個人的にはLLMのバッチ推論にユースケースの可能性を感じています。なぜなら、以下のブログ記事で触れているように、多くの企業ではバッチ処理を適用できるようなテキストを格納しているテーブルがあるからです。
Databricksで提供しているこちらの機能をサンプルノートブックで試していきます。
プロビジョニングされたスループットエンドポイントを使用したバッチ推論
このノートブックは、大規模なバッチ推論ワークロードのためにプロビジョニングされたスループットエンドポイントを設定し、ai_queryを使用して行を処理します。
要件
続行する前に、以下が必要です:
- 次のいずれかの構成を持つコンピュート:
- オールパーパスコンピュート:
- コンピュートサイズ i3.2xlarge 以上。
- Databricks DBR 15.4 LTS。
- 少なくとも2つのワーカーを持つマルチノード。
- SQL ウェアハウス:
- SQL ウェアハウス Medium 以上。
- オールパーパスコンピュート:
- Databricks Unity Catalog に登録された大規模言語モデル (LLM)。
以下のいずれかを行うことができます:
パラメータリファレンス
| パラメータ名 | 値の例 | 説明 |
|---|---|---|
model_uc_path |
system.ai.meta_llama_v3_1_70b | バッチ推論に使用するUnity CatalogのDatabricksモデルの名前。最新バージョンのモデルが使用されます。 |
prompt |
提供されたZIPコードに対応する米国の州名を教えてください。 | 推論に使用するプロンプト。各入力行はこのプロンプトに連結されます。 |
request_params |
{"max_tokens": 1000, "temperature": 0} | 推論に使用するリクエストパラメータ。 |
input_table_name |
samples.nyctaxi.trips | Unity Catalogの入力テーブルの名前。 |
input_column_name |
pickup_zip | 入力テーブルで使用される列の名前。 |
output_table_name |
main.default.batch_nyctaxi_trips | Unity Catalogの出力テーブルの名前。出力テーブルの既存の行は上書きされます。 |
output_column_name |
state_name | 生成されたデータを格納する出力テーブルの列の名前。 |
endpoint_name |
llama_batch_inference | (オプション) 作成されるプロビジョニングされたスループットエンドポイントの名前。 |
model_uc_version |
2 | (オプション) 使用するUnity CatalogのDatabricksモデルのバージョン。指定しない場合、最新バージョンのモデルが使用されます。 |
input_num_rows |
100000 | (オプション) 処理するinput_table_nameの行数。空の場合、input_table_nameのすべての行が処理されます。 |
%pip install transformers
dbutils.library.restartPython()
import requests, json, math, os, time, uuid
import numpy as np
import pandas as pd
from pyspark.sql.functions import col, rand
# ウィジェットの設定
dbutils.widgets.text("model_uc_path", "system.ai.meta_llama_v3_1_70b_instruct", "Model UC Path")
dbutils.widgets.text("input_table_name", "samples.nyctaxi.trips", "Input Table Name")
dbutils.widgets.text("input_column_name", "pickup_zip", "Input Column Name")
dbutils.widgets.text("output_table_name", "main.default.batch_nyctaxi_trips", "Output Table Name")
dbutils.widgets.text("output_column_name", "state_name", "Output Column Name")
dbutils.widgets.text("prompt", "Could you tell me the state name of the zip code provided? zip code: ", "Prompt")
dbutils.widgets.text("request_params", '{"max_tokens": 1000, "temperature": 0}', "Request Parmaeters")
dbutils.widgets.text("endpoint_name", "", "(optional) Endpoint Name")
dbutils.widgets.text("model_uc_version", "", "(optional) Model Version")
dbutils.widgets.text("input_num_rows", "", "(optional) Input Number of Rows")
# パラメータの取得
model_uc_path = dbutils.widgets.get("model_uc_path")
input_table_name = dbutils.widgets.get("input_table_name")
input_column_name = dbutils.widgets.get("input_column_name")
output_table_name = dbutils.widgets.get("output_table_name")
output_column_name = dbutils.widgets.get("output_column_name")
prompt = dbutils.widgets.get("prompt")
request_params = dbutils.widgets.get("request_params")
endpoint_name = dbutils.widgets.get("endpoint_name")
model_uc_version = dbutils.widgets.get("model_uc_version")
input_num_rows = dbutils.widgets.get("input_num_rows")
# パラメータの検証
assert model_uc_path.count(".") == 2, "model_uc_pathはcatalog.schema.model_nameの形式である必要があります"
assert input_table_name.count(".") == 2, "input_table_nameはcatalog.schema.tableの形式である必要があります"
assert input_column_name, "input_column_nameは空にできません"
assert output_table_name.count(".") == 2, "output_table_nameはcatalog.schema.tableの形式である必要があります"
assert output_column_name, "output_column_nameは空にできません"
try:
request_params = json.loads(dbutils.widgets.get("request_params"))
except:
assert False, "request_paramsは有効なjsonである必要があります"
if model_uc_version:
assert model_uc_version.isdigit(), "model_uc_versionは数字である必要があります"
model_uc_version = int(model_uc_version)
assert model_uc_version >= 1, "model_uc_versionは正の整数である必要があります"
if input_num_rows:
assert input_num_rows.isdigit(), "input_num_rowsは数字である必要があります"
input_num_rows = int(input_num_rows)
assert input_num_rows >= 1, "input_num_rowsは正の整数である必要があります"
ノートブックの上部にウィジェットが表示されます。

パート1: プロビジョニングされたスループットエンドポイントの作成
これはバッチ推論のための大規模なプロビジョニングされたスループットエンドポイントを作成します。エンドポイントのサイズはPTU(プロビジョニングされたスループットユニット)で指定されます。バッチ推論が完了した後、エンドポイントは停止されます。
from mlflow.utils.databricks_utils import get_databricks_host_creds, get_workspace_url
host = get_databricks_host_creds("databricks").host
assert host, "ホストURLを取得できません"
def getHeaders():
credentials = get_databricks_host_creds("databricks")
return {
"Authorization": f"Bearer {credentials.token}",
"Content-Type": "application/json",
}
def create_endpoint(name, model_name, model_version, pt):
data = {
"name": name,
"config": {
"served_entities": [
{
"entity_name": model_name,
"entity_version": model_version,
"min_provisioned_throughput": pt,
"max_provisioned_throughput": pt,
}
]
},
}
response = requests.post(
url=f"{host}/api/2.0/serving-endpoints", json=data, headers=getHeaders()
)
print(json.dumps(response.json(), indent=4))
def monitor_endpoint(name):
# エンドポイントが準備完了になるまで監視します。これには数分かかる場合があります。
start_time = time.time()
timeout = 2 * 60 * 60
while True:
response = requests.get(
url=f"{host}/api/2.0/serving-endpoints/{name}", headers=getHeaders()
)
if response.status_code == 404:
raise Exception(f"エンドポイント {name} が見つかりません")
elif response.status_code != 200:
print(f"リクエストがステータス {response.status_code} で失敗しました, {response.text}")
else:
serving_endpoint = response.json()
state = serving_endpoint["state"]
if state["ready"] == "READY" and state["config_update"] == "NOT_UPDATING":
print(f"エンドポイント {name} は準備完了です")
break
else:
print(f"エンドポイント {name} は準備ができていません, 状態: {state}")
time.sleep(30)
if time.time() - start_time > timeout:
raise Exception(f"エンドポイント {name} の作成がタイムアウトしました")
バッチ推論エンドポイントのサイズをPTUで設定します。PTUを増やすと推論スループットが向上します。GPU容量の制限により、エンドポイントの作成時にエラーが発生した場合は、PTUの数を減らすことを検討してください。
私は上述のエラーに遭遇したので1にしています。
num_ptus = 1
# エンドポイントを構成する
if not model_uc_version:
model_versions = requests.get(
url=f"{host}/api/2.1/unity-catalog/models/{model_uc_path}/versions",
headers=getHeaders(),
).json()
model_uc_version = max(version['version'] for version in model_versions['model_versions'])
if not endpoint_name:
endpoint_name = str(uuid.uuid4())
optimizable_info = requests.get(
url=f"{host}/api/2.0/serving-endpoints/get-model-optimization-info/{model_uc_path}/{model_uc_version}",
headers=getHeaders(),
).json()
if "optimizable" not in optimizable_info or not optimizable_info["optimizable"]:
raise ValueError(
f"モデル {model_uc_path} バージョン {model_uc_version} は存在しないか、プロビジョニングスループットの対象ではありません"
)
chunk_size = optimizable_info["throughput_chunk_size"]
# エンドポイントを作成する
print(f"プロビジョニングスループットエンドポイントを作成中:")
print(f"エンドポイント: {endpoint_name}, モデル: {model_uc_path}, バージョン: {model_uc_version}")
print(f"同時実行数: {num_ptus*chunk_size} ({num_ptus} PTU)")
create_endpoint(endpoint_name, model_uc_path, model_uc_version, num_ptus*chunk_size)
monitor_endpoint(endpoint_name)
プロビジョニングスループットエンドポイントを作成中:
エンドポイント: taka_batch_endpoint, モデル: system.ai.meta_llama_v3_1_70b_instruct, バージョン: 3
同時実行数: 6000 (1 PTU)
{
"name": "taka_batch_endpoint",
"creator": "takaaki.yayoi@databricks.com",
"creation_timestamp": 1732152126000,
"last_updated_timestamp": 1732152126000,
"state": {
"ready": "NOT_READY",
"config_update": "IN_PROGRESS",
"suspend": "NOT_SUSPENDED"
},
"pending_config": {
"served_entities": [
{
"name": "meta_llama_v3_1_70b_instruct-3",
"entity_name": "system.ai.meta_llama_v3_1_70b_instruct",
"entity_version": "3",
"min_provisioned_throughput": 6000,
"max_provisioned_throughput": 6000,
"workload_size": "Small",
"workload_type": "GPU_XLARGE_8",
"min_dbus": 424.286,
"max_dbus": 424.286,
"state": {
"deployment": "DEPLOYMENT_CREATING",
"deployment_state_message": "Creating resources for served entity."
},
"creator": "takaaki.yayoi@databricks.com",
"creation_timestamp": 1732152126000
}
],
"served_models": [
{
"name": "meta_llama_v3_1_70b_instruct-3",
"min_provisioned_throughput": 6000,
"max_provisioned_throughput": 6000,
"workload_size": "Small",
"workload_type": "GPU_XLARGE_8",
"model_name": "system.ai.meta_llama_v3_1_70b_instruct",
"model_version": "3",
"min_dbus": 424.286,
"max_dbus": 424.286,
"state": {
"deployment": "DEPLOYMENT_CREATING",
"deployment_state_message": "Creating resources for served entity."
},
"creator": "takaaki.yayoi@databricks.com",
"creation_timestamp": 1732152126000
}
],
"traffic_config": {
"routes": [
{
"served_model_name": "meta_llama_v3_1_70b_instruct-3",
"traffic_percentage": 100,
"served_entity_name": "meta_llama_v3_1_70b_instruct-3"
}
]
},
"config_version": 1,
"start_time": 1732152126000
},
"id": "9731288b510d4d32a01445b4b3aed4c6",
"permission_level": "CAN_MANAGE",
"route_optimized": false,
"creator_display_name": "Takaaki Yayoi",
"creator_kind": "User"
}
エンドポイント taka_batch_endpoint は準備ができていません, 状態: {'ready': 'NOT_READY', 'config_update': 'IN_PROGRESS', 'suspend': 'NOT_SUSPENDED'}
エンドポイント taka_batch_endpoint は準備ができていません, 状態: {'ready': 'NOT_READY', 'config_update': 'IN_PROGRESS', 'suspend': 'NOT_SUSPENDED'}
エンドポイント taka_batch_endpoint は準備ができていません, 状態: {'ready': 'NOT_READY', 'config_update': 'IN_PROGRESS', 'suspend': 'NOT_SUSPENDED'}
エンドポイント taka_batch_endpoint は準備ができていません, 状態: {'ready': 'NOT_READY', 'config_update': 'IN_PROGRESS', 'suspend': 'NOT_SUSPENDED'}
エンドポイント taka_batch_endpoint は準備ができていません, 状態: {'ready': 'NOT_READY', 'config_update': 'IN_PROGRESS', 'suspend': 'NOT_SUSPENDED'}
エンドポイント taka_batch_endpoint は準備完了です
少し待つと、モデルサービングエンドポイントが稼働します。
パート2: バッチ推論に ai_query を使用する
以下は、プロビジョニングスループットエンドポイントをクエリして、データでバッチ推論を実行するための ai_query の設定です。
# ソーステーブルから読み込む
df = spark.table(input_table_name)
if input_num_rows:
df = df.limit(input_num_rows)
input_num_rows = df.count()
print(f"テーブル {input_table_name} には {input_num_rows} 行があります")
# (オプション) 入力データを前処理する
pass
最初は以下のパラメーターで実行します:
-
endpoint_name: taka_batch_endpoint -
input_table_name: samples.nyctaxi.trips -
input_column_name: pickup_zip -
output_table_name: takaakiyayoi_catalog.batch.batch_result -
output_column_name: state -
prompt: 提供されたZIPコードに対応する米国の州名を教えてください。
# バッチ推論に ai_query を使用する
model_params_str = "named_struct(" + ", ".join([f"'{k}', {v}" for k, v in request_params.items()]) + ")"
ai_query_expr = f"""ai_query('{endpoint_name}', CONCAT('{prompt}', {input_column_name}), modelParameters => {model_params_str}) as {output_column_name}"""
df_out = df.selectExpr(ai_query_expr)
# 出力テーブルに書き込む
df_out.write.mode("overwrite").option("mergeSchema", "true").saveAsTable(output_table_name)
郵便番号を判定していますが、元データがそもそもニューヨークのものしかないので、あまり面白くないです。
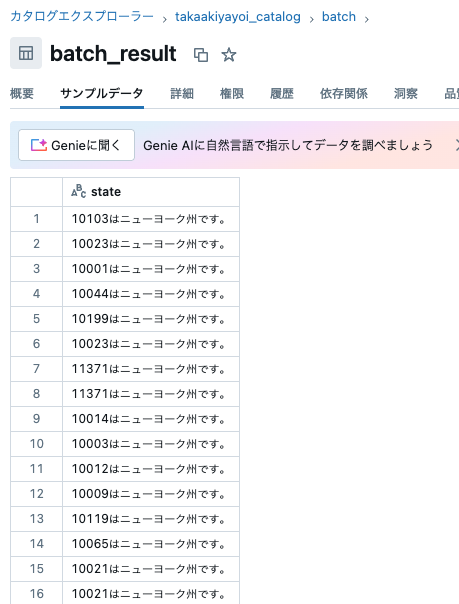
ソーステーブルを変更して、パラメーターを変更します。
-
endpoint_name: taka_batch_endpoint -
input_table_name: takaakiyayoi_catalog.qiita_2023.taka_qiita_2023 -
input_column_name: body -
output_table_name: takaakiyayoi_catalog.batch.summary_result -
output_column_name: summary -
prompt: 提供されたテキストを100字程度の要約にしてください
ソーステーブルはこのようになっています。

パラメーターの読み込みと、ai_queryの呼び出し部分のみを再度実行します。
# ウィジェットの設定
dbutils.widgets.text("model_uc_path", "system.ai.meta_llama_v3_1_70b_instruct", "Model UC Path")
dbutils.widgets.text("input_table_name", "samples.nyctaxi.trips", "Input Table Name")
dbutils.widgets.text("input_column_name", "pickup_zip", "Input Column Name")
dbutils.widgets.text("output_table_name", "main.default.batch_nyctaxi_trips", "Output Table Name")
dbutils.widgets.text("output_column_name", "state_name", "Output Column Name")
dbutils.widgets.text("prompt", "Could you tell me the state name of the zip code provided? zip code: ", "Prompt")
dbutils.widgets.text("request_params", '{"max_tokens": 1000, "temperature": 0}', "Request Parmaeters")
dbutils.widgets.text("endpoint_name", "", "(optional) Endpoint Name")
dbutils.widgets.text("model_uc_version", "", "(optional) Model Version")
dbutils.widgets.text("input_num_rows", "", "(optional) Input Number of Rows")
# パラメータの取得
model_uc_path = dbutils.widgets.get("model_uc_path")
input_table_name = dbutils.widgets.get("input_table_name")
input_column_name = dbutils.widgets.get("input_column_name")
output_table_name = dbutils.widgets.get("output_table_name")
output_column_name = dbutils.widgets.get("output_column_name")
prompt = dbutils.widgets.get("prompt")
request_params = dbutils.widgets.get("request_params")
endpoint_name = dbutils.widgets.get("endpoint_name")
model_uc_version = dbutils.widgets.get("model_uc_version")
input_num_rows = dbutils.widgets.get("input_num_rows")
# パラメータの検証
assert model_uc_path.count(".") == 2, "model_uc_pathはcatalog.schema.model_nameの形式である必要があります"
assert input_table_name.count(".") == 2, "input_table_nameはcatalog.schema.tableの形式である必要があります"
assert input_column_name, "input_column_nameは空にできません"
assert output_table_name.count(".") == 2, "output_table_nameはcatalog.schema.tableの形式である必要があります"
assert output_column_name, "output_column_nameは空にできません"
try:
request_params = json.loads(dbutils.widgets.get("request_params"))
except:
assert False, "request_paramsは有効なjsonである必要があります"
if model_uc_version:
assert model_uc_version.isdigit(), "model_uc_versionは数字である必要があります"
model_uc_version = int(model_uc_version)
assert model_uc_version >= 1, "model_uc_versionは正の整数である必要があります"
if input_num_rows:
assert input_num_rows.isdigit(), "input_num_rowsは数字である必要があります"
input_num_rows = int(input_num_rows)
assert input_num_rows >= 1, "input_num_rowsは正の整数である必要があります"
# ソーステーブルから読み込む
df = spark.table(input_table_name)
if input_num_rows:
df = df.limit(input_num_rows)
input_num_rows = df.count()
print(f"テーブル {input_table_name} には {input_num_rows} 行があります")
# (オプション) 入力データを前処理する
pass
# バッチ推論に ai_query を使用する
model_params_str = "named_struct(" + ", ".join([f"'{k}', {v}" for k, v in request_params.items()]) + ")"
ai_query_expr = f"""ai_query('{endpoint_name}', CONCAT('{prompt}', {input_column_name}), modelParameters => {model_params_str}) as {output_column_name}"""
df_out = df.selectExpr(ai_query_expr)
# 出力テーブルに書き込む
df_out.write.mode("overwrite").option("mergeSchema", "true").saveAsTable(output_table_name)
作成されたテーブルを確認します。期待した通りに要約が作成されています。
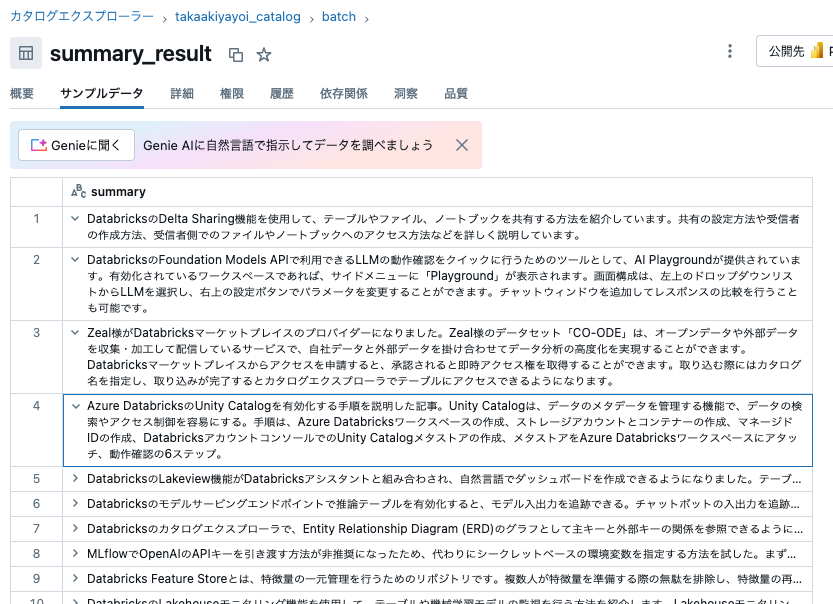
ソーステーブルと成し遂げたいことから、モデルの選択、プロンプトの定義をすることで、大量のテキストデータに様々な処理(要約、感情分析、翻訳、分類、情報抽出など)を迅速かつ容易に行う事ができます!是非ご活用ください。