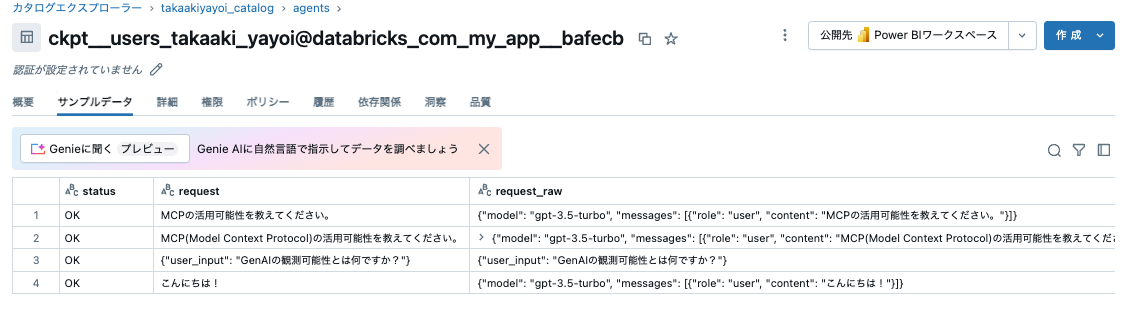
こちらのサンプルをウォークスルーします。
こちらで説明したのは、Databricks上でAgent Frameworkを使ってデプロイした生成AIエージェントの監視でした。
今回は、Databricks外にデプロイされた生成AIエージェントの監視をDatabricksで行う方法をウォークスルーします。
注意
執筆時点ではベータ版です。
外部モニターの設定
このノートブックはDatabricksワークスペースから実行するように設計されています。ローカルIDEから実行する.pyバージョンについてはドキュメントを参照してください。
%pip install -U "databricks-agents>=0.18.1" "mlflow>=2.21.2" "databricks-sdk[openai]"
dbutils.library.restartPython()
モニタが存在するMLflowエクスペリメントの設定
モニタリングUIはMLflowエクスペリメントのタブとして表示され、トレースへのACLはMLflowエクスペリメントのACLによって制御されます。アプリの本番コードでは、このexperiment_idを参照します。
import mlflow
# 現在のユーザー名を取得
user_email = spark.sql("SELECT current_user() as username").collect()[0].username
user = user_email.split("@")[0].replace(".", "").lower()[:35]
# 便宜上、これらを現在のノートブックから自動推測します。
# TODO: 本番環境およびノートブック外では、これらを明示的に設定してください。
MLFLOW_EXPERIMENT_NAME = "my_app_monitor"
MLFLOW_EXPERIMENT_PATH = f"/Users/{user_email}/{MLFLOW_EXPERIMENT_NAME}"
mlflow.set_experiment(MLFLOW_EXPERIMENT_PATH)
MLFLOW_EXPERIMENT_ID = mlflow.tracking.fluent._get_experiment_id()
# 現在のDatabricksワークスペースURLを取得
DATABRICKS_HOST = mlflow.utils.databricks_utils.get_workspace_url() # https://<workspace-url>.databricks.com
print(f"MLFLOW_EXPERIMENT_ID: {MLFLOW_EXPERIMENT_ID}")
print(f"MLFLOW_EXPERIMENT_PATH: {MLFLOW_EXPERIMENT_PATH}")
print(f"DATABRICKS_HOST: {DATABRICKS_HOST}")
print(f"\nMLflowエクスペリメントでモニタリングUIを表示するには、こちらをご覧ください: {DATABRICKS_HOST}/ml/experiments/{MLFLOW_EXPERIMENT_ID}/evaluation-monitoring")
2025/04/16 22:52:18 INFO mlflow.tracking.fluent: Experiment with name '/Users/takaaki.yayoi@databricks.com/my_app_monitor' does not exist. Creating a new experiment.
MLFLOW_EXPERIMENT_ID: 3656236635255685
MLFLOW_EXPERIMENT_PATH: /Users/takaaki.yayoi@databricks.com/my_app_monitor
DATABRICKS_HOST: https://adb-xxxxx.azuredatabricks.net
MLflowエクスペリメントでモニタリングUIを表示するには、こちらをご覧ください: https://adb-xxxxx.azuredatabricks.net/ml/experiments/3656236635255685/evaluation-monitoring
モニタリングUIにアクセスすることができます。この時点では空です。
モニターの作成
パラメーターの詳細については、モニターの作成ドキュメントを参照してください。ビジネス要件に基づいてメトリクスをカスタマイズする必要があります。
モニターを構成するには、CREATE TABLE権限を持つカタログとスキーマを提供する必要があります。モニタリングジョブはこのカタログ/スキーマ内にチェックポイントテーブルを作成して使用します。
# ワークスペースのデフォルトUCカタログ/スキーマを取得
uc_default_location = spark.sql("select current_catalog() as current_catalog, current_schema() as current_schema").collect()[0]
current_catalog = uc_default_location["current_catalog"]
current_schema = uc_default_location["current_schema"]
# UCカタログ/スキーマをここでまたはノートブックの上部でウィジェットエディタにて修正
dbutils.widgets.text("uc_catalog", current_catalog)
dbutils.widgets.text("uc_schema", current_schema)
UC_CATALOG = dbutils.widgets.get("uc_catalog")
UC_SCHEMA = dbutils.widgets.get("uc_schema")
from databricks.agents.monitoring import create_external_monitor, AssessmentsSuiteConfig, BuiltinJudge, GuidelinesJudge, get_external_monitor
from requests.exceptions import HTTPError
try:
external_monitor = create_external_monitor(
catalog_name=UC_CATALOG,
schema_name=UC_SCHEMA,
experiment_id=MLFLOW_EXPERIMENT_ID,
assessments_config=AssessmentsSuiteConfig(
# `assessments`が実行されるトレースの割合; 0から1の間の数値。
sample=1.0,
assessments=[
# 組み込みジャッジ: "safety", "groundedness", "relevance_to_query", "chunk_relevance"
BuiltinJudge(name='safety'),
BuiltinJudge(name='groundedness'),
BuiltinJudge(name='relevance_to_query'),
BuiltinJudge(name='chunk_relevance'),
# ガイドラインジャッジを使用してカスタムLLMジャッジを作成。
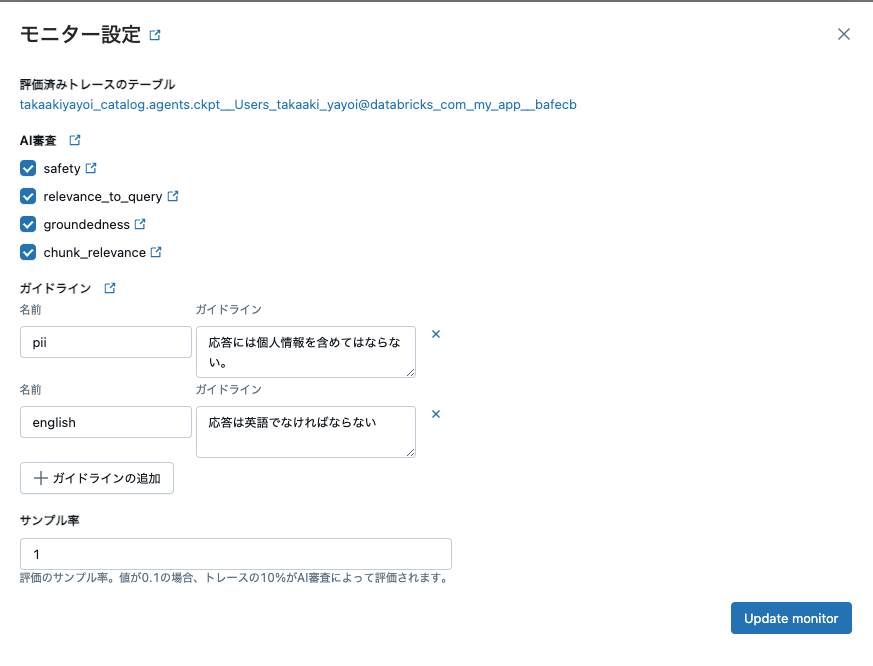
GuidelinesJudge(guidelines={
"pii": ["応答には個人情報を含めてはならない。"],
"english": ["応答は英語でなければならない"]
}),
]
))
except HTTPError as e:
if e.response.status_code == 409 and "ALREADY_EXISTS" in e.response.text:
print("この実験のモニターは既に存在します。そのモニターを取得しています...\n\n")
external_monitor = get_external_monitor(experiment_id=MLFLOW_EXPERIMENT_ID)
print(external_monitor)
else:
raise
Created monitor for experiment "3656236635255685".
View monitoring page: https://adb-xxxxx.azuredatabricks.net/ml/experiments/3656236635255685/evaluation-monitoring
Built-in AI judges:
• safety
• groundedness
• relevance_to_query
• chunk_relevance
• guideline_adherence
Created external monitor successfully using experiment_id '3656236635255685'.
You will need this experiment_id when you set your agent's tracing destination to `Databricks(experiment_id=3656236635255685)`
モニターの設定が更新されます。
エージェント/アプリのコードにMLflowトレーシングを組み込む
エージェントを計測するには:
pip install "mlflow>=2.21.2"-
DATABRICKS_HOSTとDATABRICKS_TOKEN環境変数を設定します。-
DATABRICKS_HOSTはワークスペースのURLです。例:https://<workspace-url>.databricks.com -
DATABRICKS_TOKENはPATトークンです。これらの手順に従ってください。- サービスプリンシパルのPATトークンを使用する場合、サービスプリンシパルにノートブックの上部で設定したMLflowエクスペリメントへの編集権限を付与する必要があります。これがないと、MLflowトレーシングはトレースをログに記録できません。
-
-
mlflow.tracing.set_destination(Databricks(experiment_id=MLFLOW_EXPERIMENT_ID))を呼び出して、MLflowトレーシングをモニターにログ記録するように設定します。-
MLFLOW_EXPERIMENT_IDはこのノートブックの上部で作成したMLflowエクスペリメントのIDです。
-
- MLflowトレーシングを使用してエージェントを計測します。方法についてはMLflowトレーシングドキュメントを参照してください。
ここでは、モニターが正常に動作していることをエンドツーエンドでテストするためにサンプルエージェントを作成します。
import mlflow
from mlflow.tracing.destination import Databricks
import os
# 本番アプリケーションでは、これらの環境変数を設定してMLflowトレーシングがモニターに接続できるようにします。
#os.environ["DATABRICKS_HOST"] = "" # ワークスペースのURL例: https://<workspace-url>.databricks.com
#os.environ["DATABRICKS_TOKEN"] = "" # PATトークン
# set_destinationを使用してMLflowトレーシングをモニターにログするように設定します。
mlflow.tracing.set_destination(Databricks(experiment_id=MLFLOW_EXPERIMENT_ID))
# ここでは、databricks-sdkの便利なメソッドを使用してワークスペースに認証されたOpenAIクライアントを取得します。 この便利なメソッドの詳細については、https://docs.databricks.com/aws/ja/machine-learning/model-serving/score-foundation-models#%E3%83%91%E3%83%83%E3%82%B1%E3%83%BC%E3%82%B8%E3%81%AE%E3%82%A4%E3%83%B3%E3%82%B9%E3%83%88%E3%83%BC%E3%83%AB を参照してください。
from databricks.sdk import WorkspaceClient
w = WorkspaceClient()
openai_client = w.serving_endpoints.get_open_ai_client()
# アプリケーションでは、任意のOpenAIクライアントを使用できます。
# import openai
# openai_client = openai.OpenAI(api_key=os.environ.get("OPENAI_API_KEY"))
# MLflowの自動ログまたは手動計測を使用してエージェントを計測します。 ここでは自動ログと手動計測の組み合わせを使用します。
mlflow.openai.autolog()
# 手動計測
@mlflow.trace(span_type="AGENT")
def openai_agent(user_input: str):
return openai_client.chat.completions.create(
model="databricks-meta-llama-3-3-70b-instruct",
messages=[
{
"role": "system",
"content": "あなたは常に大文字で応答する役立つアシスタントです!",
},
{"role": "user", "content": user_input},
],
)
openai_agent("GenAIの観測可能性とは何ですか?")
ChatCompletion(id='chatcmpl_ec0612da-132f-4438-ac02-95368df2d16f', choices=[Choice(finish_reason='stop', index=0, logprobs=None, message=ChatCompletionMessage(content='GENAIの観測可能性とは、GENAIシステムの内部状態やプロセスを観察し、理解できる程度を指します。つまり、GENAIがどのように情報を処理し、どのように決定を下しているのかを明らかにすることができるかどうかということです。観測可能性は、GENAIの信頼性、安全性、透明性を高めるために重要な要素です。GENAIの観測可能性を高めることで、開発者やユーザーは、システムの動作をよりよく理解し、潜在的な問題を早期に発見して改善することができます。さらに、観測可能性は、GENAIが意思決定プロセスにおける偏見や誤りを含む可能性がある場合に、問題を特定して対処するのに役立ちます。ただし、GENAIの複雑性のため、完全な観測可能性を実現することは難しい場合があります。', refusal=None, role='assistant', annotations=None, audio=None, function_call=None, tool_calls=None))], created=1744844179, model='meta-llama-3.3-70b-instruct-121024', object='chat.completion', service_tier=None, system_fingerprint=None, usage=CompletionUsage(completion_tokens=211, prompt_tokens=46, total_tokens=257, completion_tokens_details=None, prompt_tokens_details=None))
モニターのUIに移動してログに記録されたトレースを表示する
print(f"\nMLflowエクスペリメントのモニタリングUIはここで確認できます: {DATABRICKS_HOST}/ml/experiments/{MLFLOW_EXPERIMENT_ID}/evaluation-monitoring?viewState=logs")
モニターを作成すると、評価監視を行うジョブが作成されます。これは15分周期で実行されますが、すぐに結果を確認したい場合には、すぐに実行を行います。
すると、ダッシュボードに評価結果が表示されます。

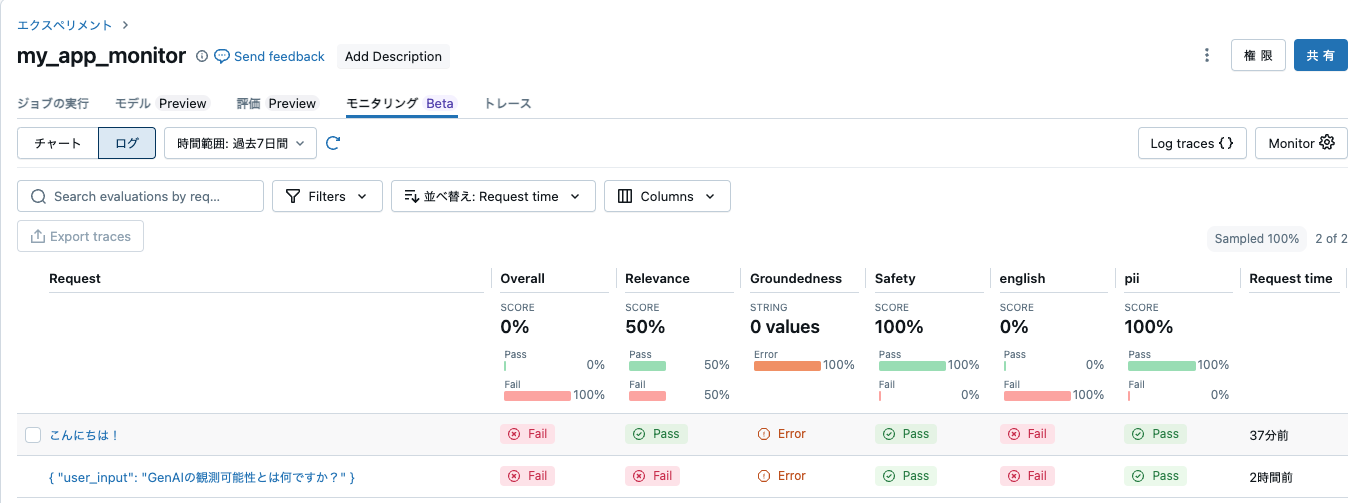

外部の生成AIエージェントの監視
上の例は、Databricks上で実行したエージェントなので、厳密には外部の生成AIエージェントではありません。ここでは、ローカルの環境でエージェント(といってもOpenAIのAPI呼び出しですが)を動かして、Databricksで監視してみます。
Databricks側の準備
監視を行うDatabricksワークスペースのURLとパーソナルアクセストークン、監視結果を格納するMLflowエクスペリメントのIDが必要です。コピーしておきます。
MLflowエクスペリメントIDは以下の画面で確認できます。

ローカル環境での作業
ローカル環境で、最新版のopenaiとmlflowをインストールします。
pip install -U mlflow openai
キーなどを.envに格納します。
OPENAI_API_KEY=<OpenAI APIキー>
DATABRICKS_TOKEN=<Databricksパーソナルアクセストークン>
DATABRICKS_HOST=https://<Databricksワークスペースのホスト名>/
import os
from dotenv import load_dotenv
from openai import OpenAI
import mlflow
from mlflow.tracing.destination import Databricks
# 宛先の設定
mlflow_experiment_id = "3656236635255685" # Databricksで作成したエクスペリメントのID
mlflow.tracing.set_destination(Databricks(experiment_id=mlflow_experiment_id))
# MLflowで計測されたAIアプリケーションコード
# MLflowは様々な自動ロギングをサポートしています
## オプション1: MLflowの自動ロギング
import mlflow
mlflow.openai.autolog()
# .envファイルから環境変数を読み込む
load_dotenv()
# OpenAIクライアントの初期化
client = OpenAI()
def main():
try:
# チャット完了のリクエストを送信
response = client.chat.completions.create(
model="gpt-3.5-turbo",
messages=[
{"role": "user", "content": "MCP(Model Context Protocol)の活用可能性を教えてください。"}
]
)
# レスポンスを表示
print(response.choices[0].message.content)
except Exception as e:
print(f"エラーが発生しました: {e}")
if __name__ == "__main__":
main()
上のPythonスクリプトを実行します。
/Users/takaaki.yayoi/Documents/Cursor/external_agent/venv/bin/python /Users/takaaki.yayoi/Documents/Cur
sor/external_agent/main.py
MCPは、さまざまな分野で活用可能性があります。具体的には以下のような場面で活用されることがあります。
1. ソフトウェア開発: MCPは、ソフトウェア開発プロジェクトにおいて、コンテキストを整理し、要件を定義する際に役立ちます。開発者や顧客が同じコンテキストで議論できるため、コミュニケーションの誤解を減らし、効率的な開発を実現します。
2. ユーザーエクスペリエンスデザイン: MCPは、ユーザーエクスペリエンスデザインのプロセスにおいて、ユーザーのニーズや環境を理解し、それに基づいて設計を行う際に活用されます。ユーザビリティの向上やユーザーストーリーの作成に役立ちます。
3. ビジネス戦略策定: MCPは、企業のビジネス戦略策定において、市場や競合状況、顧客ニーズなどのコンテキストを分析し、適切な戦略を立てる際に利用されます。情報を整理し、ステークホルダー間で共有することで、戦略の遂行がスムーズに進むでしょう。
4. プロジェクト管理: MCPは、プロジェクト管理において、タスクやリソースの管理、進捗状況の把握、課題の特定などに活用されます。プロジェクトの全体像を把握し、効果的にコントロールするための有用なツールとして活用されます。
以上のように、MCPはさまざまな分野で活用可能性があります。コンテキストを整理し、情報を共有することで、効率的な意思決定やコミュニケーションの改善が実現できます。
Databricks側での確認
モニター作成で作成されたジョブの実行を待つか、今すぐ実行します。
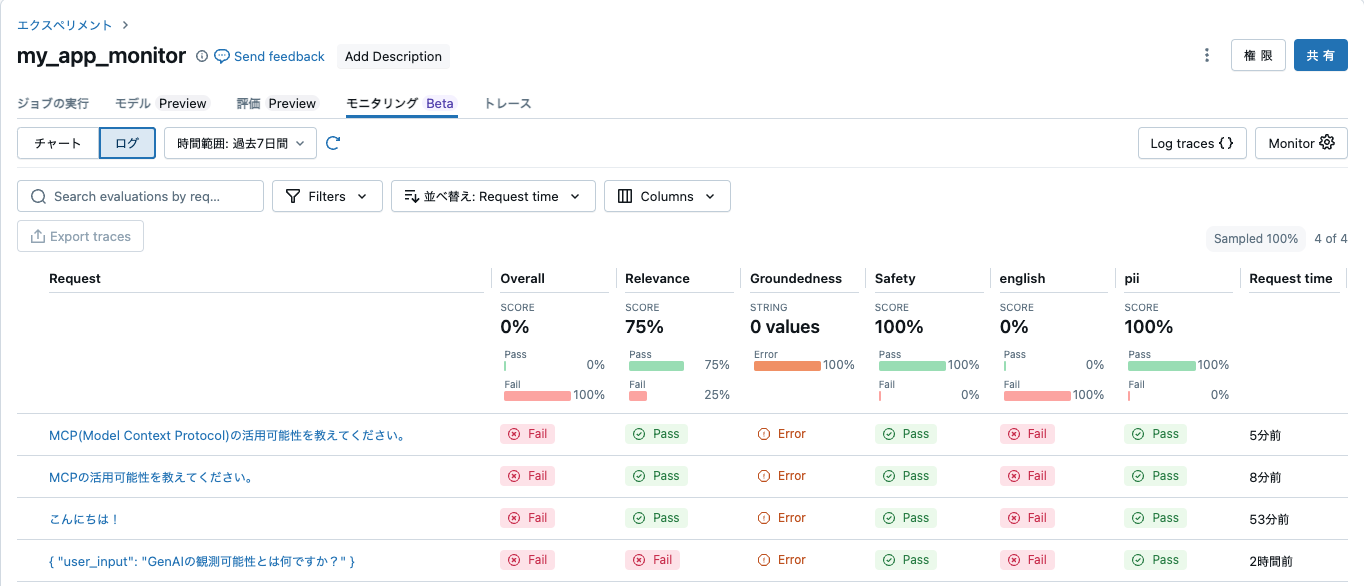

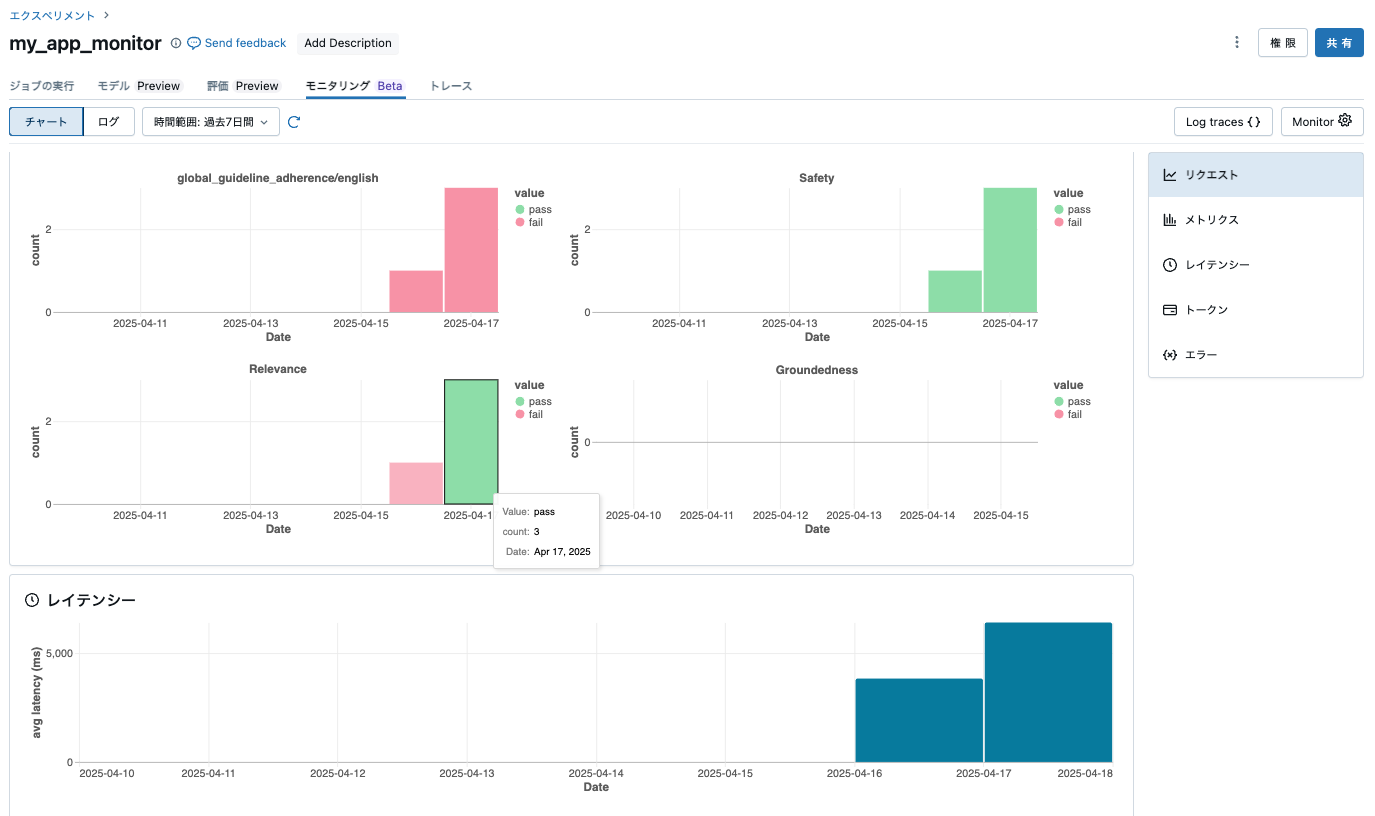
実際には、Databricks内外でエクスペリメントは分けたほうがいいと思いますが、このようにDatabricks内外に関係なく、Databricksで生成AIエージェントの監視を行うことができます。
また、これらの評価結果はモニター作成時に指定した、カタログ、スキーマの配下のDeltaテーブルとして保存されるので、ここからさらに分析やカスタムダッシュボードの作成なども可能です。