f\u3069\u306e\u3088\u3046\u306b\u304a\u624b\u4f1d\u3044\u3057\u307e\u3057\u3087\u3046\u304b\uff1f", "id": "msg_67e3bf9352d48191b2f6210cbf35121a09f22234892144da"}]}
モデルをUnity Catalogに登録
エージェントをデプロイする前に、エージェントをUnity Catalogに登録する必要があります。
-
TODO 以下の
catalog、schema、およびmodel_nameを更新して、MLflowモデルをUnity Catalogに登録します。
mlflow.set_registry_uri("databricks-uc")
# TODO: UCモデルのカタログ、スキーマ、およびモデル名を定義する
catalog = "users"
schema = "takaaki_yayoi"
model_name = "openai_responses_agent"
UC_MODEL_NAME = f"{catalog}.{schema}.{model_name}"
# モデルをUCに登録する
uc_registered_model_info = mlflow.register_model(model_uri=logged_agent_info.model_uri, name=UC_MODEL_NAME)
Successfully registered model 'users.takaaki_yayoi.openai_responses_agent'.
Created version '1' of model 'users.takaaki_yayoi.openai_responses_agent'.

エージェントのデプロイ
from databricks import agents
agents.deploy(
UC_MODEL_NAME,
uc_registered_model_info.version,
tags={"endpointSource": "docs"},
environment_vars={
"OPENAI_API_KEY": f"{{{{secrets/{secret_scope_name}/{secret_key_name}}}}}"
},
)
サービングエンドポイントにエージェントがデプロイされました。

次のステップ
エージェントがデプロイされた後、AIプレイグラウンドでエージェントとチャットして追加のチェックを行ったり、組織内のSMEと共有してフィードバックを得たり、プロダクションアプリケーションに埋め込んだりすることができます。詳細については、ドキュメントを参照してください(AWS | Azure)。