先日こちらのスライドを翻訳しました。
私は日常的にDatabricksノートブックを使っていますが、考えてみれば使い続けて約4年が経過しています。ですので、改めてここで振り返ってみたいと思います。
ノートブックとは?
こちらの記事を読むことをお勧めします。
- ノートブックは1つ以上のセルから構成されます。
- セルにPythonなどのコードを記述します。実行結果はセルの下に表示されます。
- コード以外にメモをノートブックに含めることができる。メモはMarkdown形式で記述します。
- コードは順不同で実行でき、何度も実行することもできます。これによって、開発時のデバッグが簡単になります。ただし、変数や関数を宣言している前のセルの実行を忘れないようにしてください。
Databricksノートブックとは?
上述のノートブックのDatabricksバージョンです。Databricksにはいろいろなインタフェースがありますが、Databricksノートブックが主要なインタフェースとなります。正面玄関です。
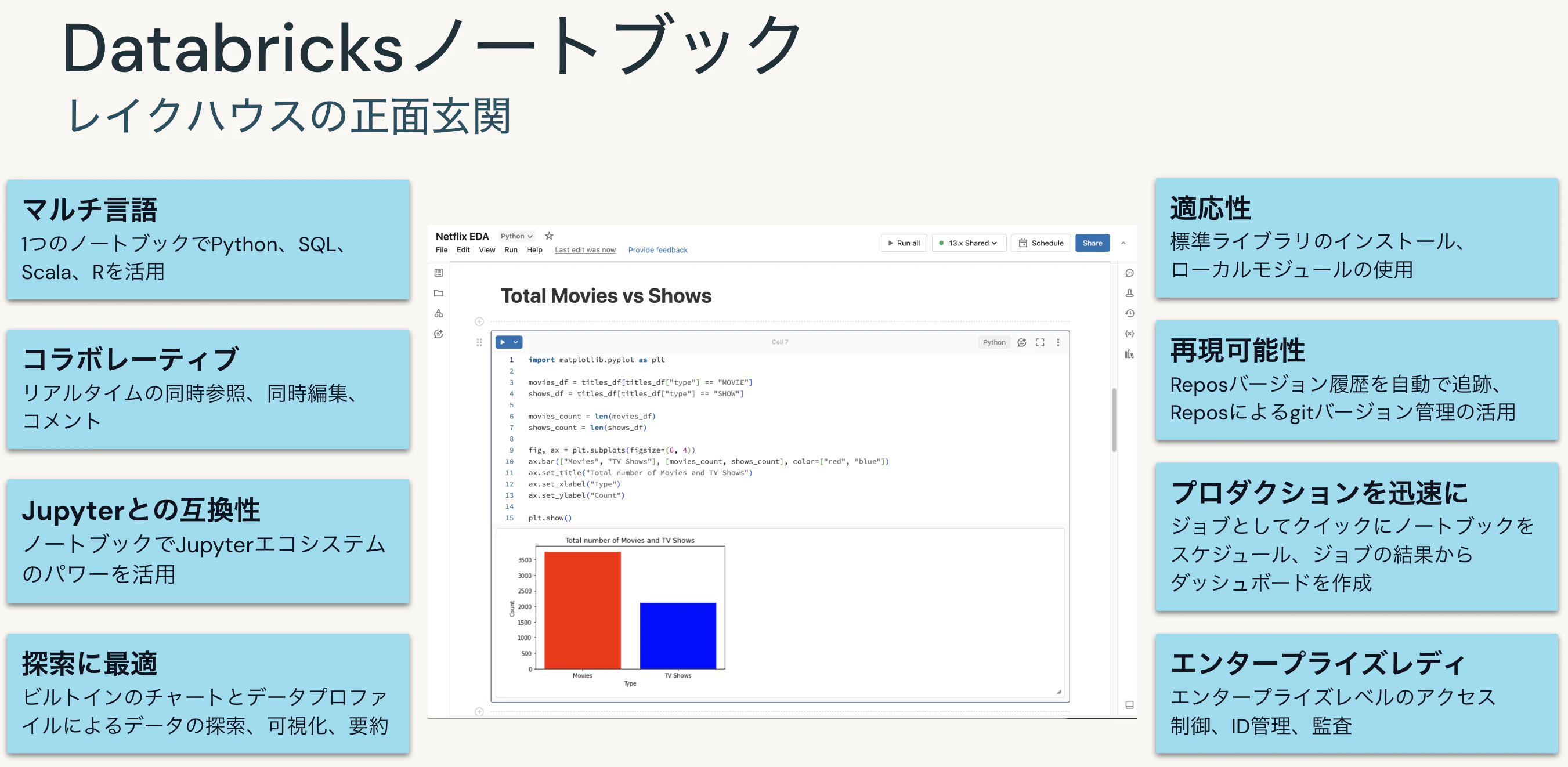
Jupyter Notebookとの違いは?
ノートブックの先駆けはJuypter Notebookですが、いろいろな側面で拡張がなされています。こちらに違いをまとめていますが、1年以上前のものなので改めて列挙します。
| Jupyter Notebook | Databricksノートブック | |
|---|---|---|
| 計算リソース | Juypter Notebookが稼働しているラップトップ、サーバーのリソースに制限を受けます。多くの場合、pandasの利用が前提となるのでメモリーの制約を受けます。 | クラウドプロバイダー(AWS/Azure/GCP)が提供するリソースを理論上無制限に活用できます。pandasに加えてSparkも活用できるので、並列処理による恩恵を享受することができます。 |
| コラボレーション | ラップトップで動作しているJupyter Notebookでの他のユーザーとのコラボレーションは限定的であり、JupyterHubを用いたとしてもその機能は限定的です。 | 複数ユーザーによるコラボレーションを前提としており、ノートブックやデータに対するアクセス制御やノートブックの同時参照、同時編集をサポートしています。最近になってコメントの通知もサポートされました。 |
| AIアシスタント | Jupyter AIが提供されているが個別セットアップが必要です。 | Databricksアシスタントがビルトイン。コードのオートコンプリートや自動修正などもサポートしています。 |
| 可視化 | matplotlibやseabornによるライブラリを用いて可視化のロジックを記述する必要があります。 | ライブラリによる可視化に加え、ノーコードでのビジュアライゼーションがビルトインされています。 |
| バージョン管理 | バージョン管理システムと連携する必要があります。 | ビルトインのバージョン管理機能に加え、Gitとの連携も可能です。 |
| マルチ言語対応 | カーネルレベルで他言語に対応する必要があります。 | 同一ノートブック内でPython、SQL、R、Scalaを使用できます。 |
| ガバナンス | ラップトップで動作しているJupyter Notebookでは、個人のデータサイエンティストによる管理しか行えず、企業全体でのデータやコード、機械学習モデルの管理を統一することができません。 | MLOpsを前提としており、データ、コード、機械学習モデルは全てUnity Catalogによって管理されます。 |
| 本格運用(Production) | ラップトップ上で実験的にPythonを実行するには適してますが、本格運用するためにジョブを組むには別のシステムが必要となります。 | Databricksにはワークフローの機能が搭載されているので、実験・テストを経たロジックを簡単に本格運用に移行することができます。また、さまざまなAPIを公開しているので、他のシステムとの連携も容易です。 |
Databricksノートブックのウォークスルー
上述の違いにフォーカスしながら、Databricksノートブックの基本的な使い方をウォークスルーします。
ウォークスルーするノートブックはこちらです。
Databricksノートブックのインタフェース
新規にノートブックを作成すると以下のような画面が表示されます。最初に慣れ親しんだほうが良い機能を太字で示しています。
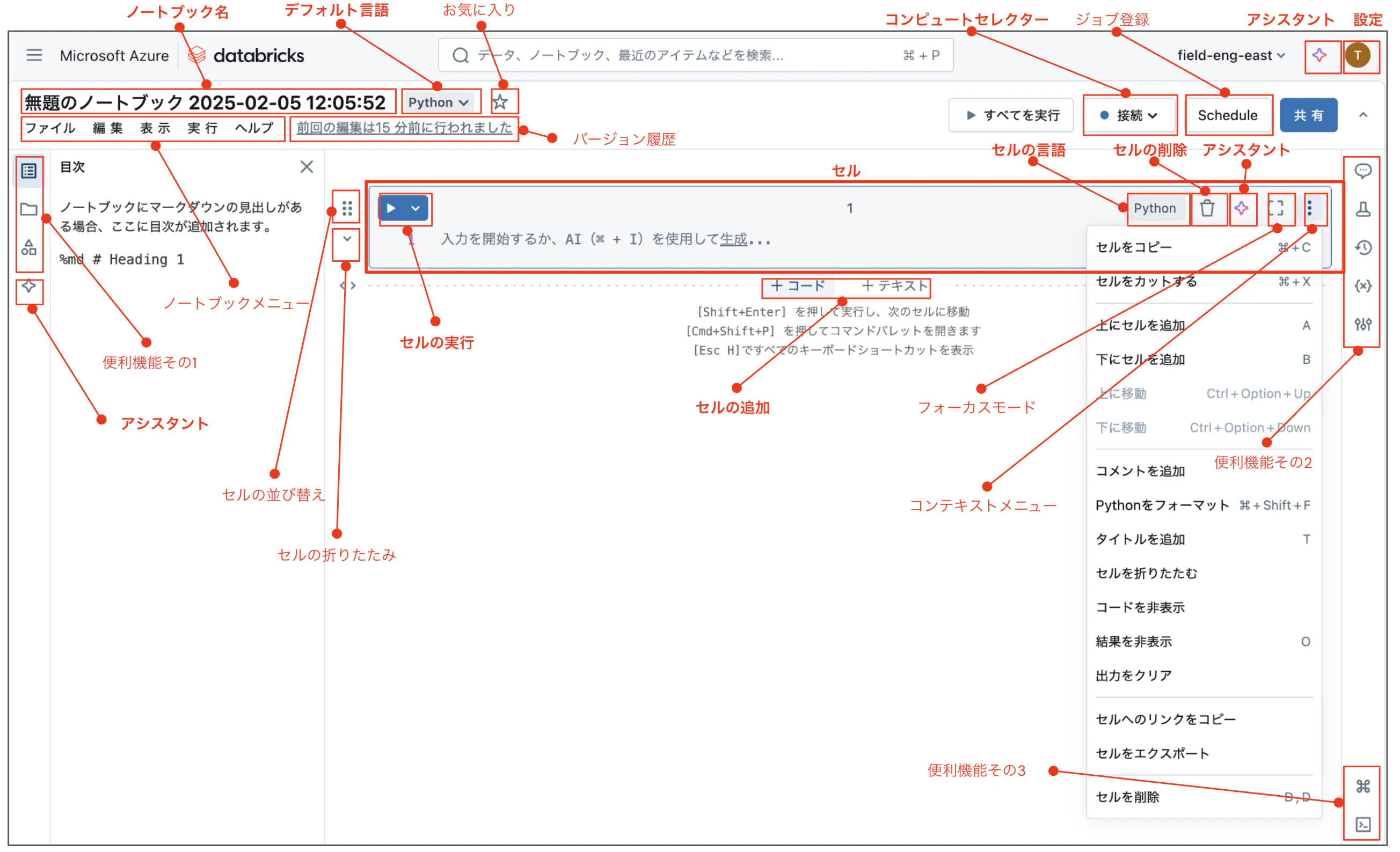
- ノートブック名: クリックで変更できます。
- デフォルト言語: ノートブックのデフォルト言語を選択します。Python、SQL、R、Scalaから選択できます。
- コンピュートセレクター: ノートブックのコード実行に必要な計算資源を選択します。
- アシスタント: Databricksアシスタントを呼び出します。
- 設定: ノートブックを含むDatabricksの様々な設定を行います。
- セル: ノートブックを構成するコードやマークダウンを記述するための箱です。
- セルの実行: 選択しているセル、あるいは前後のセルを実行します。
- セルの言語: ノートブックのデフォルト言語と異なる言語をセル単位で指定できます。後ほど詳細を説明します。
- セルの削除: セルを削除します。設定によっては確認ダイアログを非表示することもできます。
- セルの追加: 既存のセルの上下に新たなセルを追加します。このボタンはセルの境界にカーソルを移動すると表示されます。
クラスターへのアタッチ
画面の右上にあるコンピュートセレクターを使用して、このノートブックをクラスターにアタッチ(接続)します。

注意
クラスターのデプロイには数分かかる場合があります。リソースがデプロイされると、クラスター名の右側に緑色の丸が表示されます。クラスターの左側に灰色の円が表示されている場合は、クラスターを起動する手順に従う必要があります。
ノートブックの基本
ノートブックは、コードをセルごとに実行することができます。ノートブック内で複数の言語を混在させることができます。ユーザーはプロット、画像、マークダウンテキストを追加してコードを補強することができます。
このコースを通じて、ノートブックは学習ツールとして設計されています。ノートブックは、Databricksで本番コードとして簡単にデプロイできるだけでなく、データ探索、レポート作成、ダッシュボード作成のための強力なツールセットを提供します。
セルの実行
以下のいずれかのオプションを使用して、下のセルを実行します:
- CTRL+ENTER または CTRL+RETURN
- SHIFT+ENTER または SHIFT+RETURN でセルを実行し、次のセルに移動
-
▶︎ボタン、セルを実行、上記をすべて実行、以下をすべて実行 を使用

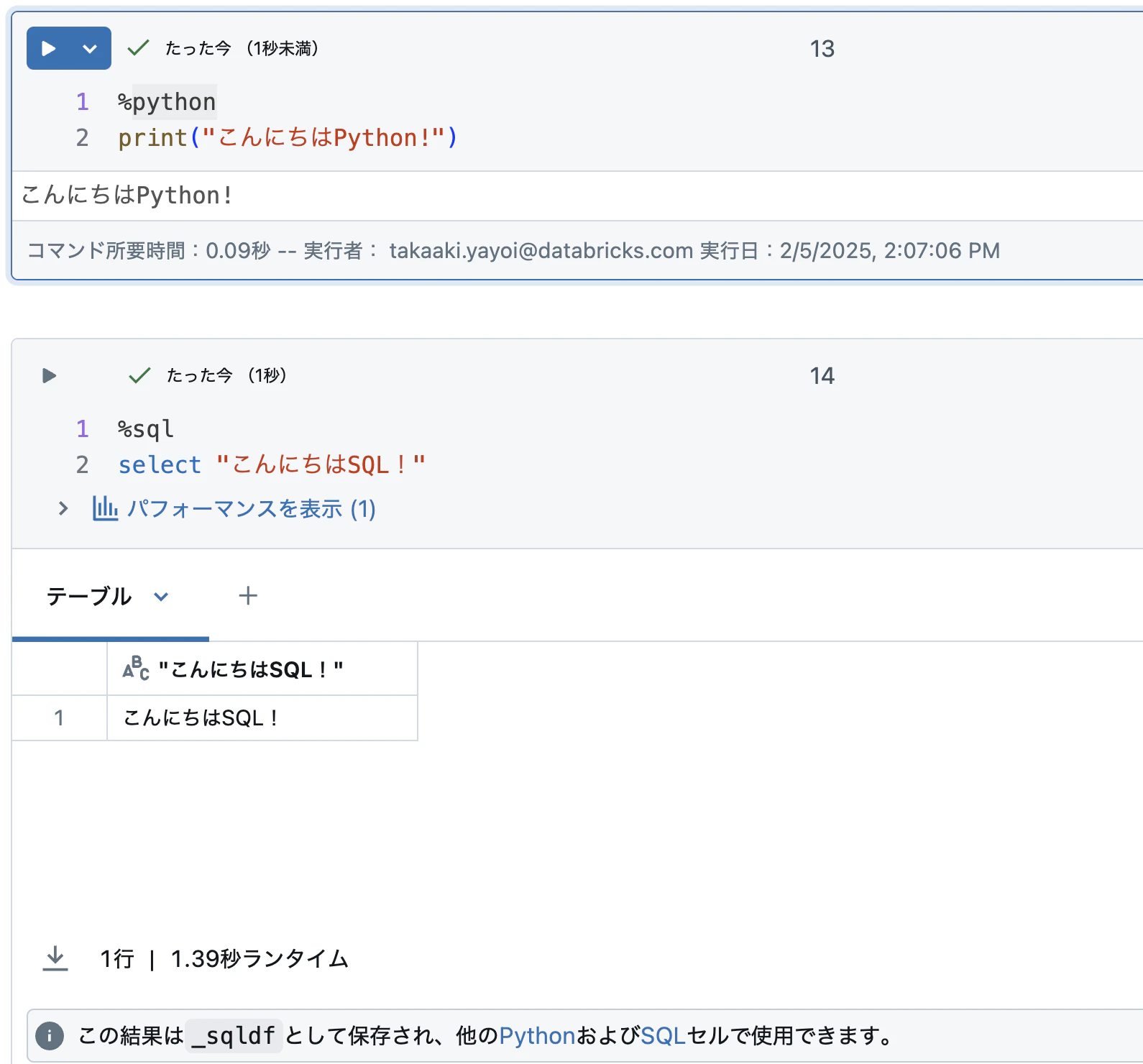
print("私はPythonを実行しています!")

注意
セルごとのコード実行は、セルが複数回または順不同で実行される可能性があることを意味します。明示的に指示されない限り、このコースのノートブックは上から下へ1つずつ実行することを前提としています。エラーが発生した場合は、トラブルシューティングを試みる前に、エラーが意図した学習のタイミングでなかったかどうかを確認するために、セルの前後のテキストを必ず読んでください。ほとんどのエラーは、ノートブックの以前のセルを実行し忘れたことであり、ノートブック全体を最初から再実行することで解決できます。
デフォルトのノートブック言語の設定
- 上のセルはPythonコマンドを実行します。なぜなら、現在のノートブックのデフォルト言語が
Pythonに設定されているからです。 - DatabricksノートブックはPython、SQL、Scala、Rをサポートしています。ノートブックを作成する際にデフォルト言語を選択できますが、これはいつでも変更可能です。
-
デフォルト言語はページ上部のノートブックタイトルの右側に表示されます。このコース全体で、SQLとPythonのノートブックを併用します。

このノートブックのデフォルト言語をSQLに変更します。
手順:
- 画面上部のノートブックタイトルの横にあるPythonをクリックします
- ドロップダウンリストからSQLを選択します
- 確認メッセージが表示されるので確認をクリックします

注意
デフォルト言語の変更後、このセルの上のセルには%pythonと表示されるはずです。これについては後ほど説明します。
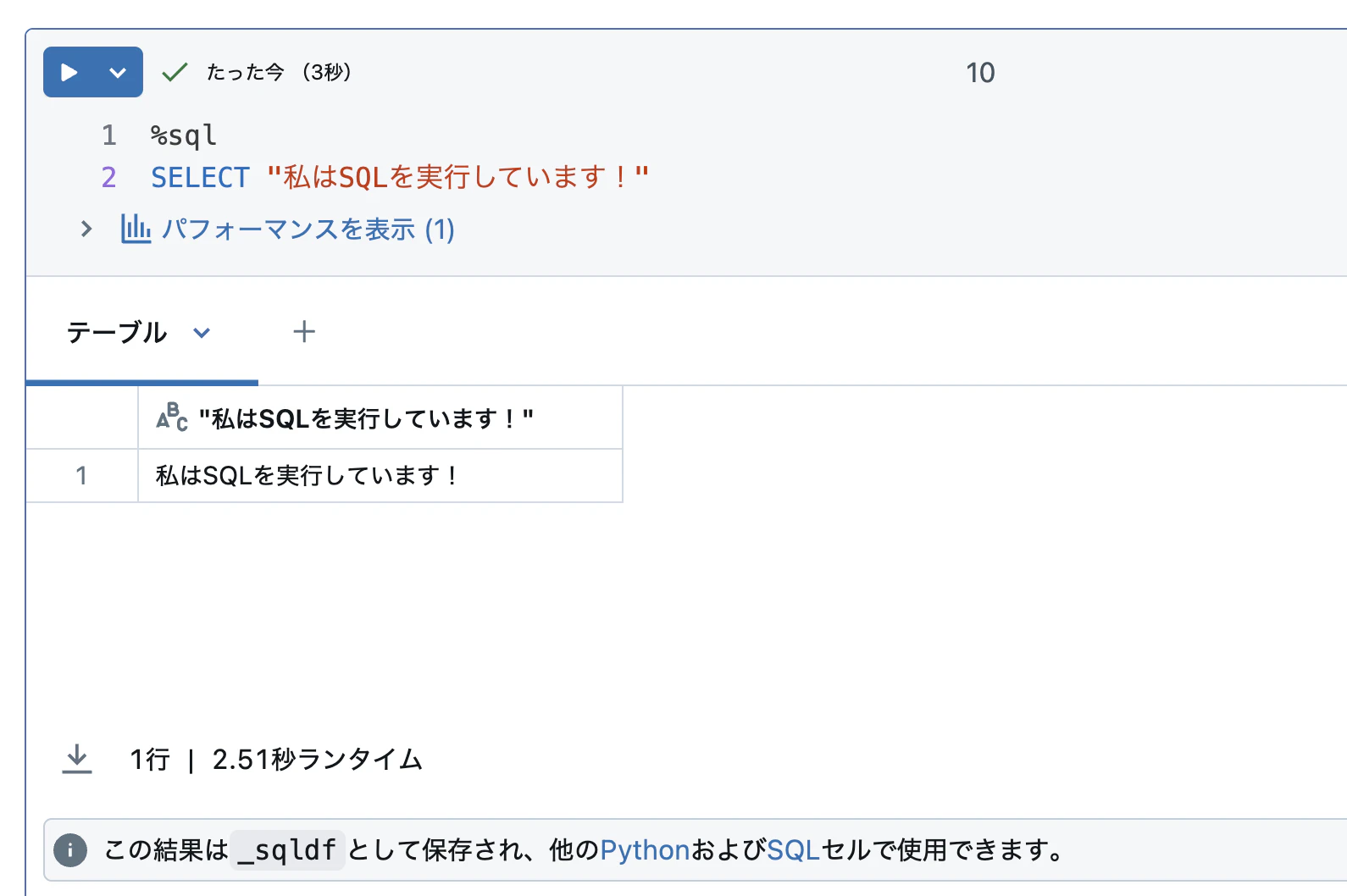
SQLセルの作成と実行
手順:
-
このセルをハイライトし、キーボードの B ボタンを押して下に新しいセルを作成します
-
以下のコードを下のセルにコピーして、セルを実行します
%sql SELECT "私はSQLを実行しています!"
注意
セルの追加、移動、削除には、GUIオプションやキーボードショートカットを含むさまざまな方法があります。詳細については、ドキュメントを参照してください。
マジックコマンド
- マジックコマンドはDatabricksノートブックに特有のものです
- これらは、同様のノートブック製品に見られるマジックコマンドと非常に似ています
- これらは、ノートブックの言語に関係なく同じ結果を提供する組み込みコマンドです
- セルの先頭に単一のパーセント(
%)記号があると、マジックコマンドであることがわかります- セルごとに1つのマジックコマンドしか使用できません
- マジックコマンドはセルの最初に配置する必要があります
言語マジックコマンド
言語マジックコマンドを使用すると、ノートブックのデフォルト以外の言語でコードを実行できます。このコースでは、次の言語マジックを使用します:
%python%sql
これ以外の言語マジックコマンドについてはこちらをご覧ください。
ノートブックで設定されているデフォルト言語のマジックコマンドを追加する必要はありません。
上でノートブックのデフォルト言語をPythonからSQLに変更したとき、既存のPythonセルには%pythonマジックコマンドが追加されました。
注意
ノートブックのデフォルト言語を頻繁に変更するのではなく、主に使用する言語をデフォルトとして使用し、他の言語でコードを実行する必要がある場合にのみ言語マジックコマンドを使用するべきです。
マークダウン
マジックコマンド %md を使用すると、セル内でマークダウンをレンダリングできます:
* このセルをダブルクリックして編集を開始します
* 編集を終了するには **`Esc`** を押します
# タイトル1
## タイトル2
### タイトル3
これは緊急放送システムのテストです。これはテストに過ぎません。
これは**太字**の単語を含むテキストです。
これは*斜体*の単語を含むテキストです。
これは順序付きリストです
1. 一度
1. 二度
1. 三度
これは順序なしリストです
* りんご
* 桃
* バナナ
リンク/埋め込みHTML: <a href="https://en.wikipedia.org/wiki/Markdown" target="_blank">Markdown - Wikipedia</a>
画像:

そしてもちろん、テーブル:
| 名前 | 値 |
|--------|------|
| Yi | 1 |
| Ali | 2 |
| Selina | 3 |
以下のようにレンダリングされます。

注意
画像を埋め込みたい場合、マークダウンセルに直接画像をドラッグ&ドロップすることで埋め込むこともできます。詳細はこちらをご覧ください。
display()
セルからSQLクエリを実行すると、結果は常にレンダリングされた表形式で表示されます。
Pythonセルから表形式のデータが返された場合、同じタイプのプレビューを得るために display を呼び出すことができます。
ここでは、Unity Catalogで管理されるテーブルから読み込んだデータを display でラップします。
%python
df = spark.table("samples.nyctaxi.trips")
display(df)

display() コマンドには以下の機能と制限があります:
- 結果のプレビューは10,000レコードに制限
- 結果データをCSVとしてダウンロードするボタンを提供
- 結果データをビルトイン機能で可視化
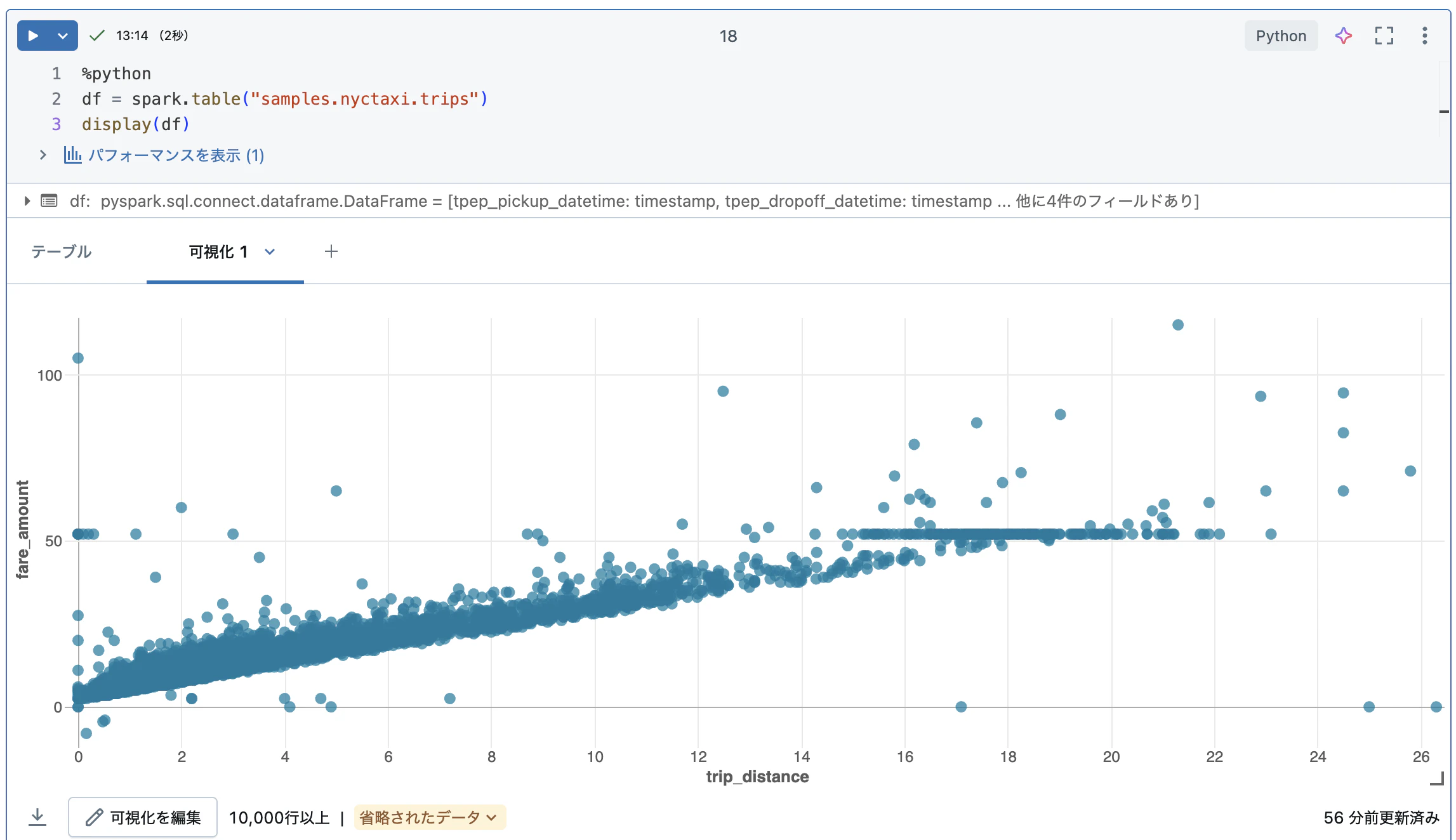
データの可視化
上で表示したデータを可視化してみます。
手順:
- 上のデータのテーブルの右にある + > 可視化 をクリックします。

- 以下のようにグラフの設定を行い保存します。

このように、ノーコードでデータを可視化することができます。
アシスタントの活用
Databricksのプラットフォームに組み込まれているDatabricksアシスタントは、様々なシーンであなたを支援します。困った時には、色々な場所にある アイコンをクリックしてアシスタントを呼び出しましょう。
アイコンをクリックしてアシスタントを呼び出しましょう。
コードを書いてもらう
手順:
-
下にコードブロックを追加します。
-
セルの言語がSQLになっているので、Pythonに変更します。
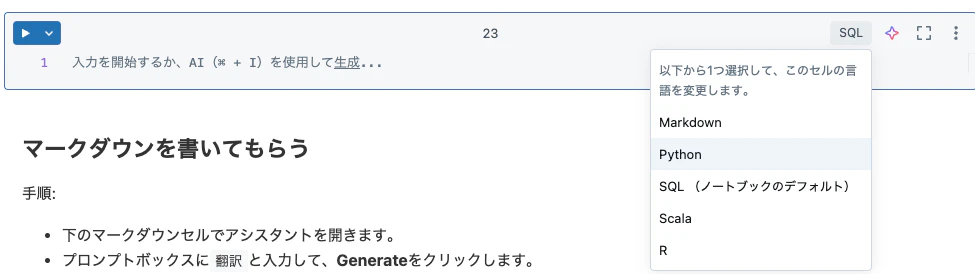
-
追加したセル右上の
アイコンをクリックしてアシスタントを開きます。 -
表示されるプロンプトボックスに
helloを表示と入力し、Generateをクリックします。

-
指示に従ったPythonコードが表示されるはずです。Acceptで確定します。

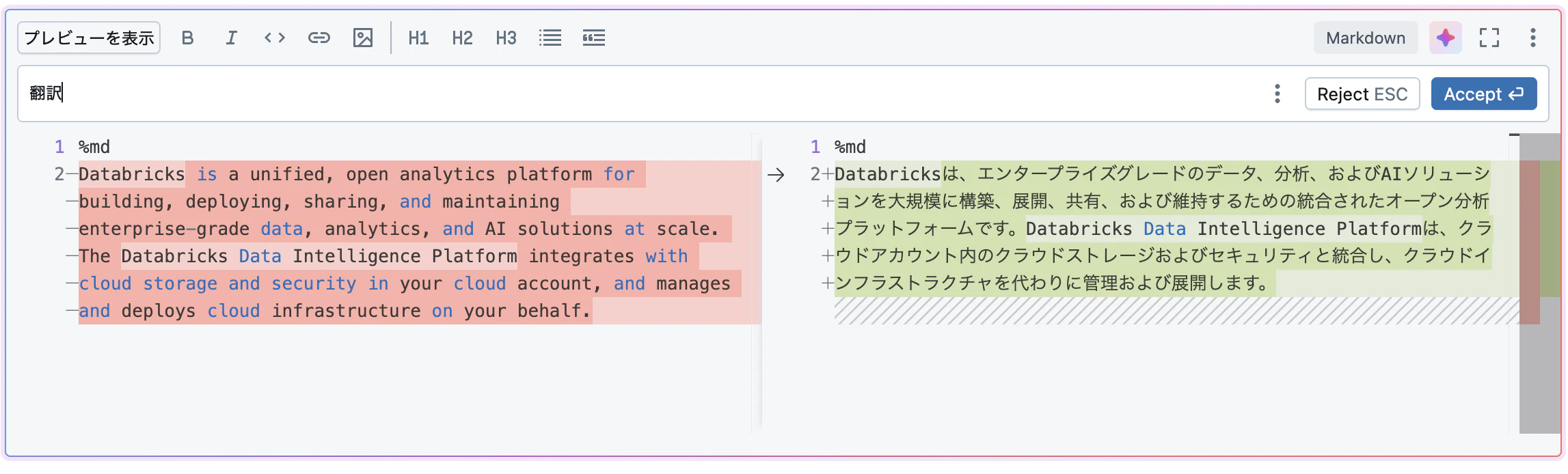
マークダウンを書いてもらう
手順:
- 下のマークダウンセルでアシスタントを開きます。
- プロンプトボックスに
翻訳と入力して、Generateをクリックします。
ノートブックでのコラボレーション
Databricksで取り扱う資産(ノートブック、テーブル、ファイルなど)はすべてアクセスコントロールがされています。適切なアクセス権を設定することで、チーム間で資産を安全に共有することができます。
ノートブックのデフォルトのアクセス権は以下のようになっています:
- ノートブックの作成者と管理者はノートブックに対するフルアクセスを持ちます。
- それ以外のアクセス権は明示的に許可する必要があります。
アクセス権を設定するにはノートブック右上の共有ボタンを押します。誰にどのような権限を与えるかを設定してアクセス権を設定します。


アクセスが許可されたノートブックでは、同時参照や同時編集、コメントを介したやり取りを行うことができます。
ノートブックのダウンロード
個々のノートブックやノートブックのコレクションをダウンロードするためのオプションがいくつかあります。ここでは、このノートブックをダウンロードする手順を説明します。
手順:
- ノートブックの上部にあるノートブックメニューにある ファイル オプションをクリックします。
- 表示されるメニューから エクスポート にカーソルを合わせ、ソースファイル を選択します。
ノートブックは個人のラップトップにダウンロードされます。現在のノートブック名で名前が付けられ、デフォルト言語のファイル拡張子が付きます。このノートブックは任意のファイルエディタで開いてDatabricksノートブックの生の内容を見ることができます。
これらのソースファイルは任意のDatabricksワークスペースにアップロードできます。
まとめ
このように、Databricksノートブックはノーコードでの可視化やAIアシスタントなど、開発や分析の生産性を高める様々な機能を提供しています。基本的な機能に慣れ親しんだら、以下のドキュメントを参考に実践を通じてDatabricksノートブックを最大限に活用できるようになることをお勧めします。
その他のリソース
Databricksのプラットフォームとノートブックの様々な機能をさらに学ぶには、ドキュメントを探索することをお勧めします。
Azure
- Azure Databricks とは
- Azure Databricks を始める
- ワークスペースを移動する
- Databricks ノートブックの概要
- コンピューティング
- データを検出する
- データに対するクエリの実行
- Databricks ノートブックでの視覚化
- Python 開発者向けの Azure Databricks
- Databricks アシスタントを使用する
- Databricks ノートブックのエクスポートとインポート
- Databricks レイクハウスにデータを取り込む
- Databricks ノートブックを使用して共同作業する
AWS
- Databricks の使用を開始する
- ワークスペース内を移動する
- Databricksノートブック入門
- コンピュート
- データの検出
- データのクエリー
- Databricks ノートブックにおけるビジュアライゼーション
- Python開発者のためのDatabricks
- Databricks Assistant からコーディングのヘルプを受ける
- ノートブック Databricks エクスポートとインポート
- Databricks レイクハウスにデータを取り込む
- Databricks ノートブックを使用した共同作業 | Databricks on AWS