こちらの記事のソリューションアクセラレータをウォークスルーします。
ソリューションアクセラレータはこちら。
01_intro_to_binpacking
こちらでは、シングルノードでビンパッキング問題に慣れ親しみます。
00. 計算環境のセットアップ
以下の例では、py3dbpというオープンソースのbinpacking実装を使用しています - ライブラリ情報やその他の例については、enzoruiz/3dbinpackingを参照してください。
以下のコードは、次のクラスタ構成でAWS Databricks上でテストされています。異なるクラスタサイズやランタイムに合わせて、RayとSparkのパラメータを調整する必要があるかもしれません:
{
...
"spark_version": "15.3.x-cpu-ml-scala2.12",
"node_type_id": "r6id.xlarge",
"num_workers": 4
"data_security_mode": "SINGLE_USER",
"single_user_name": "...",
"runtime_engine": "STANDARD"
...
}
%pip install py3dbp
dbutils.library.restartPython()
01. コンセプトの紹介: シングルノードでのpy3dpコード
Rayを使って最適化をスケールする方法を学ぶ前に、まずはコアとなるビジネス問題、つまり「ビンパッキング」(容器にアイテムを詰め込むこと)について見ていきましょう。
以下の実装はPythonライブラリのpy3dbpに依存しています。このライブラリについての詳細はこちらをご覧ください。
以下のコードは、RayやSparkを示していません。これはドライバーノードだけで実行され、ビンパッキングのロジックを確認するものです。Rayについては次のセクションで取り上げます!
from py3dbp import Packer, Bin, Item
import numpy as np
def pack_container(args):
"""
コンテナに最大数のアイテムを詰める。
パラメータ:
args (tuple): アイテムとビンの寸法を含むタプル
戻り値:
max_qty: ビンに収まるアイテムの最大数
fill_rate: max_qtyのアイテムでビンがどれだけ埋まっているかのパーセント
"""
# ゼロ除算エラーを処理
def division_zero (x, y):
return x//y if y else 0
# 引数を展開
item_x, item_y, item_z, item_wt, item_vol, bin_x, bin_y, bin_z, bin_wt, bin_vol = args
item_attributes = [item_x, item_y, item_z]
bin_attributes = [bin_x, bin_y, bin_z]
# max_qty変数 = ビンに収まるアイテムの数
max_qty = None
# コンテナの容積と重量による理論的な最大アイテム数を計算
wht_max_qty = int(division_zero(bin_wt, item_wt))
vol_max_qty = int(division_zero(bin_vol, item_vol))
# アイテムがビンに大きすぎるか重すぎる場合は、ゼロアイテムが収まる
if wht_max_qty == 0 or vol_max_qty == 0:
max_qty = 0
# 少なくとも1つのアイテムが収まる場合
else:
# py3dbpライブラリからPackerをインスタンス化し、「ビン」を追加
packer = Packer()
packer.add_bin(Bin("LB", bin_x, bin_y, bin_z, bin_wt))
# 現在の配置で素朴にパックする場合の数量を決定(「サイドロード」)
side_load = [int(j / i) for i, j in zip(item_attributes[:3], bin_attributes[:3])]
side_load_qty = np.prod(side_load)
print("wht_max_qty: ",wht_max_qty, "; vol_max_qty: ", vol_max_qty,"; side_load_qty: ", side_load_qty)
# パックする同一アイテムの数を決定
max_b_load = min(wht_max_qty, vol_max_qty, side_load_qty)
for i in range(max_b_load):
packer.add_item(Item("item_" + str(i), item_x, item_y, item_z, item_wt))
packer.pack()
max_qty = len(packer.bins[0].items)
# ビンがアイテムでどれだけ埋まっているか、またはアイテムの埋め率を計算
fill_rate = np.round((max_qty * item_vol / bin_vol) * 100, decimals=1)
return max_qty, fill_rate
テストケース1: ユニットサイズのアイテム、サイズ100のコンテナ
さて、このロジックをテストしてみましょう。以下のコードでは、体積が100(10x5x2)のアイテムと、ユニットサイズのアイテム(1x1x1)があります。このコンテナには100個のアイテムを収めることができ、100%のフィルレートになるはずです:
# BIN(ビンの設定)
bin_x = 10
bin_y = 5
bin_z = 2
bin_wt = 1000
bin_vol = bin_x * bin_y * bin_z # ビンの容積
# ITEM(アイテムの設定)
item_x = 1
item_y = 1
item_z = 1
item_wt = 1
item_vol = item_x * item_y * item_z # アイテムの容積
# 全ての引数をまとめる
args = (item_x, item_y, item_z, item_wt, item_vol, bin_x, bin_y, bin_z, bin_wt, bin_vol)
max_qty, fill_rate = pack_container(args) # コンテナに詰める
print("収まるアイテム数:", max_qty)
print("充填率:", fill_rate)
wht_max_qty: 1000 ; vol_max_qty: 100 ; side_load_qty: 100
収まるアイテム数: 100
充填率: 100.0
テストケース2: 奇妙なサイズのアイテム、サイズ100のコンテナ
次に、少し奇妙なサイズのアイテムでテストしてみましょう。ここでは、コンテナのy次元がアイテムのy次元の倍数ではない場合を想定します(例:5 / 2 != 0)。
なお、実装では最初のアイテム配置の向きのみを決定し、その後のコンテナの最適な充填はpy3dbpライブラリに依存しています。
# BIN(ビンの設定)
bin_x = 10
bin_y = 5
bin_z = 2
bin_wt = 1000
bin_vol = bin_x * bin_y * bin_z # ビンの容積
# ITEM(アイテムの設定)
item_x = 1
item_y = 2
item_z = 1
item_wt = 1
item_vol = item_x * item_y * item_z # アイテムの容積
# 全ての引数をまとめる
args = (item_x, item_y, item_z, item_wt, item_vol, bin_x, bin_y, bin_z, bin_wt, bin_vol)
max_qty, fill_rate = pack_container(args) # コンテナに詰める
print("収まるアイテム数:", max_qty)
print("充填率:", fill_rate)
wht_max_qty: 1000 ; vol_max_qty: 50 ; side_load_qty: 40
収まるアイテム数: 40
充填率: 80.0
テストケース3: 重いアイテム、重量制限による制約
3番目のケースでは、単位重量が100のアイテムを、重量制限が1000のコンテナに収めます。このテストケースでは、10個のアイテムがコンテナに収まりますが、多くの「無駄なスペース」(低い充填率)が生じます。
# BIN(ビンの設定)
bin_x = 10
bin_y = 5
bin_z = 2
bin_wt = 1000
bin_vol = bin_x * bin_y * bin_z # ビンの容積
# ITEM(アイテムの設定)
item_x = 1
item_y = 2
item_z = 1
item_wt = 100
item_vol = item_x * item_y * item_z # アイテムの容積
# 全ての引数をまとめる
args = (item_x, item_y, item_z, item_wt, item_vol, bin_x, bin_y, bin_z, bin_wt, bin_vol)
max_qty, fill_rate = pack_container(args) # コンテナに詰める
print("収まるアイテム数:", max_qty)
print("充填率:", fill_rate)
wht_max_qty: 10 ; vol_max_qty: 50 ; side_load_qty: 40
収まるアイテム数: 10
充填率: 20.0
ビンパッキングのロジックを構築してテストしたので、次に最も重要な部分に移りましょう: Rayを使用してこの単一ノードのPythonプロセスをスケーリングして、数百万のアイテム/ビンの組み合わせを処理する方法です!
次のノートブック「02_ray_for_binpacking」に進んでください。
02_ray_for_binpacking
%pip install py3dbp
dbutils.library.restartPython()
01. Rayソリューションの概要
01__intro_to_binpackingノートブックのbinpacking関数は高速です:テストケースに基づいて、ほぼ常に <1秒 で実行されることが観察できます。
しかし、このタスクは、以下の擬似コードで説明できるネストされたモデリングプロセスの一部です:
For (i in items): <-- 在庫の全てのアイテムに対して実行が必要なプロセス (~1000s)
For (c in containers): <-- 全てのタイプのコンテナでフィットするかをトライ (~10s)
For (o in orientations): <-- 最初のアイテムの開始方向はそれぞれモデル化される必要があります (==6)
Pack container: <-- 最後に、ある開始方向にあるアイテムでコンテナを埋めることにトライします
シングルノードPythonを使用してこのループ処理を順次実行した場合はどうなるでしょうか?例えば、20,000アイテム x 20コンテナ x 6スタート方向 = 240万組み合わせの場合、数百時間かかる可能性があります(例:240万組み合わせ * 各1秒 / 3600秒 = 約660時間 = 27日)。物流およびサプライチェーンのユースケースに必要な初期データを得るために、1か月も待つ時間はありません。したがって、シリアル/順次プロセスよりも効率的な計算方法を見つける必要があります。
これを実装するために、Rayフレームワークの一部であるRay Coreを使用します:
「分散アプリケーションを構築およびスケーリングするための、少数のコアプリミティブ(つまり、タスク、アクター、オブジェクト)を提供します」。
このビンパッキング最適化ケースにおいて最も重要なのはRayタスクです:
「Rayは、任意の関数を別々のPythonワーカー上で非同期に実行することを可能にします。そのような関数はRayリモート関数と呼ばれ、その非同期呼び出しはRayタスクと呼ばれます」。
これは、計算インスタンスのクラスター(ほとんどのDatabricksユーザーがSparkクラスターと考えるもの)を取り、プロセスのインスタンスを好きなだけ実行できることを意味します!次のセクションでは、これらのタスク関数を開発する方法を示します。
02. Rayクラスタのセットアップ
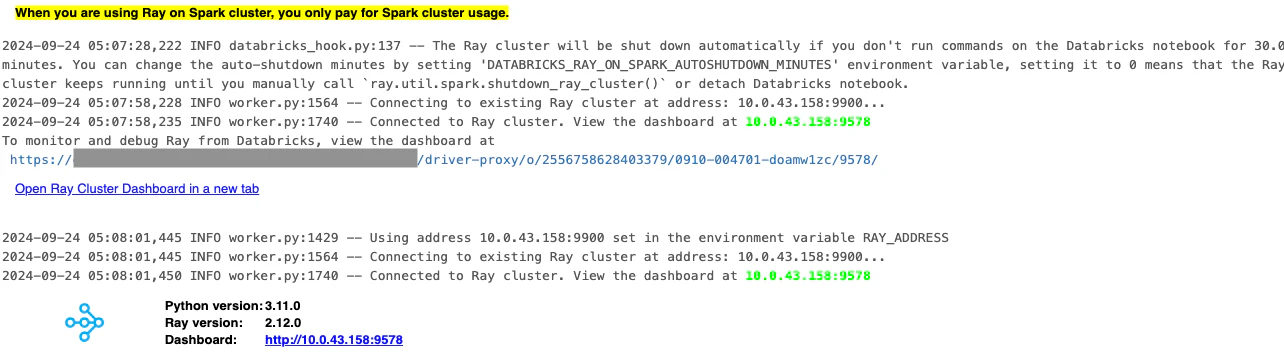
このノートブックでは、実行しているDatabricksクラスタに「Rayクラスタ」を設定する必要があります。以下のセットアップコードは、それを設定し、ワーカーノードごとに依存関係をインストールします。Rayのロジックを実行する前に、このステップを実行する必要があります。Rayは、最新のDatabricks機械学習ランタイムには事前にインストールされています。
from py3dbp import Packer, Bin, Item
import numpy as np
import pandas as pd
from itertools import permutations
import timeit, random, datetime, sys, re
import ray
from ray.util.spark import setup_ray_cluster, shutdown_ray_cluster
# 実行中のRayクラスタをシャットダウンする
ray.shutdown()
# Rayワーカーごとに依存関係を持つようにする
runtime_env = {
"pip": ["py3dbp"]
}
# Rayクラスタを初期化する
setup_ray_cluster(
num_worker_nodes=4, # この数はクラスタ内のワーカーの数に合わせる必要があります
num_cpus_worker_node=4, # デフォルトは1で、各ワーカーのすべてのコアを使用するようにスケールする場合に設定します
num_gpus_worker_node=0, # GPUノードを使用する場合に設定します
collect_log_to_path="/dbfs/ray/taka_osk_binpacking"
)
ray.init(runtime_env=runtime_env)
03. コンテナの在庫、Rayリモート変数のセットアップ
このデモでは、テストしたい各コンテナのデータを含む変数を設定します。このデータセットは比較的小さい(例:数十のレコード)ため、リモートオブジェクトを使用して、Rayの各ワーカーに効果的に「ブロードキャスト」できます。
以下のコードは、Pythonのリストから変数を作成しますが、コメントでは、ERPシステムのディメンションテーブルから最新のデータをロードする場合のデータの動的な読み込み方法を示しています。
# Deltaテーブルからコンテナデータをロードするためのコードをコメントアウトしてカスタマイズしてください
# # Deltaテーブルからデータをロードする
# containers = spark.read.table("my_container_table")
# # 必要な列を選択する
# selected_columns = [
# "container_id",
# "container_length_in",
# "container_width_in",
# "container_height_in",
# "fill_capacity_lbs",
# "bin_vol"
# ]
# df_selected = containers.select(*selected_columns)
# # DataFrameを辞書のリストに変換する
# container_list = df_selected.collect()
# container_dicts = [row.asDict() for row in container_list]
# # 辞書のリストを表示し、以下の例と一致することを確認する
# display(container_dicts)
# # Rayオブジェクトとしてブロードキャストする
# containers_remote = ray.put(container_dicts)
# サンプルの異なるサイズのコンテナのリスト
containers = [{
"container_id":"C0001",
"container_length_in":9.4,
"container_width_in":5.5,
"container_height_in":4.5,
"fill_capacity_lbs":33.8,
"bin_vol":232.65
},{
"container_id":"C0002",
"container_length_in":9.4,
"container_width_in":13,
"container_height_in":6.8,
"fill_capacity_lbs":32.4,
"bin_vol":830.96
},{
"container_id":"C0003",
"container_length_in":29.2,
"container_width_in":27.3,
"container_height_in":27,
"fill_capacity_lbs":1800,
"bin_vol":21523.32
},{
"container_id":"C0004",
"container_length_in":232,
"container_width_in":92,
"container_height_in":93,
"fill_capacity_lbs":55000,
"bin_vol":2000000
}
]
print(containers)
# Rayオブジェクトとしてブロードキャストする
containers_remote = ray.put(containers)
[{'container_id': 'C0001', 'container_length_in': 9.4, 'container_width_in': 5.5, 'container_height_in': 4.5, 'fill_capacity_lbs': 33.8, 'bin_vol': 232.65}, {'container_id': 'C0002', 'container_length_in': 9.4, 'container_width_in': 13, 'container_height_in': 6.8, 'fill_capacity_lbs': 32.4, 'bin_vol': 830.96}, {'container_id': 'C0003', 'container_length_in': 29.2, 'container_width_in': 27.3, 'container_height_in': 27, 'fill_capacity_lbs': 1800, 'bin_vol': 21523.32}, {'container_id': 'C0004', 'container_length_in': 232, 'container_width_in': 92, 'container_height_in': 93, 'fill_capacity_lbs': 55000, 'bin_vol': 2000000}]
04. Ray Binpackingロジックの構築
以下のセルでは、最も内側のループ(例:1つのコンテナを1つの開始方向でパックする)から最も外側のループ(例:単一のアイテムの結果を計算する)まで、必要な@ray.remote()関数を構築しています。
以下のコードについての1つの観察は、そのシンプルさと一般的な「Pythonらしさ」です。複雑なマルチプロセッシングや非同期呼び出しを使用せずに、これらの関数が互いと対話するために必要なコードは非常にシンプルであり、複数のデータワーカー/開発者が貢献し、メンテナンスするのに十分なものです。(注:最初の関数は、ここで使用しているpy3dbpライブラリの制約により、デフォルトのmultiprocessing Pythonライブラリを使用していますが、ほとんどの場合は必要ありません。)
最内部のループ:pack_container_ray
pack_container_ray()関数は、シングルノードのPythonと似ていますが、いくつかの追加のエラーチェックとマルチプロセッシングの使用があります。また、@ray.remote()デコレータで関数が返す変数の数を定義します。
@ray.remote(num_returns=2)
def pack_container_ray(args):
"""
コンテナに最大数のアイテムを詰め込む。Rayの実装。
パラメータ:
args (tuple): アイテムとコンテナの寸法を含むタプル
返り値:
max_qty: コンテナに詰め込むことができる最大のアイテム数
fill_rate: max_qtyの状態でコンテナが満たされる割合
"""
import numpy as np
import multiprocessing
from multiprocessing import Process, Pool, Queue
import py3dbp
from py3dbp import Packer, Bin, Item
# ゼロ除算を処理するためのローカル関数
def division_zero (x, y):
return x//y if y else 0
# argsを展開する
item_x, item_y, item_z, item_wt, item_vol, bin_x, bin_y, bin_z, bin_wt, bin_vol = args
item_attributes = [item_x, item_y, item_z]
bin_attributes = [bin_x, bin_y, bin_z]
# max_qty変数 = コンテナに詰め込むことができるアイテムの数
max_qty = None
# コンテナの体積と重量の両方に基づいて、理論上の最大アイテム数を計算する
wht_max_qty = int(division_zero(bin_wt, item_wt))
vol_max_qty = int(division_zero(bin_vol, item_vol))
# アイテムがコンテナに対して大きすぎるか重すぎる場合、アイテムは詰め込めない
if wht_max_qty == 0 or vol_max_qty == 0:
max_qty = 0
# 少なくとも1つのアイテムが詰め込める場合
else:
# py3dbpライブラリからPackerをインスタンス化し、"bin"を追加する
packer = Packer()
packer.add_bin(Bin("LB", bin_x, bin_y, bin_z, bin_wt))
# 詰め込む同一のアイテムの数を決定する
max_b_load = min(wht_max_qty, vol_max_qty)
# binpackingライブラリは詰め込み可能なアイテムを「キュー」するために使用する
for i in range(max_b_load):
packer.add_item(Item("item_" + str(i), item_x, item_y, item_z, item_wt))
# マルチプロセッシングスレッドを定義する
def worker(q):
packer.pack()
q.put(packer)
q = Queue()
pack_process = Process(target=worker, args=(q,))
pack_process.start()
pack_process.join(timeout = 0.8)
# ワーカープロセスが0.8秒以上かかる場合、代わりに単純な最大容量を計算する
# これは、巨大なコンテナ内の小さなアイテムの場合にモデリングに時間がかかることを加速するための安全策です
if pack_process.is_alive():
pack_process.terminate()
pack_process.join()
side_load = [int(j / i) for i, j in zip(item_attributes[:3], bin_attributes[:3])]
load_qty = np.prod(side_load)
max_qty = min(load_qty, wht_max_qty)
# デフォルトの場合、コンテナに詰め込まれたアイテムの数を取得する
else:
packer = q.get()
max_qty = len(packer.bins[0].items)
fill_rate = np.round((max_qty * item_vol / bin_vol) * 100, decimals=1)
return max_qty, fill_rate
中間ループ:permute_item_orientations_ray
permute_item_orientations_ray()は、アイテムの6つの可能な配置を反復処理します。使用しているPythonのビンパッキングフレームワークは、最初に詰め込まれるアイテムの配置に敏感ですので、各開始配置を最適化プロセスのユニークな試行として扱います。
@ray.remote(num_returns=2)
def permute_item_orientations_ray(args):
"""
アイテムの向きの順列を計算する。
(x, y, z); (x, z, y); (z, x, y)... それぞれのアイテムに対して6回呼び出す。
パラメータ:
args (tuple): アイテムとコンテナの寸法を含むタプル
返り値:
qty_results_list: pack_container_rayへの各呼び出しのqtyの結果のリスト
fill_results_list: pack_container_rayへの各呼び出しのfillの結果のリスト
"""
from itertools import permutations
# argsを展開する
item_x, item_y, item_z, item_wt, item_vol, bin_x, bin_y, bin_z, bin_wt, bin_vol = args
item_attributes = [item_x, item_y, item_z]
bin_attributes = [bin_x, bin_y, bin_z]
# 追跡用の変数
qty_results_list = []
fill_results_list = []
# アイテムの寸法の順列を決定する
item_perms = permutations(item_attributes[:3])
# 各アイテムに対してpack_container_rayリモート関数を6回呼び出す
for item_perm in item_perms:
qty_result, fill_rate = pack_container_ray.remote(item_perm + args[3:])
qty_results_list.append(qty_result)
fill_results_list.append(fill_rate)
# forループの外でray.get()を使用して結果を非同期に取得する
qty_results_list = ray.get(qty_results_list)
fill_results_list = ray.get(fill_results_list)
return qty_results_list, fill_results_list
最外ループ:try_container_n
最外の関数try_container_n()はRayのリモート関数ではありませんが、内部のロジックではRayオブジェクトを使用して結果を最適化して計算し、取得します。
from typing import Any, Dict
def try_container_n_ray(row: Dict[str, Any]) -> Dict[str, Any]:
"""
アイテムをビンNに詰めるための充填率を決定します。この関数は各アイテムに対してN回呼び出されます。
パラメータ:
row (Dict[str, Any]): Ray行オブジェクト、アイテムとコンテナの両方の寸法のタプル。アイテムとビンの属性に展開されます。
戻り値:
row (Dict[str, Any]): 元の行オブジェクト、特定のアイテムに対する新しいリストのコンテナ充填結果を含む
"""
# Ray行からアイテム引数を取り出す: item_args = (item_x, item_y, item_z, item_wt, item_vol)
item_args = (
row["length"],
row["width"],
row["height"],
row["weight"],
row["volume"],
)
# ビンのためのリモートRay変数を取得
bins_args = ray.get(containers_remote)
bin_fills = []
# bins_argsはリモートオブジェクトです
for bin in bins_args:
bin_args = (
bin["container_length_in"],
bin["container_width_in"],
bin["container_height_in"],
bin["fill_capacity_lbs"],
bin["bin_vol"],
)
# アイテムとビンの引数を単一のタプルに連結
args = item_args + bin_args
# ビン充填の順列に対してRay関数を呼び出す
qty_results_list, fill_results_list = permute_item_orientations_ray.remote(args)
single_bin_fill = {
"container_id": bin["container_id"],
"qty_results": ray.get(qty_results_list),
"fill_pct_results": ray.get(fill_results_list),
}
bin_fills.append(single_bin_fill)
# シリアライズのために最終リストを文字列に変換
row["bin_fills"] = str(bin_fills)
return row
05. Parquetからアイテムの在庫を読み込む
この例では、効率的な解決策の効率を示すために、アイテムの在庫の一部を読み込みます。モデル化するアイテムは30個あります。
import os
# 入力ファイルパスを設定
input_filepath = os.path.join(os.getcwd()) + "/sample_item_input.parquet"
# Rayデータを使用してファイルを読み込む
items = ray.data.read_parquet(input_filepath)
# データタイプを確認するためにスキーマを表示
items.schema()
Column Type
------ ----
part_number string
part_description string
length double
width double
height double
weight double
volume double
06. Rayの.map()を使用してBinpackingロジックを適用する
アイテムデータをRayデータセットとして読み込み、コンテナデータをRayのリモートオブジェクトとして読み込み、そして3つのBinpacking関数を持っているので、ついにロジックを適用することができます!
以下のセルは実行に少し時間がかかります。並列のRayプロセスが進行中であることを確認するには、Rayクラスタを初期化したセルに戻り、「Open Ray Cluster Dashboard in a new tab」のハイパーリンクをクリックしてください。
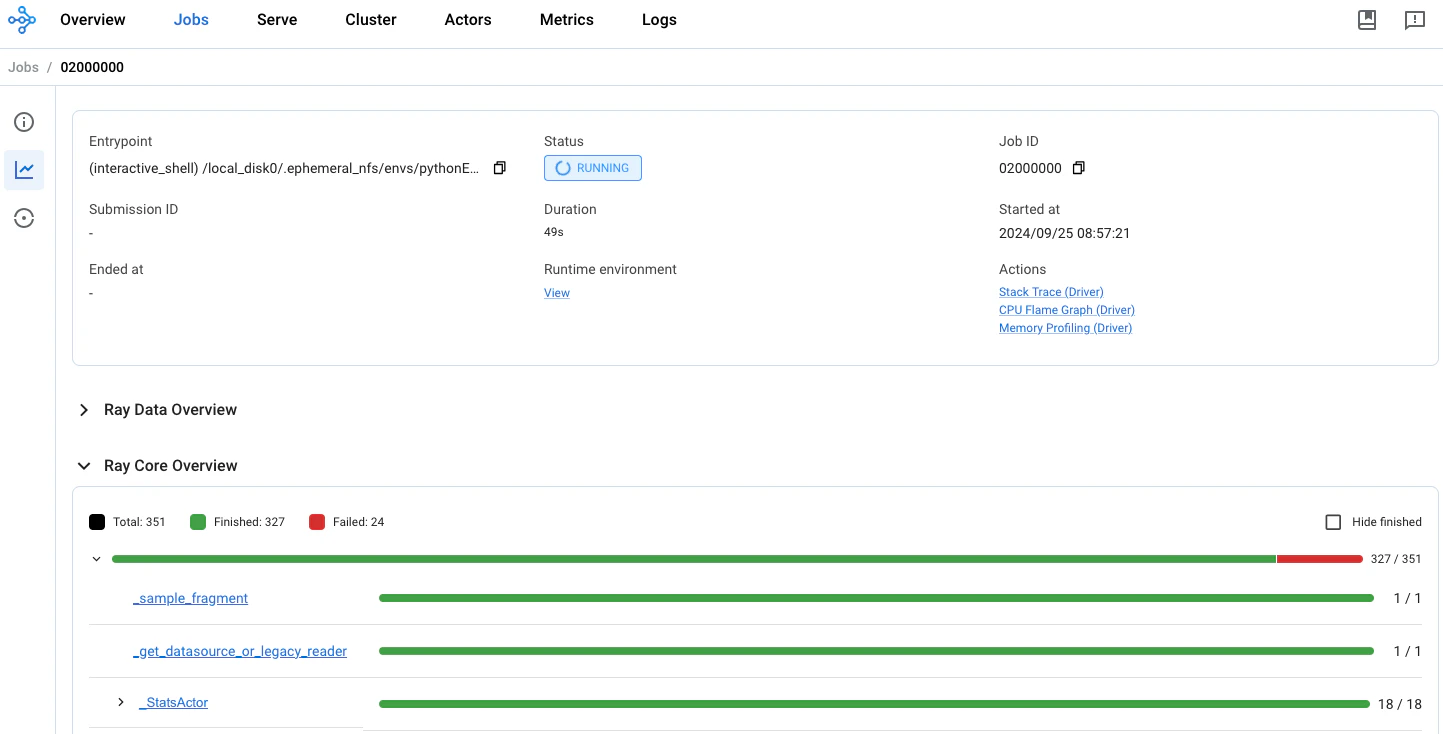
items_packed = items.map(try_container_n_ray)
items_packed.take(1)
[{'part_number': '6fb6f0a7d7',
'part_description': 'BATTERY COVER',
'length': 39.77,
'width': 12.24,
'height': 1.39,
'weight': 1.39,
'volume': 674.65,
'bin_fills': "[{'container_id': 'C0001', 'qty_results': [0, 0, 0, 0, 0, 0], 'fill_pct_results': [0.0, 0.0, 0.0, 0.0, 0.0, 0.0]}, {'container_id': 'C0002', 'qty_results': [0, 0, 0, 0, 0, 0], 'fill_pct_results': [0.0, 0.0, 0.0, 0.0, 0.0, 0.0]}, {'container_id': 'C0003', 'qty_results': [0, 0, 0, 0, 0, 0], 'fill_pct_results': [0.0, 0.0, 0.0, 0.0, 0.0, 0.0]}, {'container_id': 'C0004', 'qty_results': [2310, 2310, 2376, 2376, 2324, 2324], 'fill_pct_results': [77.9, 77.9, 80.1, 80.1, 78.4, 78.4]}]"}]
表示された結果を見ると、求めているデータ構造が得られています。各アイテムを表す行があり、bin_fillsという列には、この特定のアイテムが各ビンにどのように収まるかを表す構造体のリストが含まれています。予想通り、比較的小さいアイテムでは、最大の出荷用コンテナサイズのビンに大量のアイテムを収めることができ、奇形のオブジェクトでは、最初のアイテムの配置がビンの充填率に影響を与えることがわかります。
07.完全なパイプライン:データの読み込み、ロジックの適用、結果の保存
以下のコードは、私たちの完全なパイプラインであり、実際に「本番で実行される」ものです。また、この実行速度を、冒頭で説明した理論的な直列プロセスと比較するためにタイマーも実行します。
最後に、結果をParquetファイルに保存してさらに分析します。この操作では、書き込まれるファイルの数はデータセットのブロック/パーティションの数で制御されます。詳細はRayのドキュメントを参照してください 本番環境では、これらのデータファイルは、Unity Catalogのボリュームなどの本番データストアに書き込む必要があります。
import time
# 出力ファイルの保存先をここに設定します。UCボリュームが推奨されます。実行前にボリュームを作成してください。
output_filepath = "/Volumes/users/takaaki_yayoi/bin_packing_optimization/output"
start_time = time.perf_counter()
# Rayを使用して30アイテムを処理
items_full = (
ray.data.read_parquet(input_filepath)
.map(try_container_n_ray)
.repartition(1) # 合計で1ファイルに強制
.write_parquet(output_filepath)
)
end_time = time.perf_counter()
print(f"Rayの処理にかかった時間は {end_time - start_time} 秒です")
Rayの処理にかかった時間は 45.151948405999974 秒です
08. 結果の分析
Parquetファイルに結果が保存されたので、簡単な計算をしてみましょう。直列で実行した場合、このプロセスはどれくらいの時間がかかるでしょうか?
30個のアイテム × 4つのビン × 6つの開始方向 = 720回の試行
ビンパッキングのロジックを開発する中で、各試行には約1秒かかることを観察しました。したがって、理論的には、Rayを使用した試行よりも約10倍の時間がかかるはずです。Rayを使用した試行は、4つのワーカーノードを使用して約79秒かかりましたが、これにはRayのジョブ設定時間も含まれています。
ビジネスユースケースでは、複雑な状況を10倍速く実行できる能力は非常に重要です。これにより、利益を上げるか損失を被るかという決定の違いが生まれる可能性があります。この最適化パターンは、組み合わせの数(数百万の組み合わせなど)や、クラスタに含まれるRayワーカーノードの数(数十や数百のノードなど)に関係なく、スケーリングが可能です。
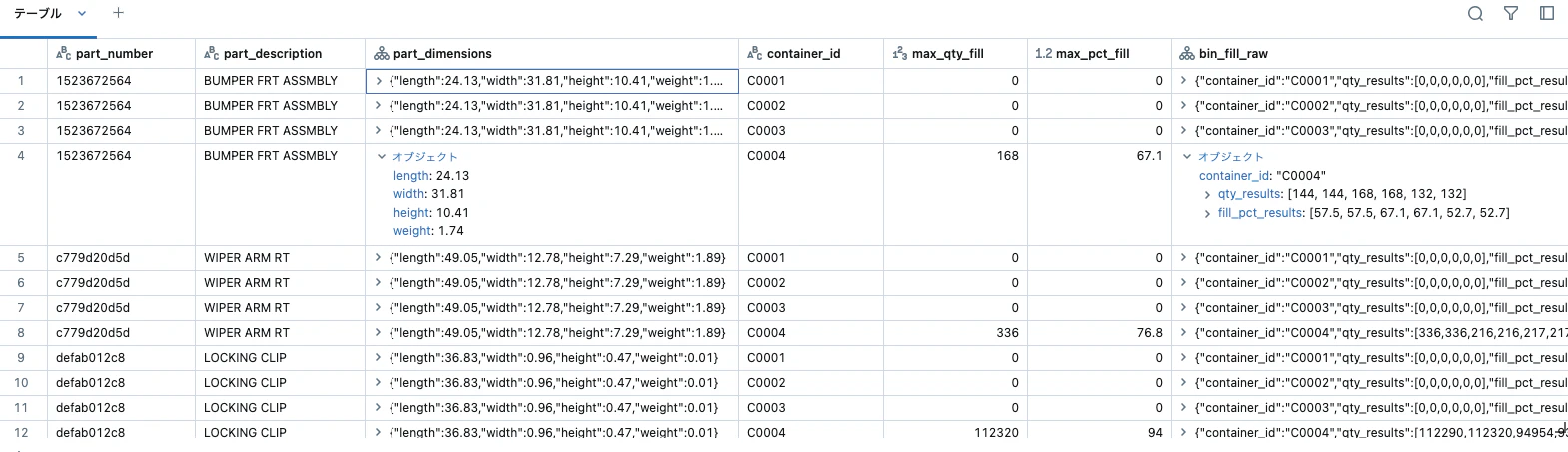
Ray on Databricksのもう一つの利点は、同時にSparkを使用できることです。これを示すために、Rayクラスタがまだ実行中の場合は、以下のPysparkコードを実行して結果のデータセットを解析します。このデータセットは、計画と在庫管理ツールにフィードされる可能性があり、各部品プロデューサーにどのビンを送るかを決定するために使用されます。
注意:
これらのハイブリッドワークロードでの作業については、Ray on Databricksのドキュメントを参照してください。以下は最小限の例です。
from pyspark.sql.functions import *
results = (
spark.read.parquet(output_filepath)
.withColumn(
"bin_fills_cast",
from_json(
col("bin_fills"),
"array<struct<container_id:string,qty_results:array<int>,fill_pct_results:array<double>>>",
),
)
.withColumn("bin_fill_raw", explode("bin_fills_cast"))
.withColumn("container_id", col("bin_fill_raw.container_id"))
.withColumn("max_qty_fill", array_max(col("bin_fill_raw.qty_results")))
.withColumn("max_pct_fill", array_max(col("bin_fill_raw.fill_pct_results")))
.withColumn(
"part_dimensions",
struct(col("length"), col("width"), col("height"), col("weight")),
)
.select(
"part_number",
"part_description",
"part_dimensions",
"container_id",
"max_qty_fill",
"max_pct_fill",
"bin_fill_raw",
)
)
display(results)
09. 結論
科学技術計算は、シミュレーションや最適化、線形計画法や数値解析など、さまざまな技術を含んでいます。これは、数十年にわたる実証済みの技術が存在する広範な領域であり、多くの企業が現在使用しているソリューションは、シングルノードや垂直スケーリングの計算インフラストラクチャ向けに構築されたものです。しかし、Ray Coreは強力な水平スケーリングフレームワークを提供しています。
Ray on Databricksを使用することで、ビンパッキングなどの計算上複雑な問題を、わずかなコードの調整で10倍高速に実行することがどれだけ簡単かをご覧いただきました。これにより、ビジネスの成果を向上させるための取り組みが可能となります。