Machine Learning with Unity Catalog on Databricks: Best Practices | Databricks Blogの翻訳です。
本書は著者が手動で翻訳したものであり内容の正確性を保証するものではありません。正確な内容に関しては原文を参照ください。
サマリー
- Unity Catalogを用いた、データの前処理からモデルのトレーニング、デプロイメントに至るシームレスなMLモデルの構築とデプロイ。
- ロールベースのアクセス制御、グループ向けクラスター、ガバナンス機能を活用することによるセキュアなコラボレーションの強化。
- 効率的なMLワークフローのための専用のグループクラスター、Delta Live Tablesによる計算リソースの最適化。
エンドツーエンドでのAIやMLのプラットフォームの構築には多くの場合、データを分析し、ビジネス部門と学びを共有するために、ストレージ、分析、ビジネスインテリジェンス(BI)ツール、MLモデルの複数の技術的なレイヤーを必要とします。ここでの課題は、異なるチームが関与する様々なツールに対して一貫性があり効果的なガバナンスコントロールを適用することです。
Unity Catalogはデータアクセス、セキュリティ、リネージを管理するために設計されたDatabricksビルトインの集中管理されたメタデータレイヤーです。これは、プラットフォームにおける検索や発見の基盤としても機能します。Unity Catalogは、ロールベースのアクセスコントロール、監査追跡、データマスキングのような堅牢な機能を提供することで、チーム間のコラボレーションを促進し、生産性を阻害することなしにセンシティブな情報の保護を確実なものとします。また、これはMLモデルにおけるエンドツーエンドのライフサイクルをサポートしています。
このガイドでは、機械学習ユースケースや計算リソースの共によるチーム間のコラボレーションにおけるUnity Catalogの活用方法に対する包括的な概要とガイドラインを提供します。
このブログ記事では、DatabricksにおけるUnity Catalogの高度な機能による機械学習のエンドツーエンドのライフサイクルにおけるステップをウォークスルーします。
本書の例では、USにおける日毎のCOVID-19の感染者数のレコードを含むデータセットと追加の地理情報を用います。ここでのゴールは、USにおける向こう7日間でのウィルス感染者数を予測することです。
DatabricksのMLのキーとなる機能
Databricksは、Unity CatalogにおけるMLのサポートを改善するために複数の機能をリリースしました。
- Databricks機械学習ランタイム(Databricks Runtime ML): 最も一般的なML、DLライブラリを含む構築済みの機械学習、ディープラーニングインフラストラクチャを用いてクラスター作成を自動化します。
- グループ専用クラスター: 専用アクセスモードを用いてグループに割り当てられるDatabricks機械学習ランタイムが稼働する計算リソースを作成します。
- デリケートなアクセスモードにおけるきめ細かいアクセスコントロール: 専用アクセスモードで動作するDatabricks機械学習ランタイムのクラスターで実行されるクエリーに対するきめ細かいアクセスコントロールを可能にします。これは、マテリアライズドビュー、ストリーミングテーブル、標準的なビューをサポートします。
要件
- ワークスペースではUnity Catalogが有効化されている必要があります。ワークスペース管理者は、ワークスペースにおけるUnity Catalogの有効化方法をマニュアルでチェックすることができます。
- Databricksランタイム15.4 LTS ML以上を使う必要があります。
- ワークスペース管理者はプレビューUIを用いてCompute: Dedicated group clustersを有効化する必要があります。Databricks プレビューの管理をご覧ください。
- ワークスペースでSecure Egress Gateway (SEG)が有効化されている場合、許可ドメインリストに
pypi.orgを追加する必要があります。サーバレスエグレスコントロールのネットワークポリシーの管理をご覧ください。
グループのセットアップ
コラボレーションを可能にするには、アカウント管理者あるいはワークスペース管理者は、以下の手順でグループをセットアップする必要があります:
- 右上のユーザーアイコンをクリックし、設定をクリックします。

- 「Workspace Admin」セッションにある「Identity and access」をクリックし、グループセクションの「Manage」をクリックします。

- 「Add group」をクリックし、

- 「Add new」をクリックします。

- グループ名を入力して「Add」をクリックします。

- 新たに作成したグループを検索し、Source列が「Account」になっていることを確認します。

- 検索結果のグループ名をクリックしてグループの詳細に移動します。
- 「Members」タブをクリックし、グループに割り当てるメンバーを追加します。

- 「Entitlements」タブをクリックし「Workspace access」と「Databricks SQL access」の両方をチェックします。

- すべての非管理者アカウントからこのグループを管理できるようにするには、「Permissions」タブで当該アカウントに「Group: Manager」アクセス権を付与することができます。

- 注意: グループクラスターを使うためにはユーザーはこのグループのメンバーである必要があります。グループマネージャだけでは権限が不足します。
グループ専用クラスターの有効化
グループ専用クラスターはパブリックプレビューなので、この機能を有効化するにはプレビューUIを用いてこの機能を有効化する必要があります。
- Databricksワークスペースのトップバーでユーザー名をクリックします。

- メニューからPreviewsを選択します。
- プレビュー機能を有効化、無効化するにはCompute: Dedicated group clustersのトグルを使用します。

グループコンピュートの作成
専用アクセスモードはシングルユーザーアクセスモードの最新バージョンです。専用アクセスを用いることで、計算リソースを単一のユーザーあるいはグループに割り当てることができ、割り当てられたユーザーのみがその計算リソースを使用することができます。
Databricks機械学習ランタイムが稼働するクラスターを作成するには:
- Databricksワークスペースでクラスターに移動し、コンピューティングを作成をクリックします。

- Databricks機械学習ランタイムを選択するには、パフォーマンスセクションで「機械学習」をチェックします。Databricksランタイムでは「15.4 LTS」を選択します。必要なインスタンスタイプとワーカー数を選択します。

- ページ下部のAdvancedセクションを展開します。

- アクセスモードで手動を選択し、ドロップダウンから専用 (旧: シングルユーザー)を選択します。
- シングルユーザーまたはグループのフィールドで、このリソースに割り当てたいグループを選択します。
- 必要に応じて他の設定を行い、作成をクリックします。
クラスターが起動すると、グループに属しているすべてのユーザーは同じクラスターを共有することができます。詳細に関しては、グループ クラスターを管理するためのベスト プラクティスをご覧ください。
Delta Live Tables(DLT)を通じたデータの前処理
このセクションでは以下を行います:
- 生データを読み込んでボリュームに保存します。
- 取り込みテーブルからレコードを読み込み、クレンジングしたデータを格納する新規テーブルを作成するためにDelta Live Tablesのエクスペクテーションを活用します。
- 派生データセットを作成するDelta Live Tablesのクエリーに対する入力として、クレンジングしたレコードを使用します。
DLTパイプラインをセットアップするためには、以下の権限を必要とする場合があります:
- 親のカタログにおける
USE CATALOG、BROWSE - ターゲットスキーマにおける
ALL PRIVILEGESあるいはUSE SCHEMA、CREATE MATERIALIZED VIEW、CREATE TABLE権限
-
ボリュームにデータをダウンロードします: この例ではUnity Catalogのボリュームからデータをロードします。
my_catalog = "<catalog-name>" my_schema = "<schema-name>" my_volume = "<volume-name>" spark.sql(f"CREATE SCHEMA IF NOT EXISTS {my_catalog}.{my_schema}") spark.sql(f"CREATE VOLUME IF NOT EXISTS {my_catalog}.{my_schema}.{my_volume}") volume_path = f"/Volumes/{my_catalog}/{my_schema}/{my_volume}/" download_url = "/databricks-datasets/COVID/covid-19-data/us-counties.csv" filename = "us-counties.csv" dbutils.fs.cp(download_url, volume_path + filename)<catalog-name>、<schema-name>、<volume-name>をUnity Catalogのカタログ、スキーマ、ボリュームの名前で置き換えます。上のコードは、それらのオブジェクトが存在しない場合にはスキーマとボリュームの作成を試みます。Unity Catalogのオブジェクトの作成、書き込みを行うためには適切な権限が必要となります。要件をご覧ください。 -
パイプラインを作成します。新規パイプラインを作成するには以下を実施します:
- サイドバーで、データエンジニアリングセクションにあるDelta Live Tablesをクリックします。

-
パイプラインを作成をクリックします。

- パイプライン名にはユニークなパイプライン名を入力します。

- サーバレスチェックボックスを選択します。
- 配信先では、テーブルが公開されるUnity Catalogのロケーションを設定し、カタログとスキーマを選択します。

- Advancedでは設定を追加し、以下のパラメータ名を用いて、データをダウンロードしたカタログ、スキーマ、ボリュームのパイプラインパラメータを定義します:
- my_catalog
- my_schema
- my_volume
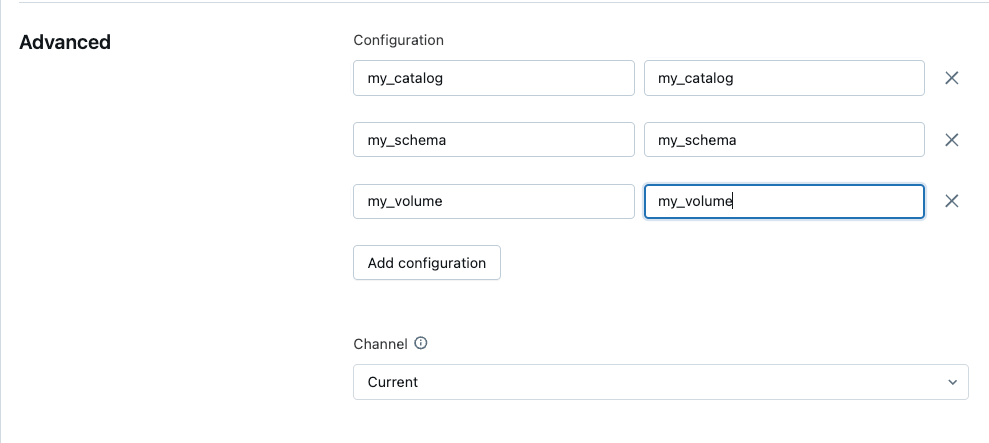
- 作成をクリックします。
新規パイプラインのためのパイプラインUIが表示されます。ソースコードノートブックが自動的に作成され、パイプラインとして設定されます。
- サイドバーで、データエンジニアリングセクションにあるDelta Live Tablesをクリックします。
-
マテリアライズドビューとストリーミングテーブルを宣言します。Delta Live Tablesパイプラインのソースコードをインタラクティブに開発、検証するためにDatabricksノートブックを使うことができます。
-
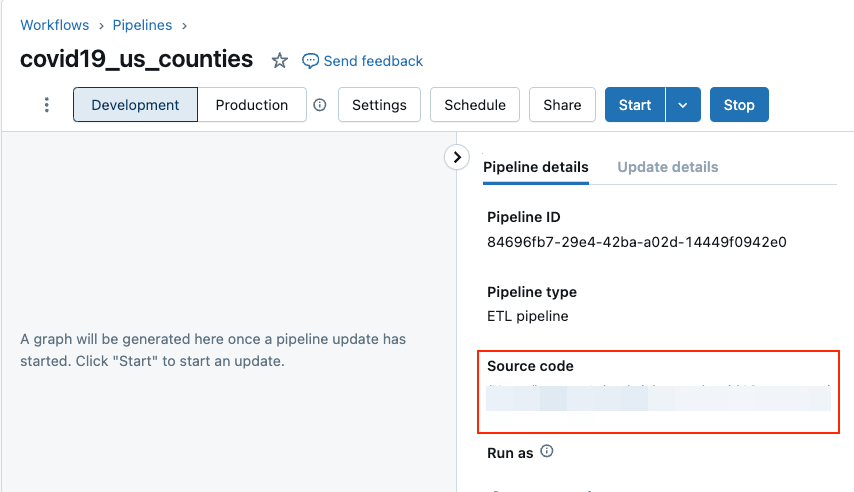
ノートブックを開くには、パイプライン詳細パネルのソースコードフィールドにあるリンクをクリックします。
-
PythonやSQLを用いてコードを開発します。詳細は、Python を使用したパイプライン コードの開発やSQL を使用したパイプライン コードの開発 をご覧ください。
# Import modules import dlt from pyspark.sql.functions import * # Assign pipeline parameters to variables my_catalog = spark.conf.get("my_catalog") my_schema = spark.conf.get("my_schema") my_volume = spark.conf.get("my_volume") # Define the path to source data volume_path = f"/Volumes/{my_catalog}/{my_schema}/{my_volume}/" # Define a streaming table to ingest data from a volume @dlt.table( comment="Covid 19 case data." ) def covid_case_raw(): df = (spark.readStream .format("cloudFiles") .option("cloudFiles.format", "csv") .option("inferSchema", True) .option("header", True) .load(volume_path) ) return df # Define a materialized view that validates data @dlt.table( comment="Covid 19 case data cleaned and prepared for analysis." ) @dlt.expect("valid_cases", "cases IS NOT NULL") @dlt.expect("valid_deaths", "deaths IS NOT NULL") def covid_case_prepared(): return ( spark.read.table("LIVE.covid_case_raw") .select("date", "cases", "deaths") ) # Define a materialized view that has a filtered, aggregated, and sorted view of the data @dlt.table( comment="A Covid 19 cased table summerized by date." ) def covid_case_by_date(): return ( spark.read.table("LIVE.covid_case_prepared") .groupBy("date") .agg(sum("cases").alias("cases")) .sort("date") ) -
-
ノートブックやDLT UIの右上にある開始ボタンをクリックすることでパイプラインのアップデートをスタートします。DLTで定義されたテーブルが
<my_catalog>.<my_schema>のカタログとスキーマの配下に生成されます。
DLTのマテリアライズドビューに対するモデルトレーニング
DLTによって生成されたマテリアライズドビューに対して、サーバレス予測エクスペリメントを起動します。
-
機械学習セクションのエクスペリメントをクリックします。
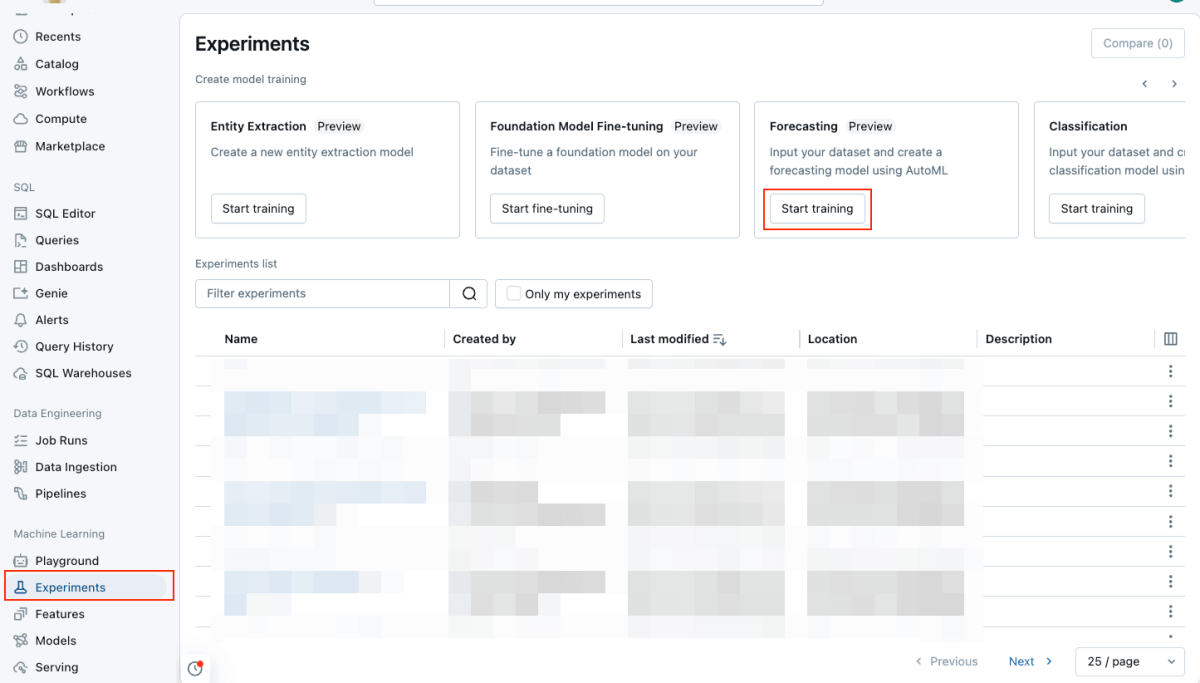
- 予測タイルのトレーニングを開始を選択します。
- 設定フォームで以下を入力します:
- トレーニングデータとしてマテリアライズドビューを選択します:
<my_catalog>.<my_schema>.covid_case_by_date - 時間列としてTime列を選択します。
- 予測頻度では日を選択します。
- 予測期間では7を入力します。
- 予測セクションではターゲット列でcasesを選択します。
-
モデルの登録では
<my_catalog>.<my_schema>を選択します。

- 予測エクスペリメントをスタートするためにトレーニングを開始をクリックします。
- トレーニングデータとしてマテリアライズドビューを選択します:
トレーニングが完了すると、予測結果は指定したDeltaテーブルに格納され、ベストモデルがUnity Catalogに登録されます。
エクスペリメントページでは、次のステップとして以下を行うことができます:
- 予測結果テーブルを参照するためにView predictionsを選択します。
- ベストモデルを用いたバッチ推論のために自動生成されたノートブックを開くためにBatch inference notebookを選択します。
- モデルサービングエンドポイントにベストモデルをデプロイするために、Create serving endpointを選択します。
まとめ
この記事では、データの前処理からモデルのトレーニングに至る予測モデルのセットアップとトレーニングのエンドツーエンドのプロセスを探索しました。Unity Catalog、グループクラスター、Delta Live Tables、AutoMLの予測を活用することで、モデル開発を円滑にし、チーム間のコラボレーションをシンプルにすることができます。