Vibe Coding Your First Databricks App | by AI on Databricks | Sep, 2025 | Mediumの翻訳です。
本書は著者が手動で翻訳したものであり内容の正確性を保証するものではありません。正確な内容に関しては原文を参照ください。

著者: Arnav Chaudhary, Solutions Architect
イントロダクション
Cursor、Windsurf、Github Copilot、Claude CodeのようにAIを活用したIDEの爆発によって、ソフトウェアエンジニアリングやアプリケーション開発はこれまでにないほどアプローチが容易になっています。「バイブコーディング」は、今時点における全てのハイプであり、これらAIを活用したIDが全てのスキルレベルの開発者に価値を解放する迅速な開発ループを説明するための用語としてAndrej Karpathyによって個人的に命名されたものでした。
このガイドのゴールは、はじめてのDatabricksアプリのバイブコーディングがアプローチ可能であると感じていただけるようにすることです。初心者がローカルのIDEをセットアップし、ローカルからDatabricksワークスペースに対する開発ループをテストし、ユーザーフィードバックを得るためのはじめてのDatabricksアプリをデプロイする助けとなれば幸いです。
もしあなたが「自分たちのビジネスステークホルダー向けの軽量Webアプリを構築したいけど、DashやFastAPI/Flask、Reactも知らないだよな」と思ったことのあるデータのプロフェッショナルであるならば、このガイドはあなたのためのものです。ここでは、1時間でゼロからプロダクションレベルのアプリケーションに到達するために、純粋なPythonとAIの支援、Databrikcs Appsを活用します。
初めてみる: 何を構築するのか?
このブログの最後には、Dashを使ってご自身のDatabricksアプリをデプロイできるようになります。このアプリは、Databricks Appsが企業で活用できるレベルであること、あなたのデータプラットフォームの側でアプリケーションを構築できることの柔軟性とパワーを説明します。ここでは、Databricksプラットフォームの3つのコアコンポーネントを活用します:
- インタラクティブなAI/BIダッシュボード: あなたのアプリケーションに直接埋め込まれたDatabricks AI / BIダッシュボード (+ Genie)を表示します。
- チャットbotエージェント: 自然言語によるデータの問い合わせに対してGenieとAgent Bricksのマルチエージェントスーパーバイザーを活用します。
- Databricksモデルサービング: あなたのアプリケーションに埋め込まれるチャットbotを支援します。
この概要をあなたの本格運用アプリケーションに対するイントロダクションとして考えましょう。Databricks ApssはUnity Catalogを通じたビルトインのガバナンスを通じて提供されるので、セキュアでエンタープライズレベルのアプリをクイックに構築、試行錯誤することができ、OIDC/OAuth 2.0 + SSOを通じてユーザーの認証を保護することができます。さらに、個々のDatabricksのコンポーネントがあなたのアプリの改善を示すに従って、あなたのアプリは徐々にビジネス価値を推進することになります。
なぜこのアーキテクチャが重要なのか
デプロイするこれらの3つのサービスは個別のものですが、相互補完するものです。AI/BIダッシュボードはビジュアルで考える人に対して運用上の洞察やトレンドを提供します。チャットボットによって、質問を通じて考える人に対して会話型のデータ探索を可能にします。Agent Brikcsとモデルサービングを通じてデプロイを行うことで、MLflowとAgent Frameworkを解放し、本格運用における品質の追跡と監視を可能にします。
Databricks Appsは、インテグレーションとデプロイメントのプロセスを抽象化することで開発者を支援します。認証フロー、セキュアなエンドポイントのコミュニケーション、環境管理のすべてはプラットフォームによって自動で対応されます。Pythonコードを記述すれば、Databricks Appsが企業の要件に対応します。
これは、データチームがどのように価値を提供するのかに関するシフトをもたらします。ユーザーがツールに適応するのではなく、ユーザーに適応するツールを構築することになります。あなたのアプリは、あなたのデータプラットフォームに対するカスタムインタフェースとなり、チャート、会話、カスタマイズされたデータドリブンのワークフローを通じて、彼らの嗜好に基づいてユーザーに適応させることが可能となります。
前提条件
環境の準備をしましょう。いくつかのツールが初めてでも心配しないでください、あなたの能力を学び徐々に改善するために必要なものの全てはバイブコーディングです。
- Databricksワークスペース
- AIを活用するIDEへのアクセス(Cursor, Github Copilot, Windsurf)
- 目的に特化したGenieスペース
- Agent Bricks - 作成、サービングされたマルチエージェントスーパーバイザー
- ローカルにインストールされたPython 3.11+
なぜDash?
このガイドでは、これまでにアプリを構築をしたことのないデータペルソナにとって最もアプローチしやすいフレームワークでありながらも、試行錯誤を通じて複雑になったとしても十分な柔軟性を提供するDashを活用します。Databricks Appsはさらに高度なハイブリッドアプローチ(フロントエンドはReact.js + バックエンドはFastAPI)もサポートします。さらに、Dashは豊富なビジュアライゼーションのエコシステムを有しており、Databricksと容易に連携し、コールバックを通じた自動状態管理を可能にします。
pandasやmatplotlibに慣れ親しんでいるのであれば、Dashに必要なことの80%は知っていることになります!
ステップバイステップの実装
ステップ1: Databricks CLIと認証のセットアップ
はじめに、あなたのローカルマシンとDatabricksっワークスペースの接続を確立しましょう。迅速なローカルの開発ループ + Databricksのデプロイメントのテストをサポートするためはこれは重要なことです。
# Install Databricks CLI if you haven't already
pip install databricks-cli
# Configure your connection
databricks configure
プロンプトが表示されたら以下を入力します:
-
Databricks Host: あなたのワークスペースのURL(
https://dbc-123456.cloud.databricks.com/など) - Personal Access Token: 設定 → 開発者 → アクセストークンで作成
設定を確認しましょう:
# Check your configured profiles
databricks auth profiles
# List workspace contents to confirm connection
databricks workspace list /
ステップ2: Databricks Appプロジェクトの初期化
次に進んで、ローカルマシンで空のディレクトリを作成します。
# Create a new directory for your app
mkdir my-first-databricks-app
cd my-first-databricks-app
お使いのDatabricksワークスペースで、コンピュートに移動してパネルの右上のアプリをクリックします。そこから「アプリの作成」をクリックし、フレームワークとして「Dash」を選択し、テンプレートとして「チャットボット」を選択し、ドロップダウンからあなたのマルチエージェントエンドポイントを選択します。
これで以下のような画面が表示されるはずです。
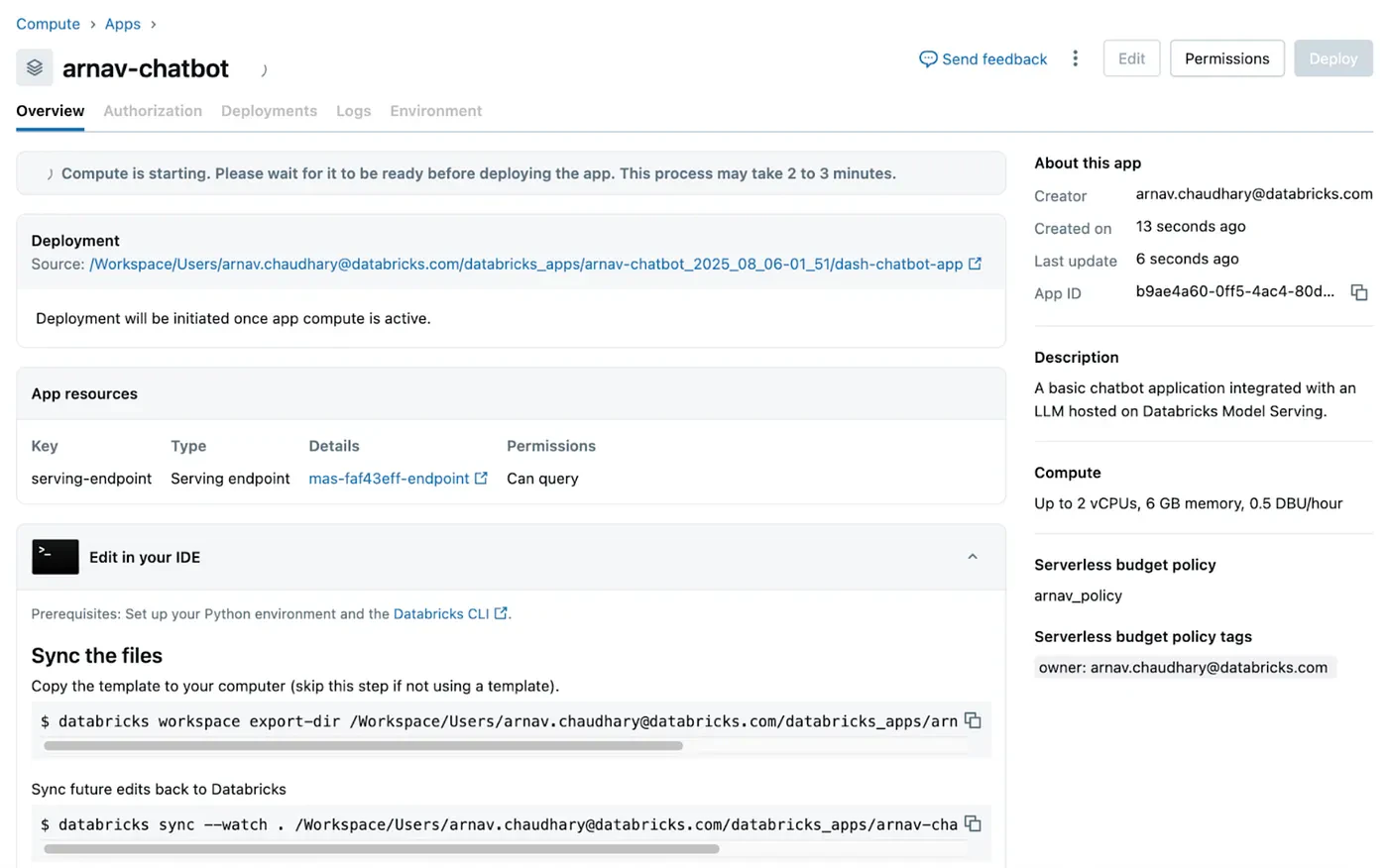
これで、ローカルマシンでdatabricks workspace export-dirコマンドを実行できます。
databricks workspace export-dir /Workspace/Users/your.email@company.com/apps/your-app-name ./
これによって、あなたのためにDatabricksが作成した完全なアプリの構成をダウンロードすることになります。AIを活用したIDEは、必要最低限のテンプレートからスタートできることで大きなメリットを享受できます。これによって、AIが生成するコードのタイプに関して開発者の助けとなるように、開始時点のスコープを限定する助けとなります。
ステップ3: UVバッケージマネージャのセットアップ
パッケージ管理にはUVを使います。UVはRustで記述されており、依存関係のロードに関してPIPよりも10-100倍高速と言われています。
# Install UV
curl -LsSf https://astral.sh/uv/install.sh | sh
# Initialize UV in your project
uv init .
# Create and activate a virtual environment
uv venv
source .venv/bin/activate # On Windows: .venv\Scripts\activate
# Install dependencies at lightning speed
# First, find the requirements.txt in your exported app
uv pip install -r requirements.txt
UVによってあなたの開発体験はより高速でシンプルになります。
ステップ4: 初めてのバイブコーディングのプロンプト - モデルサービングエンドポイントの修正
アプリケーションを実行する際には、一般的な開発上の課題に直面することになります。何が起きるのかを見てみましょう: ターミナルからあなたのディレクトリでCursorをオープンしましょう:
cursor
Cursroウィンドウでtop bar > Terminal > New Terminalに移動します。これで、IDEでターミナルを開きます。ターミナルに移動して以下を実行します: uv run python app.py
以下のようなエラーメッセージが表示されるはずです:
AssertionError: Unable to determine serving endpoint to use for chatbot app.
If developing locally, set the SERVING_ENDPOINT environment variable to the
name of your serving endpoint. If deploying to a Databricks app,
include a serving endpoint resource named 'serving_endpoint'
with CAN_QUERY permissions, as described in
https://docs.databricks.com/aws/en/generative-ai/agent-framework/chat-app#deploy-the-databricks-app
これは想定の範囲内です!Databricksのテンプレートは、エンドポイントが自動的に設定されたDatabricks環境で実行されることを前提としています。ローカルにデプロイする際には、エンドポイントの特定方法をアプリに教える必要があります。修正するためにCursorを使いましょう。以下のプロンプトをコピーします。モードが「エージェント」になっており、モデルが「claude-4-sonnet」であることを確認してください。また、モデルを「オート」に設定できますが、初心者のコーデイングアシスタントには「claude-4-sonnet」がおすすめです。
"I have a Databricks chatbot app that I need to run both locally for development and deploy as a Databricks app. I'm getting this error when trying to run it locally: AssertionError: Unable to determine serving endpoint to use for chatbot app. If developing locally, set the SERVING_ENDPOINT environment variable to the name of your serving endpoint. If deploying to a Databricks app, include a serving endpoint resource named 'serving_endpoint' with CAN_QUERY permissions
My serving endpoint is: <REPLACE_WITH_ENDPOINT>
I'm using uv for package management (I have a uv.lock file). Can you:
1. Fix local development setup so I can test with uv run python app.py
2. Fix the Databricks deployment config - so it works when deployed as a Databricks app
3. Update all documentation to use uv commands instead of pip
4. Make it work seamlessly in both environments without manual configs.
I want to be able to run locally for testing, then deploy to Databricks without any code changes."
これでアプリが起動するはずです!ローカルのリンクにアクセスしてチャットbotを試しましょう。メッセージを送信する際に「400 Client Error」に遭遇するかもしれませんがこれは正常です。DashテンプレートはあなたのAgentBricksエンドポイントが期待する正確なフォーマットをしりません。ダッシュボードの機能を追加した後にステップ6で修正します。
ステップ5: AI/BIダッシュボードの埋め込み
タブナビゲーションを持つAI/BIダッシュボードの埋め込みにはこちらのプロンプトが役に立ちます。
Cursorは既存のDatabricksアプリのテンプレートコードを解析して、修正案を提示します。ローカルでテストしているときと、Databricksワークスペースにでデプロイしたものをテストする際に固有の設定を追加するほどに賢いです。上述のダッシュボードのURLを更新する必要があるでしょう。Dashboard > Share > Embed Dashboard > Iframeの「src」のURLをコピーします。
ステップ6: Agent Bricksを活用したチャットbotの追加
次に、Databricksのマルチエージェントスーパーバイザーに接続するアプリのインタラクティブなチャットボックスを作成します。このAgent BrickはGenieエージェント、Vector Searchエージェントをオーケストレートし、MCPサーバーやUnity Catalogのツールや関数に接続できます。マルチエージェントスーパーバイザーは、Databricksで効果的に管理されるサブエージェントを用いた複合AIシステムの構築に最適な手段となります。また、Agent BricksはMlflowエクスペリメントと共にすぐに利用できるので、エージェントの品質を管理することができます。
こちらは、インタラクティブなユーザー体験を提供する巧妙でインタラクティブなチャットボックスを作成するために活用できるプロンプトとなります。これは、ステップ4でボックスに何か入力した際に遭遇するチャットボットのエラーを解消するはずです。
Cursorのターミナルで「uv run python app.py」を実行してこのプロンプトをテストしましょう。
ステップ7: Databricksへのアプリのデプロイ
あなたのDatabricksアプリのページ(上のスクショ)に移動して、「databricks sync . . .」コマンドをコピーしましょう。これによって、ローカルのリポジトリをDatabricksアプリに同期することができます。デプロイをクリックするとアプリが問題なく動作しているはずです!
まとめ
誰かが開発は範疇外と考えたものからプロダクションレベルのDatabricksアプリを1時間以内で作り上げることができました。Reactを学んだり、認証に苦戦したり、インフラストラクチャを心配する必要はありません。自然言語で必要なことを説明して、試行錯誤を通じて改善すればいいのです。
あなたのアプリは、リアルなビジネス問題を解決する3つのパワフルな機能を組み合わせました:
- ユーザーに直接洞察を提供するダッシュボードを埋め込みました。
- 自然源とを通じてデータアクセスを民主化する会話型のAI。
- インタラクティブなユーザー体験のための活発で創造的なチャットボット。
しかし、真の魔法はこちらです: DatabricksはAI/BIダッシュボードの強化、Agent Bricksの改善、Unity Catalogの機能拡張を継続しても、あなたのアプリは自動的にこれらの改善を引き継ぐことになります。あなたは、あなたと共に進化するプラットフォームで構築を行なったのです。
次のステップは:
- ビジネスステークホルダーとアプリを共有してフィードバックをもらいましょう。
- 彼らのインプットに対して、バイブコーディングを用いてカスタム機能を追加しましょう。
- 思いついたら新機能でアプリを検証、強化しましょう。
あなたのアイデアとデプロイされたアプリケーションの間にある障壁はかつてないほどに低くなっています。バイブコーディングのベストプラクティスに踏み込んで、より高度な機能を構築するパート2を楽しみにしていてください。