On-Time Flight Performance with GraphFrames for Apache Spark | Databricks Blogの翻訳です。
本書は抄訳であり内容の正確性を保証するものではありません。正確な内容に関しては原文を参照ください。
2016年の記事です。
導入
数多くの問題においてグラフ構造はより直感的なアプローチとなります。ソーシャルネットワークの経路、レストランのレコメンデーションやフライト経路などにおいて、グラフ構造の文脈でこれらの問題を理解する方が容易です: すなわち、頂点、エッジ、プロパティです。たとえば、フライトデータの分析は、空港は頂点、フライトはエッジによって表現されるので古典的なグラフ問題と言えます。そして、これらのフライトには、出発の遅延、飛行機のタイプ、キャリアなど数多くのプロパティが関連づけられます。
この記事では、グラフ構造でまとめられたフライトパフォーマンスデータをクイックかつ容易に分析できるように、Databricksノートブックで(Introducing GraphFramesで発表された)GraphFramesを活用します。グラフ構造を活用しているので、構造的なモチーフの特定、PageRankを用いたエアポートのランキング、都市間の最短パスのようにテーブル構造では直感的ではない数多くの質問を容易に行えるようになります。GraphFramesはクエリーをシンプルにし、Apache SparkのSQLエンジンのパフォーマンス最適化を活用するために、DataFrame APIの分散処理、表現能力を活用します。さらに、GraphFramesを用いる事で、Python、Scala、Javaでグラフ分析を行うことができます。
GraphFrames Sparkパッケージのインストール
GraphFramesを使うには、はじめにGraphFrames Spark Packagesをインストールする必要があります。Databricksでのパッケージのインストールは数ステップのシンプルなものです。
spark-shell、pyspark、spark-submitでのGraphFramesの参照方法は以下のようになります。
$SPARK_HOME/bin/spark-shell --packages graphframes:graphframes:0.1.0-spark1.6
Flightデータセットの準備
我々のグラフを構成する二つのデータセットは、OpenFlights Airport, airline and route dataで取得できるairportsデータセット(頂点)とAirline On-Time Performance and Causes of Flight Delays: On_Time Dataで取得できるdeparturedelaysデータセット(エッジ)です。
GraphFrames Spark Packageをインストールしたら、以下のようにすることで頂点、エッジ、(PySparkの)GraphFrameをインポート、作成します。
# Import graphframes (from Spark-Packages)
from graphframes import *
# Create Vertices (airports) and Edges (flights)
tripVertices = airports.withColumnRenamed("IATA", "id").distinct()
tripEdges = departureDelays.select("tripid", "delay", "src", "dst", "city_dst", "state_dst")
# This GraphFrame builds upon the vertices and edges based on our trips (flights)
tripGraph = GraphFrame(tripVertices, tripEdges)
例えば、tripEdgesにはoriginのIATA空港コード(src)、destinationのIATA空港コード(dst)、都市(city_dst)、州(state_dst)、出発遅延(delay)を特定できるフライトデータが含まれます。

tripGraphグラフフレームに対するシンプルなクエリー
tripGraphグラフフレームができたので、ご自身のグラフフレームをクイックにナビゲートし理解するために、数多くのシンプルなクエリーを実行することができます。例えば、グラフフレームに含まれる空港と移動の数を理解するために、以下のPySparkコードを実行します。
print "Airports: %d" % tripGraph.vertices.count()
print "Trips: %d" % tripGraph.edges.count()
これは以下のアウトプットとなります:
Airports: 279
Trips: 1361141
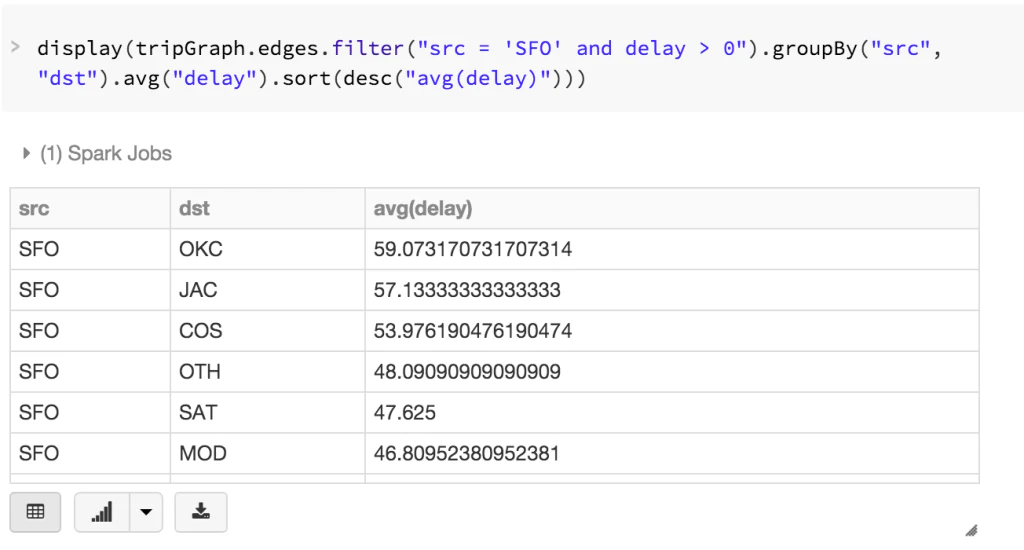
GraphFramesはSparkにおけるDataFrameベースのグラフであるため、DataFrame APIを活用した高度に表現的なクエリーを記述することができます。例えば、以下のクエリーによって、SFO空港からの出発が遅延した(delay > 0)フライト(エッジ)をフィルタリングし、平均遅延時間を計算しソートすることができます。これはすなわち、SFOから出発したどのフライトが、重大な遅延を引き起こす可能性が高いのか? という質問をしていることになります。
tripGraph.edges\
.filter("src = 'SFO' and delay > 0")\
.groupBy("src", "dst")\
.avg("delay")\
.sort(desc("avg(delay)"))
アウトプットを確認することで、このデータセットではSFOからWill Rogers World Airport (OKC)、Jackson Hole (JAC)、Colorado Springs (COS)へのフライトにおいて平均的に大きな遅延が生じていることをクイックに特定することができます。
Databricksノートブックでは、地図上にクイックに可視化することもできます: SEAから出発する際、どの州へのフライトで大きな遅延が起きる傾向があるのか?

フライト遅延を理解するためにMotif Findingを活用
都市の空港とフライト間の複雑な関係性をより簡単に理解するために、フライトで接続された空港のパターンを特定するためにモチーフを活用することができます。結果は、モチーフのキーが与えられたカラム名を持つデータフレームとなります。
例えば、SFO起因の遅延は何か? という質問を尋ねるためには、以下のようにシンプルなモチーフを生成することができます。
motifs = tripGraphPrime.find("(a)-[ab]->(b); (b)-[bc]->(c)")\
.filter("(b.id = 'SFO') and (ab.delay > 500 or bc.delay > 500) and bc.tripid > ab.tripid and bc.tripid > ab.tripid + 10000")
display(motifs)
SFOをcity(b)に接続することで、任意の目的地(c)へのフライト[bc]の前に、SFO(b)に接続する任意の出発地(a)からのすべてのフライト[ab]を検索します。それぞれのフライト([ab] or [bc])の遅延が500分以上で2番目のフライト(bc)が最初のフライト(ab)から1日以内に発生しているものにフィルタリングしています。
このクエリーによって得られる、カラム名がそれぞれのモチーフのキーとなっている簡易版のサブセットを以下に示します。
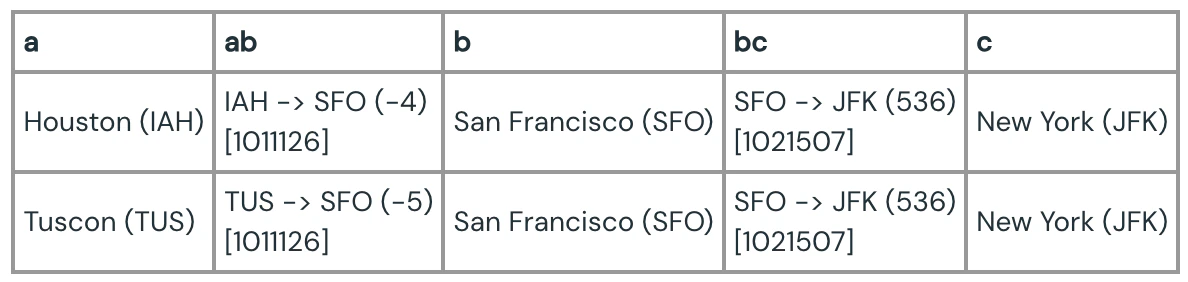
このモチーフ特定クエリーによって、このデータセットにおいてHoustonやTusconからSan Franciscoには定刻あるいは少し早くに出発していることをクイックに特定できます[1011126]。しかし、SFOでの接続フライトを利用している乗客[1021507]は536分の遅延を体験しています。
最も重要な空港を特定するためにPageRankを活用
GraphFramesはGraphXをベースとしているので、すぐに利用できる数多くのビルトインのアルゴリズムがあります。PageRankはGoogle Search Engineで人気を博し、ラリー・ペイジによって開発されました。Wikipediaによると:
PageRank works by counting the number and quality of links to a page to determine a rough estimate of how important the website is. The underlying assumption is that more important websites are likely to receive more links from other websites.
上の例はwebページを指しているものですが、このコンセプトの素晴らしいところは、Webページ、バイクステーション、空港であろうが任意のグラフ構造に適用でき、インタフェースはメソッド呼び出しのようにシンプルなものになっているということです。また、GraphFramesではアルゴリズムを実行した後に分析を継続できるように、シンプルな方法で頂点のデータフレームの新規カラムとして、PageRankの結果が返却されることに気づくことでしょう!
このデータセットにはさまざまな空港を経由する膨大な数のフライトと接続が含まれているので、それぞれの空港がどれだけ重要なのかをラフに見積もるために、PageRankアルゴリズムを活用することができます。
# Determining Airport ranking of importance using pageRank
ranks = tripGraph.pageRank(resetProbability=0.15, maxIter=5)
display(ranks.vertices.orderBy(ranks.vertices.pagerank.desc()).limit(20))
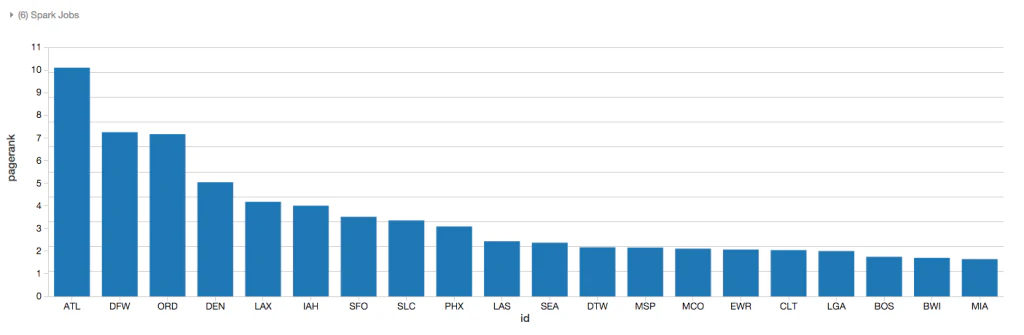
以下のグラフに示すように、PageRankアルゴリズムを用いる事で様々な頂点(空港)間の接続(フライト)の質によると、Atlantaが最も重要な空港の一つと考えることができます。これは、Atlanta is the busiest airport in the world by passenger trafficという事実と一致しています。
フライト接続の決定
様々な都市間で数多くのフライトがあるため、二つの都市間の経路を特定するためにGraphFrames.bfs (Breadth First Search)手法を活用することができます。以下のクエリーでは、最大パス長を1(ダイレクトフライト)にして、San Francisco (SFO)とBuffalo (BUF)間の経路を特定しようとしています。結果セットは空となっています(つまり、SFOとBUF間にはダイレクトフライトはありません)。
filteredPaths = tripGraph.bfs(
fromExpr = "id = 'SFO'",
toExpr = "id = 'BUF'",
maxPathLength = 1)
display(filteredPaths)
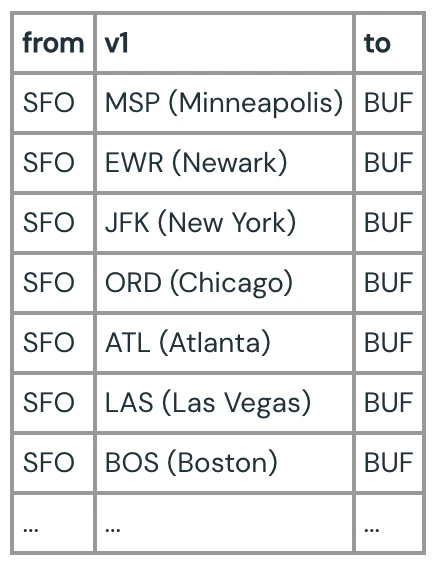
それでは、SFOとBUF間で1つの接続を持つmaxPathLength = 2を指定してクエリーを拡張しましょう。
filteredPaths = tripGraph.bfs(
fromExpr = "id = 'SFO'",
toExpr = "id = 'BUF'",
maxPathLength = 2)
display(filteredPaths)
SFOとBUF間の経路のサブセットは以下のようになります。
D3を用いたフライトの可視化
このデータセットのフライト経路と接続に関するパワフルなビジュアライゼーションを得るために、DatabricksノートブックでAirports D3 visualizationを活用することができます。GraphFrames、DataFrames、D3のビジュアライゼーションを組み合わせることで、このデータセットにおいて定時あるいは早期に出発したすべてのフライトにおけるすべてのフライト接続のスコープを可視化することができます。青い円は頂点、すなわち空港を表現し、円のサイズはエッジ、この空港で到着、発着するフライトの数を示しています。黒い線はエッジ、フライトを意味しており、他の頂点、空港への接続を表現しています。スクリーン外に伸びているエッジは、HawaiiとAlaskaの空港を示していることに注意してください。