How to Save Time and Money on Data and ML Workflows With “Repair and Rerun” - The Databricks Blogの翻訳です。
本書は抄訳であり内容の正確性を保証するものではありません。正確な内容に関しては原文を参照ください。
Databricksジョブは皆様のデータ、分析、AI全てに対する完全にマネージドなオーケストレーターです。全てのユーザーは複数のタスクから構成されるワークフローを簡単に作成することができ、タスク間の依存関係を定義することができます。これによって、コードのモジュール化、迅速なテスト、より効率的なリソースの利用を実現し、トラブルシュートを容易にします。背後のレイクハウスプラットフォームとの密なインテグレーションによって、包括的なモニタリング、スケーラビリティを提供しつつもプロダクションにおける信頼性を実現します。
現実世界のデータと機械学習のユースケースをサポートするために、企業はデータの取り込みからETL、MLモデルのトレーニング、サービングに至る多くの異なるタスクと依存関係を持つ洗練されたワークフローを構築する必要があります。これらのそれぞれのタスクは特定の順序で実行される必要があります。
しかし、ワークフローの重要なタスクが失敗した場合、関連している後段のタスク全てにインパクトがあります。ワークフローを復旧するには、インパクトを受けるタスク全てを理解し、最初からパイプラインを再実行することなしにどのように処理するのかを知っている必要があります。Databricksジョブの新たな「リペアおよびリラン」の機能は、まさにこの問題に取り組むために設計されました。
APIからバスの停留場に関する情報を取得し、別のAPIからリアルタイムで停留場の気候情報を取得しようとする以下の例を考えてみます。これら全てのAPI呼び出しの結果は取り込まれ、変換され、Delta Live Tablesのタスクによって集約されます。

このワークフローの通常のオペレーションでは、最初から最後まで問題なく動作します。しかし、タスクが気候データの取得に失敗したら何が起きるのでしょうか?何かしらの理由で気候APIが一時的に利用できなかったのかもしれません。この場合、前段の依存関係が失敗したのでDelta Live Tablesのタスクはスキップされることでしょう。当たり前ですが、ワークフローを再実行する必要がありますが、最初からプロセス全体を起動することは、station_informationデータを再度処理することになり、時間とリソースの無駄となります。
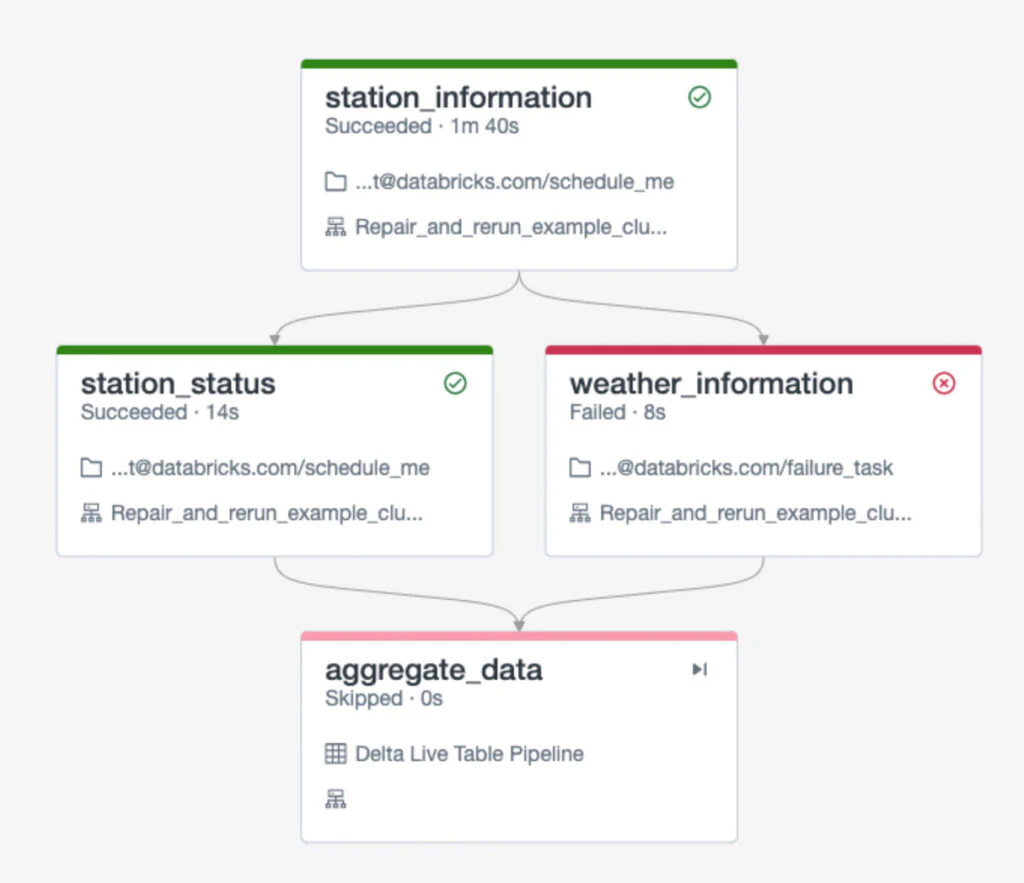
新たに導入された「リペアおよびリラン」の機能は、お使いのジョブでエラーが起きた箇所を表示するだけではなく、インパクトを受けた全てのタスクを再実行することができます。これによって、すでに成功しているタスクを再実行する必要がなくなるので、時間とコストを劇的に節約することができます。
ジョブの実行が失敗した場合、リランを実行するにはRepair runをクリックします。実行される残りのタスクを表示するポップアップ画面が表示されます。

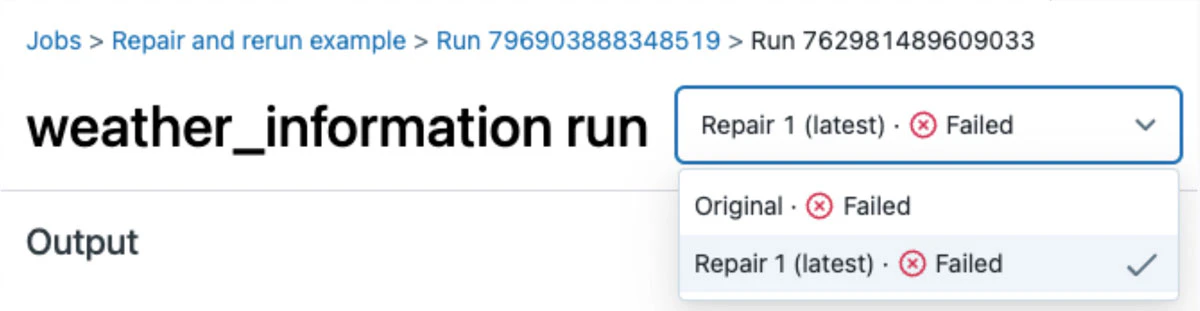
新たなジョブ実行には、失敗した親のジョブ実行と関連づけられるユニークなバージョン番号が割り当てられるので、過去の失敗を確認し分析することが容易となります。
タスクが失敗した際、Databricksジョブの「リペアおよびリラン」は、お使いのプロダクションのパイプラインを迅速に修正するお役に立ちます。直感的なUIでは、どのタスクがインパクトを受けているのかを正確に表示するので、フロー全体を再実行することなしに問題を修正することができます。これによって、将来的に発生する問題を低減するための深い洞察を得つつも、時間と工数を削減することができます。
「リペアおよびリラン」は、最近提供されたクラスターの再利用機能に続いて正式提供(GA)となっています。
次のステップ
ロードマップに従い提供される新機能を楽しみにしており、皆様からのフィードバックを心待ちにしています。