本書は著者が手動で翻訳したものであり内容の正確性を保証するものではありません。正確な内容に関しては原文を参照ください。
Twelve LabsのEmbed APIによって、セマンティック動画検索やコンテンツ推薦や動画RAGシステムに至る高度な動画理解ユースケースを強化するマルチモーダルのエンべディングを手に入れることができます。
Twelve Labsでは、動画におけるビジュアルな表現、ボディランゲージ、発話、全体的な文脈間の関係性を捕捉する文脈的なベクトル表現を生成することができます。Databricks Mosaic AIのVector Searchは、高次元のベクトルのインデックスやクエリーのための堅牢かつスケーラブルなインフラストラクチャを提供します。この記事では、動画AIアプリケーションにおける新たな可能性を解放する、これら補完し合う技術の組み合わせを通じてガイドを行います。
なぜTwelve Labs + Databricks Mosaic AIなのか?
Twelve Labs Embed APIとDatabricks Mosaic AI Vector Searchをインテグレーションすることで、効率的な大規模動画データセットの処理や正確なマルチモーダルのコンテンツ表現のような、動画AIにおける主要な課題に対応します。このインテグレーションは、高度な動画アプリケーションにおける開発時間や時間やリソースの要件を削減し、膨大な動画ライブラリに対する複雑なクエリーを可能とし、全体的なワークフローの効率性を改善します。
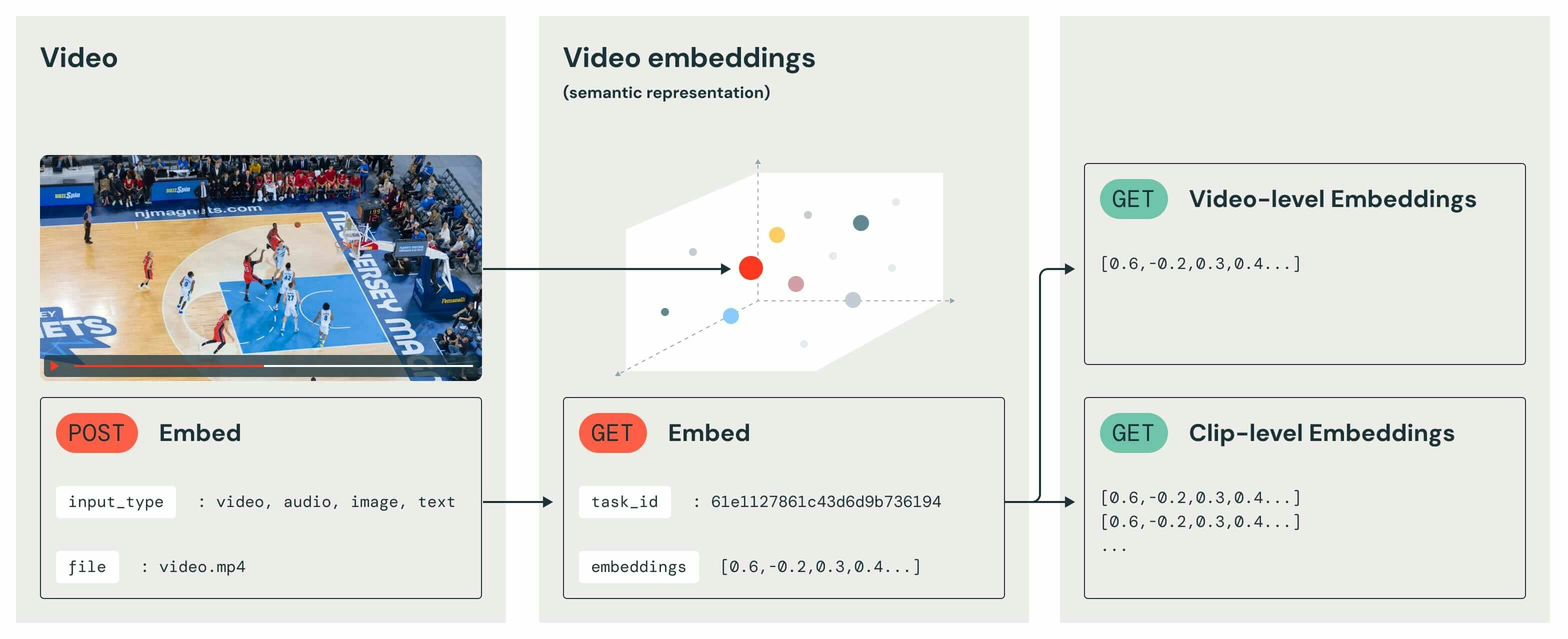
マルチモーダルデータを取り扱う統合アプローチは特筆すべきものです。テキスト、画像、動画分析のための個別のモデルを調整するのではなく、ユーザーは動画コンテンツのエッセンスを全体としてとらえる単一かつ一貫性のある表現を用いて作業することができます。これは、デプロイメントのアーキテクチャをシンプルにするだけでなく、洗練されたコンテンツ推薦システムから高度な動画検索エンジン、自動コンテンツもでレーションツールに至るよりニュアンスを理解し、コンテキストアウェアなアプリケーションを実現できることになります。
さらに、このインテグレーションはDatabricksエコシステムの能力を拡張し、既存のデータパイプラインや機械学習ワークフローに、動画理解をシームレスに組み込めるようになります。企業においてリアルタイム動画分析を開発したり、大規模なコンテンツ分類システムを構築したり、生成AIにおける新たなアプリケーションを探索していたとしても、この複合ソリューションはパワフルな基盤を提供します。これは、動画AIで可能なことの境界を押し上げ、メディアエンターテイメントやセキュリティ、ヘルスケアに渡る業界におけるイノベーションや問題解決における新たな道筋を開きます。
Twelve Labs Embed APIの理解
Twelve Labs Embed APIは、マルチモーダル技術、特に動画コンテンツに特化して設計された大きな進歩を表しています。従来のフレームごとのアプローチや、モダリティごとの個別のモデルとは異なり、このAPIは動画のビジュアル表現、ボディランゲージ、発話、全体的なコンテキストの複雑な相互作用を捕捉する子文脈的なベクトル表現を生成します。
Embed APIは、動画データを取り扱うAIエンジニアにとって特に強力ないくつかの主要な機能を提供します。まず、動画に存在するすべてのモダリティに対する柔軟性を提供し、テキストのみ、画像のみのモデルを個別に使う必要がなくなります。次に、動作、アクション、時間的情報を考慮する動画ネイティブなアプローチを採用しており、動画コンテンツのより正確で時間的に一貫性のある解釈を確実なものとします。最後に、すべてのモダリティのエンべディングを統合する統合ベクトル空間を作成し、動画コンテンツに対してより全体的な理解を促進します。
AIエンジニアにとっては、このEmbed APIは動画理解タスクにおける新たな可能性の扉を開くことになります。これによって、より洗練されたコンテンツ分析、セマンティック検索能力の改善、強化された推薦システムが可能となります。このAPIが瑣末な合図や、異なるモダリティ間のインタラクションの時間変化を捕捉する能力は、感情認識、コンテキストアウェアなコンテンツモデレーション、高度な動画検索システムのように、動画コンテンツをきめ細かく理解する必要があるアプリケーションにとっては特に重要なものとなります。
前提条件
Twelve LabsのEmbed APIとDatabricks Mosaic AI Vector Searchをインテグレーションする前に、以下の前提条件を満たしている必要があります:
- ワークスペースを作成、管理する権限を持つDatabricksアカウント。(フリートライアルへのサインアップは https://databricks.com/jp/try-databricks から)
- Pythonプログラミングと基本的なデータサイエンスのコンセプトに慣れ親しんでいること。
- Twelve LabsのAPIキー。(サインアップは https://api.twelvelabs.io/ から)
- ベクトルエンべディングと類似検索のコンセプトの基本的な理解。
- (オプション)AWSのDatabricksを使っている場合にはAWSアカウント。AzureやGoogle CloudでDatabricksを使っている場合には不要です。
ステップ1: 環境のセットアップ
始めるには、Databricks環境をセットアップし、必要なライブラリをインストールします:
-
新規Databricksワークスペースの作成
- https://accounts.cloud.databricks.com/ からDatabricksアカウントにログイン
- 新規ワークスペースを作成するには、Databricksドキュメントで説明されているステップに従います: https://docs.databricks.com/ja/getting-started/index.html
-
新規クラスターを作成するか既存クラスターに接続
ほとんどすべてのMLクラスターはこのアプリケーションで動作します。最適なコストパフォーマンスを求めている方のために以下の設定を提供しています。- Computeタブで「Create compute」をクリック
- 「Single node」とランタイム: 14.3 LTS ML non-GPUを選択
- クラスターポリシーとアクセスモードはデフォルトのままに
- ノードタイプで「r6i.xlarge」を選択
- これは、ディスカウントなしでAWSのコストが$0.252/hr、Databricksのコストが1.02 DBU/hrでありながらも、メモリー容量を最大にします
- テストした中では最も高速なものの一つでもありました
- 他のオプションはすべてデフォルトのままに
- 下にある「Create compute」をクリックし、ワークスペースに戻ります
-
Databricksワークスペースで新規ノートブックを作成
- ワークスペースで「Create」をクリックし「Notebook」を選択
- ノートブックに名前をつけます(「TwelveLabs_MosaicAI_VectorSearch_Integration」など)
- デフォルト言語としてPythonを選択
-
Twelve LabsとMosaic AI Vector Search SDKのインストール
ノートブックの最初のセルで以下のPythonコマンドを実行します:%pip install twelvelabs databricks-vectorsearch -
Twelve Labs認証のセットアップ
次のセルで、以下のPythonコードを追加します:from twelvelabs import TwelveLabs import os # Retrieve the API key from Databricks secrets (recommended) # You'll need to set up the secret scope and add your API key first TWELVE_LABS_API_KEY = dbutils.secrets.get(scope="your-scope", key="twelvelabs-api-key") if TWELVE_LABS_API_KEY is None: raise ValueError("TWELVE_LABS_API_KEY environment variable is not set") # Initialize the Twelve Labs client twelvelabs_client = TwelveLabs(api_key=TWELVE_LABS_API_KEY)
注意:
- セキュリティ強化のために、APIキーをハードコードしたり環境変数を用いるのではなく、Databricksシークレットを使うことをお勧めします。
- Embed APIは現時点ではプライベートベータですが、こちらのフォームに記入するだけでアクセスをリクエストすることができます。数時間以内に、確認のメールを受け取り、Embed APIを使い始めることができます。
ステップ2: マルチモーダルエンべディングの生成
Twelve Labs Embed APIを用いてマルチモーダルのエンべディングを生成するために提供されているgenerate_embedding関数を使います。この関数は、DatabricksにおけるSparkデータフレームと効率的に動作するPandasユーザー定義関数(UDF)として設計されています。これは、エンべディングの作成タスク、進捗の監視、結果の取得のプロセスをカプセル化しています。
次に、文字列入力として動画のURLを受け取り、Twelve Labs Embed APIを呼び出すラッパーの起動を行い、array<float>を返却するprocess_url関数を作成します。
以下に実装方法と使用方法を示します。
1. UDFの定義
from pyspark.sql.functions import pandas_udf
from pyspark.sql.types import ArrayType, FloatType
from twelvelabs.models.embed import EmbeddingsTask
import pandas as pd
@pandas_udf(ArrayType(FloatType()))
def get_video_embeddings(urls: pd.Series) -> pd.Series:
def generate_embedding(video_url):
twelvelabs_client = TwelveLabs(api_key=TWELVE_LABS_API_KEY)
task = twelvelabs_client.embed.task.create(
engine_name="Marengo-retrieval-2.6",
video_url=video_url
)
task.wait_for_done()
task_result = twelvelabs_client.embed.task.retrieve(task.id)
embeddings = []
for v in task_result.video_embeddings:
embeddings.append({
'embedding': v.embedding.float,
'start_offset_sec': v.start_offset_sec,
'end_offset_sec': v.end_offset_sec,
'embedding_scope': v.embedding_scope
})
return embeddings
def process_url(url):
embeddings = generate_embedding(url)
return embeddings[0]['embedding'] if embeddings else None
return urls.apply(process_url)
2. 動画URLを持つサンプルデータフレームの作成
video_urls = [
"https://example.com/video1.mp4",
"https://example.com/video2.mp4",
"https://example.com/video3.mp4"
]
df = spark.createDataFrame([(url,) for url in video_urls], ["video_url"])
3. エンべディングを生成するためにUDFを適用
df_with_embeddings = df.withColumn("embedding", get_video_embeddings(df.video_url))
4. 結果の表示
df_with_embeddings.show(truncate=False)
このプロセスは、ビジュアル、音声、テキスト情報を含むビデオコンテンツのマルチモーダルのエッセンスを捕捉するデータフレームとして、それぞれの動画URLに対応するマルチモーダルのエンべディングを生成します。
大規模動画データセットにおけるエンべディング生成は計算資源を大量に必要とし、時間を浪費する場合があることに注意してください。プロダクション規模のアプリケーションにおいては、バッチあるいは分散処理戦略を実装することを検討しましょう。さらに、潜在的なAPI失敗やネットワーク問題に対応するように、適切なエラーハンドリングやロギングを実装するようにしてください。
ステップ3: 動画エンべディングのためのDeltaテーブルの作成
それでは、動画のメタデータとTwelve Labs Embed APIによって生成されたエンべディングを格納するソースDeltaテーブルを作成しましょう。このテーブルは、Databricks Mosaic AI Vector Searchのベクトル検索インデックスの基盤として動作します。
はじめに、動画URLとメタデータを持つソースデータフレームを作成します:
from pyspark.sql import Row
# Create a list of sample video URLs and metadata
video_data = [
Row(url='http://commondatastorage.googleapis.com/gtv-videos-bucket/sample/ElephantsDream.mp4', title='Elephant Dream'),
Row(url='http://commondatastorage.googleapis.com/gtv-videos-bucket/sample/Sintel.mp4', title='Sintel'),
Row(url='http://commondatastorage.googleapis.com/gtv-videos-bucket/sample/BigBuckBunny.mp4', title='Big Buck Bunny')
]
# Create a DataFrame from the list
source_df = spark.createDataFrame(video_data)
source_df.show()
次に、SQLを用いてDeltaテーブルのスキーマを宣言します:
%sql
CREATE TABLE IF NOT EXISTS videos_source_embeddings (
id BIGINT GENERATED BY DEFAULT AS IDENTITY,
url STRING,
title STRING,
embedding ARRAY<FLOAT>
) TBLPROPERTIES (delta.enableChangeDataFeed = true);
ベクトル検索インデックスの作成と維持において重要となるチェンジデータフィードをテーブルで有効化していることに注意してください。
次に、上で定義したget_video_embeddings関数を用いて動画のエンべディングを生成します。
embeddings_df = source_df.withColumn("embedding", get_video_embeddings("url"))
このステップは動画の数と長さに応じてある程度の時間を要します。エンべディングが作成されたら、Deltaテーブルにデータを書き込むことができます。
embeddings_df.write.mode("append").saveAsTable("videos_source_embeddings")
最後に、エンべディングを含むデータフレームを表示することでデータを検証します:
display(embeddings_df)
このステップでは、Vector Searchの機能の堅牢な基盤を作成しています。Deltaテーブルは、ベクトル検索インデックスと自動的に同期されるので、動画データセットに対するすべての更新や追加処理が検索結果に反映されるようになります。
覚えておくべきいくつかのキーポイントです:
- idカラムは自動生成されるので、それぞれの動画に対するユニークなIDを提供します。
- embeddingカラムには、Vector Searchのインデックスの維持に重要な、Twelve Labs Embed APIによって生成されたそれぞれの動画の高次元ベクトル表現が格納されます。
- チェンジデータフィードを有効化することで、Databricksはテーブルの変更を効率的に追跡でき、これはVector Searchインデックスを最新の状態に保つためには重要なものとなります。
ステップ4: Mosaic AI Vector Searchの設定
このステップでは、動画のエンべディングを取り扱うためにDatabricks Mosaic AI Vector Searchをセットアップします。これには、Vector Searchエンドポイントとあなたのvideos_source_embeddings Deltaテーブルと自動で同期されるDelta Sync Indexの作成が含まれます。
はじめに、Vector Searchエンドポイントを作成します:
from databricks.vector_search.client import VectorSearchClient
# Initialize the Vector Search client and name the endpoint
mosaic_client = VectorSearchClient()
endpoint_name = "twelve_labs_video_endpoint"
# Delete the existing endpoint if it exists
try:
mosaic_client.delete_endpoint(endpoint_name)
print(f"Deleted existing endpoint: {endpoint_name}")
except Exception:
pass # Ignore non-existing endpoints
# Create the new endpoint
endpoint = mosaic_client.create_endpoint(
name=endpoint_name,
endpoint_type="STANDARD"
)
このコードは、新規のVector Searchエンドポイントを作成、あるいは既存のものを同じ名前で置き換えます。このエンドポイントはVector Searchオペレーションにおけるアクセスポイントとして動作します。
次に、あなたのvideos_source_embeddings Deltaテーブルと自動で同期されるDelta Sync Indexを作成します:
# Define the source table name and index name
source_table_name = "twelvelabs.default.videos_source_embeddings"
index_name = "twelvelabs.default.video_embeddings_index"
index = mosaic_client.create_delta_sync_index(
endpoint_name="twelve_labs_video_endpoint",
source_table_name=source_table_name,
index_name=index_name,
primary_key="id",
embedding_dimension=1024,
embedding_vector_column="embedding",
pipeline_type="TRIGGERED"
)
print(f"Created index: {index.name}")
このコードは、あなたのソースDeltaテーブルにリンクするDelta Sync Indexを作成します。(あなたのVector Searchの結果を常に最新の状態に保つために)ソーステーブルになされた変更を数秒以内にインデックスに更新したい場合には、pipeline_type="CONTINUOUS"を設定します。
インデックスが作成され、適切に同期されていることを検証するには、動機をトリガーするために以下のコードを使います:
# Check the status of the index; this may take some time
index_status = mosaic_client.get_index(
endpoint_name="twelve_labs_video_endpoint",
index_name="twelvelabs.default.video_embeddings_index"
)
print(f"Index status: {index_status}")
# Manually trigger the index sync
try:
index.sync()
print("Index sync triggered successfully.")
except Exception as e:
print(f"Error triggering index sync: {str(e)}")
このコードによって、インデックスのステータスをチェックし、必要であれば手動で同期処理を起動することができます。プロダクション環境では、ソースDeltaテーブルに対する変更に基づいて自動で同期を行うパイプラインをセットアップしたいと思うかもしれません。
覚えておくべきキーポイントです:
- Vector Searchエンドポイントは、ベクトル検索オペレーションのアクセスポイントとして動作します。
- Delta Sync IndexはソースDeltaテーブルと同期し続けるので、最新の検索結果を保証します。
- embedding_dimensionはTwelve Labs' Embed APIによって生成されたエンべディングの次元(1024)とマッチすべきです。
- primary_keyは我々のソーステーブルのユニークなIDと対応する"id"に設定します。
embedding_vector_columnは、動画エンべディングを含む我々のソーステーブルのカラム名とマッチする"embedding"に設定します。
ステップ5: 類似検索の実装
次のステップは、設定したMosaic AI Vector Search index とTwelve Labs Embed APIを用いた類似検索機能の実装です。これによって、マルチモーダルエンべディングのパワーを活用することで、指定されたテキストクエリーに類似した動画を検索できるようになります。
はじめに、Twelve Labs Embed APIを用いて、テキストクエリーのエンべディングを取得する関数を定義します:
def get_text_embedding(text_query):
# Twelve Labs Embed API supports text-to-embedding
text_embedding = twelvelabs_client.embed.create(
engine_name="Marengo-retrieval-2.6",
text=text_query,
text_truncate="start"
)
return text_embedding.text_embedding.float
この関数は、テキストのクエリーを受け取り、動画エンべディングと同じモデルを用いたエンべディングを返却し、ベクトル空間の互換性を担保します。
次に、類似検索関数を実装します:
def similarity_search(query_text, num_results=5):
# Initialize the Vector Search client and get the query embedding
mosaic_client = VectorSearchClient()
query_embedding = get_text_embedding(query_text)
print(f"Query embedding generated: {len(query_embedding)} dimensions")
# Perform the similarity search
results = index.similarity_search(
query_vector=query_embedding,
num_results=num_results,
columns=["id", "url", "title"]
)
return results
この関数は、テキストのクエリーと返却する結果の数を受け取ります。そして、クエリーのエンべディングを生成し、類似した動画を特定するためにMosaic AI Vector Searchのインデックスを活用します。
検索結果をパース、表示するために、以下のヘルパー関数を活用します:
def parse_search_results(raw_results):
try:
data_array = raw_results['result']['data_array']
columns = [col['name'] for col in raw_results['manifest']['columns']]
return [dict(zip(columns, row)) for row in data_array]
except KeyError:
print("Unexpected result format:", raw_results)
return []
それでは、全てをまとめ上げてサンプルの検索を行います:
# Example usage
query = "A dragon"
raw_results = similarity_search(query)
# Parse and print the search results
search_results = parse_search_results(raw_results)
if search_results:
print(f"Top {len(search_results)} videos similar to the query: '{query}'")
for i, result in enumerate(search_results, 1):
print(f"{i}. Title: {result.get('title', 'N/A')}, URL: {result.get('url', 'N/A')}, Similarity Score: {result.get('score', 'N/A')}")
else:
print("No valid search results returned.")
このコードではクエリー"A dragon"に関連する動画を特定するためにTwelve Labsの類似検索関数をどのように使うのかをデモンストレーションしています。そして、ユーザーフレンドリーなフォーマットにパースして表示しています。
覚えておくべきキーポイントです:
- get_text_embedding関数は、動画のエンべディングと同じTwelve Labsのモデルを使用しており、互換性を担保しています。
- similarity_search関数は、類似動画を検索するためにテキストからエンべディングの変換とVector Searchを組み合わせています。
- ネットワーク問題やAPIの変更が検索プロセスに影響を与えることがあるため、エラーハンドリングが重要となります。
- parse_search_results関数は、生のAPIレスポンスをより使いやすいフォーマットに変換する助けになります。
- 返却件数をコントロールするために、similarity_search関数のnum_resultsパラメータを調整することができます。
この実装によって、あなたの動画データセットに対するパワフルなセマンティック検索を実現することができます。ユーザーは、Twelve Labs Embed APIによって生成されたリッチなマルチモーダルエンべディングを活用することで、自然言語で適切な動画を検索できるようになりました。
ステップ6: 動画推薦システムの構築
これで、Twelve Labs Embed APIとDatabricks Mosaic AI Vector Searchによって生成されたマルチモーダルエンべディングを用いた基本的な動画推薦システムを作成する準備が整いました。このシステムは、エンべディングの類似性に基づいて指定された動画に類似する動画を提案します。
はじめに、シンプルな推薦関数を実装します:
def get_video_recommendations(video_id, num_recommendations=5):
# Initialize the Vector Search client
mosaic_client = VectorSearchClient()
# First, retrieve the embedding for the given video_id
source_df = spark.table("videos_source_embeddings")
video_embedding = source_df.filter(f"id = {video_id}").select("embedding").first()
if not video_embedding:
print(f"No video found with id: {video_id}")
return []
# Perform similarity search using the video's embedding
try:
results = index.similarity_search(
query_vector=video_embedding["embedding"],
num_results=num_recommendations + 1, # +1 to account for the input video
columns=["id", "url", "title"]
)
# Parse the results
recommendations = parse_search_results(results)
# Remove the input video from recommendations if present
recommendations = [r for r in recommendations if r.get('id') != video_id]
return recommendations[:num_recommendations]
except Exception as e:
print(f"Error during recommendation: {e}")
return []
# Helper function to display recommendations
def display_recommendations(recommendations):
if recommendations:
print(f"Top {len(recommendations)} recommended videos:")
for i, video in enumerate(recommendations, 1):
print(f"{i}. Title: {video.get('title', 'N/A')}")
print(f" URL: {video.get('url', 'N/A')}")
print(f" Similarity Score: {video.get('score', 'N/A')}")
print()
else:
print("No recommendations found.")
# Example usage
video_id = 1 # Assuming this is a valid video ID in your dataset
recommendations = get_video_recommendations(video_id)
display_recommendations(recommendations)
この実装では以下を行なっています:
- get_video_recommendations関数は、動画のIDと返却する推薦の件数を受け取ります。
- 与えられた動画のエンべディングをソースDeltaテーブルから取得します。
- エンべディングを用いて、最も類似した動画を検索するための類似検索を実行します。
- この関数は、同じ動画を推薦しないように、結果から(存在する場合)入力動画を除外します。
- display_recommendationsヘルパー関数は、推薦内容をユーザーフレンドリーな形式にフォーマットして表示します。
この推薦システムを使うには:
- あなたの動画が適切なエンべディングと共にvideos_source_embeddingsテーブルに格納されていることを確認します。
- あなたのデータセットにおける適切な動画IDを用いて、get_video_recommendations関数を呼び出します。
- 関数は類似性に基づいた推薦動画リストを返却して表示します。
この基本的な推薦システムでは、コンテンツベースの動画推薦においてどのようにマルチモーダルのエンべディングを活用するのかをデモンストレーションしています。いくつかの方法で拡張、改善することができます:
- パーソナライズされた推薦nのためにユーザーの嗜好や視聴履歴を組み込む。
- 変化のある推薦を行えるように、多様性のメカニズムを実装する。
- 動画のメタデータ(ジャンル、長さ、アップロード日など)に対するフィルターを追加する。
- パフォーマンス改善のために、頻繁にリクエストされる推薦をキャッシュする機構を実装する。
推薦の品質は、あなたのデータセットのサイズや多様性、Twelve Labs Embed APIによって生成されるエンべディングの精度に依存することに注意してください。システムにさらに動画を追加することで、推薦はより適切かつ多様性を持つものとなります。
このインテグレーションを次のレベルに
インデックスの更新と同期
あなたの動画ライブラリが成長、進化していくと、ベクトル検索インデックスを最新に保つことが重要となります。Mosaic AI Vector Searchは、ソースDeltaテーブルとのシームレスな同期処理を提供し、推薦や検索結果が常に最新のデータを反映するようにします。
インデックスの更新と同期に関するキーとなる検討事項です:
- インクリメンタルな更新: あなたのインデックスにおける変更や新規レコードのみを効率的に更新するように、Delta Lakeのチェンジデータフィードを活用します。
- 同期のスケジュール: インデックスの鮮度を保つために、Databricksワークフローオーケストレーションツールを用いた定期的な同期ジョブを実装します。
- リアルタイムの更新: 時間の制約が厳しいアプリケーションにおいては、Databricks Mosaic AIのストリーミング機能を用いたニアリアルタイムのインデックス更新を検討します。
- バージョン管理: インデックスの複数のバージョンを保持するDelta Lakeのタイムトラベルの機能を活用することで、必要な場合に簡単にロールバックできるようになります。
- 同期ステータスの監視: 同期の成功を追跡し、更新プロセスにおけるすべての問題をクイックに特定するためのロギングやアラートの機構を実装します。
これらのテクニックをマスターすることで、Twelve Labsの動画エンべディングが常に現在の状態であり、高度な検索や推薦のユースケースに活用できるようになることを保証できるようになります。
パフォーマンスの最適化とスケーリング
動画分析パイプラインが成長すると、継続的なあなたのソリューションのパフォーマンスの最適化やスケーリングが重要となります。Databricksの分散処理能力とTwelve Labsの効率的なエンべディング生成を組み合わせることで、大規模動画処理タスクに対するための堅牢な基盤を提供します。
あなたのソリューションの最適化とスケーリングに関してこれらの戦略を検討しましょう:
- 分散処理: 複数ノードでエンべディング生成やインデックス作成のタスクを並列化するために、DatabricksのSparkクラスターを活用します。
- キャッシュ戦略: APIコールを削減し、レスポンス時間を改善するために、頻繁にアクセスされるエンべディングをインテリジェントにキャッシュする機構を実装します。
- バッチ処理: 大規模動画ライブラリにおいては、オフピーク時間にエンベディングを生成し、インデックスを更新するバッチ処理ワークフローを実装します。
- クエリーの最適化: num_resultsのようなパラメータを調整することでVector Searchのクエリーをファインチューンし、効率的なフィルタリングテクニックを実装します。
- インデックスのパーティショニング: 大規模データセットにおいては、クエリーのパフォーマンスを改善し、よりきめ細かい更新を可能にするインデックスのパーティショニング戦略を探索します。
- オートスケーリング: ワークロードの需要に基づいて計算リソースを動的に調整する、Databricksのオートスケーリングの機能を活用します。
- エッジコンピューティング: レーテンシーの要件が厳しいアプリケーションにおいては、データソースに近いところにモデルの軽量バージョンをデプロイすることを検討します。
これらの最適化テクニックを実装することで、成長する動画ライブラリや増加するユーザーの需要に備えつつも、高いパフォーマンスとコスト効率性を維持することができます。
監視と分析
あなたの動画理解パイプラインの継続的な盛況を確実なものにするには、堅牢な監視と分析の実装が重要となります。Databricksでは、システムパフォーマンス、ユーザーエンゲージメント、ビジネスインパクトを追跡するためのパワフルなツールを提供しています。
監視と分析においてキーとなるフォーカスエリアです:
- パフォーマンスメトリクス: クエリーのレーテンシー、エンべディング生成時間、インデックス更新期間のようなキーとなるパフォーマンスインジケーターを追跡します。
- 利用方法の分析: ユーザーの挙動に対する洞察を得るために、ユーザーのインタラクション、人気の検索クエリー、頻繁に推薦される動画を監視します。
- 品質の評価: 自動で取得されるメトリクスとユーザーのフィードバックの両方を用いて、検索結果や推薦の適切を評価するためのフィードバックループを実装します。
- リソースの使用状況: コストやパフォーマンスを最適化するために、計算リソースの使用量、APIコールのボリューム、ストレージの消費に目を向けます。
- エラー追跡: パイプラインの問題をクイックに特定、解決するために包括的なエラーロギングやアラートをセットアップします。
- A/Bテスト: さまざまなエンべディングモデル、検索アルゴリズム、推薦戦略をテストするために、Databricksの実験機能を活用します。
- ビジネスインパクト分析: ユーザーエンゲージメント、コンテンツの消費、コンバージョン率のようなキーとなるビジネスメトリクスと動画理解の能力の相関を見ます。
- コンプライアンス監視: あなたの動画処理パイプラインが、データプライバシー規制やコンテンツモデレーションのガイドラインに準拠することを確実にします。
包括的な監視、分析戦略を実装することで、あなたの動画理解パイプラインのパフォーマンスやインパクトに対する重要な洞察を得ることができます。このデータドリブンのアプローチによって継続的な改善が可能となり、Twelve LabsとDatabricksのデータインテリジェンスプラットフォームで高度な動画理解能力をインテグレーションすることによる価値をデモンストレーションできる助けとなります。
まとめ
Twelve LabsとDatabricks Mosaic AIは、高度な動画理解や分析のための堅牢なフレームワークを提供します。このインテグレーションでは、マルチモーダルのエンベディングと効率的なVector Searchの機能を活用しており、開発者は洗練された動画検索、推薦、分析システムを構築することが可能となります。
このチュートリアルでは、環境のセットアップ、エンべディングの生成、Vector Searchの設定、基本的な検索および推薦機能の実装における技術的なステップをウォークスルーしました。また、ソリューションのスケーリング、最適化、監視においてキーとなる検討事項にも取り組みました。
動画コンテンツにおけるランドスケープの成長において、このメディアから正確な洞察を抽出する能力は重要なものとなります。このインテグレーションによって、開発者は複雑な動画理解タスクに対応するツールで準備を整えることができます。皆様には、技術的な能力を探索し、高度なユースケースで実験し、動画理解技術を前進させているAIエンジニアのコミュニティに貢献いただけると幸いです。
その他のリソース
このインテグレーションを探索し、活用するには、以下のリソースを検討してください:
- Twelve Labs Documentation
- Databricks Vector Searchのドキュメント
- Databricks Community Forums
- Twelve Labs Discord Community