テーブルの一覧の取得は簡単です。
SQL
SHOW TABLES;
しかし、上の結果から得られるテーブル一覧に含まれるテーブルのカラム情報も含めてデータとして取得したいとなると話は複雑になります。
本書では、Hiveメタストアのテーブルとそれらテーブルのカラム名、データ型を格納するデータフレームを作成する方法を説明します。
なお、Unity Catalogでは、同様に機能を利用できるInformation schemaがサポートされています。
情報スキーマ - Azure Databricks | Microsoft Learn
SparkのCatalog.listColumsというメソッドを使用してテーブルのカラム名、データ型を取得します。SQLのDESCRIBE TABLEを使う方法もありますが、パーティション情報など今回不要なデータが入ってしまうのでここでは使いません。
Catalog.listColumsのスキーマは以下の様になりますので、スキーマを定義しておきます。
root
|-- name: string (nullable = true)
|-- description: string (nullable = true)
|-- dataType: string (nullable = true)
|-- nullable: boolean (nullable = true)
|-- isPartition: boolean (nullable = true)
|-- isBucket: boolean (nullable = true)
Python
from pyspark.sql.types import *
schema = StructType([
StructField("name", StringType(), True),
StructField("description", StringType(), True),
StructField("dataType", StringType(), True),
StructField("nullable", BooleanType(), True),
StructField("isPartition", BooleanType(), True),
StructField("isBucket", BooleanType(), True)
])
以下の処理を実行することで、テーブル一覧を取得し、一覧に含まれるテーブルごとにspark.catalog.listColumnsを実行します。そして、結果を一つのデータフレームにunionしていきます。
Python
from pyspark.sql.functions import *
# データベース名
schemaName = "default"
spark.sql(f"USE {schemaName}")
# テーブル一覧を取得
tables_df = spark.sql("SHOW TABLES")
df = tables_df.select("TableName")
list = [x["TableName"] for x in df.collect()]
count = 0
# テーブルに対するループ
for targetTable in list:
print("targetTable:", targetTable)
# 物理ファイルがない場合などではスキーマ取得に失敗するのでtry-catchしています
try:
table_schema_df = spark.createDataFrame(spark.catalog.listColumns(targetTable, schemaName), schema=schema)
# テーブル名を追加
table_schema_df = table_schema_df.withColumn("tableName", lit(targetTable))
if count == 0:
return_df = table_schema_df
else:
return_df = return_df.union(table_schema_df)
count = count + 1
except:
pass
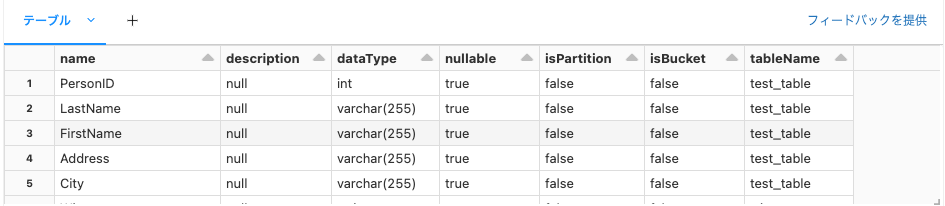
display(return_df)
これで、テーブル名とカラム情報が格納されたデータフレームを手に入れることができます。
参考資料
- How to see all the databases and Tables in Data...anycodings
- pyspark.sql.Catalog.listColumns — PySpark 3.3.0 documentation