こちらのサンプルノートブックをウォークスルーします。
プレビュー
本機能はパブリックプレビューです。かつ、執筆時点ではリージョンの制限があり日本リージョンでは利用できません。
オンラインテーブル、特徴量サービングエンドポイントとは?
RAG(Retrieval Augumented Generation)は広く使われており、いろいろなアプリケーションが構築されています。以下のようにシンプルな仕組みですが、その精度から活用がどんどん進んでいます。
- テキストデータをエンベディングに変換し、ベクトルストアに格納
- ベクトルストアに(エンべディングに変換した)クエリーを投入し類似検索
- 検索結果をプロンプトに組み込みLLMが回答を生成
このような仕組みをとる際、エンべディングモデルやLLMを呼び出すことになるため、何かしらのエンドポイントが必要になります。多くの場合、REST APIエンドポイントになるかと思います。利用ユーザーが多ければ、このエンドポイントのコンカレンシーやレーテンシーが問題になるため、オートスケーリングの機能が求められます。すでに、Databricksでもモデルサービングエンドポイントとしてこのような機能も提供しています。
しかし、RAGはテキストのみの世界であれば威力を発揮しますが、そこに構造化データの必要性が出てくると課題に直面します。どれだけLLMのサービングエンドポイントのレーテンシーが改善できたとしても、構造化データ取得で時間を要していたのではアプリケーション全体の性能が低下することになります。
そこで、Databricksでは構造化データをオンラインでサービングできるようにするために、オンラインテーブルのサービング機能をリリースしました。
- オンラインテーブル: サービングエンドポイントから参照できるDeltaテーブルのオンラインかつ読み取り専用のコピー。
- 特徴量サービングエンドポイント: オンラインテーブルにアクセスするためのREST APIエンドポイントを提供します。
ノートブックのウォークスルー
このノートブックでは、プロダクション規模かつリアルタイムの企業データを用いてアプリケーションを強化するために、Databricksオンラインテーブルと特徴量サービングエンドポイントをどのように活用するのかを説明します。
このサンプルでは、ダミーのデータセットを用い、オンラインテーブルからリアルタイムで提供される企業データを用いて、チャットbotのレスポンスを拡張するオーケストレーションレイヤーとしてLangchainを使います。
必要なパッケージのインストール
%pip install --force-reinstall databricks-feature-store
%pip install --force-reinstall databricks_vectorsearch
%pip install --force-reinstall -v langchain openai
dbutils.library.restartPython()
from pyspark.sql.types import StructType, StructField, StringType, IntegerType, DoubleType, ArrayType
import mlflow
from databricks import feature_engineering
import json
import requests
import time
fe = feature_engineering.FeatureEngineeringClient()
特徴量テーブルの作成と公開
以下のセルではダミーデータを用いて特徴量テーブルを作成します。
使用するカタログとスキーマのセットアップ
username = spark.sql("SELECT current_user()").first()["current_user()"]
username = username.split(".")[0]
#catalog_name = username
catalog_name = "takaakiyayoi_catalog" # 既存のカタログを使用
# Fetch the username to use as the schema name.
schema_name = "rag"
spark.sql(f"CREATE CATALOG IF NOT EXISTS {catalog_name}")
spark.sql(f"USE CATALOG {catalog_name}")
spark.sql(f"CREATE DATABASE IF NOT EXISTS {catalog_name}.{schema_name}")
spark.sql(f"USE SCHEMA {schema_name}")
特徴量テーブルと関数の作成
以下のセルでは、ユーザーの嗜好とホテル価格の特徴量テーブルを作成し、滞在期間に対する税込のホテル合計金額を計算する関数を作成します。
user_preference_feature_table = f"{catalog_name}.{schema_name}.user_preferences"
spark.sql(f"""
CREATE TABLE IF NOT EXISTS {user_preference_feature_table} (
user_id VARCHAR(255),
avg_budget DOUBLE,
hotel_preference VARCHAR(255),
CONSTRAINT users_pk PRIMARY KEY(user_id)
) TBLPROPERTIES (delta.enableChangeDataFeed = true);
""")
hotel_prices_feature_table = f"{catalog_name}.{schema_name}.hotel_prices"
spark.sql(f"""
CREATE TABLE IF NOT EXISTS {hotel_prices_feature_table} (
hotel_id VARCHAR(255),
name STRING,
price DOUBLE,
tax_rate DOUBLE,
CONSTRAINT hotels_pk PRIMARY KEY(hotel_id)
) TBLPROPERTIES (delta.enableChangeDataFeed = true);
""")
hotel_price_function_name = f"{catalog_name}.{schema_name}.hotel_total_price"
spark.sql(f"""
CREATE OR REPLACE FUNCTION {hotel_price_function_name}(price DOUBLE, tax_rate DOUBLE, num_days INT)
RETURNS DOUBLE
LANGUAGE PYTHON AS
$$
def hotel_total_price(price, tax_rate, num_days):
# 税込の価格を計算
price_with_taxes = price + price * tax_rate
# コンテキストの特徴量である num_days を用いて旅行のう合計金額を計算
total_price = price_with_taxes * num_days
return total_price
return hotel_total_price(price, tax_rate, num_days)
$$""")
特徴量テーブルのダミーデータの作成
schema = StructType([
StructField("user_id", StringType(), False),
StructField("avg_budget", DoubleType(), False),
StructField("hotel_preference", StringType(), True),
])
# ダミーデータを作成
data = [("a-456", 700.0, "city"),
("b-591", 100.0, "beach"),
("c-197", 2300.0, "cottage"),
("d-862", 300.0, "oceanview")]
# ダミーデータでデータフレームを作成
df = spark.createDataFrame(data, schema=schema)
# 特徴量テーブルを作成
fe.write_table(name=user_preference_feature_table, df=df)
schema = StructType([
StructField("hotel_id", StringType(), False),
StructField("name", StringType(), False),
StructField("price", DoubleType(), False),
StructField("tax_rate", DoubleType(), True),
])
# ダミーデータの作成
data = [('AB123', 'Hotel Miramalfi', 340.0, 0.05),
('SW345', 'Hotel Marina Riviera', 442.0, 0.07),
('MJ564', 'Hotel Luna Convento', 566.0, 0.03),
('QE278', 'Hotel Residence', 450.0, 0.02)]
# ダミーデータでデータフレームを作成
df = spark.createDataFrame(data, schema=schema)
# 特徴量テーブルの作成
fe.write_table(name=hotel_prices_feature_table, df=df)
特徴量テーブルをDatabricksオンラインテーブルに同期
Databricksオンラインテーブルは、MLサービングソリューションにおいてあなたのデータに対する低レーテンシーでの検索機能を提供するためのマネージドテーブルです。オンラインテーブルを作成するにはDatabricksのUIを使用します。手順についてはドキュメントをご覧ください(AWS|Azure)。
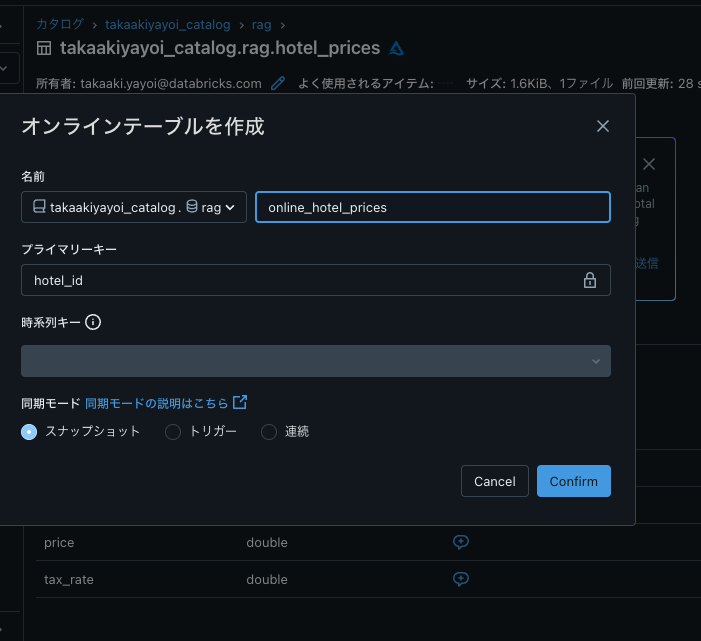
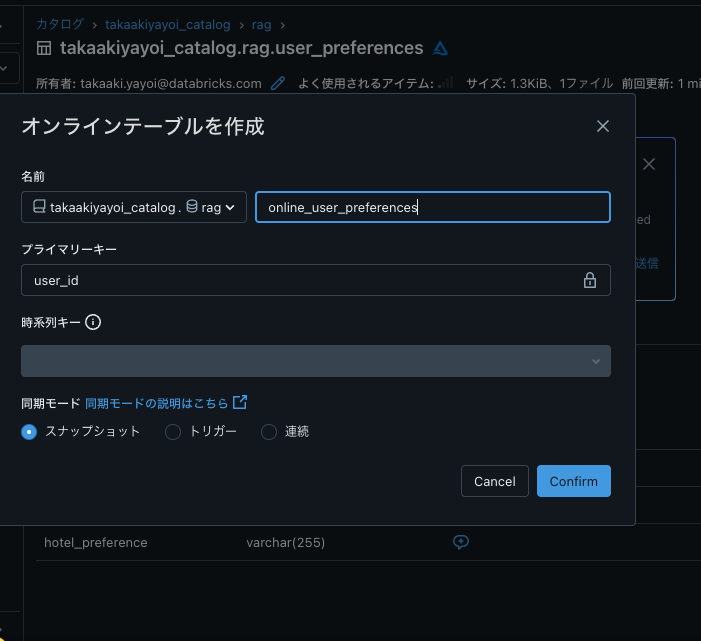
以下のテーブルに対するオンラインテーブルを作成します。
- user_preferences
- hotel_prices
非構造化データの検索のためにベクトルインデックスを作成
Databricks Vector Searchによって非構造化データを取り込んで検索することができます。
from databricks.vector_search.client import VectorSearchClient
vsc = VectorSearchClient()
#vector_search_endpoint_name = "rag_endpoint"
vector_search_endpoint_name = "dbdemos_vs_endpoint"
#try:
# vsc.create_endpoint(vector_search_endpoint_name)
#except Exception as e:
# if "already exists" in str(e):
# pass
# else:
# raise e
#vsc.list_endpoints()
注意
上の例では、既存のベクトルサーチエンドポイントを使っているので作成部分はコメントアウトしています。
def vector_index_ready(vsc, endpoint_name, index_name, desired_state_prefix="ONLINE"):
index = vsc.get_index(endpoint_name=endpoint_name, index_name=index_name).describe()
status = index["status"]["detailed_state"]
return desired_state_prefix in status
def vector_index_exists(vsc, endpoint_name, index_name):
try:
vsc.get_index(endpoint_name=endpoint_name, index_name=index_name).describe()
return True
except Exception as e:
if "DOES_NOT_EXIST" in str(e) or "NOT_FOUND" in str(e):
return False
else:
raise e
def wait_for_vector_index_ready(vsc, endpoint_name, index_name, max_wait_time=2400, desired_state_prefix="ONLINE"):
wait_interval = 60
max_wait_intervals = int(max_wait_time / wait_interval)
for i in range(0, max_wait_intervals):
time.sleep(wait_interval)
if vector_index_ready(vsc, endpoint_name, index_name, desired_state_prefix):
print(f"Vector search index '{index_name}' is ready.")
return
else:
print(
f"Waiting for vector search index '{index_name}' to be in ready state."
)
raise Exception(f"Vector index '{index_name}' is not ready after {max_wait_time} seconds.")
Databricks基盤モデルを用いたエンべディングの計算
def calculate_embedding(text):
embedding_endpoint_name = "databricks-bge-large-en"
url = f"https://{mlflow.utils.databricks_utils.get_browser_hostname()}/serving-endpoints/{embedding_endpoint_name}/invocations"
databricks_token = mlflow.utils.databricks_utils.get_databricks_host_creds().token
headers = {'Authorization': f'Bearer {databricks_token}', 'Content-Type': 'application/json'}
data = {
"input": text
}
data_json = json.dumps(data, allow_nan=True)
print(f"\nCalling Embedding Endpoint: {embedding_endpoint_name}\n")
response = requests.request(method='POST', headers=headers, url=url, data=data_json)
if response.status_code != 200:
raise Exception(f'Request failed with status {response.status_code}, {response.text}')
return response.json()['data'][0]['embedding']
ホテルの特徴を示す特徴量テーブルの作成
hotels_table = f"{catalog_name}.{schema_name}.hotels_data"
spark.sql(f"""
CREATE TABLE IF NOT EXISTS {hotels_table} (
hotel_id STRING,
embedding ARRAY<DOUBLE>,
CONSTRAINT hotel_pk PRIMARY KEY(hotel_id)
) TBLPROPERTIES (delta.enableChangeDataFeed = true);
""")
schema = StructType([
StructField("hotel_id", StringType(), False),
StructField("embedding", ArrayType(DoubleType()), False)
])
# ダミーのエンべディングを作成
data = [('AB123', calculate_embedding("ocean view, beautiful architecture, beautiful beaches")),
('SW345', calculate_embedding("city views, nice restaurants")),
('MJ564', calculate_embedding("beach facing, private beach")),
('QE278', calculate_embedding("beach views, nice beaches"))]
# ダミーデータを用いてデータフレームを作成
df = spark.createDataFrame(data, schema=schema)
# ホテルの特徴のエンべディングを保持する特徴量テーブルの作成
fe.write_table(name=hotels_table, df=df)
# エンべディング特徴量テーブルをベースとしたベクトルサーチインデックスの作成
hotels_table_index = f"{catalog_name}.{schema_name}.hotels_index"
try:
vsc.create_delta_sync_index(
endpoint_name=vector_search_endpoint_name,
index_name=hotels_table_index,
source_table_name=hotels_table,
pipeline_type="TRIGGERED",
primary_key="hotel_id",
embedding_dimension=1024, # お使いのモデルのエンべディングサイズと揃えます (bge)
embedding_vector_column="embedding"
)
except Exception as e:
if "already exists" in str(e):
pass
else:
raise e
wait_for_vector_index_ready(vsc, vector_search_endpoint_name, hotels_table_index)
Waiting for vector search index 'takaakiyayoi_catalog.rag.hotels_index' to be in ready state.
Waiting for vector search index 'takaakiyayoi_catalog.rag.hotels_index' to be in ready state.
Vector search index 'takaakiyayoi_catalog.rag.hotels_index' is ready.
ここまでで、以下のようにテーブルが作成されいるはずです。

特徴量サービングエンドポイントのセットアップ
# 必要なクラスのインポート
from databricks.feature_engineering.entities.feature_lookup import FeatureLookup
from databricks.feature_engineering import FeatureEngineeringClient, FeatureFunction
from databricks.feature_engineering.entities.feature_serving_endpoint import (
EndpointCoreConfig,
ServedEntity
)
# feature storeクライアントの作成
fe = FeatureEngineeringClient()
# エンドポイントと特徴量テーブルの名前の設定
user_endpoint_name = f"{username}-user-preferences"
# キーで特徴量を取得する lookup の作成
features=[
FeatureLookup(
table_name=user_preference_feature_table,
lookup_key="user_id"
)
]
# 特徴量に対する lookup を用いて feature spec を作成
user_spec_name = f"{catalog_name}.{schema_name}.user_preferences_spec"
try:
fe.create_feature_spec(name=user_spec_name, features=features)
except Exception as e:
if "already exists" in str(e):
pass
else:
raise e
# ユーザーの予算、嗜好をサービングするエンドポイントの作成
try:
status = fe.create_feature_serving_endpoint(
name=user_endpoint_name,
config=EndpointCoreConfig(
served_entities=ServedEntity(
feature_spec_name=user_spec_name,
workload_size="Small",
scale_to_zero_enabled=True)
)
)
# エンドポイント作成ステータスの表示
print(status)
except Exception as e:
if "already exists" in str(e):
pass
else:
raise e
hotel_endpoint_name = f"{username}-hotel-price"
# キーで特徴量を取得する lookup の作成
hotel_features=[
FeatureLookup(
table_name=hotel_prices_feature_table,
lookup_key="hotel_id",
),
FeatureFunction(
udf_name=hotel_price_function_name,
input_bindings={
"price": "price",
"tax_rate": "tax_rate",
"num_days": "num_days"
},
output_name="total_price"
)
]
# 特徴量の lookup と関数計算処理を用いて feature spec を作成
hotel_spec_name = f"{catalog_name}.{schema_name}.hotel_price_spec"
try:
fe.create_feature_spec(name=hotel_spec_name, features=hotel_features)
except Exception as e:
if "already exists" in str(e):
pass
else:
raise e
# エンドポイントの作成
try:
status = fe.create_feature_serving_endpoint(
name=hotel_endpoint_name,
config = EndpointCoreConfig(
served_entities=ServedEntity(
feature_spec_name=hotel_spec_name,
workload_size="Small",
scale_to_zero_enabled=True
)
)
)
print(status)
except Exception as e:
if "already exists" in str(e):
pass
else:
raise e
サイドメニューのサービングにアクセスして、エンドポイントが作成されたことを確認します。

# エントポイントのステータス取得
status = fe.get_feature_serving_endpoint(name=hotel_endpoint_name)
print(status)
<FeatureServingEndpoint: creation_time_millis=1709857488000, creator='takaaki.yayoi@databricks.com', name='takaaki-hotel-price', state={'config_update': 'NOT_UPDATING', 'ready': 'READY'}, url='https://xxxxx.com/serving-endpoints/takaaki-hotel-price/invocations'>
Databricksの特徴量 & 関数サービングとオンラインテーブルで強化されたAI bot
- Deltaテーブルからオンラインテーブルに自動で同期。
- 低レーテンシーによるリアルタイムでの特徴量検索。
- この例で説明しているように企業データを用いてチャットbotにコンテキストを提供し拡張。
- LLMOpsによる、MLOpsにおけるデータ管理のベストプラクティスを実装。
顧客情報と予算を取得するツールの定義
CustomerRetrievalToolはDatabricksオンラインテーブルからデータをサービングする特徴量 & 関数サービングエンドポイントにクエリーを行い、ユーザークエリーに基づくコンテキストをLLMに提供します。
from langchain.tools import BaseTool
from typing import Union
class UserPreferenceTool(BaseTool):
name = "User Preference Feature Server"
description = "Use this tool when you need to fetch current users travel preferences."
def _run(self, user_id: str):
import requests
import pandas as pd
import json
import mlflow
url = f"https://{mlflow.utils.databricks_utils.get_browser_hostname()}/serving-endpoints/{user_endpoint_name}/invocations"
databricks_token = mlflow.utils.databricks_utils.get_databricks_host_creds().token
headers = {'Authorization': f'Bearer {databricks_token}', 'Content-Type': 'application/json'}
data = {
"dataframe_records": [{"user_id": user_id}]
}
data_json = json.dumps(data, allow_nan=True)
print(f"\nCalling Feature & Function Serving Endpoint: {user_endpoint_name}\n")
response = requests.request(method='POST', headers=headers, url=url, data=data_json)
if response.status_code != 200:
raise Exception(f'Request failed with status {response.status_code}, {response.text}')
return response.json()['outputs'][0]['hotel_preference']
def _arun(self, user_id: str):
raise NotImplementedError("This tool does not support async")
from langchain.tools import BaseTool
from typing import Union
from typing import List
from databricks.vector_search.client import VectorSearchClient
class HotelRetrievalTool(BaseTool):
name = "Hotels based on User's Hotel Preference Vector Server"
description = "Use this tool when you need to fetch hotels based on users hotel_preference."
def _run(self, hotel_preference: str):
def calculate_embedding(text):
embedding_endpoint_name = "databricks-bge-large-en"
url = f"https://{mlflow.utils.databricks_utils.get_browser_hostname()}/serving-endpoints/{embedding_endpoint_name}/invocations"
databricks_token = mlflow.utils.databricks_utils.get_databricks_host_creds().token
headers = {'Authorization': f'Bearer {databricks_token}', 'Content-Type': 'application/json'}
data = {
"input": text
}
data_json = json.dumps(data, allow_nan=True)
print(f"\nCalling Embedding Endpoint: {embedding_endpoint_name}\n")
response = requests.request(method='POST', headers=headers, url=url, data=data_json)
if response.status_code != 200:
raise Exception(f'Request failed with status {response.status_code}, {response.text}')
return response.json()['data'][0]['embedding']
try:
vsc = VectorSearchClient()
index = vsc.get_index(endpoint_name=vector_search_endpoint_name, index_name=hotels_table_index)
print(index)
resp = index.similarity_search(columns=["hotel_id"], query_vector=calculate_embedding(hotel_preference), num_results=5, filters={})
print(resp)
data_array = resp and resp.get('result', {}).get('data_array')
print(data_array)
except Exception as e:
print(f"Exception while running test case {e}")
return []
result = [hotel[0] for hotel in data_array]
print(result)
return result
def _arun(self, user_id: str):
raise NotImplementedError("This tool does not support async")
from langchain.tools import BaseTool
from typing import Union
from typing import List
from datetime import datetime
class TotalPriceTool(BaseTool):
name = "Total vacation price Feature Server"
description = "Use this tool when you need to fetch hotels total price including taxes."
def _run(self, *args, **kwargs):
import requests
import pandas as pd
import json
import mlflow
hotels_req = []
hotel_ids = kwargs["hotel_ids"]
num_days = kwargs["days"]
for hotel_id in hotel_ids:
hotels_req.append({"hotel_id": hotel_id, "num_days": num_days})
data = {
"dataframe_records": hotels_req
}
url = f"https://{mlflow.utils.databricks_utils.get_browser_hostname()}/serving-endpoints/{hotel_endpoint_name}/invocations"
databricks_token = mlflow.utils.databricks_utils.get_databricks_host_creds().token
headers = {'Authorization': f'Bearer {databricks_token}', 'Content-Type': 'application/json'}
data_json = json.dumps(data, allow_nan=True)
print("Calling Feature & Function Serving Endpoint: " + hotel_endpoint_name)
response = requests.request(method='POST', headers=headers, url=url, data=data_json)
if response.status_code != 200:
raise Exception(f'Request failed with status {response.status_code}, {response.text}')
output_dict = []
for output in response.json()["outputs"]:
output_dict.append({"hotel name": output["name"], "total_price": output["total_price"]})
return json.dumps(output_dict)
def _arun(self, user_id: str):
raise NotImplementedError("This tool does not support async")
特徴量 & 関数サービングを用いてDatabricksレイクハウスから企業データを取得するエージェントのセットアップ
以下のセルではOpenAIのAPIキーを使います。Databricksシークレットマネージャの使い方については、ドキュメント(AWS|Azure)を参照ください。
# OpenAIのAPIキーのセットアップ
# これによって、ノートブックでChatGPTの会話モデルと通信できるようになります。
# あるいは、ご自身のLLMモデルを設定し、Langchainにそれを参照するように設定することができます。
OPENAI_API_KEY = dbutils.secrets.get("demo-token-takaaki.yayoi", "openai_api_key") #replace this with your openAI API key
from langchain.agents import initialize_agent
# ツールのインポート
from langchain.agents import Tool
tools = [
UserPreferenceTool(),
HotelRetrievalTool(),
TotalPriceTool(),
]
import os
from langchain.chat_models import ChatOpenAI
from langchain.chains.conversation.memory import ConversationBufferWindowMemory
# LLMの初期化 (このサンプルでは、あとで `chat`エージェントを定義するのでChatOpenAIを使っています)
llm = ChatOpenAI(
openai_api_key=OPENAI_API_KEY,
temperature=0,
#model_name='gpt-3.5-turbo'
model_name='gpt-4'
)
# 会話メモリーの初期化
conversational_memory = ConversationBufferWindowMemory(
memory_key='chat_history',
k=5,
return_messages=True
)
# ツールを用いてエージェントを初期化
aibot = initialize_agent(
agent='chat-conversational-react-description',
tools=tools,
llm=llm,
verbose=True,
max_iterations=5,
early_stopping_method='force',
memory=conversational_memory
)
sys_msg = """Assistant is a large language model trained by OpenAI.
Assistant is designed to be plan a vacation for the input user_id.
When user ask to plan a travel, use the user_id to fetch the user hotel_preference.
Use the hotel_preference from it's trusty tools to retrieve list of hotels that fit in the user's preferences from retrival from the tools.
Use the list of hotel_ids and number of days to calculate total price and return name and total price of hotels as output.
Overall, Assistant is a powerful system that can help users plan a vacation and can help with a wide range of tasks and provide valuable insights and information on a wide range of topics.
"""
new_prompt = aibot.agent.create_prompt(
system_message=sys_msg,
tools=tools
)
aibot.agent.llm_chain.prompt = new_prompt
オンラインテーブルや特徴量サービングエンドポイントを含むDatabricksレイクハウスからのコンテキストを組み込むことで、コンテキスト取得ツールを持つAIチャットbotは一般的なチャットbotよりも優れたパフォーマンスを発揮します。
aibot_output = aibot('Plan a 7-day vacation to the Amalfi Coast around September for user id "a-456".')
> Entering new AgentExecutor chain...
```json
{
"action": "User Preference Feature Server",
"action_input": "a-456"
}
```
Calling Feature & Function Serving Endpoint: takaaki-user-preferences
Observation: city
Thought:```json
{
"action": "Hotels based on User's Hotel Preference Vector Server",
"action_input": "city"
}
```[NOTICE] Using a notebook authentication token. Recommended for development only. For improved performance, please use Service Principal based authentication. To disable this message, pass disable_notice=True to VectorSearchClient().
<databricks.vector_search.index.VectorSearchIndex object at 0x7fe1cd22fc10>
Calling Embedding Endpoint: databricks-bge-large-en
{'manifest': {'column_count': 2, 'columns': [{'name': 'hotel_id'}, {'name': 'score'}]}, 'result': {'row_count': 4, 'data_array': [['SW345', 0.5675767], ['QE278', 0.5170265], ['AB123', 0.4993552], ['MJ564', 0.49724537]]}, 'next_page_token': '', 'debug_info': {'response_time': 210.0, 'ann_time': 47.0}}
[['SW345', 0.5675767], ['QE278', 0.5170265], ['AB123', 0.4993552], ['MJ564', 0.49724537]]
['SW345', 'QE278', 'AB123', 'MJ564']
Observation: ['SW345', 'QE278', 'AB123', 'MJ564']
Thought:```json
{
"action": "Total vacation price Feature Server",
"action_input": {
"hotel_ids": ["SW345", "QE278", "AB123", "MJ564"],
"days": 7
}
}
```Calling Feature & Function Serving Endpoint: takaaki-hotel-price
Observation: [{"hotel name": "Hotel Marina Riviera", "total_price": 3310.58}, {"hotel name": "Hotel Residence", "total_price": 3213.0}, {"hotel name": "Hotel Miramalfi", "total_price": 2499.0}, {"hotel name": "Hotel Luna Convento", "total_price": 4080.86}]
Thought:```json
{
"action": "Final Answer",
"action_input": "Here are some hotels that fit your preferences for a 7-day vacation to the Amalfi Coast in September: \n1. Hotel Marina Riviera, total price including taxes: $3310.58 \n2. Hotel Residence, total price including taxes: $3213.0 \n3. Hotel Miramalfi, total price including taxes: $2499.0 \n4. Hotel Luna Convento, total price including taxes: $4080.86"
}
```
> Finished chain.
結果を確認します。
print(aibot_output['output'])
Here are some hotels that fit your preferences for a 7-day vacation to the Amalfi Coast in September:
1. Hotel Marina Riviera, total price including taxes: $3310.58
2. Hotel Residence, total price including taxes: $3213.0
3. Hotel Miramalfi, total price including taxes: $2499.0
4. Hotel Luna Convento, total price including taxes: $4080.86
おおー。ですが、今回はサンプルデータなのであまり面白味がありません。ただ、エージェントの挙動を見ると質問に応じて適切にオンラインテーブルからデータを取得して回答を作成していることがわかります。
個人的にも今後は構造化データを活用するエージェントのユースケースが増えていくのではないかと思っています。