2024/4/12に翔泳社よりApache Spark徹底入門を出版します!

書籍のサンプルノートブックをウォークスルーしていきます。Python/Chapter07/7-5 Caching Dataとなります。
翻訳ノートブックのリポジトリはこちら。
ノートブックはこちら
cache() の使用
いくつかのカラムを持つ大規模データセットを作成します。
from pyspark.sql.functions import col
df = spark.range(1 * 10000000).toDF("id").withColumn("square", col("id") * col("id"))
df.cache().count()
10000000
どこにデータが格納されるのかを確認するためにSpark UIのstorageタブをチェックします。
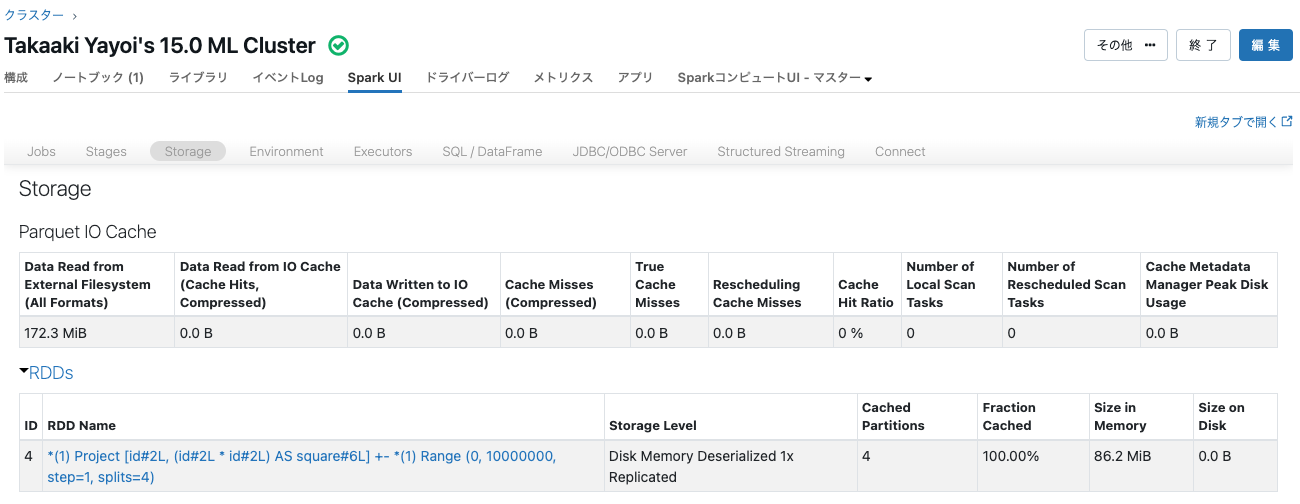
Disk Memory Deserialized 1x Replicatedとなっています。
df.unpersist() # unpersistしない場合、下のdf2はdfと同じクエリープランであるためdf2はキャッシュされません
persist(StorageLevel.Level) の使用
from pyspark import StorageLevel
df2 = spark.range(1 * 10000000).toDF("id").withColumn("square", col("id") * col("id"))
df2.persist(StorageLevel.DISK_ONLY).count()
df2.count()
10000000
データがどこに格納されているのかを確認するためにSpark UIのStorageタブをチェックします。
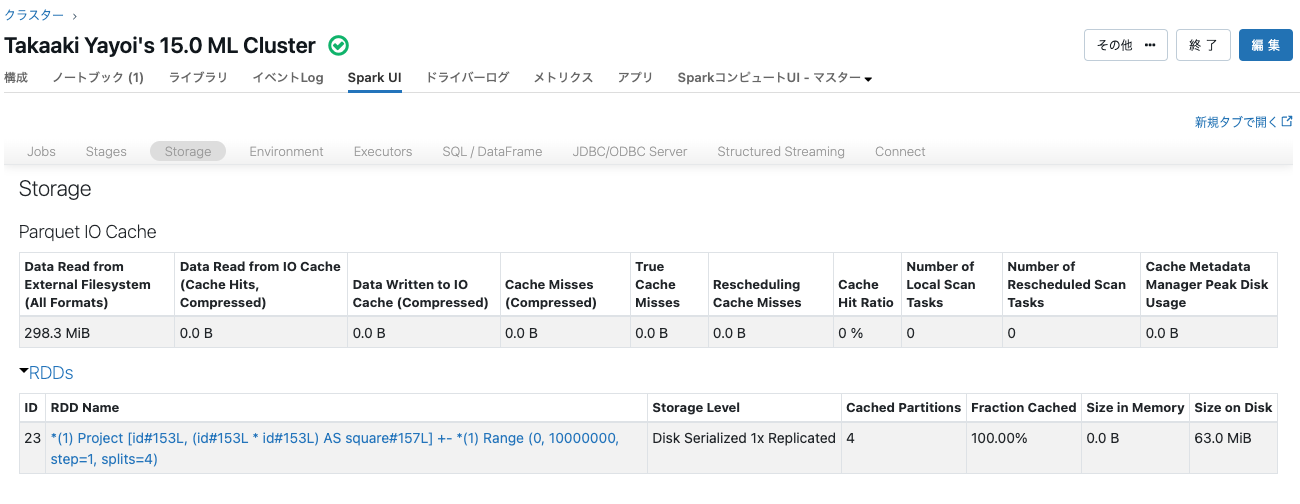
Disk Deserialized 1x Replicatedとなっています。
SQLでのキャッシュ
df.createOrReplaceTempView("dfTable")
spark.sql("CACHE TABLE dfTable")
どこにデータが格納されるのかを確認するためにSpark UIのstorageタブをチェックします。
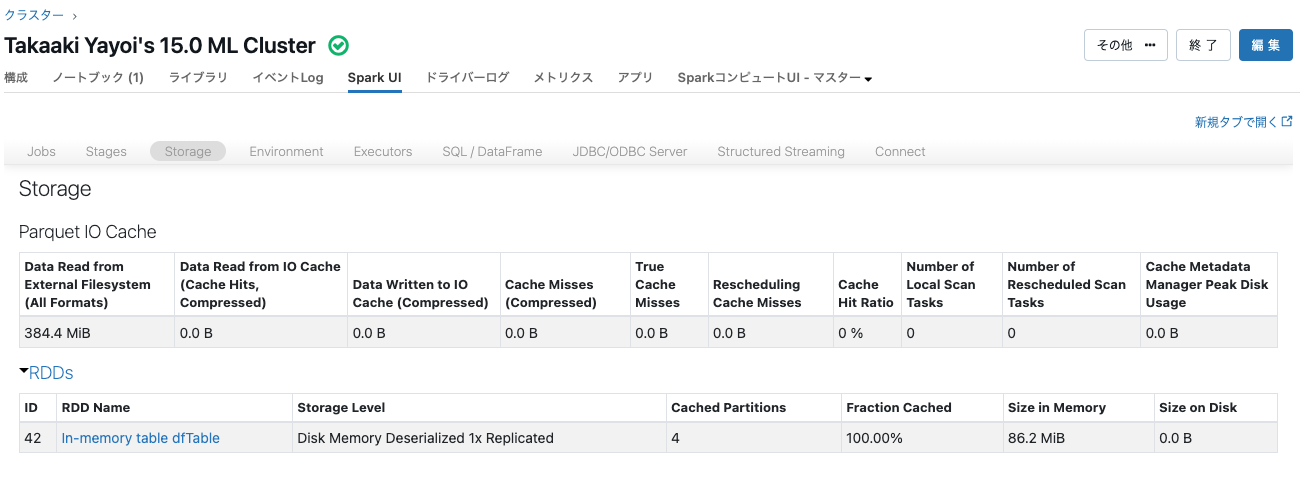
In-memory table dfTableがキャッシュされています。
spark.sql("SELECT count(*) FROM dfTable").show()
+--------+
|count(1)|
+--------+
|10000000|
+--------+