こちらのノートブックをウォークスルーします。
以前にもオンラインテーブルには触れています。マニュアルはこちら。
注意
こちらの記事の執筆時点でオンラインテーブルがサポートされているリージョンは、Azureはwestus、 eastus、 eastus2、 northeurope、 westeurope、AWSではus-east-1、 us-west-2、 eu-west-1、 ap-southeast-1、 ap-southeast-2となっており、日本リージョンではまだサポートされていません。
以前は、モデルサービングエンドポイントにデプロイされているRAGから構造化データを取得するためにサービングされているオンラインテーブルにアクセスする流れを説明しました。
冒頭のノートブックはRAGとは関係なく、モデルサービングエンドポイントにデプロイされている従来型の機械学習モデルから特徴量にアクセスするためにオンラインテーブルを利用する流れが説明されています。
サンプルノートブックの翻訳したバージョンはこちらです。
オンライン特徴量ストアのサンプルノートブック
このノートブックは、Databricks Feature Storeを使用して、リアルタイムサービングと自動特徴量ルックアップのためにDatabricksオンラインテーブルに特徴量を公開する方法を示しています。問題は、さまざまな静的なワインの特徴量とリアルタイム入力を使用して、MLモデルでワインの品質を予測することです。
このノートブックは、IDとリアルタイム特徴量であるアルコール度数を与えられたワインボトルの品質を予測するエンドポイントを作成します。
ノートブックの構成は次のとおりです:
- 特徴量テーブルの準備。
- Databricks Online Tableのセットアップ。
- モデルのトレーニングとデプロイ。
- 自動特徴量ルックアップを使用したリアルタイムクエリの提供。
- クリーンアップ。
データセット
この例では、Wine Quality Data Setを使用します。
要件

%pip install databricks-sdk==0.41.0
%pip install databricks-feature-engineering==0.8.0
%pip install mlflow>=2.9.0
dbutils.library.restartPython()
特徴量テーブルの準備
wine_idだけでワインの品質を予測するエンドポイントを構築する必要があるとします。これには、エンドポイントがwine_idでワインの特徴を検索できるように、Feature Storeに保存された特徴量テーブルが必要です。このデモの目的のために、まずこの特徴量テーブルを自分で準備する必要があります。手順は次のとおりです:
- 生データを読み込み、クリーンアップする。
- 特徴量とラベルを分離する。
- 特徴量を特徴量テーブルに保存する。
生データの読み込みとクリーンアップ
生データには11の特徴量とquality列を含む12列があります。quality列は3から8の範囲の整数です。目標はquality値を予測するモデルを構築することです。
raw_data_frame = spark.read.load("/databricks-datasets/wine-quality/winequality-red.csv",format="csv",sep=";",inferSchema="true",header="true" )
display(raw_data_frame.limit(10))
| fixed acidity | volatile acidity | citric acid | residual sugar | chlorides | free sulfur dioxide | total sulfur dioxide | density | pH | sulphates | alcohol | quality |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 7.4 | 0.7 | 0 | 1.9 | 0.076 | 11 | 34 | 0.9978 | 3.51 | 0.56 | 9.4 | 5 |
| 7.8 | 0.88 | 0 | 2.6 | 0.098 | 25 | 67 | 0.9968 | 3.2 | 0.68 | 9.8 | 5 |
| 7.8 | 0.76 | 0.04 | 2.3 | 0.092 | 15 | 54 | 0.997 | 3.26 | 0.65 | 9.8 | 5 |
| 11.2 | 0.28 | 0.56 | 1.9 | 0.075 | 17 | 60 | 0.998 | 3.16 | 0.58 | 9.8 | 6 |
| 7.4 | 0.7 | 0 | 1.9 | 0.076 | 11 | 34 | 0.9978 | 3.51 | 0.56 | 9.4 | 5 |
| 7.4 | 0.66 | 0 | 1.8 | 0.075 | 13 | 40 | 0.9978 | 3.51 | 0.56 | 9.4 | 5 |
| 7.9 | 0.6 | 0.06 | 1.6 | 0.069 | 15 | 59 | 0.9964 | 3.3 | 0.46 | 9.4 | 5 |
| 7.3 | 0.65 | 0 | 1.2 | 0.065 | 15 | 21 | 0.9946 | 3.39 | 0.47 | 10 | 7 |
| 7.8 | 0.58 | 0.02 | 2 | 0.073 | 9 | 18 | 0.9968 | 3.36 | 0.57 | 9.5 | 7 |
| 7.5 | 0.5 | 0.36 | 6.1 | 0.071 | 17 | 102 | 0.9978 | 3.35 | 0.8 | 10.5 | 5 |
# 生データのサイズを確認します。
raw_data_frame.count(), len(raw_data_frame.columns)
(1599, 12)
生データにはいくつかの問題があります:
- 列名にスペース(' ')が含まれており、これはFeature Storeと互換性がありません。
- 後でFeature Storeで検索できるように、生データにIDを追加する必要があります。
次のセルでは、これらの問題に対処します。
Sparkデータフレームの前処理
from sklearn.preprocessing import MinMaxScaler
from pyspark.sql.functions import monotonically_increasing_id
# ID列を追加する関数
def addIdColumn(dataframe, id_column_name):
columns = dataframe.columns
new_df = dataframe.withColumn(id_column_name, monotonically_increasing_id())
return new_df[[id_column_name] + columns]
# 列名を変更する関数
def renameColumns(df):
renamed_df = df
for column in df.columns:
renamed_df = renamed_df.withColumnRenamed(column, column.replace(' ', '_'))
return renamed_df
# 列名をFeature Storeに対応するように変更
renamed_df = renameColumns(raw_data_frame)
# ID列を追加
id_and_data = addIdColumn(renamed_df, 'wine_id')
display(id_and_data)
| wine_id | fixed_acidity | volatile_acidity | citric_acid | residual_sugar | chlorides | free_sulfur_dioxide | total_sulfur_dioxide | density | pH | sulphates | alcohol | quality |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 7.4 | 0.7 | 0 | 1.9 | 0.076 | 11 | 34 | 0.9978 | 3.51 | 0.56 | 9.4 | 5 |
| 1 | 7.8 | 0.88 | 0 | 2.6 | 0.098 | 25 | 67 | 0.9968 | 3.2 | 0.68 | 9.8 | 5 |
| 2 | 7.8 | 0.76 | 0.04 | 2.3 | 0.092 | 15 | 54 | 0.997 | 3.26 | 0.65 | 9.8 | 5 |
| 3 | 11.2 | 0.28 | 0.56 | 1.9 | 0.075 | 17 | 60 | 0.998 | 3.16 | 0.58 | 9.8 | 6 |
| 4 | 7.4 | 0.7 | 0 | 1.9 | 0.076 | 11 | 34 | 0.9978 | 3.51 | 0.56 | 9.4 | 5 |
ワインが開封された後、アルコール度数は時間とともに変化する変数であると仮定します。この値はオンライン推論のためにリアルタイム入力として提供されます。
次に、データを2つに分割し、静的な特徴量を含む部分のみをFeature Storeに保存します。
# wine_idと静的特徴量
id_static_features = id_and_data.drop('alcohol', 'quality')
# wine_id、リアルタイム特徴量(alcohol)、ラベル(quality)
id_rt_feature_labels = id_and_data.select('wine_id', 'alcohol', 'quality')
特徴量テーブルを作成する
特徴量データ id_static_features を特徴量テーブルに保存します。
# カタログに対する `CREATE CATALOG` 権限が必要です。
# 必要に応じて、ここでカタログとスキーマ名を変更してください。
username = spark.sql("SELECT current_user()").first()["current_user()"]
username = username.split(".")[0]
# 既存のカタログを使います
catalog_name = "users"
# スキーマ名として使用するユーザー名を取得します。
schema_name = "takaaki_yayoi"
#spark.sql(f"CREATE CATALOG IF NOT EXISTS {catalog_name}")
spark.sql(f"USE CATALOG {catalog_name}")
#spark.sql(f"CREATE DATABASE IF NOT EXISTS {catalog_name}.{schema_name}")
spark.sql(f"USE SCHEMA {schema_name}")
from databricks.feature_engineering import FeatureEngineeringClient
wine_table = f"{catalog_name}.{schema_name}.wine_static_features"
online_table_name = f"{catalog_name}.{schema_name}.wine_static_features_online"
fe = FeatureEngineeringClient()
fe.create_table(
name=wine_table,
primary_keys=["wine_id"],
df=id_static_features,
description="すべてのワインのIDと特徴量",
)
特徴量データは特徴量テーブルに保存されました。次のステップは、Databricksオンラインテーブルを設定することです。
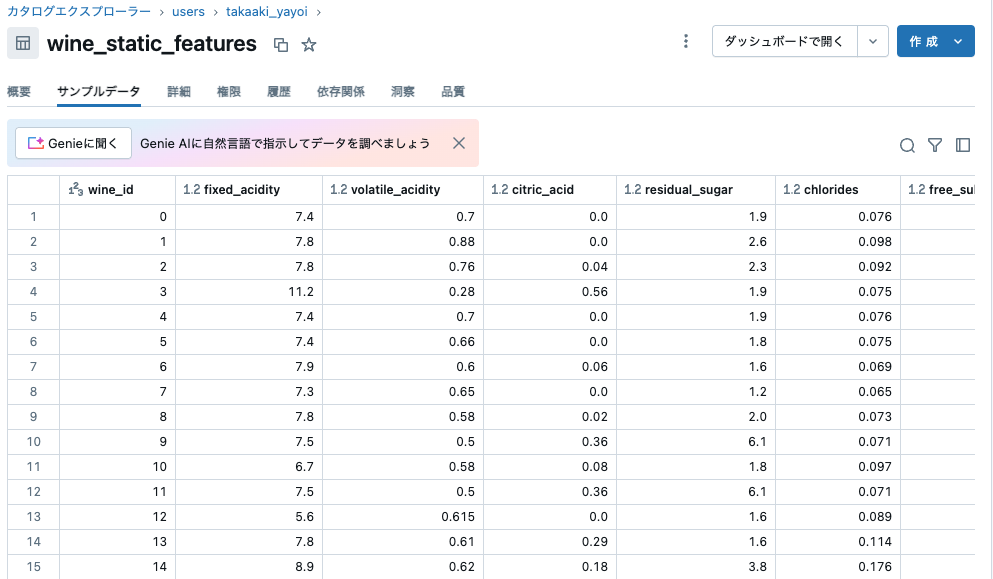
Databricksオンラインテーブルの設定
カタログエクスプローラーUI、Databricks SDK、またはRest APIからオンラインテーブルを作成できます。以下に、Databricks Python SDKを使用する手順を説明します。詳細については、Databricksのドキュメントを参照してください(AWS | Azure)。必要な権限については、権限に関する情報を参照してください(AWS | Azure)。
Databricksオンラインテーブルの作成
from pprint import pprint
from databricks.sdk import WorkspaceClient
from databricks.sdk.service.catalog import OnlineTable, OnlineTableSpec, OnlineTableSpecTriggeredSchedulingPolicy
workspace = WorkspaceClient()
# オンラインテーブルを作成
spec = OnlineTableSpec(
primary_key_columns = ["wine_id"],
source_table_full_name = wine_table,
run_triggered=OnlineTableSpecTriggeredSchedulingPolicy.from_dict({'triggered': 'true'}),
perform_full_copy=True)
online_table = OnlineTable(name=online_table_name, spec=spec)
try:
workspace.online_tables.create_and_wait(table=online_table)
except Exception as e:
if "already exists" in str(e):
print(f"オンラインテーブル {online_table_name} は既に存在します。再作成しません。")
else:
raise e
pprint(workspace.online_tables.get(online_table_name))
モデルのトレーニングとデプロイ
次に、Feature Storeの特徴量を使用して分類器をトレーニングします。主キーを指定するだけで、Feature Storeが必要な特徴量を取得します。
from sklearn.ensemble import RandomForestClassifier
import pandas as pd
import logging
import mlflow.sklearn
from databricks.feature_engineering import FeatureLookup
まず、TrainingSetを定義します。トレーニングセットはfeature_lookupsリストを受け取り、各アイテムはFeature Store内の特徴量テーブルからの特徴量を表します。この例では、wine_idをルックアップキーとして使用し、テーブルonline_feature_store_example.wine_featuresからすべての特徴量を取得します。
ワイン品質トレーニングローダー
# トレーニングセットを作成
training_set = fe.create_training_set(
df=id_rt_feature_labels,
label='quality',
feature_lookups=[
FeatureLookup(
table_name=f"{catalog_name}.{schema_name}.wine_static_features",
lookup_key="wine_id"
)
],
exclude_columns=['wine_id'],
)
# Feature Storeからトレーニングデータをロード
training_df = training_set.load_df()
display(training_df)
| alcohol | fixed_acidity | volatile_acidity | citric_acid | residual_sugar | chlorides | free_sulfur_dioxide | total_sulfur_dioxide | density | pH | sulphates | quality |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 10.1 | 11.5 | 0.18 | 0.51 | 4 | 0.104 | 4 | 23 | 0.9996 | 3.28 | 0.97 | 6 |
| 10.6 | 9.1 | 0.28 | 0.48 | 1.8 | 0.067 | 26 | 46 | 0.9967 | 3.32 | 1.04 | 6 |
| 10 | 7.6 | 0.42 | 0.08 | 2.7 | 0.084 | 15 | 48 | 0.9968 | 3.21 | 0.59 | 5 |
| 10.4 | 6.4 | 0.79 | 0.04 | 2.2 | 0.061 | 11 | 17 | 0.99588 | 3.53 | 0.65 | 6 |
| 11.9 | 6.2 | 0.7 | 0.15 | 5.1 | 0.076 | 13 | 27 | 0.99622 | 3.54 | 0.6 | 6 |
次のセルでは、RandomForestClassifierモデルをトレーニングします。
# トレーニングデータの特徴量とラベルを準備
X_train = training_df.drop('quality').toPandas()
y_train = training_df.select('quality').toPandas()
# モデルをトレーニング
model = RandomForestClassifier()
model.fit(X_train, y_train.values.ravel())
トレーニング済みモデルをlog_modelを使用して保存します。log_modelは、モデルと特徴量(training_setを通じて)の間の系統情報も保存します。そのため、サービング中にモデルはルックアップキーだけで特徴量をどこから取得するかを自動的に認識します。
MLflowへのモデル登録
import mlflow
mlflow.set_registry_uri("databricks-uc")
registered_model_name = f"{catalog_name}.{schema_name}.wine_classifier"
fe.log_model(
model=model,
artifact_path="model",
flavor=mlflow.sklearn,
training_set=training_set,
registered_model_name=registered_model_name
)
# 最新のモデルバージョンを取得
client = mlflow.tracking.MlflowClient()
versions = client.search_model_versions(f"name='{registered_model_name}'")
registered_model_version = max(int(v.version) for v in versions)
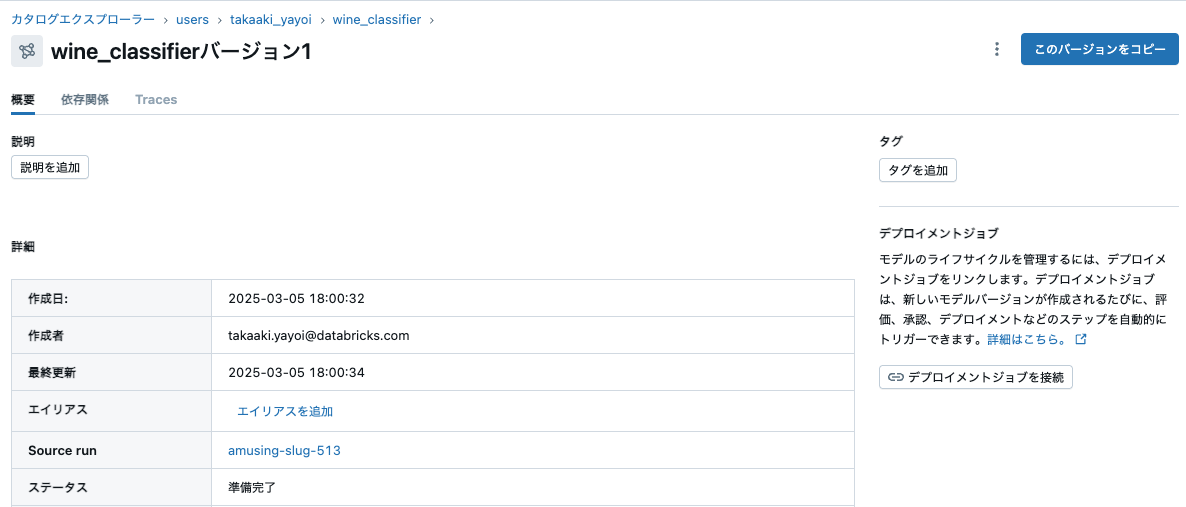
log_modelを呼び出した後、新しいバージョンのモデルが保存されます。このようにモデルを記録することで、特徴量とモデルの間のリネージがキャプチャされます。
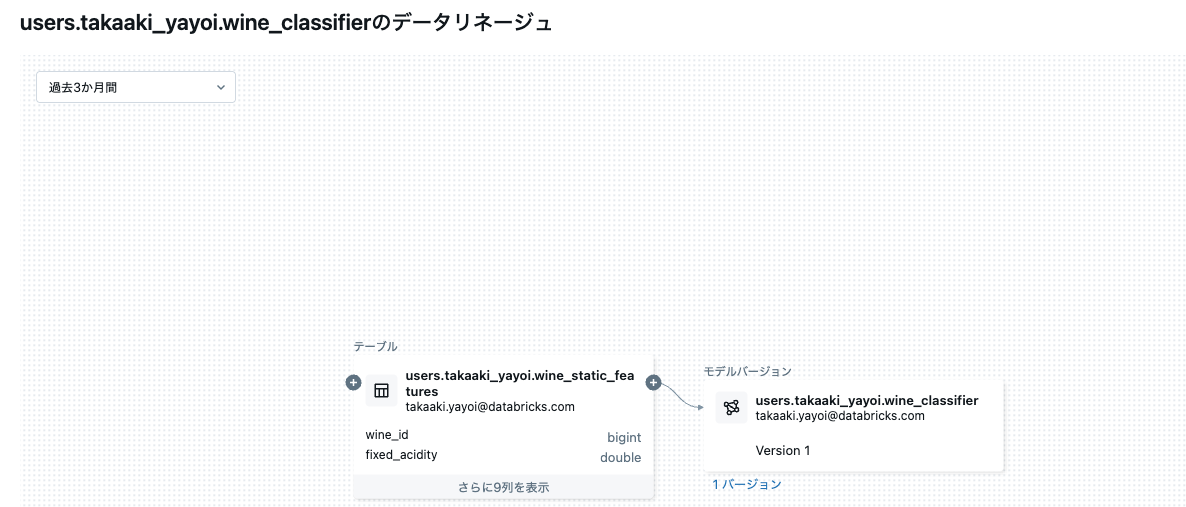
自動特徴量ルックアップを使用したリアルタイムクエリの提供
ワイン分類器のセットアップ
from databricks.sdk import WorkspaceClient
from databricks.sdk.service.serving import EndpointCoreConfigInput, ServedEntityInput
# エンドポイントを作成
endpoint_name = f"{username}_wine_classifier_endpoint"
try:
status = workspace.serving_endpoints.create_and_wait(
name=endpoint_name,
config = EndpointCoreConfigInput(
served_entities=[
ServedEntityInput(
entity_name=registered_model_name,
entity_version=registered_model_version,
scale_to_zero_enabled=True,
workload_size="Small"
)
]
)
)
print(status)
except Exception as e:
if "already exists" in str(e):
print(f"エンドポイント {endpoint_name} は既に存在するため、作成しません。")
else:
raise e
これでワイン分類器モデルがサービングされました。
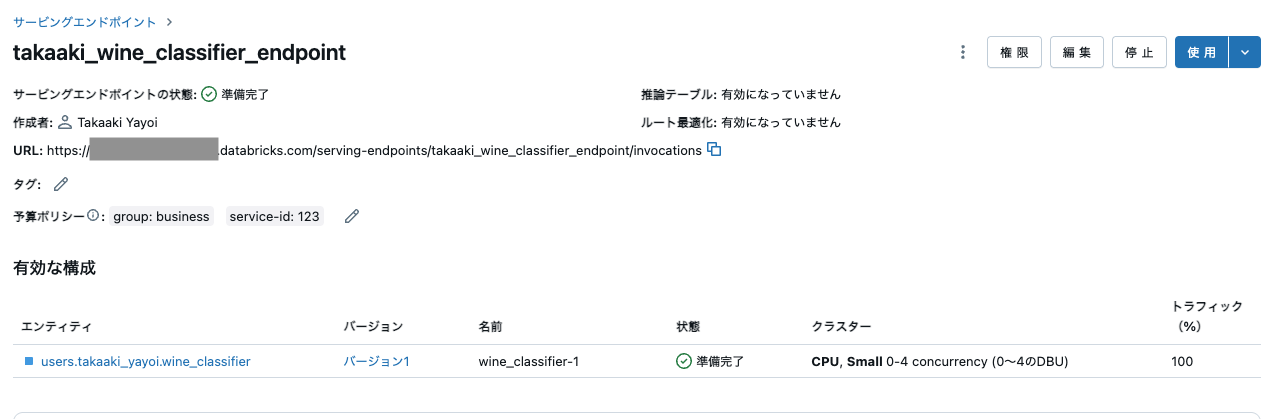
クエリを送信する
さて、ワインのボトルを開けて、ボトルから現在のアルコール度数を測定するセンサーがあるとします。モデルと自動特徴量ルックアップを使用したリアルタイムサービングを使用して、測定されたアルコール度数をリアルタイムの入力値alcoholとしてワインの品質を予測できます。
ワイン予測器の呼び出し
import mlflow.deployments
client = mlflow.deployments.get_deploy_client("databricks")
response = client.predict(
endpoint=endpoint_name,
inputs={
"dataframe_records": [
{"wine_id": 25, "alcohol": 7.9},
{"wine_id": 25, "alcohol": 11.0},
{"wine_id": 25, "alcohol": 27.9},
]
},
)
pprint(response)
{'predictions': [5, 5, 5]}
リクエスト形式とAPIバージョンに関する注意事項
リクエストフォーマットの例は以下の通りです:
{"dataframe_split": {"index": [0, 1, 2], "columns": ["wine_id", "alcohol"], "data": [[25, 7.9], [25, 11.0], [25, 27.9]]}}
Databricksモデルサービングの詳細はこちらをご覧ください(AWS|Azure)。
クリーンアップ
このノートブックで作成したリソースをクリーンアップするには、次の手順に従ってください:
- Catalog ExplorerからDatabricksオンラインテーブルを削除します。
a. 左側のサイドバーで、Catalogをクリックします。
b. オンラインテーブルに移動します。
c. ケバブメニューからDeleteを選択します。 -
Servingタブからサービングエンドポイントを削除します。
a. 左側のサイドバーで、Servingをクリックします。
b. エンドポイントの名前をクリックします。
c. ケバブメニューからDeleteを選択します。