Real-time Insights in Financial Services - The Databricks Blogの翻訳です。
本書は抄訳であり内容の正確性を保証するものではありません。正確な内容に関しては原文を参照ください。
パーソナライゼーションのためのストリーミング基盤
銀行から保険会社に至るほぼすべての金融サービス機関(略してFSI)において、パーソナライゼーションは競争力を持つ差別化要因となっており、今では投資管理のプラットフォームとなっています。あらゆるFSIがインテリジェントかつリアルタイムのパーソナライゼーションを顧客に提供したいと考えていますが、多くのケースで基盤が見せかけだけのものであるか、不完全なプラットフォームで実装されており、ストリーミング、AI、レポーティングサービスを結びつける必要がありながらも、時代遅れの洞察、市場提供の遅れ、生産性の損失を引き起こしています。
この記事では、OLTPデータベースから、チェンジデータキャプチャ(CDC)、ダッシュボードでのレポーティングに至る、Databricksレイクハウスプラットフォームによる金融サービス向けユースケースにおけるリアルタイム洞察のための、堅牢な基盤をどのように構築するのかを説明します。Databricksは、プラットフォームネイティブのストリーミングを長期間に渡ってサポートしてきています。最近のDelta Live Tables(DLT)のリリースによって、ストリーミングがさらにシンプルになり、新たなCDC機能によってさらにパワフルになりました。最近投稿した包括的なブログ記事では、DLTを用いたCDCのガイドをカバーしています。この記事では、FSI向けのストリーミングにフォーカスし、これらの機能が新製品の差別化要因とFSI内部向け洞察を支援するのかを説明します。
ストリーミング取り込みがなぜ重要なのか
技術的詳細に踏み込む前に、なぜDatabricksがパーソナライゼーションのユースケースに最適なのか、特になぜ最初のステップとしてストリーミングを実装すべきなのかを論じましょう。カスタマー360プロジェクトやフルファンネルのマーケティング戦略を実装しているDatabricksの多くのお客様は、通常以下のような基本的な要件を持っています。一時的な(時間に関連する)データフローに注意します。
FSIのデータフローと要件
- ユーザー向けアプリケーションは、クリックストリームやユーザーの更新、位置情報データなどのデータを保存、更新します -
オペレーショナルデータベースが必要となります。 - クラウドアカウント上のオブジェクトストレージ、あるいはデータベースにサードパーティーの行動データがインクリメンタルにデリバリーされます -
分析のための信頼できる唯一の情報源として新規データをインクリメンタルに追加、更新、削除するストリーミング機能が必要となります。 - FSIはユーザーの更新、クリックストリーム、ユーザーの行動データを含むすべてのデータベースのデータをデータレイクにエクスポートする自動化プロセスを持っています -
チェンジデータキャプチャ(CDC)を行う取り込み、処理ツール、そして、準構造化データ、非構造化データのサポートが必要となります。 - データエンジニアリングチームは、自動化されたデータ品質チェックを実行し、データが最新であることを保証します -
データ品質ツールとネイティブなストリーミングが必要となります。 - データサイエンスチームは、ネクストベストアクションや他の予測分析のためにデータを活用します -
ネイティブなML(機械学習)の機能が必要となります。 - 分析エンジニアやデータアナリストは、データモデルをマテリアライズし、レポートにデータを活用します -
ダッシュボードのインテグレーションとネイティブな可視化が必要となります。
ここでのコアの要件は、レポートのためのデータの鮮度、一貫性を維持するためのデータ品質、CDC取り込み、MLで活用できるデータストアです。Databricksでは、これらはDelta Live Tables(特に、Auto Loader、エクスペクテーション、DLTのSCD Type OのAPI)、Databricks SQL、そしてFeature Storeに直接マッピングされます。レポートとAIドリブンな洞察は、高品質なデータの弛まないフローに依存するので、論理的にストリーミングが最初に検討すべきステップとなります。

例えば、リテールバンクがより多くの顧客を惹きつけ、ブランドロイヤリティを改善するためにデジタルマーケティングを活用しようとしていると考えてみます。顧客の購買パターンにおける鍵となるトレンドを特定し、顧客の要望や必要性に正確に仕立てられた専用の製品のリアルタイムのオファーを用いて、パーソナライズされたコミュニケーションを送信することは可能です。これはシンプルですが、顧客の行動とリスクのプロファイルにおける変更を捕捉するため必要となるストリーミングとチェンジデータキャプチャ(CDC)の両方が必要となる非常に重要なユースケースです。
我々のリファレンスパイプラインにおいて取り扱うデータのタイプを覗いてみるために、以下のサンプルをご覧ください。データの時間的特性に注意してください。すべての銀行、融資システムは時間で並べられたトランザクションデータを取り扱い、信頼できるデータソースとは、遅延して到着するデータ、順番が入れ替わったデータに対応できることを意味します。以下に示すコアのデータセットには、当座預金口座(図2)、顧客のアップデート、トランザクションや上流のサードパーティデータから追跡されたであろう行動データ(図3)が含まれています。
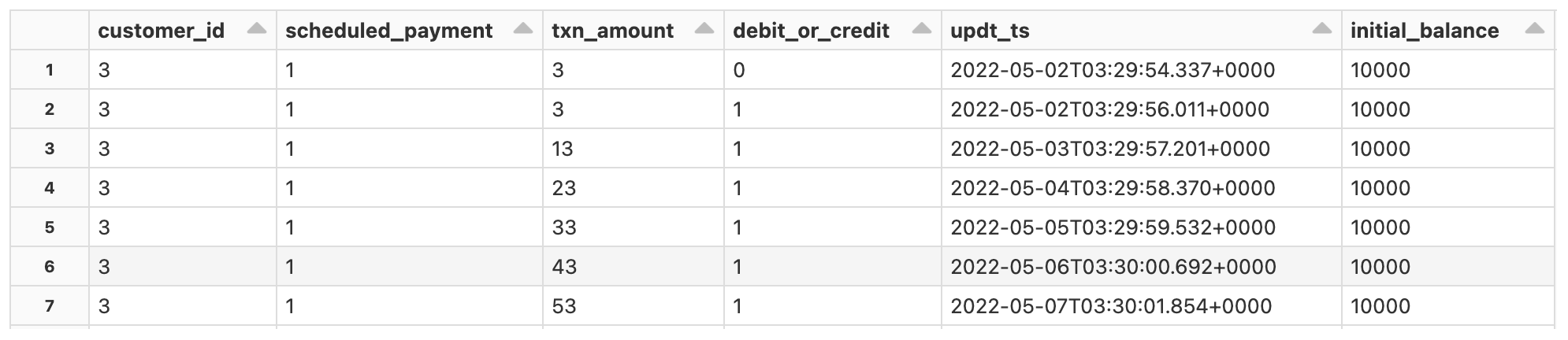
図2
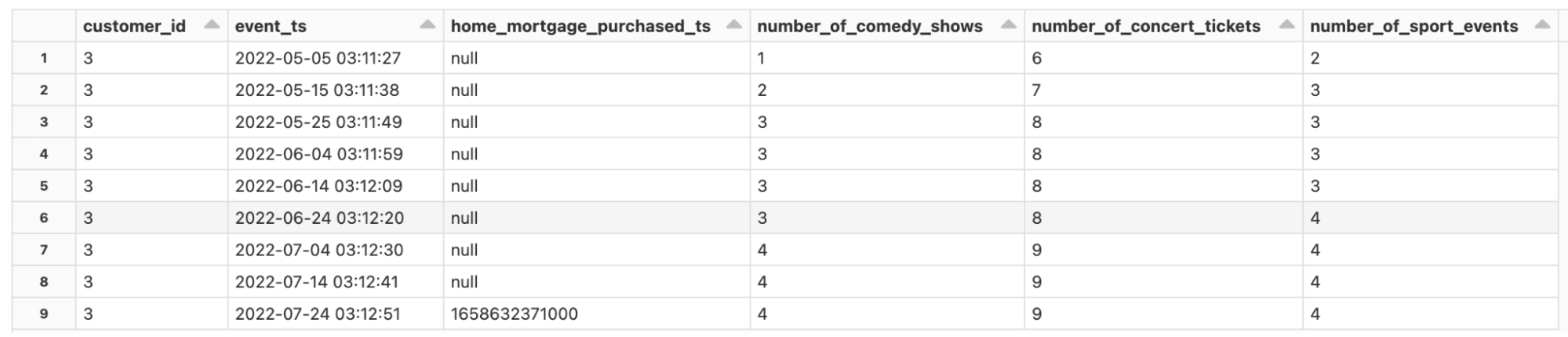
図3
ストリーミングを始めてみる
このセクションでは、Databricksのストリーミング機能を用いて、トランザクションデータベースからの継続的な変更をどのように捕捉し、レイクハウスに格納するのかを明らかにできるように、シンプルなエンドツーエンドのデータフローを説明します。
スタート地点は、トランザクションデータベースにおける標準的なフォーマットを真似たレコードからとなります。以下の図では、FSIのインフラストラクチャを通じて、最終的にはDelta Lakeに到着するさまざまな種類のデータがクレンジングされ、要約されてダッシュボードに表示されるになるために、どのようにデータが流れるのかを示すエンドツーエンドの図を示しています。この図で説明される主要なプロセスは3つあり、次のセクションでそれぞれに対するいくつかのアドバイスを説明していきます。
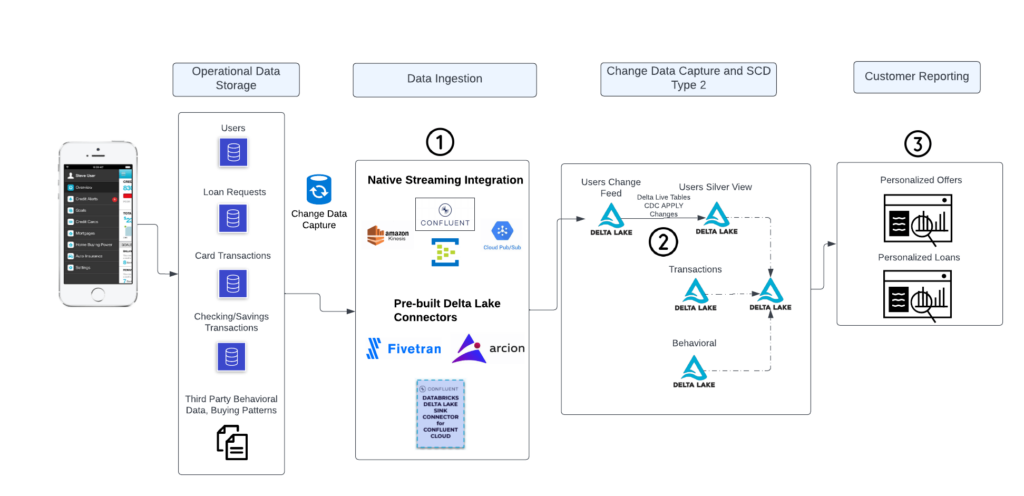
FSIのインフラをデータが流れるエンドツーエンドのアーキテクチャ、最終的にはDelta Lakeに大量のデータが到着し、クレンジングされ、要約され、ダッシュボードで提供される。
プロセス #1 - データ取り込み
ネイティブな構造化ストリーミングによる取り込みのオプション
バンキングや保険のアプリを通じて顧客が提供するデータの増加に伴い、FSIは下流にいるチームが様々なユースケースでデータを活用できるように、データ収集に対する戦略を作り出す必要性に迫られました。これらの企業が直面する最も基本的な意思決定の一つに、顧客がプロダクション環境のアプリケーションサービス、ユーザーからポリシー、融資アプリ、クレジットカードのトランザクションから生成するすべての変更をどのようにキャプチャするのかというものです。基本的に、これらのアプリケーションはトランザクションデータソースに支えており、MySQLデータベースやMongoDBのようなNoSQLデータベースに存在するその他の非構造化データベースが使用されています。
幸運なことに、これらのシステムの外からデータを取り込むことができるDebeziumのような数多くのオープンソースツールが存在しています。あるいは、多くのお客様がトランザクションのデータストアからデータを読み込み、マネージドのKafkaクラスターのような分散メッセージキューに書き込みを行うステートフルなクライアントを自分の手で開発しているのを見てきています。DatabricksはKafkaと密接なインテグレーションをしており、ストリーミングジョブとの直接接続はデータが可能な限り新鮮である必要がある場合に推奨されるパターンとなります。このセットアップによって、リアルタイムのクロスセルのレコメンデーションや損失のリアルタイムビュー(バランスシートにおける現金のリワーズの影響)のようなビジネスに対するニアリアルタイムの洞察を実現することができます。このパターンは以下のようになります。
- Kafkaに変更レコードを書き無ためのCDCツールのセットアップ
- Debeziumあるいは他のCDCツールに対するKafkaシンクのセットアップ
- Kafkaからブロンズテーブルにデータが直接到着し、Delta Live Tablesを用いたDatabricks上でのチェンジデータキャプチャ(CDC)レコードのパースおよび処理
考察
良い点
- 低レーテンシーでデータが継続的に到着するので、利用者はバッチのアップデートに依存することなしにニアリアルタイムで結果を取得できる。
- ストリーミングロジックに対する完全なコントロール。
- ブロンズレイヤーに対してDelta Live Tablesはクラスター管理を抽象化しながらも、ユーザーにオートスケーリングを提供することでリソース管理を効率的に行える。
- Delta Live Tablesは、完全なデータリネージュとブロンズレイヤーに到着するデータに対するシームレスなデータ品質モニタリングを提供。
悪い点
- Kafkaからの直接読み込みは、ブロンズのステージングレイヤーにデータが到着した際に必要となるパーシングのコードが必要になる。
- 直接の接続を確立するツールを用いるのではなく、データベースからデータを抽出し、メッセージストアにデータを投入するために、外部サードパーティのCDCツールに依存している。
パートナーのデータ取り込みオプション
継続的な洞察のためのダッシュボードにデータを供給する2つ目のオプションは、Databricksへのデータ取り込みをシンプルなものにするデータ取り込みパートナーの広範なネットワークであるDatabricks Partner Connectです。この例では、Databricksと密接に連携する堅牢なマネージドKafkaオファリングであるConfluentによって開発されたDeltaコネクターを通じてデータを取り込みます。FivetranやArcionのような他の人気のツールは、コアのトランザクションシステムに対する数百のコネクターを提供しています。

両方のオプションは、COPY INTOの利用を通じて、Delta Lakeにおける生データの読み込みとデータの到着に関するコアロジックの多くのを抽象化します。このパターンでは、以下のステップが実行されます。
- Kafkaに変更レコードを書き込むCDCツールのセットアップ(上と同じ)
- Confluent Cloud向けDatabricks Delta Lakeシンクコネクターをセットアップし、適切なトピックに接続
このオプションとネイティブストリーミングオプションの主な違いは、ConfluentのDelta Lakeシンクコネクターを使うかどうかです。どのパターンを選択するのかを理解するためにトレードオフを見てみましょう。
考察
良い点
- オンプレミスのレガシーソース、データベース、メインフレームからの高速なデータ複製をサポートするパートナーツール(Fivetran、Arcionなどデータベースと直接接続できる他のツール)を通じたローコードのCDC。
- ストリーミングパートナーに馴染みのあるデータプラットフォームチーム向けのローコードのデータ取り込み、Apache Spark™を使わずにDelta Lakeにデータを取り込める環境。
- Confluent Cloud(Fivetranも同様)でのトピックとシンクのコネクターの集中管理。
悪い点
- 初期ETLステージにおけるSparkやサードパーティライブラリによるデータ変換およびペイロードのパーシングに対する低いコントロール。
- コネクター向けのDatabrikcsクラスターの設定が必要。
ファイルベースの取り込み
モバイルテレマティクスプロバイダー、信用データプロバイダー、内部データプロデューサーを含む数多くのデータベンダーは、クライアントにファイルを提供することでしょう。インクリメンタルなファイルの取り込みを最も適切に取り扱えるようにするためにDatabricksは、旅行データの日中のフィード、トレードアンドクォート(TAQ)データ、収益予測のためのセールスのレシートのようなインクリメンタルなデータの状態を追跡するシンプルかつ自動化されたストリーミングツールであるAuto Loaderを導入しました。
Auto LoaderはDelta Live Tablesのパイプラインで利用することができ、低レベルの詳細を設定することなしに数百のデータフィードを容易に処理することができます。Auto Loaderは大規模にスケールすることができ、簡単に一日あたり数百万のファイルを取り扱うことができます。さらに、Delta Live Tables APIの文脈ではシンプルに使うことができます(以下のSQLの例をご覧ください)。
CREATE INCREMENTAL LIVE TABLE customers
AS SELECT * FROM cloud_files("/databricks-datasets/retail-org/customers/", "csv", map("delimiter", "\t"))
プロセス #2 - チェンジデータキャプチャ
トランザクションデータベースに追加の負荷をかけることなしに、コアシステムから集中管理されたデータストアに最終的に変更を保存するチェンジデータキャプチャソリューションが必要になります。デジタルデータの膨大なストリームによって、バンキングやクレーム体験をパーソナライズするために、顧客行動の変更を捕捉することは非常に大規模な取り組みとなっています。
技術的視点から、我々はハイライトするCDCツールとしてDebeziumを使っています。ここで特筆すべきことは、リアルタイムで最新の変更を特定し、ターベットテーブルに適用するためのレコードを通じて、Delta Live Tables(DLT)がソートに使用するDebeziumのdatetime_updatedエポックであるシーケンスキーです。繰り返しになりますが、ユーザージャーニーには重要な時間的要素が関わっているので、ユーザーの状態を更新するのに必要な複雑性を抽象化するDLTのAPPLY CHANGES INTO機能がエレガントなソリューションとなります。DLTはシンプルに1行のSQLあるいはPythonのコマンドを用いてニアリアルタイムで状態を更新します(つまり、リアルタイムで顧客の嗜好をで参加したイベントの数を3から5に更新し、パーソナライズされたオファーを提供する機会を強化します)。
以下のコードでは、最新の顧客を確認し、更新を集計するためのテーブルに連続的なストリームの到着を指定することができるSQLストリーミング機能を使用しています。以下の完全なパイプラインの設定をご覧ください。完全なコードはこちらからアクセスできます。
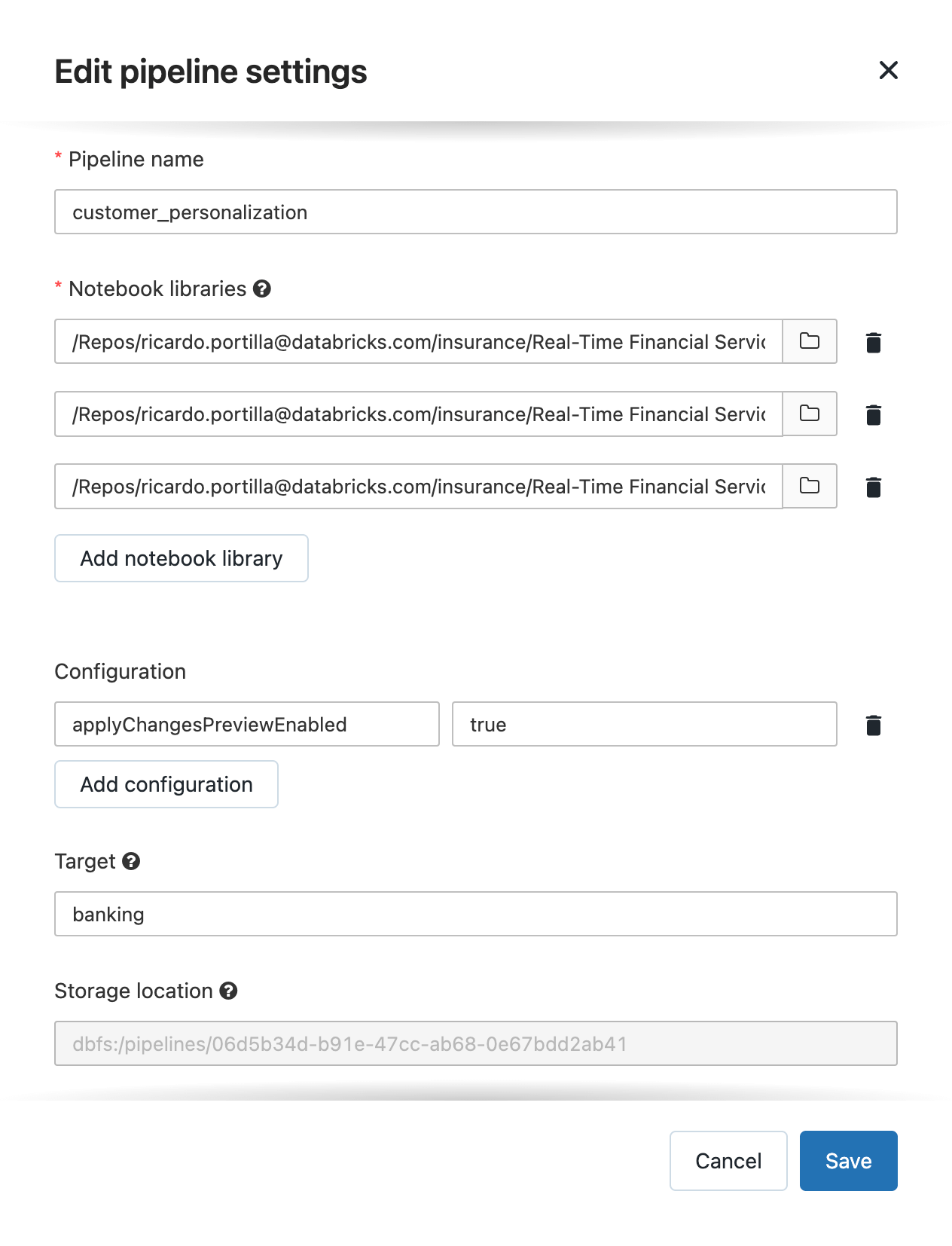
ここで注意しておくべきことがいくつかあります。
- STREAMINGキーワードはストリーミングのソース(Kafkaなど)からのインクリメンタルなインサート/アップデート/デリートを受け付ける(顧客のトランザクションのような)テーブルであることを意味します。
- LIVEキーワードは、データセットが内部的なものであり、既にDLT APIを用いて保存されており、DLTが提供する完全自動化機能(自動コンパクション、クラスター管理、パイプライン設定を含みます)の全てを利用できることを意味します。
-
APPLY CHANGES INTOはDLTが提供するエレガントなCDC APIであり、内部で状態を維持することで、追加のコードやSQLコマンドを記述することなしに、順序が乱れた、あるいは遅れて到着したデータを取り扱うことができます。

CREATE STREAMING LIVE TABLE customer_patterns_silver_copy
(
CONSTRAINT customer_id EXPECT (customer_id IS NOT NULL) ON VIOLATION DROP ROW
)
TBLPROPERTIES ("quality" = "silver")
COMMENT "Cleansed Bronze customer view (i.e. what will become Silver)"
AS SELECT json.payload.after.* , json.payload.op
FROM stream(live.customer_patterns_bronze);
APPLY CHANGES INTO live.customer_patterns_silver
FROM stream(live.customer_patterns_silver_copy)
KEYS (customer_id)
APPLY AS DELETE WHEN op = "d"
SEQUENCE BY datetime_updated;
プロセス #3 - 顧客の嗜好とシンプルなオファーの要約
上述したシンプルなデータ取り込みパイプラインを完結するために、ここで我々はレイクハウスを用いることでどのようなタイプの機能と洞察が実現できるのかを説明するために、Databricks SQLのダッシュボードをハイライトします。以下に示すすべてのメトリクス、セグメント、オファーは、この洞察パイプラインのために模したリアルタイムのデータフィードから生成されています。これらは分刻みで更新するようにスケジュールすることもでき、さらに重要なことに、このデータは新鮮かつMLで活用することができるようになっています。特筆すべきメトリクスには、顧客口座の履歴に基づく顧客の生涯価値や処方的なオファー、キャッシュバックによる損失やブレークイーブンの閾値が含まれます。リアルタイムのシンプルなレポートは、どのようにキャッシュバックのオファーのような特定の製品をリリースするのかに関する情報を提供します。最後になりますが、レポート用のダッシュボード(DatabricksあるいはPower BIやTableauのようなBIパートナー)はこれらの洞察を表出化します。洞察が利用できるようになった際には、背後のデータは一つのレイクハウスに集中化されているので、これらを容易にダッシュボードに追加することができます。
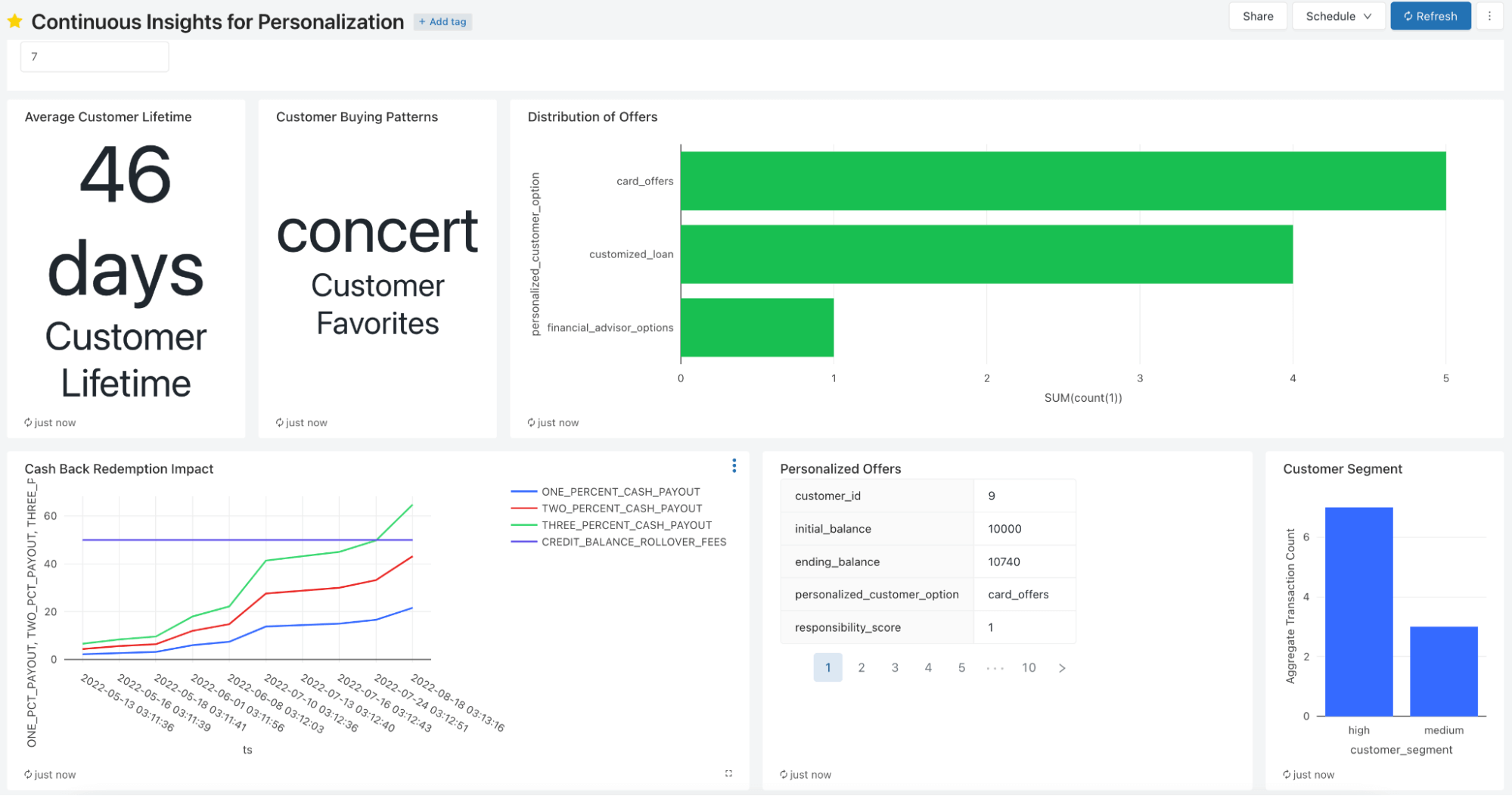
ストリーミングがどのようにレイクハウスにデータを流し込み、オファーの損失に対するアクション可能な洞察、顧客に対してパーソナライズされたオファーの機会、新製品に対する顧客の好みを導き出すDatabricks SQLのダッシュボード
まとめ
この記事では、金融サービスのさまざまなパーソナライゼーションのユースケースをサポートするために重要となるデータ取り込みプロセスの複数の側面にハイライトを当てました。より重要なこととして、Databircksはネイティブでニアリアルタイムのユースケースをサポートしており、新鮮な洞察と変更データを取り扱う抽象化API(Delta Live Tables)をPythonとSQLの両方ですぐに利用することができます。
銀行や保険プロバイダーがよりパーソナライズされた体験を提供するにつれて、モデルの開発をサポートすることは重要になりますが、さらに重要なこととして、インクリメンタルなデータ取り込みのための堅牢な基盤を構築することが挙げられます。最終的には、Databricksのレイクハウスプラットフォームは、より高いCSAT/NPSをもたらし、CAC/解約を引き下げ、より顧客が幸せにかつ利益を生み出せるようにするために、ストリーミングとAIドリブンのパーソナライゼーションを提供する比類なきものとなります。
この記事で適用したDelta Live Tablesの手法の詳細を知りたいのであれば、GitHubリポジトリにあるすべてのサンプルデータとコードをチェックしてみてください。