最近までDatabricksのノートブックギャラリーなるものがあることに気づいていませんでした。
今日はその中からこちらのノートブックを試してみます。
Instacartの注文情報を用いたマーケットバスケット分析です。こちらの記事で説明しているノートブックはこちらとなります。
イントロダクション
Databricksのレイクハウスプラットフォームにおけるマーケットバスケット分析のコンセプトを説明するために、Instacartの300万のオーダーデータセット、3 Million Instacart Orders, Open Sourcedを使用します。
“The Instacart Online Grocery Shopping Dataset 2017”, Accessed from https://www.instacart.com/datasets/grocery-shopping-2017 on 01/17/2018.
この匿名化されたデータセットには、200,000以上のInstacartユーザーによる300万もの雑貨注文のサンプルが含まれています。
ユーザーごとに4から100の注文があり、注文ごとの購入の順番も含まれています。また、注文があった週と時間も含まれており、注文間の相対的な時間間隔も含まれています。
綿密に計画された雑貨品のリストに基づいて買い物するか、自分の直感に基づいてみたものを購入するのか、いずれにしてもユニークな食べ物の習慣はあなたが誰であるのかを定義します。Instacartの雑貨注文と配送アプリは、あなたの個人的好みと必要な時には特産品で冷蔵庫と食料品置き場を容易に満たすことを狙いとしています。Instacartのアプリで商品を選択した後に、自身の注文のパーソナルレビューを行い、店舗内ショッピングやデリバリーを提供します。
このノートブックでは、どの商品を再び購入するのかをどのように予測し、初回に試すことをレコメンドするのかを説明します。

Source: 3 Million Instacart Orders, Open Sourced
データエンジニアリングパイプライン

一般的にデータエンジニアリングパイプラインはこれらのコンポーネントから構成されます。
- データの取り込み: ソースシステムからデータの持ち込み。多くの場合ETLプロセスが関係します(このデモではシンプルさのためこのステップをスキップします)。
- データの探索: クレンジングされたデータが入手できたので、いくつかのビジネス洞察を得るためにデータを探索します。
- MLモデルのトレーニング: 頻出パターンマイニングのためにFP-growthを実行します。
- アソシエーションルールのレビュー: 生成されたアソシエーションルールをレビューします。
データの取り込み
はじめに、3 Million Instacart Orders, Open Sourcedをダウンロードし、dbfsにアップロードします。詳細についてはデータのインポートをご覧ください。
dbutils filesystem (fs)のクエリーコマンドを実行すると6つのファイルが表示されます。
-
Orders: 3.4M 行, 206K ユーザー -
Products: 50K 行 -
Aisles: 134 行 -
Departments: 21 行 -
order_products__SET: 30M+ 行 ここではSETは以下のように定義されます:-
prior: 3.2M の事前の注文 -
train: トレーニングデータセットのための 131K の注文
-
リファレンス: The Instacart Online Grocery Shopping Dataset 2017 Data Descriptions
重要!
データをアップロードした場所に応じて、格納場所(以下の例では /FileStore/shared_uploads/takaaki.yayoi@databricks.com/market_basket/ を使用しています)を編集する必要があります。
注意
2022/5/30時点では上記リンク先のデータセットが利用できないため、Kaggleからデータをダウンロードしています。
取り込みデータの確認
%fs ls /FileStore/shared_uploads/takaaki.yayoi@databricks.com/market_basket/

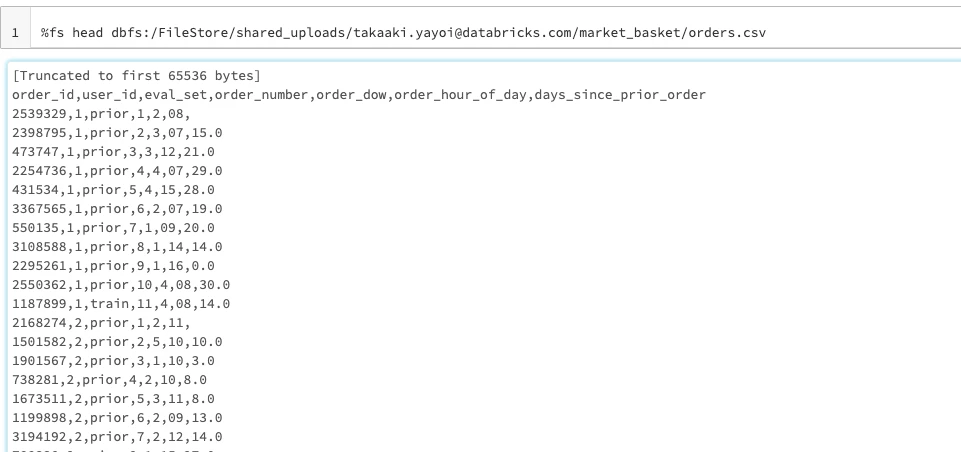
orders.csvファイルの確認
%fs head dbfs:/FileStore/shared_uploads/takaaki.yayoi@databricks.com/market_basket/orders.csv
データフレームの作成
dataset_path = "/FileStore/shared_uploads/takaaki.yayoi@databricks.com/market_basket"
# データのインポート
aisles = spark.read.csv(f"{dataset_path}/aisles.csv", header=True, inferSchema=True)
departments = spark.read.csv(f"{dataset_path}/departments.csv", header=True, inferSchema=True)
order_products_prior = spark.read.csv(f"{dataset_path}/order_products__prior.csv", header=True, inferSchema=True)
order_products_train = spark.read.csv(f"{dataset_path}/order_products__train.csv", header=True, inferSchema=True)
orders = spark.read.csv(f"{dataset_path}/orders.csv", header=True, inferSchema=True)
products = spark.read.csv(f"{dataset_path}/products.csv", header=True, inferSchema=True)
# 一時テーブルの作成
aisles.createOrReplaceTempView("aisles")
departments.createOrReplaceTempView("departments")
order_products_prior.createOrReplaceTempView("order_products_prior")
order_products_train.createOrReplaceTempView("order_products_train")
orders.createOrReplaceTempView("orders")
products.createOrReplaceTempView("products")
探索的データ分析(EDA)
Spark SQLを用いてInstacartデータを探索します。
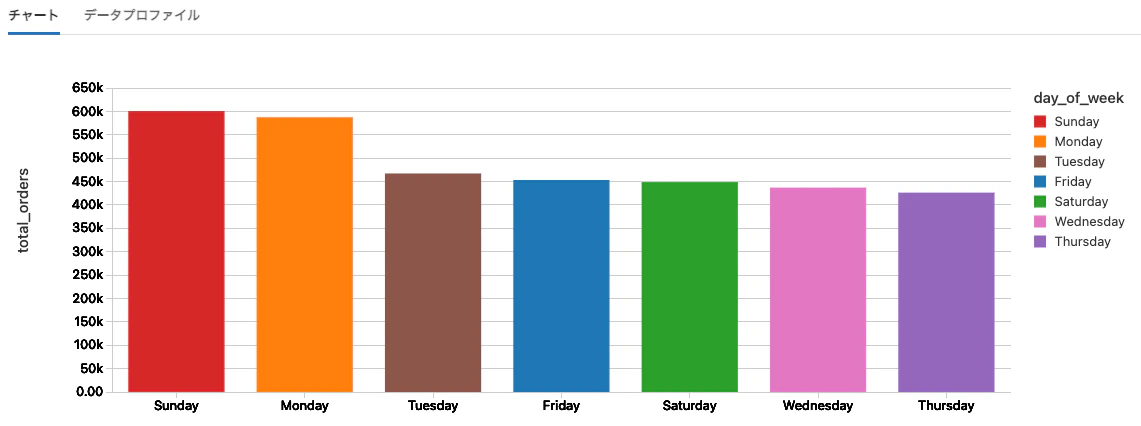
最も忙しい曜日
%sql
select
count(order_id) as total_orders,
(case
when order_dow = '0' then 'Sunday'
when order_dow = '1' then 'Monday'
when order_dow = '2' then 'Tuesday'
when order_dow = '3' then 'Wednesday'
when order_dow = '4' then 'Thursday'
when order_dow = '5' then 'Friday'
when order_dow = '6' then 'Saturday'
end) as day_of_week
from orders
group by order_dow
order by total_orders desc
プロットオプションは以下の通りとなっています。
時間ごとの注文のブレークダウン
%sql
select
count(order_id) as total_orders,
order_hour_of_day as hour
from orders
group by order_hour_of_day
order by order_hour_of_day
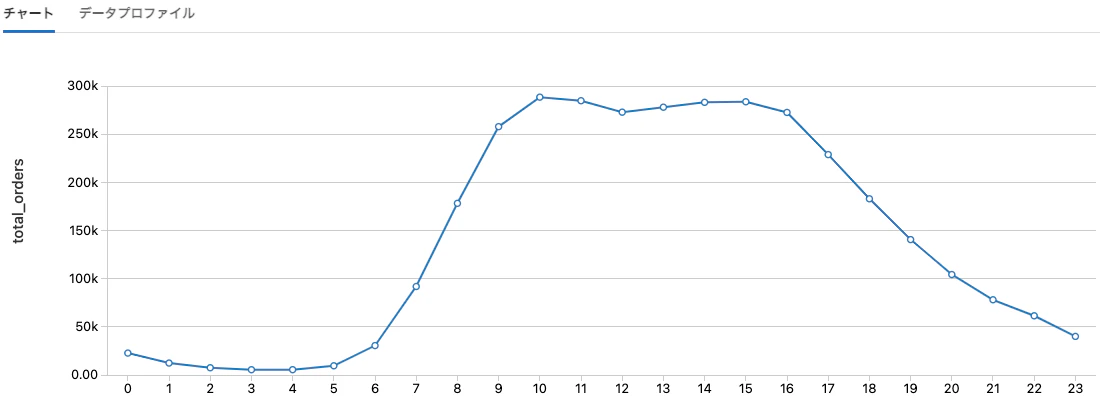
プロットオプションは以下の通りとなっています。
部門ごとの売り上げが最大の商品
%sql
select countbydept.*
from (
-- productsテーブルから部門ごとのレコード数をカウントし、カウントでソート(高いとこから低いところに)してみましょう。
select department_id, count(1) as counter
from products
group by department_id
order by counter asc
) as maxcount
inner join (
-- エクササイズを繰り返しますが、今回はdeptとprodカウントの完全なリストを得るために、productsとdepartmentsテーブルをjoinします。
select
d.department_id,
d.department,
count(1) as products
from departments d
inner join products p
on p.department_id = d.department_id
group by d.department_id, d.department
order by products desc
) countbydept
-- 商品カウントをマッチさせることで2つのクエリーの結果を組み合わせます。
on countbydept.products = maxcount.counter
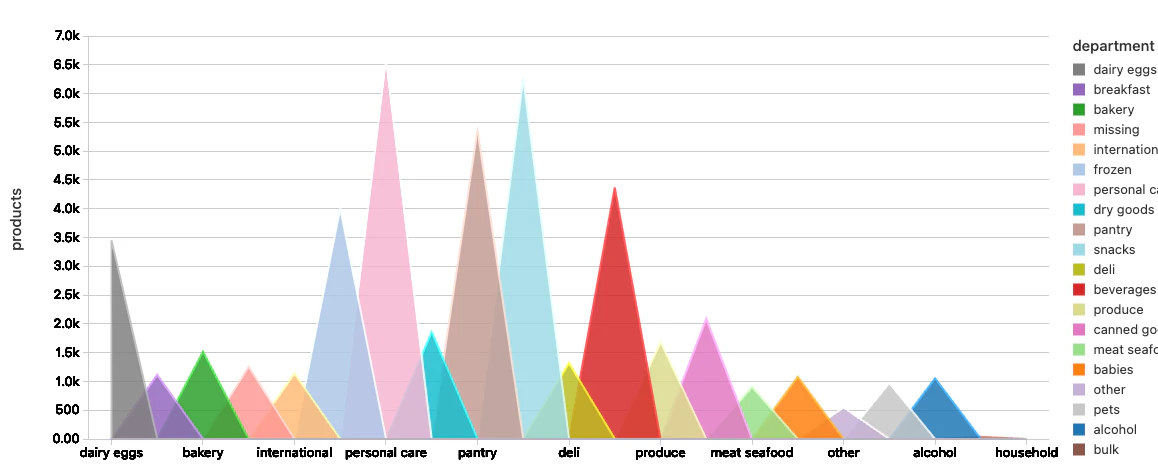
プロットオプションは以下の通りとなります。
人気アイテムトップ10
%sql
select count(opp.order_id) as orders, p.product_name as popular_product
from order_products_prior opp, products p
where p.product_id = opp.product_id
group by popular_product
order by orders desc
limit 10
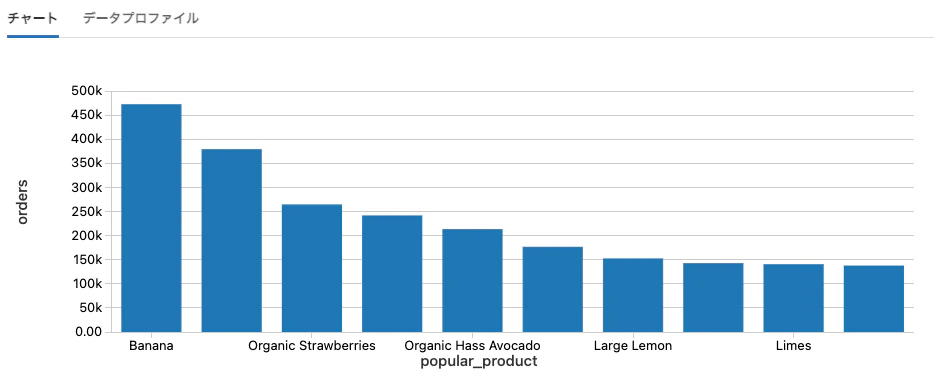
プロットオプションは以下の通りとなります。
部門ごとの棚のスペース
%sql
select d.department, count(distinct p.product_id) as products
from products p
inner join departments d
on d.department_id = p.department_id
group by d.department
order by products desc
limit 10
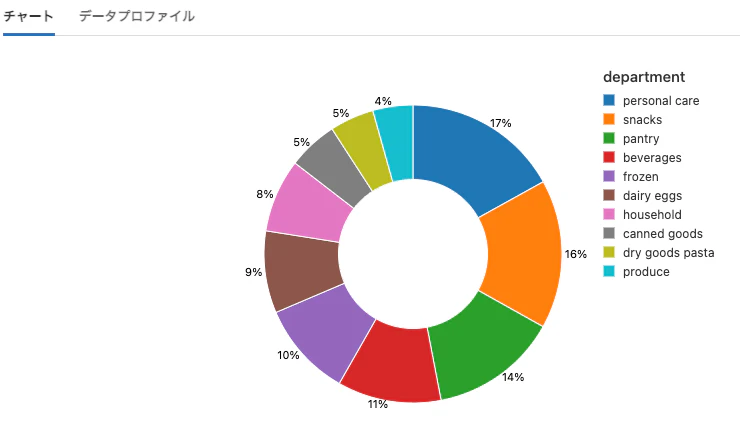
プロットオプションは以下の通りとなります。
買い物バスケットの整理及び参照
マーケットバスケット分析に向けてデータを準備します。
# 買い物バスケットごとにデータを整理
from pyspark.sql.functions import collect_set, col, count
rawData = spark.sql("select p.product_name, o.order_id from products p inner join order_products_train o where o.product_id = p.product_id")
baskets = rawData.groupBy('order_id').agg(collect_set('product_name').alias('items'))
baskets.createOrReplaceTempView('baskets')
データを確認します。
display(baskets)

MLモデルのトレーニング
互いに関連づけられているアイテムの頻度(ピーナッツバターとジャムなど)を理解するために、マーケットバスケット分析のためのアソシエーションルールマイニングを使用します。Spark MLlibでは頻度パターンマイニング(FPM)に関連する2つのアルゴリズムを実装しています。FP-growth と PrefixSpanです。違いは、FP-growthはアイテムセット内の順番を使用せず、PrefixSpanはアイテムセットに順序がある場合のシーケンシャルパターンマイニングのために設計されているということです。このユースケースでは順番の情報は重要ではないので、ここではFP-growthを使用します。
ここでは
Scala APIを使用するのでsetMinConfidenceを設定できることに注意してください。
FP-growthの使用
%scala
import org.apache.spark.ml.fpm.FPGrowth
// アイテムの抽出
val baskets_ds = spark.sql("select items from baskets").as[Array[String]].toDF("items")
// FPGrowthの使用
val fpgrowth = new FPGrowth().setItemsCol("items").setMinSupport(0.001).setMinConfidence(0)
val model = fpgrowth.fit(baskets_ds)
最頻アイテムセット
%scala
// 頻出するアイテムセットの表示
val mostPopularItemInABasket = model.freqItemsets
mostPopularItemInABasket.createOrReplaceTempView("mostPopularItemInABasket")
%sql
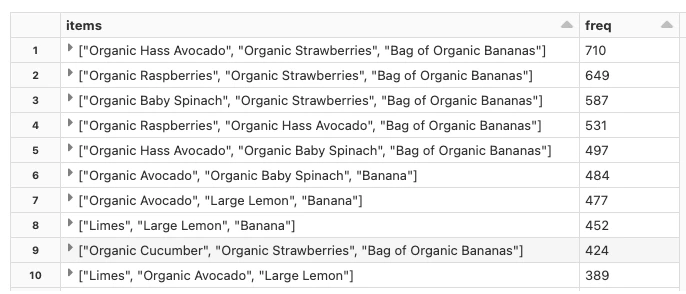
select items, freq from mostPopularItemInABasket where size(items) > 2 order by freq desc limit 20
アソシエーションルールのレビュー
freqItemSetsに加え、FP-growthはアソシエーションルールを生成します。例えば、あるお客様がピーナッツバターを購入する場合、同時に購入するであろう商品はジャムとなります。詳細に関しては、Susan Liの良いリファレンスであるA Gentle Introduction on Market Basket Analysis — Association Rulesをご覧ください。
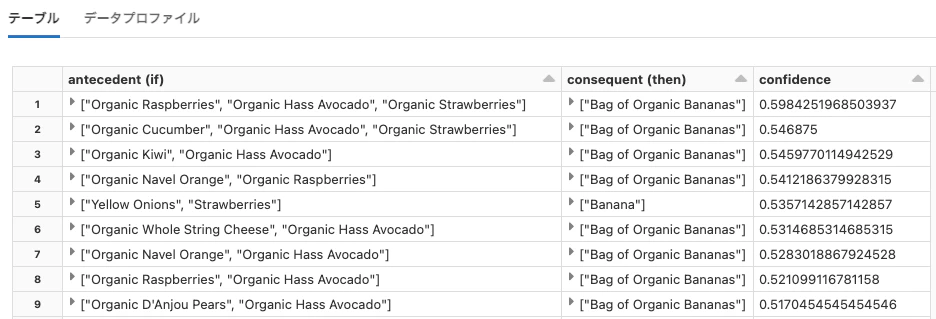
生成されたアソシエーションルールの参照
%scala
// 生成されたアソシエーションルールの表示
val ifThen = model.associationRules
ifThen.createOrReplaceTempView("ifThen")
%sql
select antecedent as `antecedent (if)`, consequent as `consequent (then)`, confidence from ifThen order by confidence desc limit 20