AWSとAzureのDatabricks SQLにおけるシンプル、高速、効率的な取り込みと変換処理の正式提供
マテリアライズドビュー(MV)とストリーミングテーブル(ST)が、AWSとAzureのDatabricks SQLでの正式提供を発表できることを嬉しく思っています。ストリーミングテーブルは、数行のSQLでクラウドストレージやメッセージバスのようなソースからのシンプルかつインクリメンタルな取り込み処理を提供します。マテリアライズドビューは、クエリーの結果を事前に計算し、インクリメンタルにアップデートするので、お使いのダッシュボードやクエリーがこれまで以上に高速に実行されるようになります。これらをまとめることで、SQLだけを用いて取り込みから変換処理に至る効率的かつスケーラブルなデータパイプラインを作成できるようになります。
この記事においては、DBSQLウェアハウスでデータや分析アプリケーションをより効果的にデリバリーするために、これらのツールがアナリストや分析エンジニアをどのように支援するのかをディープダイブします。さらに、モニタリング、エラーのトラブルシューティング、コスト追跡を強化するMVとSTの新機能をカバーします。
データウェアハウスユーザーが直面する課題
データウェアハウスは、ビジネスインテリジェンス(BI)アプリケーションを通じた分析や内部レポートのための主要な場となります。SQLアナリストは大規模なデータセットを効率的に取り込んで変換し、リアルタイム分析のための高速なクエリー性能を確実なものとし、クイックなデータアクセスとコストコントロールの間のバランスを管理しなくてはなりません。彼らは、これらのゴールを達成するためには以下のような課題に直面します:
- 遅いエンドユーザーのクエリーとダッシュボード: 大規模なBIダッシュボードは大規模なデータセットの複雑なビューを処理し、インタラクティブ性を阻害し、繰り返しのデータ再処理によるコスト増加につながる遅いクエリーにつながります。
- コストを削減しつつもデータの新鮮度を改善: 結果の再計算はクエリーのレイテンシーを削減しますが、多くの場合、古いデータやコストの増加につながり、合理性のあるコストで新鮮なデータを維持するための複雑なインクリメンタル処理を必要とします。
- セルフサービス: 従来のSQLパイプラインは複雑なマニュアルのコーディングに依存しており、ビジネス要件に対するレスポンスをスローダウンします。
マテリアライズドビューとストリーミングテーブルは高速で新鮮なデータを提供
MVとSTは、自動的なエンドツーエンドのインクリメンタル処理のおかげで、データの事前計算処理によるスピードを持つビューを簡単に組み合わせることで、これらの課題を解決します。これによって、エンジニアはビジネス要件に合わせてデータを最新の状態に保ちつつも、複雑なコードを記述することなしに、高速なクエリーを提供できるようになります。
MVによる高速なクエリーとダッシュボード
マテリアライズドビュー(MV)は、事前にクエリーの結果を事前計算し格納することでSQL分析やBIダッシュボードのパフォーマンスを強化し、クエリーのレイテンシーを劇的に削減します。ベーステーブルにクエリーを繰り返し実行するのではなく、MVによってダッシュボードやエンドユーザーのクエリーは事前に集計、事前にjoinしたデータを収集できるので、はるかに高速になります。さらに、MVへのクエリーはMVに格納されたデータのみにアクセスし、クエリーの都度背後のベーステーブルを再処理するオーバーヘッドを回避し、ビューと比べてはるかにコスト効率性が高いものとなっています。
コストを低く抑えつつもリアルタイムユースケースに移行
STとMVは完全にインクリメンタルなデータパイプラインを作成するために協働し、リアルタイムのユースケースで理想的なものとなります。STはストリーミングデータを連続的に取り込んで処理し、BIダッシュボードや機械学習モデル、オペレーショナルシステムが常に最新のデータを持つことを保証します。一方で、MVは新規データが到着すると自動でインクリメンタルにリフレッシュし、ビューの完全な再構築を回避することで処理コストを削減しつつも、手動での入力なしにユーザーに新鮮なデータを維持することが出来ます。STとMVを組み合わせることで、リアルタイム分析とレポーティングのベストなコストパフォーマンスを提供します。
また、インクリメンタルなリフレッシュを持つMVは時間をコストを激手に削減することが出来ます。200B行のテーブルにおける内部ベンチマークによると、MVのリフレッシュはテーブル全体のリフレッシュするよりも98%安価で85%高速であり、同様のCREATE TABLE AS文のコストの1/50で約7倍のデータの新鮮度につながりました。
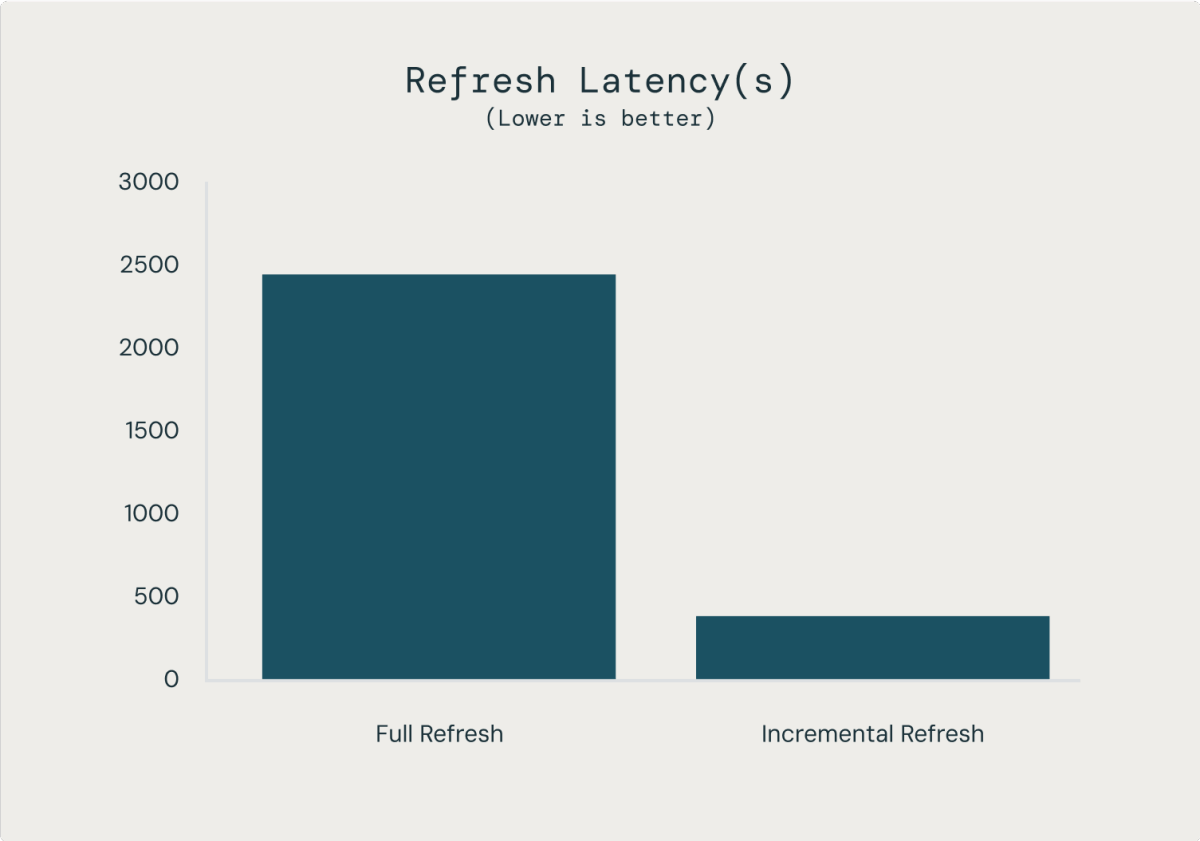
MVは類似のCREATE TABLE AS分よりも85%高速にアップデートできます
DBSQLにおけるデータパイプラインを構築するアナリストを支援
データパイプラインを開発するためにMVとSTを使うことで、テーブルとDMLコードの管理に関連する手動の作業の多くを自動化し、分析エンジニアがシンプルなSQL構文を用いて企業により大きな価値を提供し、ビジネスロジックにフォーカスできるようにします。
「トランザクションテーブルに対して効果的にマテリアライズドビューを用いることで、500Mのファクトテーブルにおけるクエリー時間を最大85%削減し、クエリーのパフォーマンスに大きな改善につながりました。これによって、ビジネスチームは分析ダッシュボードをより効率的に利用できるようになり、データから得られる洞察に基づいてよりクイックな意思決定をできるようになりました。」— Shiv Nayak / Head of Data and AI Architecture, EasyJet
「Databricksのマテリアライズドビューを用いることで、大規模なデータを取り扱うのに要する時間を劇的に削減することが出来ました。このエンハンスによって実行時間を85%削減し、我々のチームはより効率的に作業を行えるようになり、機械学習とビジネスインテリジェンスの洞察にフォーカスできるようになりました。これは、簡素化されたプロセスはより大規模なデータボリュームに対応できるようになり、全体的なコスト削減に寄与し、プロジェクトの俊敏性を増加させました。」- Sam Adams, Senior Machine Learning Engineer, Paylocity
「マテリアライズドビューに変換することで、クエリー性能の劇的な改善につながりました...さらに、コストの削減は本当に助かりました。」— Karthik Venkatesan, Security Software Engineering Sr. Manager, Adobe
「数テラバイトのデータを持ついくつかのテーブルにおいて、クエリー性能が98%改善したことを確認しました。」— Gal Doron, Head of Data, AnyClip
「トランザクションテーブルでマテリアライズドビューを活用することで、500Mのファクトテーブルにおいて実行時間を85%まで削減することで、我々の分析レイヤーにおけるクエリー性能を劇的に改善しました。」— Nikita Raje, Director Data Engineering, DigiCert
例: Databricksのボリュームからのデータ取り込みと変換
STとMVの一般的なユースケースは、データがクラウドストレージバケットに到着に応じて、データを連続的に取り込んで変換するというものです。以下の例では、外部の設定やオーケストレーションなしに、どのようにSQLで全てを行うのかを示しています。レイクハウスに到着するデータに対する一つのストリーミングテーブルを作成し、取り込まれた行数をカウントするマテリアライズドビューを作成します。
-
5分ごとにボリュームからデータを取り込むSTを作成します。このストリーミングテーブルは、新規データの一度きりのデリバリーを保証します。そして、STはデータ処理にバックグラウンドでサーバレスを使用するので、データボリュームのスパイクに対応するために自動でスケールします。
CREATE OR REFRESH STREAMING TABLE my_bronze REFRESH EVERY 5 minutes AS SELECT count(distinct event_id) FROM event_count from '/Volumes/bucket_name' -
1時間ごとにデータを変換するMVを作成します。このMVは定義されたクエリーの結果を常に反映し、可能な場合にはインクリメンタルにリフレッシュを行います。
CREATE OR REPLACE MATERIALIZED VIEW my_silver REFRESH EVERY 1 hour AS SELECT count(distinct event_id) as event_count from my_bronze
新機能
プレビューのローンチ以来、MVやST向けのカタログエクスプローラをエンハンスしてきており、リアルタイムのステータスやリフレッシュのスケジュールにアクセスすることが出来ます。さらに、MVではCREATE OR REPLACE機能をサポートしたので、インプレースでのアップデートが可能になりました。また、MVではinner join、UNION ALL、ウィンドウ関数の新規サポートを含む様々な種類のクエリーに対して拡張されたインクリメンタルなリフレッシュを提供します。新機能にディープダイブしていきましょう。
観測可能性
MVやSTのステータスやスケジュールに関する文脈に基づくリアルタイムの情報を用いて、カタログエクスプローラを強化しました。
- 現在のリフレッシュのステータス: MVやSTが最後にリフレッシュされた正確な時刻を表示します。これは、データがどれだけ新鮮なのかを示す優れたシグナルとなります。
- リフレッシュのスケジュール: お使いのマテリアライズドビューが時間ベースのスケジュールで自動リフレッシュされるように設定されている場合、カタログエクスプローラでは読みやすいフォーマットでスケジュールを表示するようになりました。これによって、エンドユーザーはMVの新鮮度を容易に確認することができます。
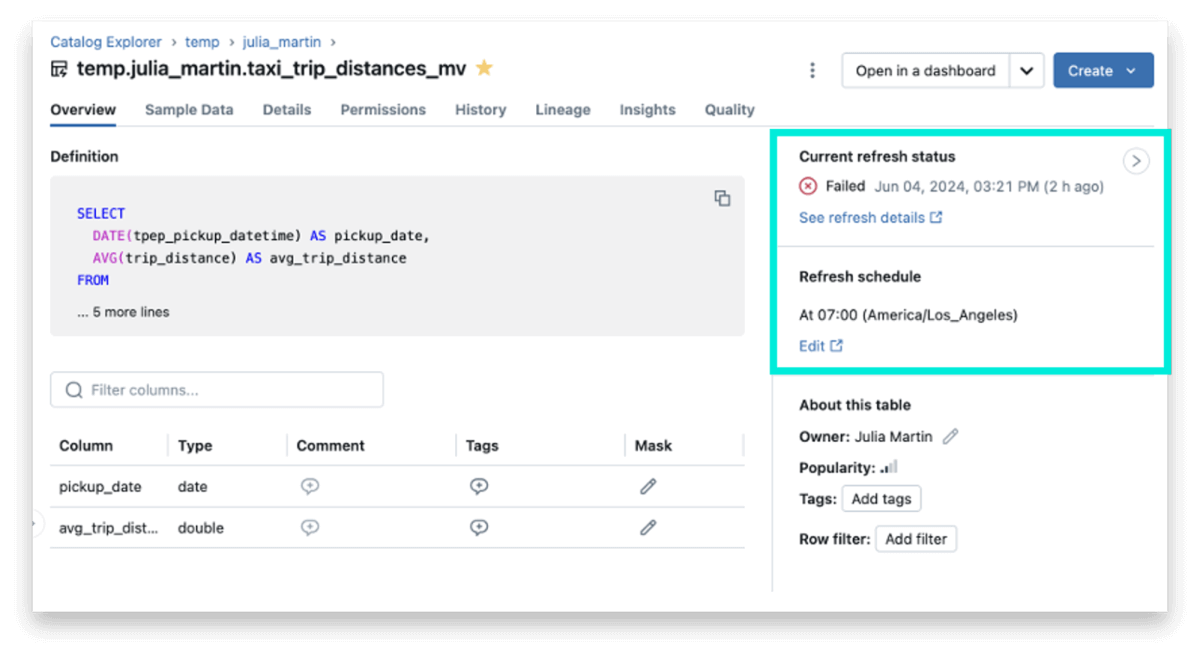
スケジューリングと管理を容易
DDLを用いたMVとSTのスケジューリングでEVERY構文を導入しました。EVERYは、CRON構文を書くことなしに、時間ベースのスケジュールの設定をシンプルにします。CRON構文の表現能力を必要とするユーザーのために、CRONのスケジューリングのサポートは継続します。
例:
CREATE OR REPLACE MATERIALIZED VIEW | STREAMING TABLE <name>
SCHEDULE EVERY 1 HOUR|DAY|WEEK
AS...
さらに、マテリアライズドビューでCREATE OR REPLACEのサポートを追加しており、既存の権限やACLを保持しつつも、ドロップ、再作成を行うことなしに、インプレイスで定義を簡単に更新することが出来ます。
left join、inner join、ウィンドウ関数をインクリメンタルにリフレッシュ
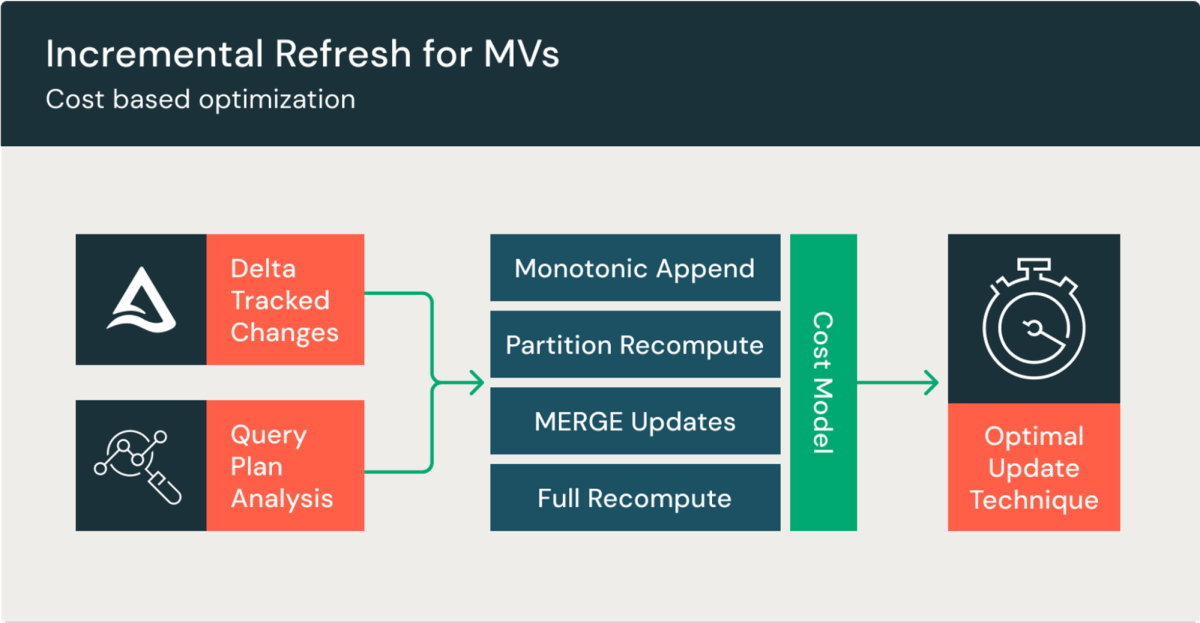
大規模なMVの再計算は高コストで遅いものです。MVはインクリメンタルに処理のアップデートを行うことでこれを解決し、コスト削減や高速なリフレッシュを実現します。これによって、エンドユーザーは計算済みのデータをクエリーできるようにしつつも、少ないコストでデータの新鮮度を改善することが出来ます。MVはDBSQL Proとサーバレスウェアハウス、Delta Live Tables(DLT)パイプラインでインクリメンタルにリフレッシュされます。
MVのクエリーがサポートされている場合、自動でインクリメンタルにリフレッシュされます。クエリーにサポートされていないエクスプレッションが含まれている場合、代わりにフルリフレッシュが実行されます。インクリメンタルなリフレッシュは最後のアップデート以降の変更のみを処理し、テーブルに追加あるいは更新を行います。
MVでは、inner join、left join、UNION ALL、ウィンドウ関数(OVER)をサポートしています。joinで任意の数のテーブルを指定することができ、joinに含まれるすべてのテーブルを更新し、クエリーの結果に反映されます。我々は継続的にさらなるクエリータイプのサポートに取り組んでいます。最新の機能に関してはドキュメントをご覧ください。
コストの配賦
課金システムテーブルでリフレッシュに関する情報を特定できるようになりました。この情報を取得するには、マテリアライズドビューやストリーミングテーブルに関連づけられているパイプラインのIDがusage_metadata.dlt_pipeline_idに設定されているレコードをシステムテーブルから取得するだけです。カタログエクスプローラでマテリアライズドビューやストリーミングテーブルを参照した際、詳細タブでパイプラインIDを特定することが出来ます。詳細はドキュメントをご覧ください。
SELECT sku_name, usage_date, identity_metadata, SUM(usage_quantity) AS `DBUs`
FROM
system.billing.usage
WHERE
usage_metadata.dlt_pipeline_id = <pipeline_id>
GROUP BY ALL
MVとSTで次に来るのは
MVとSTは、DBSQLのベストなデータウェアハウスの上の構築されたパワフルなデータウェアハウス機能です。1,400以上のお客様が、インクリメンタルな取り込みやリフレッシュ処理を強化するためにすでにこの機能を活用しています。また、近い将来、さらにMVとSTをより良いものにする予定であることに非常に興奮しています。まもなく提供されるいくつかのプレビューを以下に示します:
- 上流のデータ更新に基づいたリフレッシュ。 あるアップデート以降にどのくらいの感覚でリフレッシュを行うのかを制御することでコストを管理しつつも、上流のデータの変更に基づいて自動でリフレッシュを行うように設定できるようになります。
- オーナーの変更とサービスプリンシパルとしての実行。
- カタログエクスプローラで直接MVやSTにコメントをつけられる機能。
- UIでのMV/STの統合モニタリング。 DatabricksのUIですべてのMVとSTを確認し、ワークスペース全体での健康情報、運用情報を容易にモニタリングできるように。
- コスト監視。 MVとST名が課金システムテーブルに含まれるようになるので、パイプラインIDを検索することなしに、DBU使用量を容易に監視し、データを特定し、リフレッシュ履歴を確認できるようになります。
- Delta Sharing: プライベートプレビューで利用可能です。
- Google Cloudのサポート: 間も無く!
MVとSTを使い始める
使い始めるには:
- AWSやAzureのあなたのアカウントでサーバレスコンピュートを有効化する。
- サポートされているリージョンであり、お使いのワークスペースでUnity Catalogが有効化されていること
- マテリアライズドビューやストリーミングテーブルを始めるための特定の手順に従う