How to Augment Your SIEM for Cybersecurity at Cloud Scale - The Databricks Blogの翻訳です。
本書は抄訳であり内容の正確性を保証するものではありません。正確な内容に関しては原文を参照ください。
過去十年間を通じて、セキュリティ/インシデント/イベント管理ツール(SIEM)は企業のセキュリティオペレーションの標準となりました。SIEMには常に批判的な人がいます。しかし、クラウドフットプリントの爆発によって疑問が浮上します。クラウド規模の世界においてSIEMは適切な戦略なのでしょうか?HSBCのセキュリティリーダーはそう思いませんでした。最近のセッションEmpower Splunk and Other SIEMs with the Databricks Lakehouse for Cybersecurityにおいて、HSBCはレガシーなSIEMの限界、そして、どのようにDatabricksレイクハウスプラットフォームがサイバーディフェンスを変化させたのかにハイライトしました。3兆ドルの資産があることから、HSBCのセッションに関してはいくつか探索が必要と言えます。
この記事では、ITとサイバー攻撃の脅威に関するランドスケープの変化、SIEMの利点、Databricksレイクハウスのメリット、なぜ、SIEM + レイクハウスがセキュリティオペレーションチムにおける新たな戦略となるのかを議論します。もちろん、我々の大好きなSIEMについても話します!しかし、注意してください。この記事は「オンプレミスに構築されたレガシーな技術」を批判するものではありません。この記事は、どのようにセキュリティオペレーションチームが、先進的かつ永続的な脅威に対して企業を守ることができるベストな防護策で自身の装備を整えられるのかを説明するものです。
エンタープライズにおける技術的な足跡
ある人はクラウドファースト、別の人はクラウドスマートと呼びます。どちらにしても、クラウドのトランスフォーメーションあるいは評価を行なっているすべての企業、そして技術にオンボーディングすることが簡単な決断ではない公的機関においても広く受け入れられているものです。このため、主要なUSのクラウドサービスプロバイダーは、世界における最大の時価総額トップ5にランクインしています。多くの技術がクラウドに移行しており、サイバーセキュリティチームもクラウドに移行することになっています。脅威の検知、調査のプラクティスは、新たなフットプリントの複雑性と膨大な量のデータによって全てが困難なものとなっています。IBMによると、セキュリティ侵害を検知し封じ込めるには平均280日を要するとのことです。Data + AIサミットにおけるHSBCの話によると、280日とは、ネットワークやEDR(エンドポイント脅威の検知およびレスポンス)データソースだけでもペタバイト以上のデータを意味するとのことです。
企業がこのように膨大データに対して、検知とレスポンスを必要とした際に何をするのでしょうか?多くの企業はクラウドデータはクラウドに維持したいと考えます。しかし、あるクラウドから別のクラウドへの移動はどうでしょうか?今週ある大規模な金融サービス機関と会話した際、こういった話を聞きました。「使っているクラウドプロバイダーに100万ドルの外向きの通信コストを払っているよ」なぜでしょうか?これは、彼らが使っているSIEMツールはあるクラウドサービス上にあり、彼らの最大のデータは別のクラウドにあるためです。彼らが使っているSIEMはマルチクラウドではありません。そして、長い年月をかけて、彼らはデータを取得し別のクラウドプロバイダーに転送する複雑な転送パイプラインを構築したのでした。このような複雑性は彼らの技術に対する期待を捻じ曲げました。例えば、リアルタイムにおける5分のデータの遅延を考えてみてください。ここでは、モダンな企業が直面している現実を説明しました。私は、このような複雑性に直面しているのが、私が会話したグループだけではないと確信しています。
クラウドの世界におけるセキュリティ分析
クラウドの世界は本当にセキュリティオペレーションチームのオペレーションのあり方をメチャクチャにしています。10年前にビッグデータと読んでいたものは、今のクラウド標準では取るに足らないものです。現在のネットワークトラフィックの規模では、ギガバイトがペタバイトになり、生成するのに数ヶ月かかっていたものが数時間で生成されています。新しいスタックが生まれており、セキュリティチームは学習する必要が出てきています。「これらのIPは前に目撃したことがあるか」といった日常的なタスクにおいては、SIEMとロギングツールを検索するのに数時間あるいは数日要するようになっています。ネットワークイベントにユーザー名を追加するといったより洗練されたコンテキスト作成のタスクは、もはや不可能な試練となっています。そして、もし一日当たりテラバイトのデータの外部脅威インテリジェンス情報を用いたストリーミングによるデータ補強をやりたいと思ったのでしたら、皆様が小規模な軍隊と膨大な資産を持っていれば幸いです。幸運を祈ります。そして、我々はまだ異常検知や脅威捕捉ユースケースにすら到達していません。これは間違いなくSIEMの仕事ではありません。実際には、世界は変化しており、それを受け入れる時です。セキュリティチームはこの仕事に適したベストなツールを必要としています。
クラウド世界でセキュリティチームが必要とする機能とは何でしょうか?まず第一に重要なのは、プロプライエタリなデータストアに自分のデータを預ける必要がなく、ITやセキュリティチェーンと統合可能なオープンプラットフォームです。別の重要なファクターは、お好きな(複数の)クラウドで実行可能なマルチクラウドのプラットフォームです。さらに、エンドツーエンドのストリーミングとバッチ処理をサポートする計算資源とストレージが分離されたスケーラブルかつ高性能な分析プラットフォームです。最後に、データサイエンティスト、データエンジニア、SOCアナリスト、ビジネスアナリスト、すべてのデータ人材を支援する統合プラットフォームです。これらがDatabricksレイクハウスプラットフォームの機能です。
DatabricksのSaaS、オートスケーリングの機能は、これら洗練された機能の活用をシンプルにします。 Databricksをセキュリティ目的で活用しているお客様は10分未満でペタバイトのデータを活用しています。あるお客さまは、1500万以上のエンドポイントからデータを収集し、1時間以内に脅威の兆候を分析しています。グローバルなオイル&ガスの生産者はランサムウェアに対して被害妄想を持っており、彼らの環境における個々のpowershellの実行のコンテキスト化と複数の分析を実施しており、アナリストは信頼性の高いアラートのみを参照します。
レイクハウス + SIEM: クラウド規模のセキュリティオペレーションのパターン
HSBCのサイバーセキュリティサイエンス & アナリティクスのヘッドであるGeorge Websterは、レイクハウス + SIEMがセキュリティオペレーションに対するパターンであると述べています。ここでは、マルチクラウドネイティブなストレージと分析のためのレイクハウスアーキテクチャ、セキュリティオペレーションのためのSIEMという2つのコンポーネントの強みを活かしています。Databricksのお客さまにおいては、このインテグレーションに対して2つの一般的なパターンが存在します。しかし、Websterがレイクハウスを用いたサイバーセキュリティデータレイクと呼ぶものによって、両方が支援されます。
1つ目のパターン: 最大の保持期間においてレイクハウスがすべてのデータを保持します。データのサブセットがSIEMに送られ、ある一定の期間保持されます。このパターンにおいては、アナリストはSIEMを使ってニアリアルタイムでクエリーを行いつつも、Databricks上で過去データの分析やより高度な分析を行えるという利点があります。そして、SIEMのデプロイメントに対するライセンス費用やストレージコストを管理できます。
2つ目のパターンでは、最大ボリュームのデータソース(例: クラウドネイティブのログ、エンドポイント脅威検知およびレスポンスのログ、DNSデータ、ネットワークイベント)からDatabricksにデータが送信されます。比較的ボリュームの小さいデータソース(例: アラート、メールログ、脆弱性スキャンデータ)からSIEMにデータが送信されます。このパターンでは、SIEMで優先度の高いアラートをクイックに取り扱えるティア1分析が可能となります。脅威ハントチームと調査官はDatabricksにおける高度な分析機能を活用することができます。このパターンでは、SIEMから処理、調査、ストレージをオフロードすることによるコストメリットがあります。
レイクハウスとSplunkを連携する
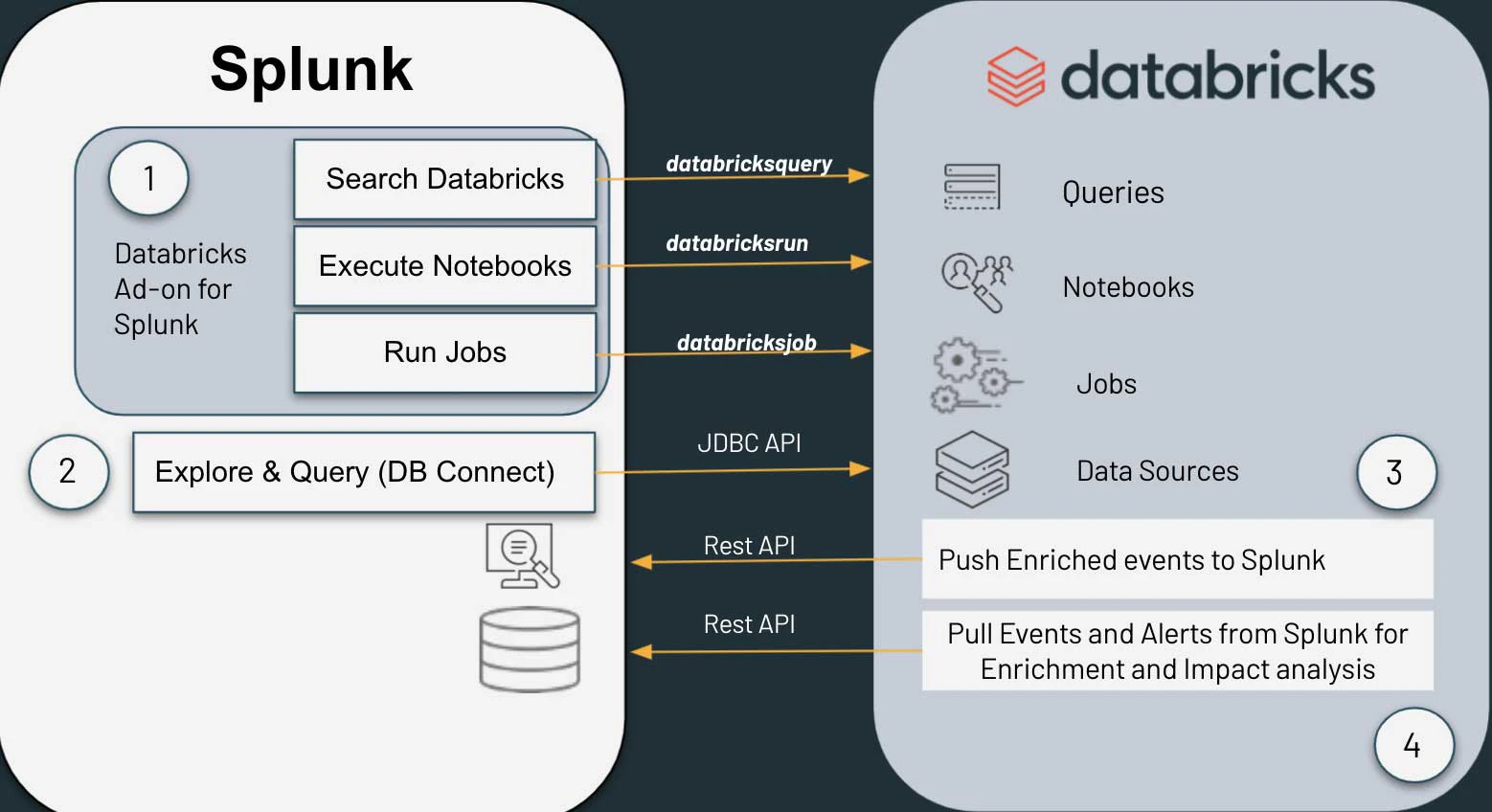
実際に動くサンプルとはどのようなものでしょうか?お客さまの要求に基づき、DatabricksのサイバーセキュリティSMEチームはSplunkに対するDatabricksアドオンを作成しました。このアドオンを用いることで、セキュリティアナリストは、SplunkからDatabricksのクエリーやノートブックを実行し、Splunkに結果を戻すことができます。添付のDatabricksノートブックは、DatabricksからSplunkにクエリーを行い、Splunkの結果を取得し、イベントや結果をDatabrikcsからSplunkに転送することができます。
これら2つの機能によって、アナリストはSplunkのUIを離れることなしにSplunkのサーチバーでDatabricksとやり取りをすることができます。そして、Splunkのサーチビルダーとダッシュボードにはこれらのサーチの一部としてDatabricksを含めることができます。しかし、最も素晴らしいのは、セキュリティチームがSplunkとDatabricks間の双方向の自動分析パイプラインを作成できるということです。例えば、Splunkでアラートがあった場合、Splunkは自動で関連イベントをDatabricksから検索することができ、結果をアラートのインデックスあるいはダッシュボード、後続のサーチに追加することができます。あるいは逆に、DatabricksノートブックのコードブロックがSplunkに対してクエリーを行い、結果を後続のコードブロックの入力にすることができます。
このリファレンスアーキテクチャを用いることで、企業は自身のインフラストラクチャをモダン化しつつも自身の現在のプロセスや手順を維持することができ、自身の拡大するデジタルフットプリントのサイバーセキュリティのリスクに対応できるようにマルチクラウドネイティブになることができます。
スケール、スピード、セキュリティ、コラボレーションを達成する
Databricksとのパートナー関係を結んで以来、HSBCはコストを削減し、脅威検知・レスポンスを加速し、セキュリティに対する態勢を改善しました。金融機関が必要とするすべてのデータを処理できるだけでなく、オンラインの問い合わせの保持期間を数日からペタバイト規模の数ヶ月にまで拡張することができました。攻撃者のスピードと悪意のある活動を検知し、調査を実施するHSBCの能力の間のギャップは狭まっています。攻撃者のペースとスピードで高度な分析をこなうことで、HSBCは悪者よりも早く行動するという彼らのゴールに近づいています。
データ保持の能力によって、HSBCの脅威ハントのスコープは劇的に拡大しました。今では、HSBCはハードウェアの制限を受けることなしに、アナリストあたり2〜3倍の脅威ハントが行えるようになっています。Databricksノートブックを用いることで、脅威ハントは再利用でき、自身にドキュメントを含めることができるので、未来のハントでも過去のデータをそのまま活用することができます。このような情報や調査、脅威ハントのライフサイクルは、脅威検知を自動化し繰り返せるように、HSBCのチームで共有することができます。この効率性によって、スピードと機械学習/人工知能のイノベーションは今では現実のものとなっており、HSBCはコスト、リソースの再配置、そして自身のビジネス上重要なデータをより適切に防御できるようになっています。
次のステップ
サイバーセキュリティの要件にどのように取り組んだのかを直接HSBCとDatabricksから聞くためにEmpower Splunk and Other SIEMs with the Databricks Lakehouse for Cybersecurityをご覧ください。
DatabricksのSplunkアドオンの詳細に関してはこちらを参照ください。
リファレンス
- 時価総額: https://www.visualcapitalist.com/the-biggest-companies-in-the-world-in-2021/
- 脅威のライフサイクル: https://www.ibm.com/security/digital-assets/cost-data-breach-report/#/