こちらのサンプルノートブックをウォークスルーします。
翻訳版のノートブックはこちらです。
特徴量ストアとは
特徴量ストアは、データサイエンティストが特徴量を発見、共有できる集中管理されたリポジトリであり、モデルトレーニングと推論に使われる特徴量の値を計算するために同じコードが使われることを確実にします。
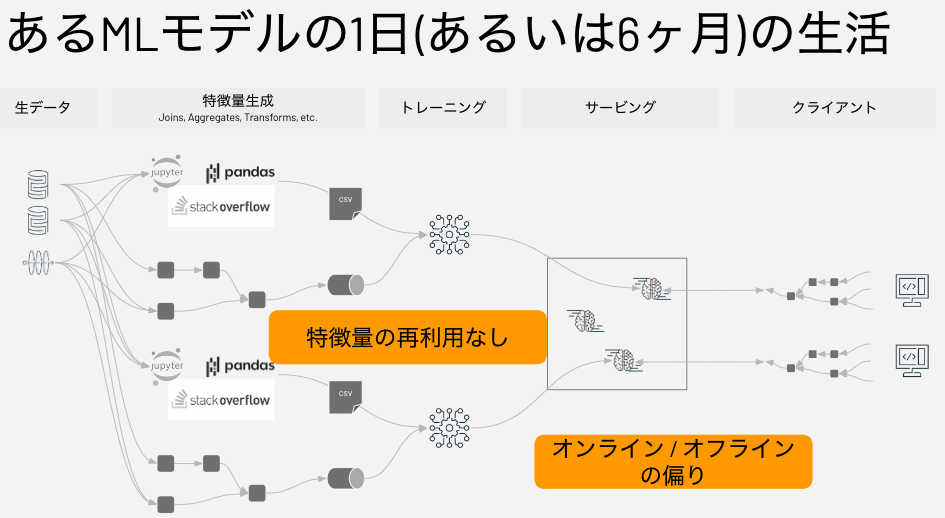
特徴量ストアが解決する課題は、複数人のデータサイエンティストが同じデータを基点として機械学習を行う際に、それぞれが別個に特徴量エンジニアリングを行なって、各自で特徴量のデータ(テーブルやデータフレーム)を作ってしまい、特徴量の用途は同じながらも微妙にロジックや結果が異なり、しかも、作りっぱなしで再利用されないということです。
さらに、モデルをトレーニングする際にモデルに入力する特徴量と、推論の際にモデルに入力する特徴量は同じロジックで計算されるべきですが、各自でロジックを作っていると、トレーニングで用いる特徴量と、推論で用いられる特徴量が異なるロジックで計算されてしまうということが起こってしまいます。これによって、期待した精度が出ないということも起こり得ます。これを「オフライン(トレーニング)とオンライン(推論)の偏り」と呼びます。
Databricks Feature Storeとは
Databricksが提供する特徴量ストアであるDatabricks Feature Storeは、他のDatabricksのコンポーネントと完全にインテグレーションされています。
- 発見可能性。DatabricksワークスペースからアクセスできるFeature Store UIを用いることで、既存の特徴量をブラウズ、検索することができます。
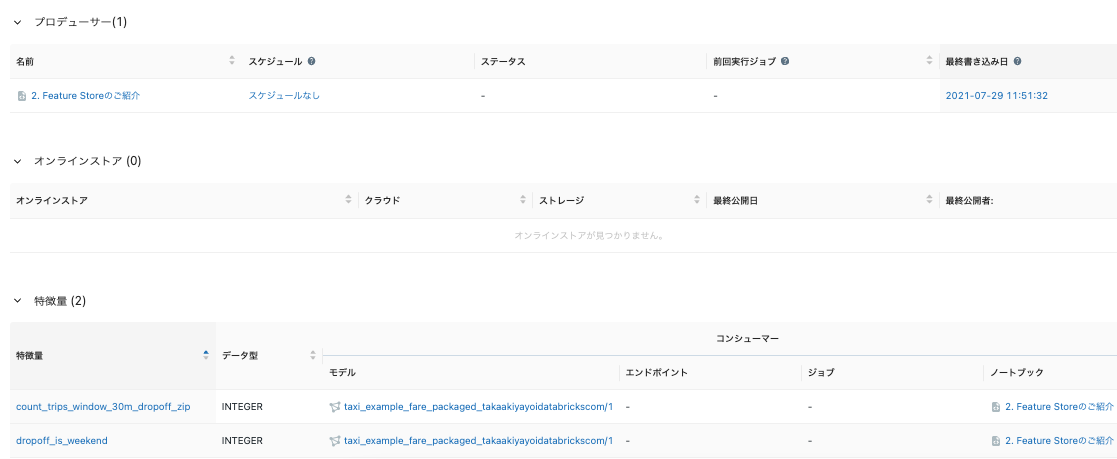
- リネージュ。Feature Storeを用いて特徴量テーブルを作成すると、特徴量テーブルを作成するために使用されたデータソースが保存され、アクセス可能になります。特徴量テーブルのそれぞれの特徴量に対して、特徴量を使用しているモデル、ノートブック、ジョブ、エンドポイントにもアクセスすることができます。
- モデルスコアリング、モデルサービングとのインテグレーション。モデルをトレーニングするためにFeature Storeからの特徴量を使う際、モデルは特徴量メタデータと一緒にモデルがパッケージングされます。バッチスコアリングやオンライン推論にモデルを使う際、Feature Storeから自動で特徴量を取得します。呼び出し元は、これらに関して知る必要や、新規データをスコアリングするために特徴量を検索、joinするロジックを含める必要はありません。これによって、モデルのデプロイメントと更新をより簡単なものにします。
- ポイントインタイムの検索。Feature Storeでは、ポイントインタイムの正確性を必要とする時系列、イベントベースのユースケースをサポートしています。
Databricks Feature Storeを用いることで、特徴量エンジニアリングのロジックと特徴量データを、トレーニングや推論のノートブックから分離することができます。これによって、特徴量の再利用を促進し、オフライン・オンラインの偏りを回避することができます。
具体的にどの様に行うのかを以下で見ていきます。
ノートブックのウォークスルー
このノートブックでは、NYCイエロータクシーの料金を予測するモデルを作成するために、どのようにFeature Storeを使うのかを説明します。以下のステップが含まれます:
- 特徴量の計算および書き込み。
- 料金を予測するためにこれらの特徴量を用いてモデルをトレーニング。
- Feature Storeに保存された既存の特徴量を用いて新たなバッチデータでモデルを評価。
特徴量の計算
特徴量を計算するために生のデータをロード
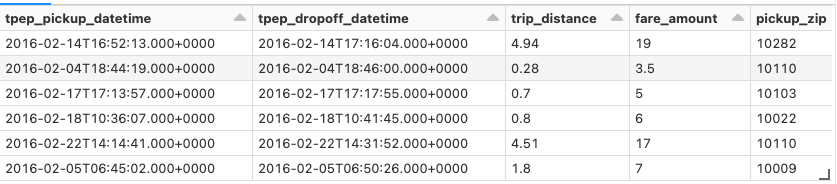
nyc-taxi-tinyデータセットをロードします。これは、完全なNYC Taxi Dataから生成されたものであり、以下の変換処理を適用した後にdbfs:/databricks-datasets/nyctaxiに保存されています。
- 緯度経度をZIPコードに変換するUDFを適用し、データフレームにZIPコードのカラムを追加。
- Spark
DataFrameAPIの.sample()メソッドを用いて、日付レンジクエリーに基づいてより小規模なデータセットにサブサンプリング。 - 特定のカラム名を変更し、不要なカラムを削除。
raw_data = spark.read.format("delta").load("/databricks-datasets/nyctaxi-with-zipcodes/subsampled")
display(raw_data)
特徴量エンジニアリング
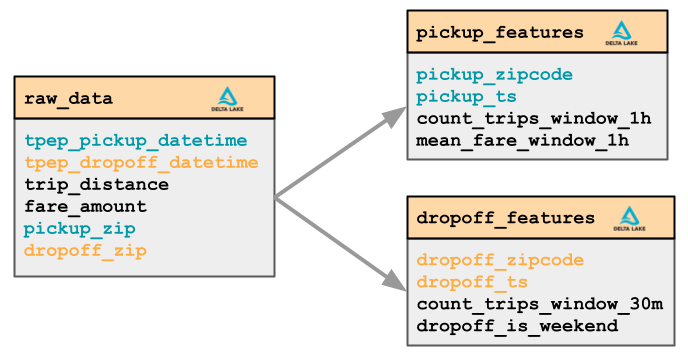
タクシー料金のトランザクションデータから、乗車地点(Pick up)と降車時点(Drop off)のZIPコードに基づいて2つのグループの特徴量を計算します。
Pickup特徴量
- 移動回数(時間ウィンドウ = 1時間、スライディングウィンドウ = 15分)
- 平均料金(時間ウィンドウ = 1時間、スライディングウィンドウ = 15分)
Dropoff特徴量
- 移動回数(時間ウィンドウ = 1時間、スライディングウィンドウ = 15分)
- 降車は週末か(Pythonコードによるカスタム特徴量)
ヘルパー関数
from databricks import feature_store
from pyspark.sql.functions import *
from pyspark.sql.types import FloatType, IntegerType, StringType
from pytz import timezone
@udf(returnType=IntegerType())
def is_weekend(dt):
tz = "America/New_York"
return int(dt.astimezone(timezone(tz)).weekday() >= 5) # 5 = 土曜日, 6 = 日曜日
@udf(returnType=StringType())
def partition_id(dt):
# datetime -> "YYYY-MM"
return f"{dt.year:04d}-{dt.month:02d}"
def filter_df_by_ts(df, ts_column, start_date, end_date):
if ts_column and start_date:
df = df.filter(col(ts_column) >= start_date)
if ts_column and end_date:
df = df.filter(col(ts_column) < end_date)
return df
特徴量を計算するためのデータサイエンティストのカスタムコード
def pickup_features_fn(df, ts_column, start_date, end_date):
"""
pickup_features特徴量グループを計算
特徴量を時間レンジに限定するには、kwargsとしてts_columnにstart_date, end_dateを指定します
"""
df = filter_df_by_ts(
df, ts_column, start_date, end_date
)
pickupzip_features = (
df.groupBy(
"pickup_zip", window("tpep_pickup_datetime", "1 hour", "15 minutes")
) # 1時間のウィンドウ、15分ごとにスライド
.agg(
mean("fare_amount").alias("mean_fare_window_1h_pickup_zip"),
count("*").alias("count_trips_window_1h_pickup_zip"),
)
.select(
col("pickup_zip").alias("zip"),
unix_timestamp(col("window.end")).alias("ts").cast(IntegerType()),
partition_id(to_timestamp(col("window.end"))).alias("yyyy_mm"),
col("mean_fare_window_1h_pickup_zip").cast(FloatType()),
col("count_trips_window_1h_pickup_zip").cast(IntegerType()),
)
)
return pickupzip_features
def dropoff_features_fn(df, ts_column, start_date, end_date):
"""
dropoff_features特徴量グループを計算
特徴量を時間レンジに限定するには、kwargsとしてts_columnにstart_date, end_dateを指定します
"""
df = filter_df_by_ts(
df, ts_column, start_date, end_date
)
dropoffzip_features = (
df.groupBy("dropoff_zip", window("tpep_dropoff_datetime", "30 minute"))
.agg(count("*").alias("count_trips_window_30m_dropoff_zip"))
.select(
col("dropoff_zip").alias("zip"),
unix_timestamp(col("window.end")).alias("ts").cast(IntegerType()),
partition_id(to_timestamp(col("window.end"))).alias("yyyy_mm"),
col("count_trips_window_30m_dropoff_zip").cast(IntegerType()),
is_weekend(col("window.end")).alias("dropoff_is_weekend"),
)
)
return dropoffzip_features
from datetime import datetime
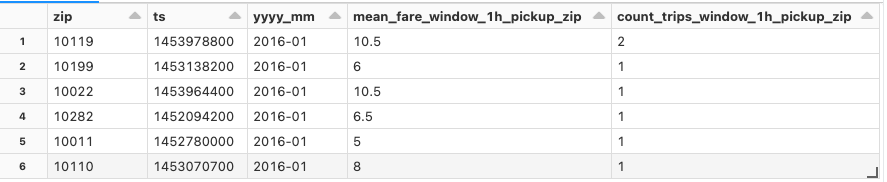
pickup_features = pickup_features_fn(
raw_data, ts_column="tpep_pickup_datetime", start_date=datetime(2016, 1, 1), end_date=datetime(2016, 1, 31)
)
dropoff_features = dropoff_features_fn(
raw_data, ts_column="tpep_dropoff_datetime", start_date=datetime(2016, 1, 1), end_date=datetime(2016, 1, 31)
)
display(pickup_features)
注意
このノートブックでは特徴量エンジニアリングのコードとトレーニングのコード、推論のコードが一緒になっていますが、実際の運用では特徴量エンジニアリングのコードは別出しにし、ジョブなどで定期更新する形になります。
新規特徴量テーブルを作成するためにFeature Storeライブラリを使用
最初に特徴量テーブルが保存されるデータベースを作成します。
%sql
-- データベースは適宜変更してください
CREATE DATABASE IF NOT EXISTS feature_store_taxi_example_takaaki_yayoi;
次にFeature Storeクライアントのインスタンスを作成します。
fs = feature_store.FeatureStoreClient()
スキーマとユニークIDキーを定義するために、create_table APIを使います。オプションの引数df (0.3.6以降)が渡されると、このAPIはこのデータもFeature Storeに書き込みます。
spark.conf.set("spark.sql.shuffle.partitions", "5")
# データベースを適宜変更してください
fs.create_table(
name="feature_store_taxi_example_takaaki_yayoi.trip_pickup_features",
primary_keys=["zip", "ts"],
df=pickup_features,
partition_columns="yyyy_mm",
description="タクシー料金。 Pickup特徴量",
)
# データベースを適宜変更してください
fs.create_table(
name="feature_store_taxi_example_takaaki_yayoi.trip_dropoff_features",
primary_keys=["zip", "ts"],
df=dropoff_features,
partition_columns="yyyy_mm",
description="タクシー料金。 Dropoff特徴量",
)
特徴量の更新
特徴量テーブルの値を更新するには、write_tableを使います。

# pickup_features特徴量グループを計算します
pickup_features_df = pickup_features_fn(
df=raw_data,
ts_column="tpep_pickup_datetime",
start_date=datetime(2016, 2, 1),
end_date=datetime(2016, 2, 29),
)
# 特徴量ストアテーブルにpickupデータフレームを書き込みます
# データベースを適宜変更してください
fs.write_table(
name="feature_store_taxi_example_takaaki_yayoi.trip_pickup_features",
df=pickup_features_df,
mode="merge",
)
# dropoff_features特徴量グループを計算します
dropoff_features_df = dropoff_features_fn(
df=raw_data,
ts_column="tpep_dropoff_datetime",
start_date=datetime(2016, 2, 1),
end_date=datetime(2016, 2, 29),
)
# 特徴量ストアテーブルにdropoffデータフレームを書き込みます
# データベースを適宜変更してください
fs.write_table(
name="feature_store_taxi_example_takaaki_yayoi.trip_dropoff_features",
df=dropoff_features_df,
mode="merge",
)
書き込む際、mergeとoverwriteモードの両方がサポートされています。
fs.write_table(
name="feature_store_taxi_example_takaaki_yayoi.trip_pickup_features",
df=pickup_features_df,
mode="overwrite",
)
また、df.isStreamingがTreuに設定されたデータフレームを渡すことでFeature Storeにストリーミングすることができます:
fs.write_table(
name="feature_store_taxi_example_takaaki_yayoi.streaming_features",
df=streaming_df,
mode="merge",
)
Databricks Jobs (AWS|Azure|GCP)を用いて特徴量を定期的に更新する様にノートブックをスケジューリングすることができます。
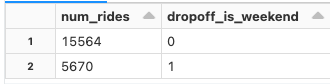
以下の様に、アナリストはSQLを用いてFeature Storeとやり取りすることができます:
%sql
-- データベースを適宜変更してください
SELECT SUM(count_trips_window_30m_dropoff_zip) AS num_rides,
dropoff_is_weekend
FROM feature_store_taxi_example_takaaki_yayoi.trip_dropoff_features
WHERE dropoff_is_weekend IS NOT NULL
GROUP BY dropoff_is_weekend;
特徴量の検索と発見
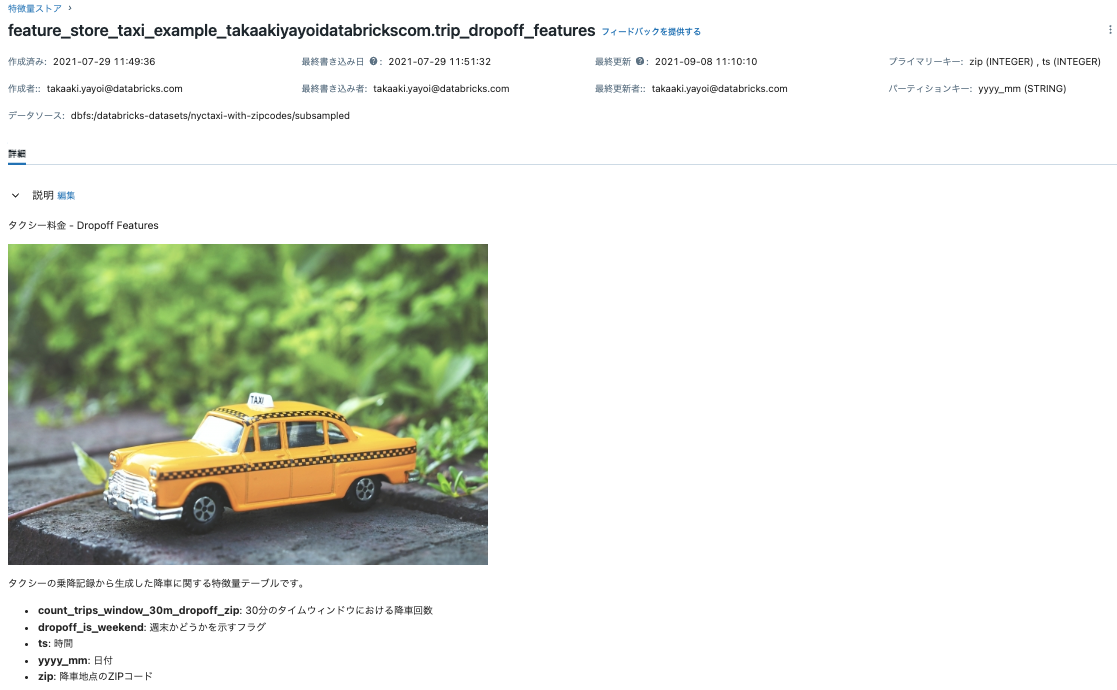
Feature Store UIを用いて特徴量テーブルを発見することができます。"trip_pickup_features"や"trip_dropoff_features"で検索を行い、テーブルスキーマ、メタデータ、データソース、プロデューサー、オンラインストアの様な詳細を参照するためにテーブル名をクリックします。特徴量の検索と、特徴量リネージュの追跡に関しては、(AWS|Azure|GCP)をご覧ください。
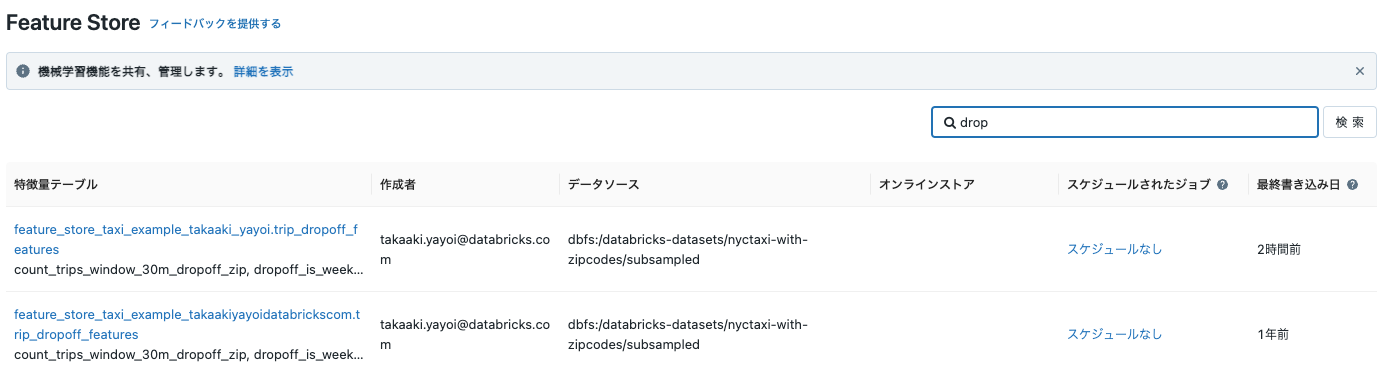
また、Feature Store UIで特徴量テーブルのアクセス権を設定することができます。(AWS|Azure|GCP)をご覧ください。
モデルのトレーニング
このセクションでは、Feature Storeに格納されたpickup、dropoff特徴量を用いてどのようにモデルをトレーニングするのかを説明します。タクシー料金を予測するためにLightGBMモデルをトレーニングします。
ヘルパー関数
from pyspark.sql import *
from pyspark.sql.functions import current_timestamp
from pyspark.sql.types import IntegerType
import math
from datetime import timedelta
import mlflow.pyfunc
def rounded_unix_timestamp(dt, num_minutes=15):
"""
datetimeのdtをintervalのnum_minutesに切り上げ、unixタイムスタンプを返却します。
"""
nsecs = dt.minute * 60 + dt.second + dt.microsecond * 1e-6
delta = math.ceil(nsecs / (60 * num_minutes)) * (60 * num_minutes) - nsecs
return int((dt + timedelta(seconds=delta)).timestamp())
rounded_unix_timestamp_udf = udf(rounded_unix_timestamp, IntegerType())
def rounded_taxi_data(taxi_data_df):
# タクシーデータのタイムスタンプを15分と30分のインターバルに丸め、pickupとdropoffの特徴量をそれぞれjoinできるようにします
taxi_data_df = (
taxi_data_df.withColumn(
"rounded_pickup_datetime",
rounded_unix_timestamp_udf(taxi_data_df["tpep_pickup_datetime"], lit(15)),
)
.withColumn(
"rounded_dropoff_datetime",
rounded_unix_timestamp_udf(taxi_data_df["tpep_dropoff_datetime"], lit(30)),
)
.drop("tpep_pickup_datetime")
.drop("tpep_dropoff_datetime")
)
taxi_data_df.createOrReplaceTempView("taxi_data")
return taxi_data_df
def get_latest_model_version(model_name):
latest_version = 1
mlflow_client = MlflowClient()
for mv in mlflow_client.search_model_versions(f"name='{model_name}'"):
version_int = int(mv.version)
if version_int > latest_version:
latest_version = version_int
return latest_version
トレーニングのためにタクシーデータを読み込み
taxi_data = rounded_taxi_data(raw_data)
どの様にトレーニングデータセットが作成されるのかを理解する
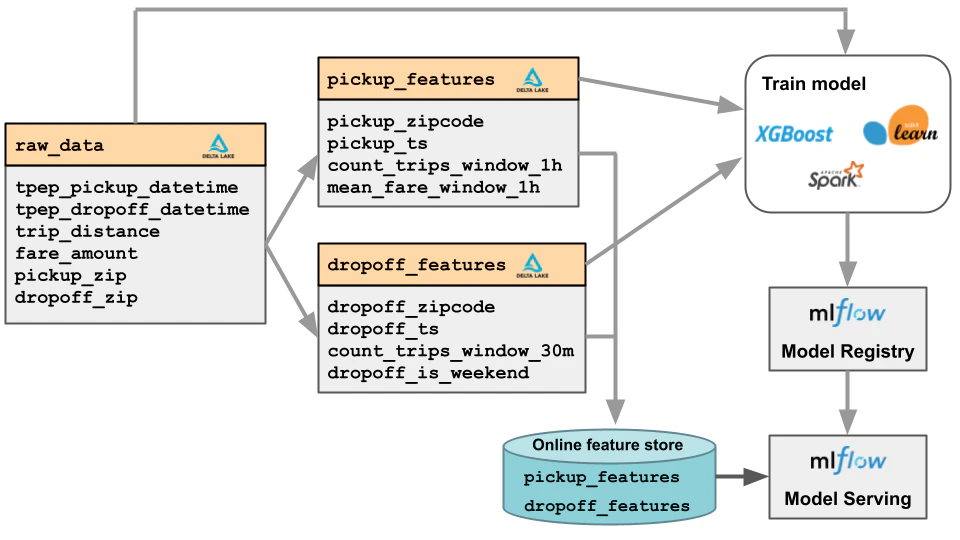
モデルをトレーニングするには、モデルのトレーニングに使用されるトレーニングデータセットを作成する必要があります。トレーニングデータセットは以下から構成されます:
- 生の入力データ
- 特徴量ストアの特徴量
生の入力データは以下を含んでいるので必要になります:
- 特徴量とjoinするために使用される主キー。
- 特徴量ストアにない
trip_distanceのような生の特徴量。 - モデルトレーニングに必要な
fareのような予測ターゲット。
以下の図は、トレーニングデータセットを作成するために、Feature Storeの特徴量と生の入力データが組み合わされる様子をビジュアルで示したものです。

これらのコンセプトは、トレーニングデータセットの作成に関するドキュメントでさらに説明されています(AWS|Azure|GCP)。
次のセルでは、必要な特徴量それぞれにFeatureLookupを作成することで、モデルをトレーニングするための特徴量をFeature Storeからロードしています。
from databricks.feature_store import FeatureLookup
import mlflow
# データベースは適宜変更してください
pickup_features_table = "feature_store_taxi_example_takaaki_yayoi.trip_pickup_features"
dropoff_features_table = "feature_store_taxi_example_takaaki_yayoi.trip_dropoff_features"
pickup_feature_lookups = [
FeatureLookup(
table_name = pickup_features_table,
feature_names = ["mean_fare_window_1h_pickup_zip", "count_trips_window_1h_pickup_zip"],
lookup_key = ["pickup_zip", "rounded_pickup_datetime"],
),
]
dropoff_feature_lookups = [
FeatureLookup(
table_name = dropoff_features_table,
feature_names = ["count_trips_window_30m_dropoff_zip", "dropoff_is_weekend"],
lookup_key = ["dropoff_zip", "rounded_dropoff_datetime"],
),
]
トレーニングデータセットの作成
以下でfs.create_training_set(..)が呼び出されると、以下のステップが実行されます:
- モデルのトレーニングで使用するFeature Storeからの特定の特徴量を選択する
TrainingSetオブジェクトが作成されます。それぞれの特徴量は、上で作成したFeatureLookupで指定されます。 - それぞれの
FeatureLookupのlookup_keyに沿って、生の入力データと特徴量がjoinされます。
そして、TrainingSetはトレーニングするデータフレームに変換されます。このデータフレームにはtaxi_dataのカラムと、FeatureLookupsで指定された特徴量が含まれます。
# すべての既存のランを終了 (このノートブックの実行が二回目の場合)
mlflow.end_run()
# 特徴量ストアがモデルを記録するために必要なmlflowランをスタート
mlflow.start_run()
# 追加の特徴量エンジニアリングを実行しない場合、丸められたタイムスタンプのカラムはデータの過学習を引き起こす可能性があるので、これらをトレーニングしない様に除外します
exclude_columns = ["rounded_pickup_datetime", "rounded_dropoff_datetime"]
# 生の入力データと対応する両方の特徴量テーブルからの特徴量を含むトレーニングセットを作成します
training_set = fs.create_training_set(
taxi_data,
feature_lookups = pickup_feature_lookups + dropoff_feature_lookups,
label = "fare_amount",
exclude_columns = exclude_columns
)
# TrainingSetをモデルトレーニングのためにsklearnに渡すことができるデータフレームにロードします
training_df = training_set.load_df()
# トレーニングデータフレームを表示します
# 生の入力データと`dropoff_is_weekend`のようにFeature Storeの特徴量が含まれていることに注意してください
display(training_df)
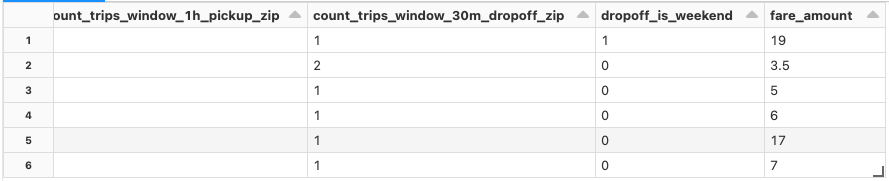
TrainingSet.load_dfによって返却されるデータに対してLightGBMモデルをトレーニングし、FeatureStoreClient.log_modelを用いてモデルを記録します。モデルは特徴量のメタデータと一緒にパッケージングされます。
from sklearn.model_selection import train_test_split
from mlflow.tracking import MlflowClient
import lightgbm as lgb
import mlflow.lightgbm
from mlflow.models.signature import infer_signature
features_and_label = training_df.columns
# トレーニングのためにデータをPandasのarrayに変換します
data = training_df.toPandas()[features_and_label]
train, test = train_test_split(data, random_state=123)
X_train = train.drop(["fare_amount"], axis=1)
X_test = test.drop(["fare_amount"], axis=1)
y_train = train.fare_amount
y_test = test.fare_amount
mlflow.lightgbm.autolog()
train_lgb_dataset = lgb.Dataset(X_train, label=y_train.values)
test_lgb_dataset = lgb.Dataset(X_test, label=y_test.values)
param = {"num_leaves": 32, "objective": "regression", "metric": "rmse"}
num_rounds = 100
# lightGBMモデルのトレーニング
model = lgb.train(
param, train_lgb_dataset, num_rounds
)
# MLflowを用いてトレーニングしたモデルを記録し、特徴量検索情報と一緒にパッケージングします
fs.log_model(
model,
artifact_path="model_packaged",
flavor=mlflow.lightgbm,
training_set=training_set,
registered_model_name="taxi_example_fare_packaged"
)

カスタムPyFuncモデルの構築および記録
モデルに前処理、後処理を追加し、バッチ推論で処理された予測結果を生成するために、これらのメソッドをカプセル化するカスタムPyFuncのMLflowモデルを作成することができます。以下のセルでは、モデルの数値の予測結果に基づいて文字列を出力するサンプルを示しています。
class fareClassifier(mlflow.pyfunc.PythonModel):
def __init__(self, trained_model):
self.model = trained_model
def preprocess_result(self, model_input):
return model_input
def postprocess_result(self, results):
'''後処理の結果を返却します。
料金レンジのセット作成し、予測されたレンジを返却します。'''
return ["$0 - $9.99" if result < 10 else "$10 - $19.99" if result < 20 else " > $20" for result in results]
def predict(self, context, model_input):
processed_df = self.preprocess_result(model_input.copy())
results = self.model.predict(processed_df)
return self.postprocess_result(results)
pyfunc_model = fareClassifier(model)
# 新たなpyfuncモデルを記録するために、現在のMLflowランを終了し、新しいランをスタートします
mlflow.end_run()
with mlflow.start_run() as run:
fs.log_model(
pyfunc_model,
"pyfunc_packaged_model",
flavor=mlflow.pyfunc,
training_set=training_set,
registered_model_name="pyfunc_taxi_fare_packaged",
)
スコアリング: バッチ推論
別のデータサイエンティストがこのモデルを別のバッチデータに適用したいものとします。
new_taxi_data = rounded_taxi_data(raw_data)
推論に使うデータを表示し、予測ターゲットであるfare_amountカラムをハイライトする様に並び替えます。
cols = ['fare_amount', 'trip_distance', 'pickup_zip', 'dropoff_zip', 'rounded_pickup_datetime', 'rounded_dropoff_datetime']
new_taxi_data_reordered = new_taxi_data.select(cols)
display(new_taxi_data_reordered)

バッチデータに対してモデルを評価するためにscore_batch APIを使い、Feature Storeから必要な特徴量を取得します。
# モデルURIの取得
latest_model_version = get_latest_model_version("taxi_example_fare_packaged")
model_uri = f"models:/taxi_example_fare_packaged/{latest_model_version}"
# モデルから予測結果を取得するために score_batch を呼び出します
with_predictions = fs.score_batch(model_uri, new_taxi_data)
記録されたPyFuncモデルを用いてスコアリングを行います。
latest_pyfunc_version = get_latest_model_version("pyfunc_taxi_fare_packaged")
pyfunc_model_uri = f"models:/pyfunc_taxi_fare_packaged/{latest_pyfunc_version}"
pyfunc_predictions = fs.score_batch(pyfunc_model_uri,
new_taxi_data,
result_type='string')

タクシー料金の予測結果を参照
このコードでは、最初のカラムにタクシー料金の予測値を表示する様にカラムを並び替えています。モデル精度を改善するには、さらなるデータや特徴量エンジニアリングが必要となるかもしれませんが、predicted_fare_amountが概ね実際のfare_amountに近い値になっていることに注意してください。
import pyspark.sql.functions as func
cols = ['prediction', 'fare_amount', 'trip_distance', 'pickup_zip', 'dropoff_zip',
'rounded_pickup_datetime', 'rounded_dropoff_datetime', 'mean_fare_window_1h_pickup_zip',
'count_trips_window_1h_pickup_zip', 'count_trips_window_30m_dropoff_zip', 'dropoff_is_weekend']
with_predictions_reordered = (
with_predictions.select(
cols,
)
.withColumnRenamed(
"prediction",
"predicted_fare_amount",
)
.withColumn(
"predicted_fare_amount",
func.round("predicted_fare_amount", 2),
)
)
display(with_predictions_reordered)

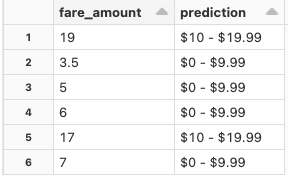
PyFuncの予測結果の参照
display(pyfunc_predictions.select('fare_amount', 'prediction'))
次のステップ
- Feature Store UIで、このサンプルで作成された特徴量テーブルを探索する。
- このノートブックをご自身のデータに対応させ、ご自身の特徴量テーブルを作成する。