こちらのイベントで話した内容をこちらにもまとめます。資料にはデモを含めていないので、こちらではデモの流れもカバーします。
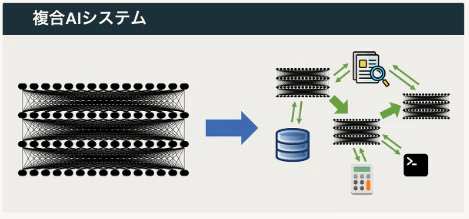
複合AIシステム(Compound AI system)
複合AIシステムは、インタラクションする複数のコンポーネントを組み合わせることで課題に取り組むシステムです。対照的に、テキストの次のトークンを予測するTransformerのようなAIモデルは単なる統計モデルです。複合AIシステムは、そのパフォーマンスと柔軟性により、AIアプリケーションの設計パターンとしてますます一般的になっています。
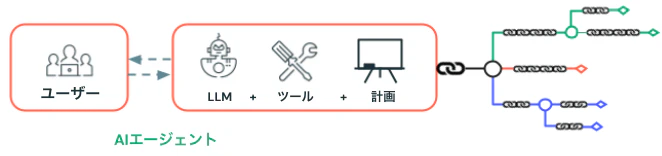
AIエージェント
この業界ではまだAIエージェントを定義している最中ですが、一般的にはハードコードされたロジックとは対照的に、モデルが計画決定の一部またはすべてを行うAIシステムとして理解されています。これらのエージェントは、大規模言語モデル (LLM) を活用して意思決定を行い、目的を達成します。多くのAIエージェントアプリケーションは複数のシステムで構成されているため、複合AIシステムとして見なすことができます。

ツール
AI エージェントは、構造化・非構造化データの取得、コードの実行、EメールやSlackメッセージの送信などのリモートサービスとの会話など、言語生成以外のアクションを実行するためのツールを使用します。
一般的なエージェントワークフローでは、エージェントLLMには、ツールに関するメタデータが与えられ、それを使用してツールをいつ、どのように使用するかを決定します。 したがって、ツールを定義するときは、エージェント LLM がツールを最大限に活用できるように、ツール、そのパラメーター、および戻り値が十分に文書化されていることを確認する必要があります。
AIシステムの進化
LLM: 当初、大規模言語モデルは、膨大なトレーニング データセットからの知識に基づいてプロンプトに応答するだけでした。
LLM + ツールチェーン: その後、開発者はハードコードされたツールを追加して、LLMの機能を拡張しました。 たとえば、RAG(Retrieval Augmented Generation)はカスタムの文書を使用して LLMのナレッジベースを拡張し、API ツールによってLLMはサポートチケットの作成や電子メールの送信などのタスクを実行できるようになりました。

AIエージェント: 現在、AIエージェントは、問題に対する理解に基づいて自律的に計画を作成し、タスクを実行します。 AIエージェントはまだツールを使用していますが、どのツールをいつ使用するかは彼ら次第です。 主な違いは、複合AIシステムと比較した自律性と意思決定能力の
レベルにあります
AIエージェントの例
顧客サービス: AIを利用したチャットボット (カスタマーサービス) は、ユーザーと対話し、自然言語を理解し、適切な応答を提供したり、タスクを実行したりします。 企業は顧客サービスのためにAI チャットボットを使用して、問い合わせに回答したり、製品情報を提供したり、トラブルシューティングを支援しています。
製造業の予知保全: AIエージェントは、単に機器の故障を予測したり、交換品を注文して自律的に対応したり、メンテナンスをスケジュールしてダウンタイムを削減し、生産性を向上させたりするだけでなく、さまざまなことを行うことができます。
しかし、高品質で正確なエージェントの作成は困難です
- 品質を評価するためのメトリクスの選択が困難
- 人間のフィードバックを効率的に収集することが困難
- 品質問題の根本原因の特定が困難
- プロダクション目標に到達するようにエージェント品質改善の迅速な試行錯誤が困難
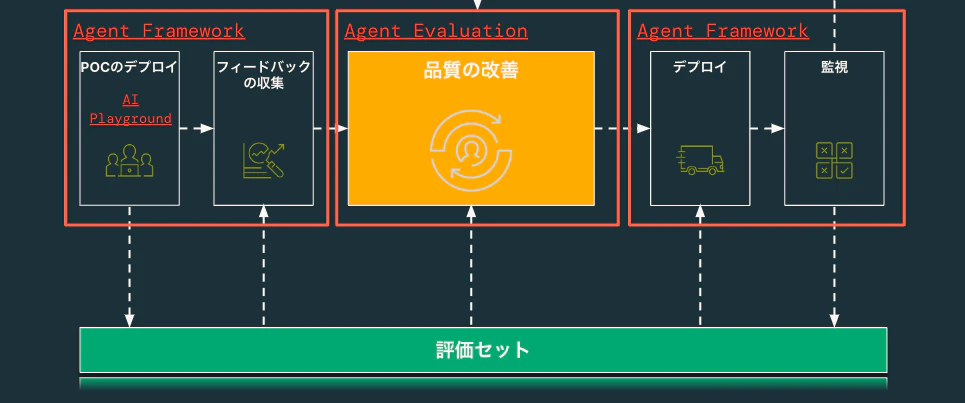
Databricksにおける評価ドリブン開発のワークフロー
このような課題を解決するために、Databricksでは、評価ドリブン開発のワークフローを提唱しています。エージェントシステムの開発時点から評価の仕組みを組み込んでしようというものです。

Agent Framework & Agent Evaluation
このようなワークフローを実現するために、DatabricksではMosaic AI Agent FrameworkとMosaic AI Agent Evaluationというソリューションを提供しています。
Mosaic AI Agent Framework
- エージェントを作成、MLflowで記録
- 1行のコードでエージェントをモデルサービングエンドポイントにデプロイ
- ステークホルダーからフィードバックを収集するためのレビューアプリを自動で作成
Mosaic AI Agent Evaluation
- エージェントを評価するためにプロプライエタリなLLMジャッジを活用
- Mosaic ResearchではこれらのLLM審判を高品質にするために投資しています
- レーテンシーやトークンのコストのようなパフォーマンスメトリクスを収集
- Agent Frameworkと独立して活用可能
これらのソリューションは、以下のように開発フェーズのそれぞれでサポートします。
Mosaic AI Agent FrameworkとMosaic AI Agent Evaluationのデモ
ここではクッキーフランチャイズのデータを取り扱うエージェントをデモします。フランチャイズの情報や売り上げのデータはテーブルで管理されています。

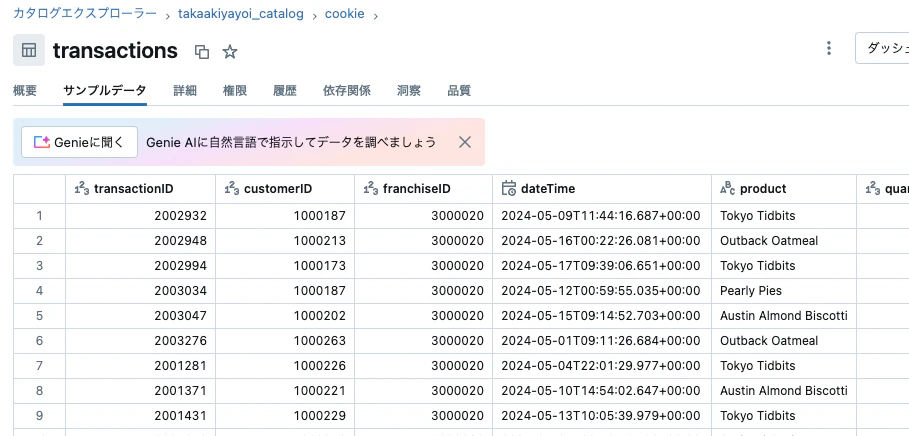
Databricksではエージェントが活用するツールを関数として定義することができます。上記のテーブルに問い合わせを行うツールを定義します。ここでは関数の定義や入出力に対するコメントを適切に定義することが重要です。LLMがこれらのコメントを参照して適切なツールを特定し、活用できるようになります。以下の例ではSQLでツールを定義していますが、Pythonも使えますのでより柔軟にツールのロジックを構成することができます。

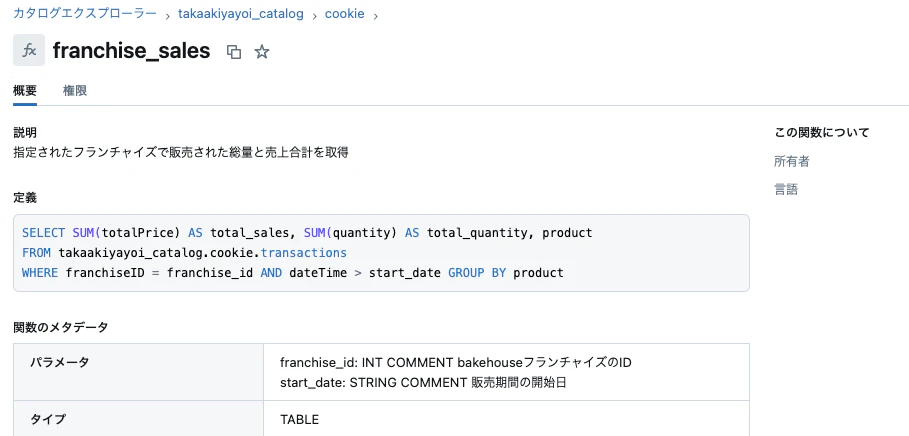
これらのツールを定義したら、プロトタイピングのためにAI Playgroundを活用することができます。AI Playgroundでは様々なモデルを対象にしたプロンプトエンジニアリングを行うことができますが、ここで上記のツールを組み合わせることができます。
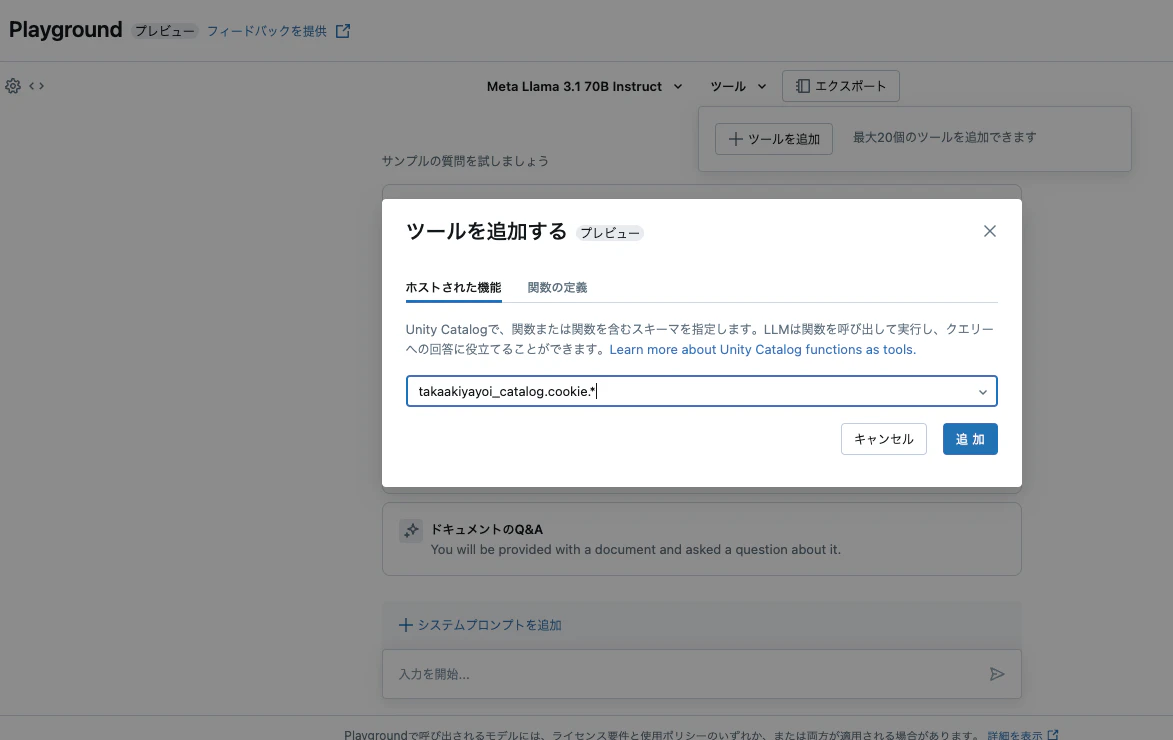
上で定義したツールを選択することで、プロンプトの内容に基づいてLLMがツールを活用するようになります。
東京で一番売り上げのあるクッキー
このように問い合わせを行うと、定義したツールを活用してデータを取得してレスポンスを返します。
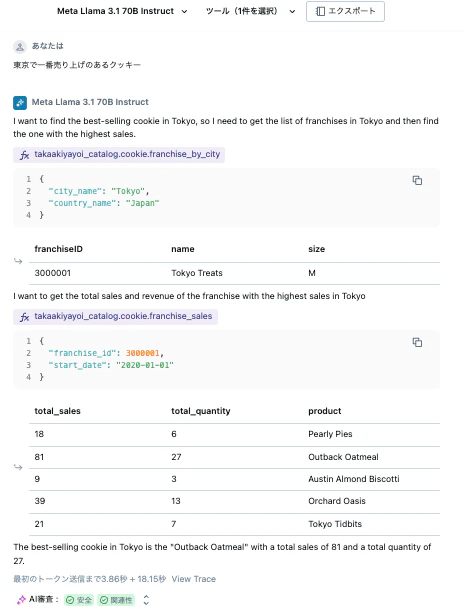
さらに、モデルを変更したり、システムプロンプトを定義することで、エージェントの挙動をコントロールすることができます。
あなたはクッキー売り上げデータの専門家です。フランチャイズ情報や売り上げ情報を活用して、質問に対して日本語で回答します。地名は英語に変換してください。
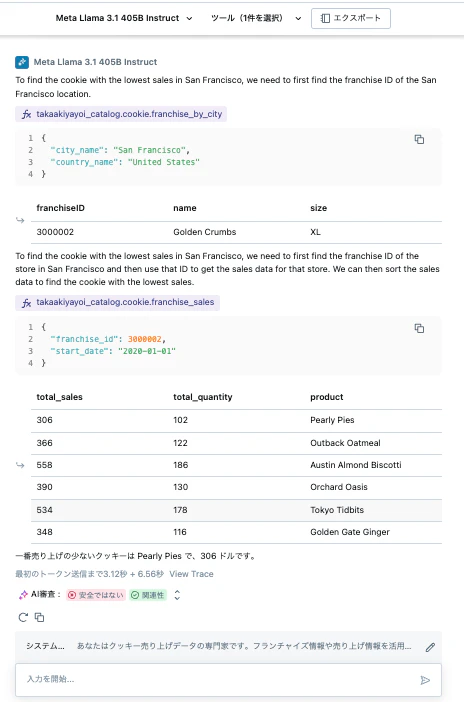
ここまではあくまでプロトタイプです。このエージェントを本格運用したい場合には、画面上にあるエクスポートボタンをクリックします。これによって、ツールとLLMが組み合わされたエージェントの実装を含むノートブックやYAMLファイルが生成されます。
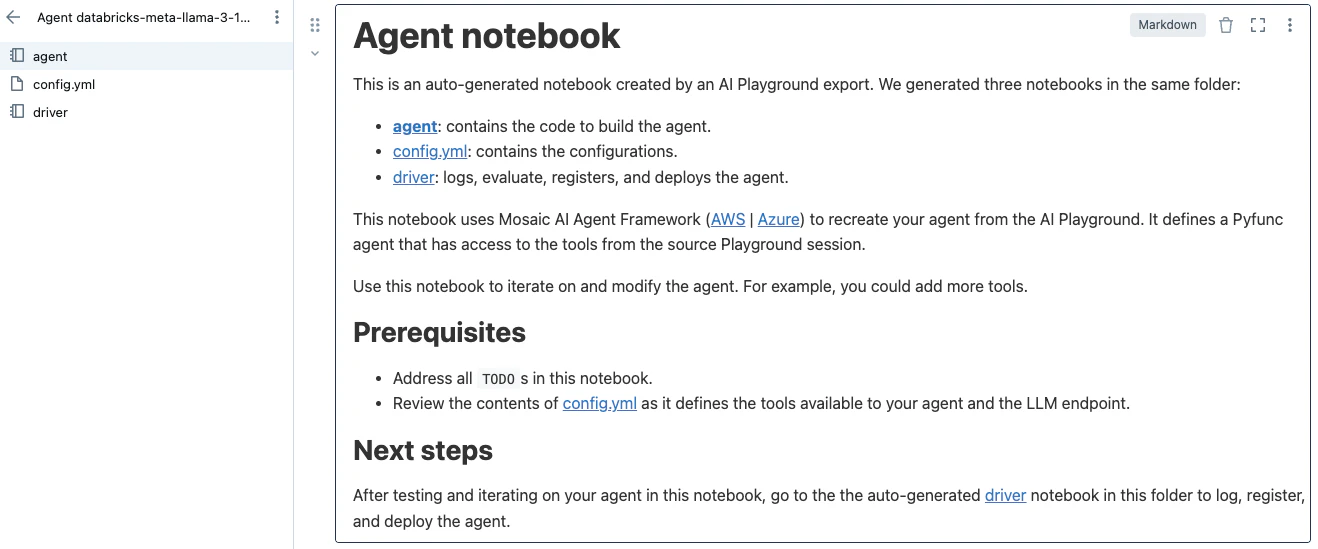
この中のdriverノートブックを実行することで、エージェントがモデルサービングエンドポイントにデプロイされ、品質レビューのためのアプリもデプロイされます。

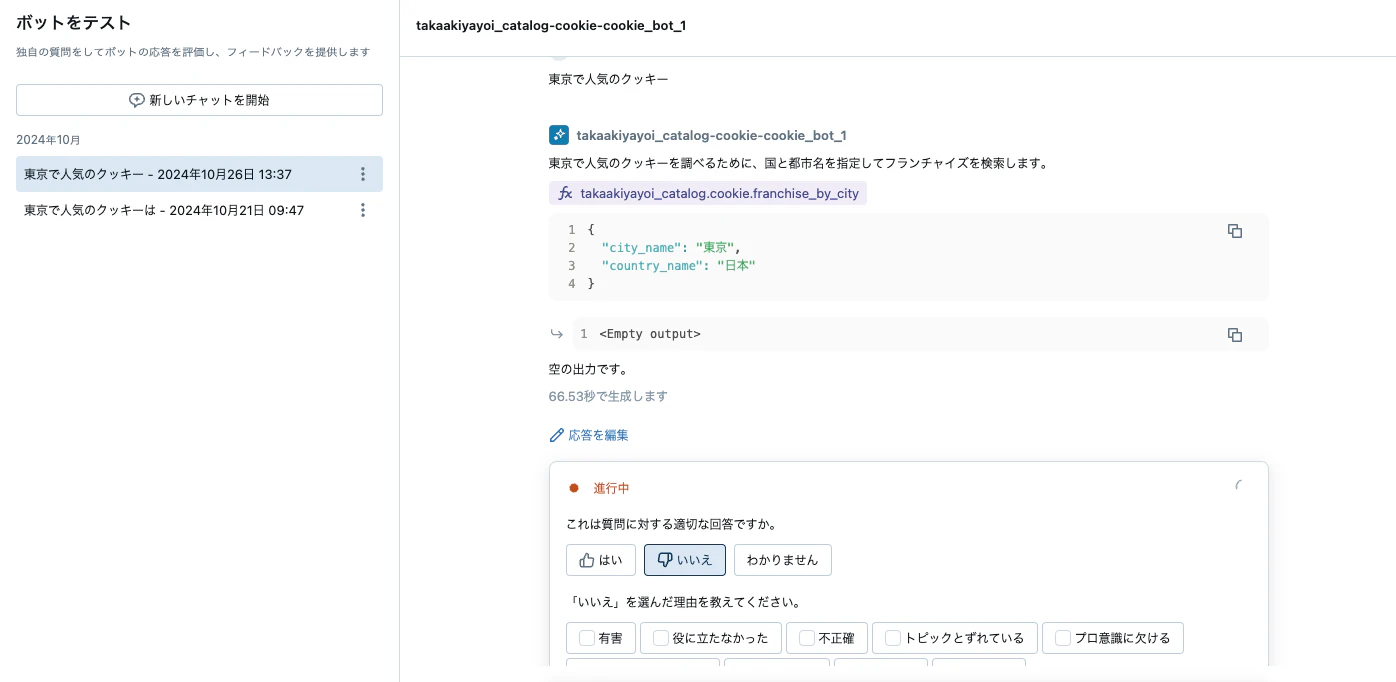
レビューアプリはドメイン専門家に活用していただき、エージェントのレスポンスの良し悪しをフィードバックいただき、エージェントの品質を改善することを目的にしています。
今回は、シンプルなLLM→SQLというエージェントでしたが、今後は外部API呼び出しなどより複雑な挙動を可能にするエージェントがサポートされる予定です!