こちらの機能のサンプルノートブックをウォークスルーします。
オンデマンド特徴量とは
「オンデマンド」とは、値が事前にわかっていないが、推論時に計算される特徴量を指します。 Databricksでは、Pythonユーザー定義関数 (UDF)を使用して、オンデマンド機能の計算方法を指定します。 これらの関数はUnity Catalogによって管理され、カタログエクスプローラーで検出できます。
オンデマンド特徴量 - 基本的なデモ
この例では、オンデマンド特徴量を使用してモデルをトレーニングし、スコアリングします。
この特徴量は、JSON文字列を解析してウェブページ上のホバー時間のリストを抽出します。これらの時間を平均し、その平均値をモデルの特徴量として渡します。
要件:
- Databricks Runtime for ML 13.3 LTS以上を実行しているクラスター。
- クラスターアクセスモデルはシングルユーザーである必要があります。
ヘルパー関数とノートブック変数
import json
import random
import time
import pandas as pd
import requests
from datetime import datetime
from databricks.feature_engineering import FeatureEngineeringClient, FeatureFunction
from pyspark.sql.types import IntegerType, BooleanType, StructField, StructType, StringType
import mlflow
from mlflow import MlflowClient
fe = FeatureEngineeringClient()
suffix = random.randint(1, 10000000000)
registered_model_name = f"takaakiyayoi_catalog.on_demand_demo.simple_model_{suffix}"
endpoint_name = f"on_demand_demo_simple_endpoint_{suffix}"
should_cleanup = True
セットアップ
%sql
-- デモ機能テーブルと関数を格納するスキーマを作成
CREATE SCHEMA IF NOT EXISTS takaakiyayoi_catalog.on_demand_demo
%sql
-- Python UDFを定義
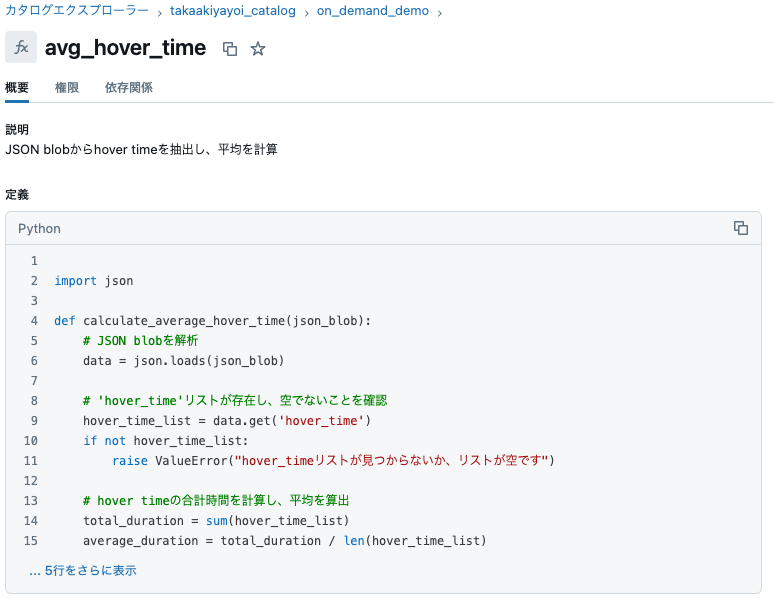
CREATE OR REPLACE FUNCTION takaakiyayoi_catalog.on_demand_demo.avg_hover_time(blob STRING)
RETURNS FLOAT
LANGUAGE PYTHON
COMMENT "JSON blobからhover timeを抽出し、平均を計算"
AS $$
import json
def calculate_average_hover_time(json_blob):
# JSON blobを解析
data = json.loads(json_blob)
# 'hover_time'リストが存在し、空でないことを確認
hover_time_list = data.get('hover_time')
if not hover_time_list:
raise ValueError("hover_timeリストが見つからないか、リストが空です")
# hover timeの合計時間を計算し、平均を算出
total_duration = sum(hover_time_list)
average_duration = total_duration / len(hover_time_list)
return average_duration
return calculate_average_hover_time(blob)
$$
関数が定義されます。
次のセルに示すように、SQLからPython UDFを呼び出すことができます。
%sql SELECT takaakiyayoi_catalog.on_demand_demo.avg_hover_time('{"hover_time": [5.0, 3.2, 4.1, 2.8, 6.7]}')

トレーニングデータセットを準備します。
schema = StructType([
StructField("id", IntegerType(), True),
StructField("json_blob", StringType(), True),
StructField("label", BooleanType(), True)
])
data = [
(1, '{"hover_time": [3.5, 4.2, 5.1, 2.8, 3.3]}', True),
(2, '{"hover_time": [1.2, 2.3, 3.4, 4.5, 5.6, 6.7]}', False),
(3, '{"hover_time": [7.8, 8.9, 6.1, 4.0, 5.3]}', True)
]
label_df = spark.createDataFrame(data, schema)
オンデマンド特徴量を使用してトレーニングセットを作成する
features = [
FeatureFunction(
udf_name="takaakiyayoi_catalog.on_demand_demo.avg_hover_time",
output_name="on_demand_output",
input_bindings={"blob": "json_blob"},
)
]
training_set = fe.create_training_set(
df=label_df, feature_lookups=features, label="label", exclude_columns=["id"]
)
display(training_set.load_df())
生データ、オンデマンド特徴量、予測ラベルから構成されるデータセットが作成されました。

トレーニングセットを使用してシンプルなモデルを記録する
簡単にするため、このノートブックではハードコーディングされたモデルを使用します。実際には、生成されたトレーニングセットでトレーニングされたモデルをログします。
class HighViewTime(mlflow.pyfunc.PythonModel):
def predict(self, ctx, inp):
return inp['on_demand_output'] > 5
model_name = "fs_packaged_model"
mlflow.set_registry_uri("databricks-uc")
fe.log_model(
model=HighViewTime(),
artifact_path=model_name,
flavor=mlflow.pyfunc,
training_set=training_set,
registered_model_name=registered_model_name
)
モデルが記録、登録されます。

関数とモデルのリネージを確認できます。

score_batch を使用してモデルをスコアリングする
schema = StructType([
StructField("id", IntegerType(), True),
StructField("json_blob", StringType(), True),
])
data = [
(4, '{"hover_time": [2.1, 3.1, 4.1, 5.1, 6.1]}'),
(5, '{"hover_time": [4.4, 5.5, 6.6, 7.7, 8.8]}'),
]
scoring_df = spark.createDataFrame(data, schema)
result = fe.score_batch(
model_uri = f"models:/{registered_model_name}/1",
df = scoring_df,
result_type = 'bool'
)
display(result)
推論が行われました。

特徴量ストアパッケージモデルのサービング
オンラインからオンデマンド特徴量を利用できるようにするために、このモデルをモデルサービングエンドポイントにデプロイします。
start_endpoint_json_body = {
"name": endpoint_name,
"config": {
"served_entities": [
{
"entity_name": registered_model_name,
"entity_version": "1",
"workload_size": "Small",
"scale_to_zero_enabled": True,
}
]
},
}
host_creds = mlflow.utils.databricks_utils.get_databricks_host_creds()
headers = {
"Authorization": f"Bearer {host_creds.token}",
"Content-Type": "application/json"
}
response = requests.request(
url=f"{host_creds.host}/api/2.0/serving-endpoints",
method="POST",
json=start_endpoint_json_body,
headers=headers
)
assert (
response.status_code == 200
), f"Failed to launch model serving cluster: {response.text}"
print("Starting model serving endpoint. See Serving page for status.")
数分待つと、エンドポイントが利用できるようになります。

エンドポイントへのクエリー
req = pd.DataFrame(
[
{"json_blob": '{"hover_time": [5.5, 2.3, 10.3]}'}
]
)
json_req = json.dumps({"dataframe_split": json.loads(req.to_json(orient="split"))})
response = requests.request(
method="POST",
headers=headers,
url=f"{host_creds.host}/serving-endpoints/{endpoint_name}/invocations",
data=json_req
)
response.json()
{'predictions': [{'on_demand_output': True}]}
あるいは、サービングエンドポイントのUIを使用してリクエストを送信します:
{
"dataframe_records": [
{"json_blob": "{\"hover_time\": [5.5, 2.3, 10.3]}"}
]
}

クリーンアップ
モデルサービングエンドポイントを削除します。
if should_cleanup:
MlflowClient().delete_registered_model(name=registered_model_name)
requests.request(
method="DELETE",
headers=headers,
url=f"{host_creds.host}/api/2.0/preview/serving-endpoints/{endpoint_name}"
)