先日のイベントで発表があった件です。

マニュアルはこちら。
注意
利用できるようになるまでにはタイムラグがある場合があります。有効化の画面が表示されない場合には少々お待ちください。
ノートブック用サーバレスとは
これまではノートブックのPythonプログラムなどを実行するには、お客様VPC上のEC2をベースとしたAll Purpose(汎用)クラスターが必要でした(SQLのみならサーバレスSQLウェアハウスも使えますが)。このため、インスタンスの獲得、ランタイムのインストールなどで通常は起動に5分程度を要していました。これのサーバレス版がノートブック用サーバレス(Serverless compute for notebooks)です。即座に利用できる計算資源です。
サーバレスを利用する際の考慮事項
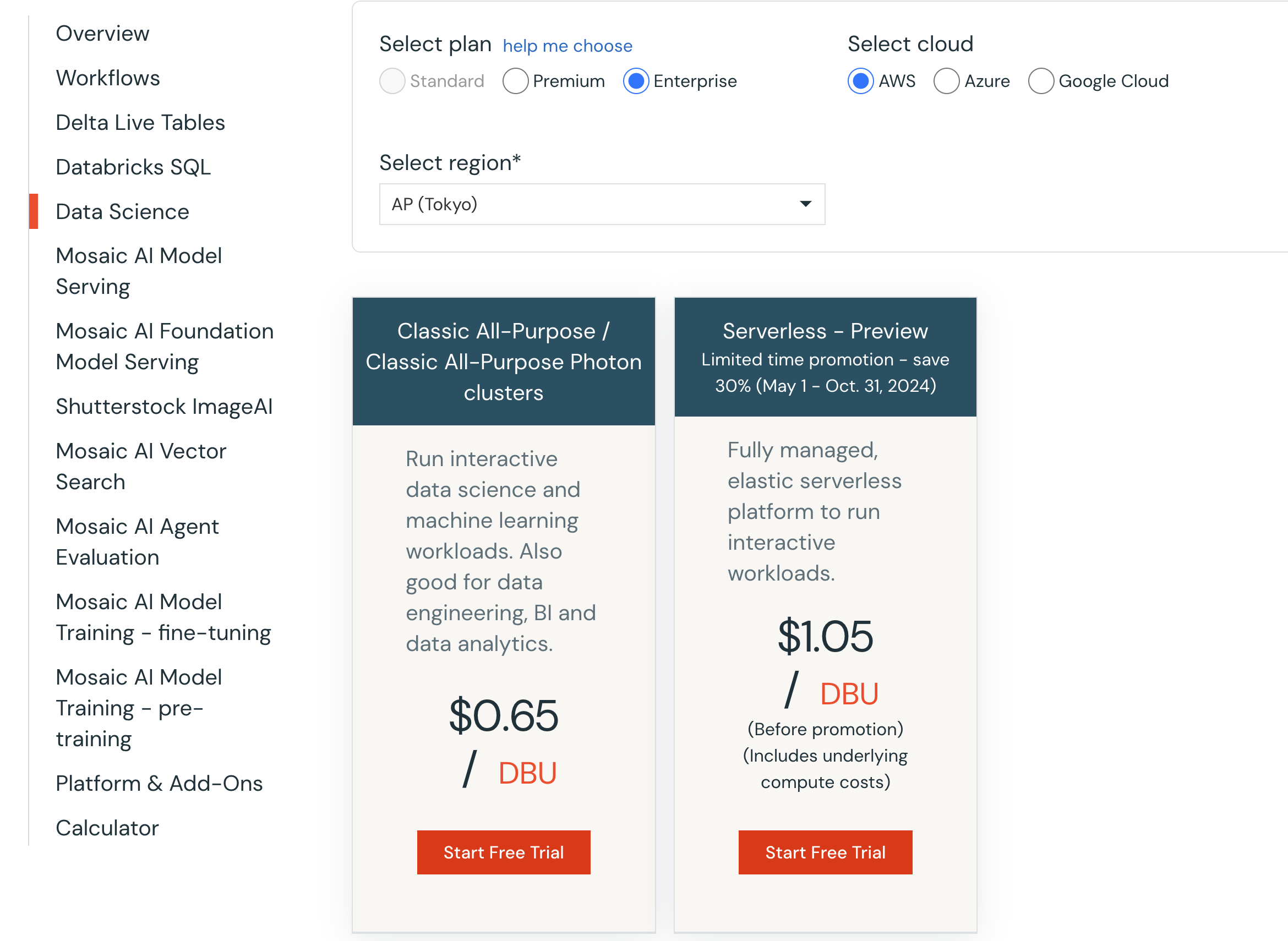
価格
2024/7/9朝時点でのPricingページのスクリーンショットです。詳細はDatabricksアカウントチームにお問い合わせください。
制限事項
こちらの制限事項をご確認ください。関連する箇所を翻訳します。
一般的な制限
-
ScalaとRは未サポート。
-
SQLを記述する際にはANSI SQLのみがサポート。
-
Spark RDD APIは未サポート。
-
Sparkコンテキスト(sc)、
spark.sparkContext、sqlContextは未サポート。 -
DBFSにアクセスはできません。
-
webターミナルは未サポート。
-
48時間以上クエリーを実行することはできません。
-
外部データソースに接続するにはUnity Catalogが必要です。クラウドストレージにアクセスするには外部ロケーションを使います。
-
データソースのサポートは、AVRO, BINARYFILE, CSV, DELTA, JSON, KAFKA, ORC, PARQUET, ORC, TEXT, XMLに限定されます。
-
ユーザー定義関数(UDF)はインターネットにアクセスできません。
-
個々の行の最大サイズが128MBを超えることはできません。
-
Spark UIを使うことはできません。代わりに、Sparkクエリーの情報を参照するためにはクエリープロファイルを使います。クエリープロファイルをご覧ください。
-
Databricksエンドポイントを使用するPythonクラウアントは、“CERTIFICATE_VERIFY_FAILED”のようなSSL検証エラーに遭遇するかもしれません。これらのエラーを回避するには、クライアントが
/etc/ssl/certs/ca-certificates.crtにあるCAファイルを信頼するように設定して下さい。例えば、サーバレスノートブックやジョブの最初に以下を記述します:import os; os.environ['SSL_CERT_FILE'] = '/etc/ssl/certs/ca-certificates.crt' -
ワークスペース横断のAPIリクエストはサポートされていません。
機械学習の制限
- 機械学習ランタイムやApache Spark MLlibはサポートされていません。
- GPUはサポートされていません。
ノートブックの制限
- ノートブックは設定不可の8GBメモリーにアクセスします。
- ノートブックスコープライブラリは開発セッション横断ではキャッシュされません。
- ユーザー間でノートブックを共有する際、TEMPテーブルやビューの共有はサポートされません。
- ノートブックにおけるデータフレームのオートコンプリートや変数エクスプローラはサポートされません。
コンピュート固有の制限
以下のコンピュート固有の機能はサポートされません:
- コンピュートポリシー
- コンピュートスコープinitスクリプト
- カスタムデータソースやSpark拡張を含むコンピュートスコープのライブラリ。代わりにノートブックスコープライブラリを使います。
- インスタンスプロファイルを含むコンピュートレベルのデータアクセス設定。このため、クラウドパスに基づくHMS経由や埋め込まれた資格情報がないDBFSマウント経由でのテーブルやファイルは動作しません。
- インスタンスプール
- コンピュートのイベントログ
- Apache Sparkコンピュート設定や環境変数
ウォークスルー
有効化
- アカウントコンソールにログインします。
- 設定の機能の有効化にアクセスします。
-
ワークフロー、ノートブック、Delta Liveテーブル向けのサーバーレスコンピュートをオンにします。

ノートブックのアタッチ
適当なノートブックを作成し、右上のクラスターセレクターを開くとサーバレスが表示されているので選択します。
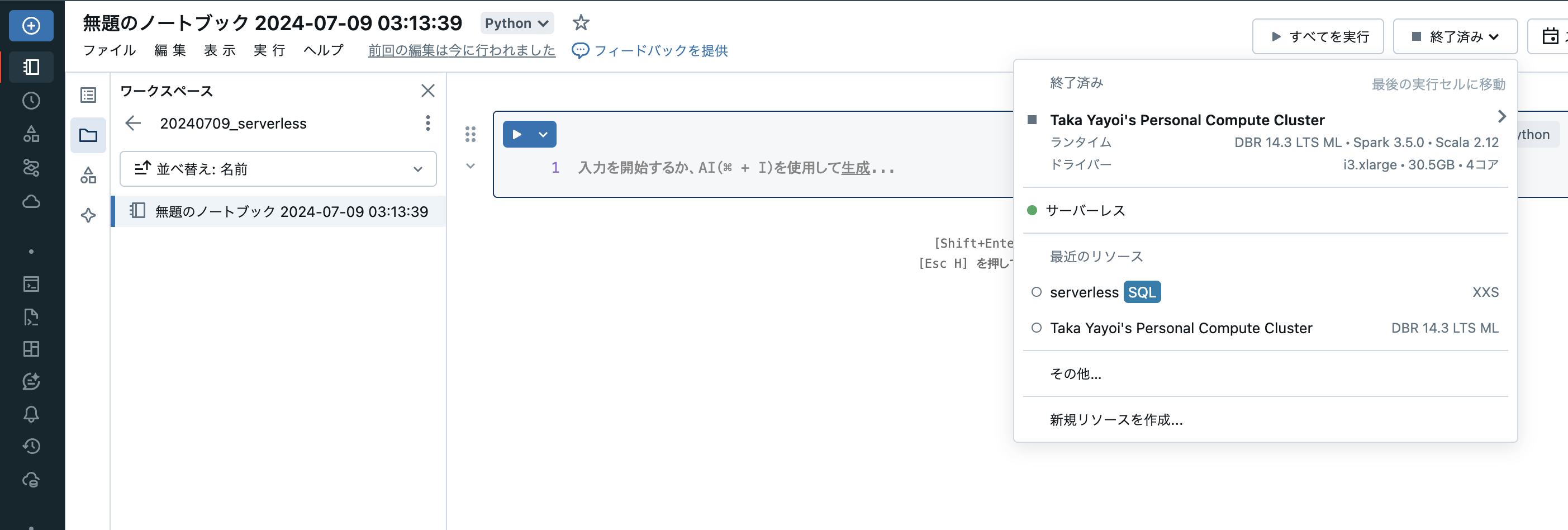
これで、サーバレスコンピュートを使ってプログラムを実行できるようになりました。
プログラムの実行
簡単なPySparkのコードを実行してみます。
df = spark.table("main.default.`日本語テーブル`")
display(df)
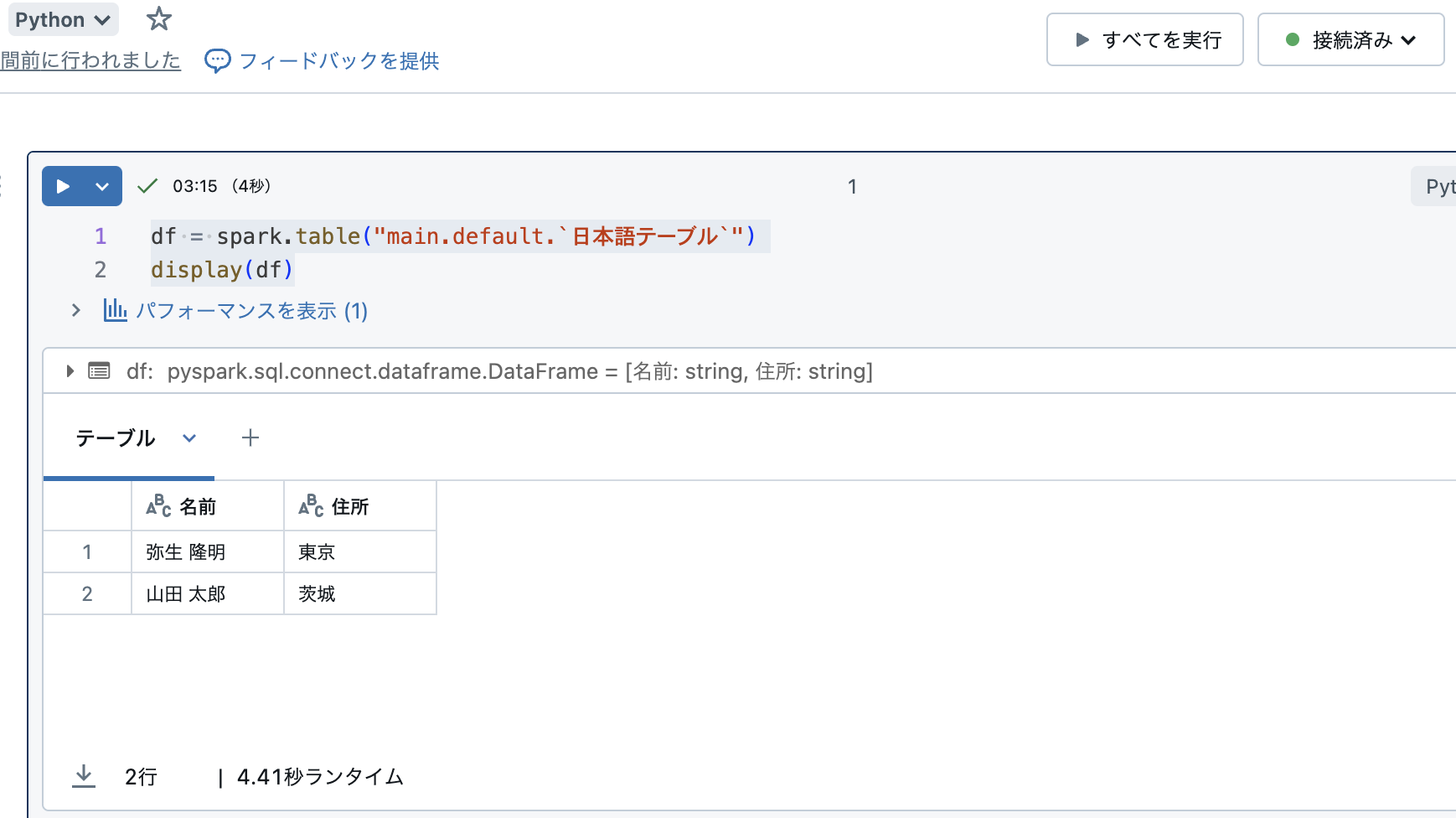
実行できました!
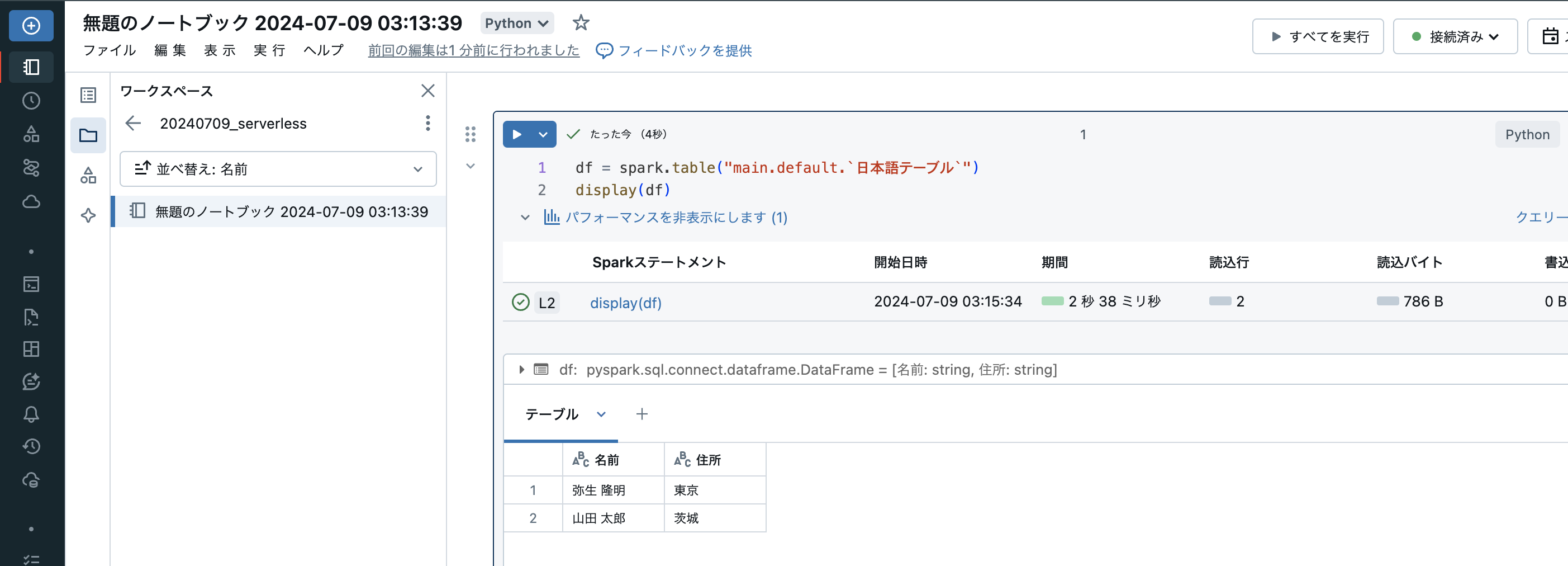
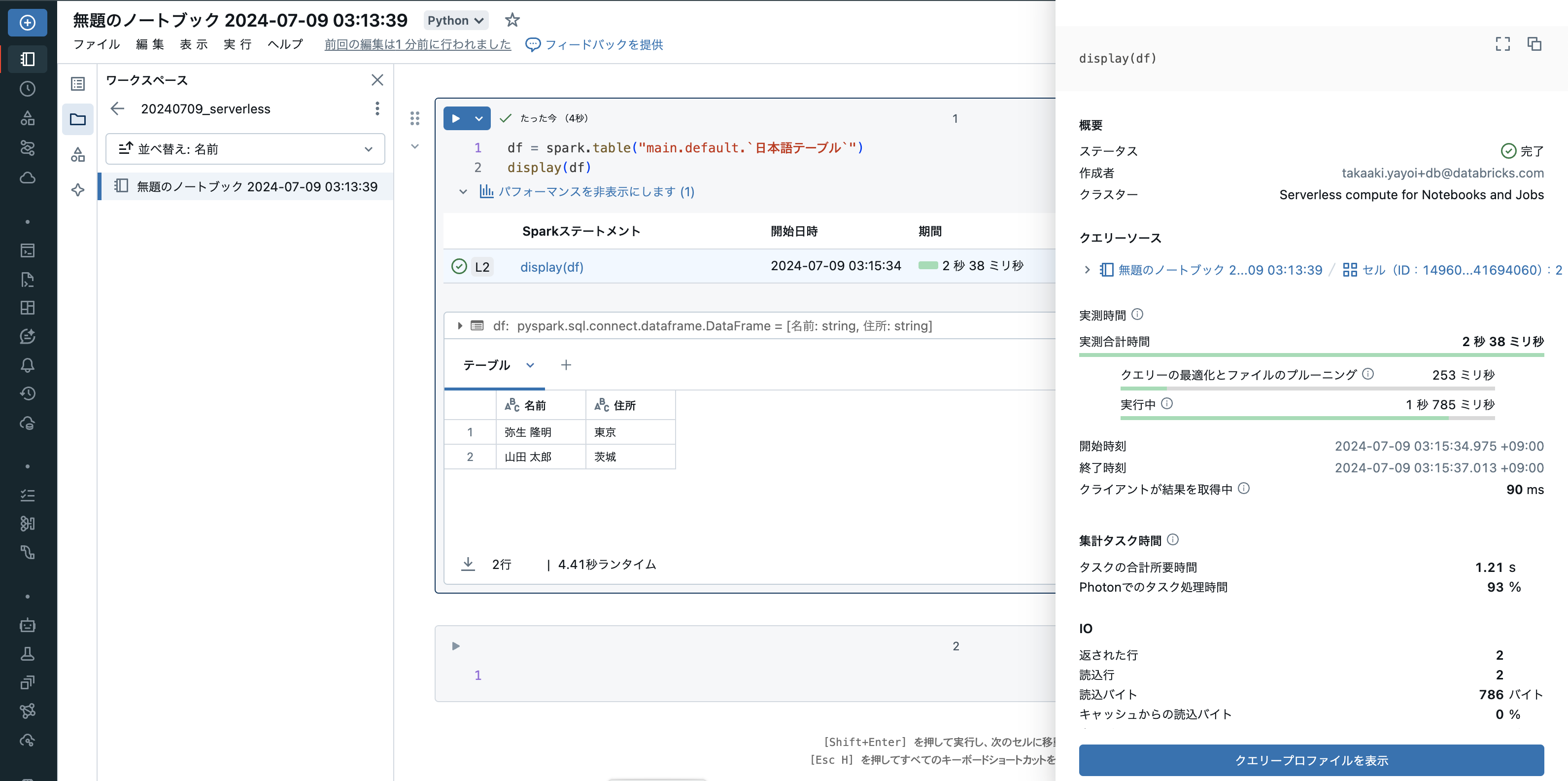
パフォーマンスを表示
パフォーマンスを表示をクリックすると、処理のパフォーマンスに関するメトリクスを表示することができます。パフォーマンス改善の取り組みで活用できます。
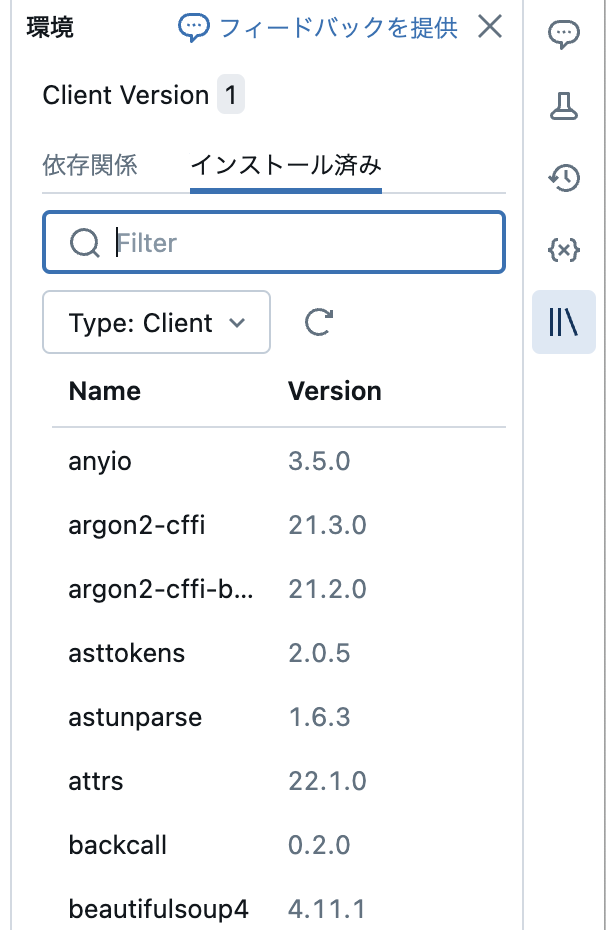
ライブラリのインストール
画面右の本棚マークで環境を設定することができます。ここからライブラリを追加することができます。
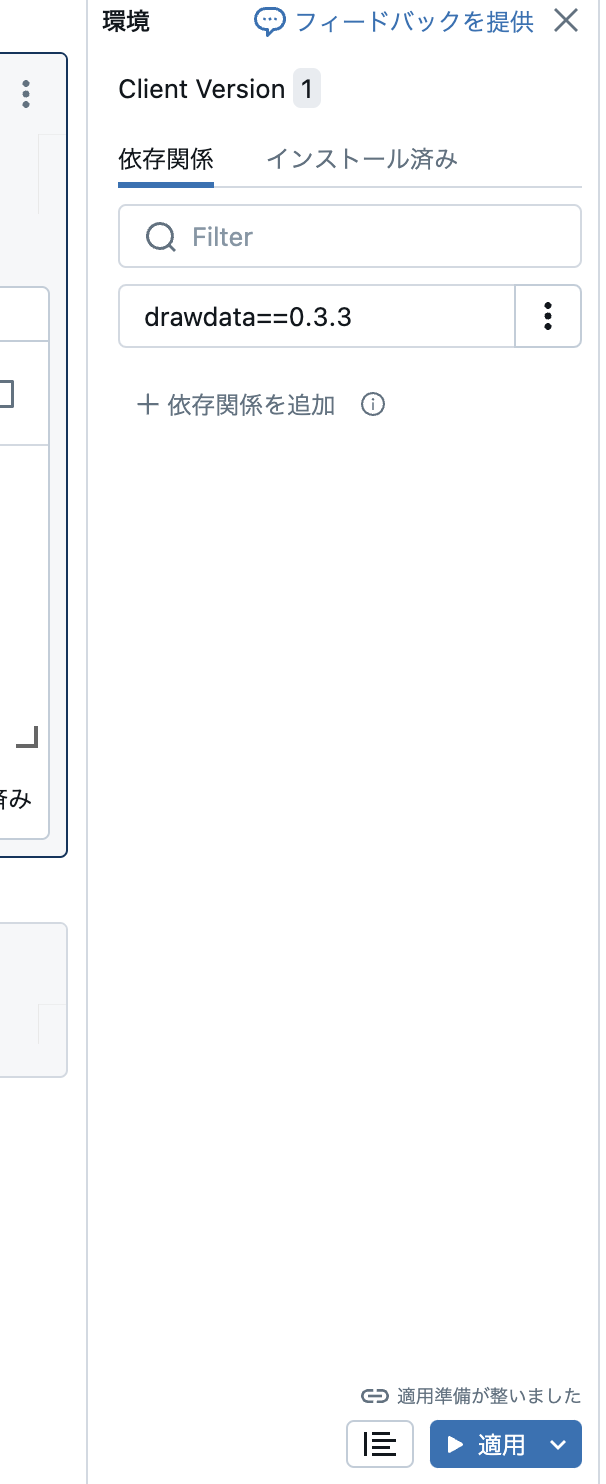
以下のように記述して、パネル下部の適用をクリックします。
drawdata==0.3.3
これでライブラリが追加されました。
用法・用量にご留意の上ご活用ください!