Get to Know Your Queries With the New Databricks SQL Query Profile! - The Databricks Blogの翻訳です。
本書は抄訳であり内容の正確性を保証するものではありません。正確な内容に関しては原文を参照ください。
Databricks SQLは、DatabricksのレイクハウスプラットフォームにおけるSQLのファーストクラスサポートとデータウェアハウスの機能を提供し、レガシーなクラウドデータウェアハウスの一部のコストでより迅速に新たな洞察を発見、共有するための分析を可能とします。
この記事は、パフォーマンス、使いやすさ、ガバナンスに関する重要な機能をカバーするDatabricks SQLの記事シリーズの一部です。以前のブログ記事では、最新のユーザー体験の強化を説明しました。本記事では、ユーザーによるクエリー自身の理解、クエリーパフォーマンスの理解を支援する機能改善を説明します。
実行時のボトルネックを特定することでクエリーのスピードを改善する
Databricks SQLは自動でクエリーを高速化することに長けています。実際のところ我々は世界記録を打ち立てました!これまでの技術革新があったとしても、クエリー実行の内部を検証する必要(例えば、予想以上にクエリーが遅い場合)はあります。だからこそ、クエリー実行の詳細と、計算リソースがどのように消費されているのかを確認できる詳細なメトリクスを提供する新機能のクエリープロファイルをご紹介できることを大変嬉しく思っています。このUIはデータベースを触っていた管理者には親しみやすいものになっています。
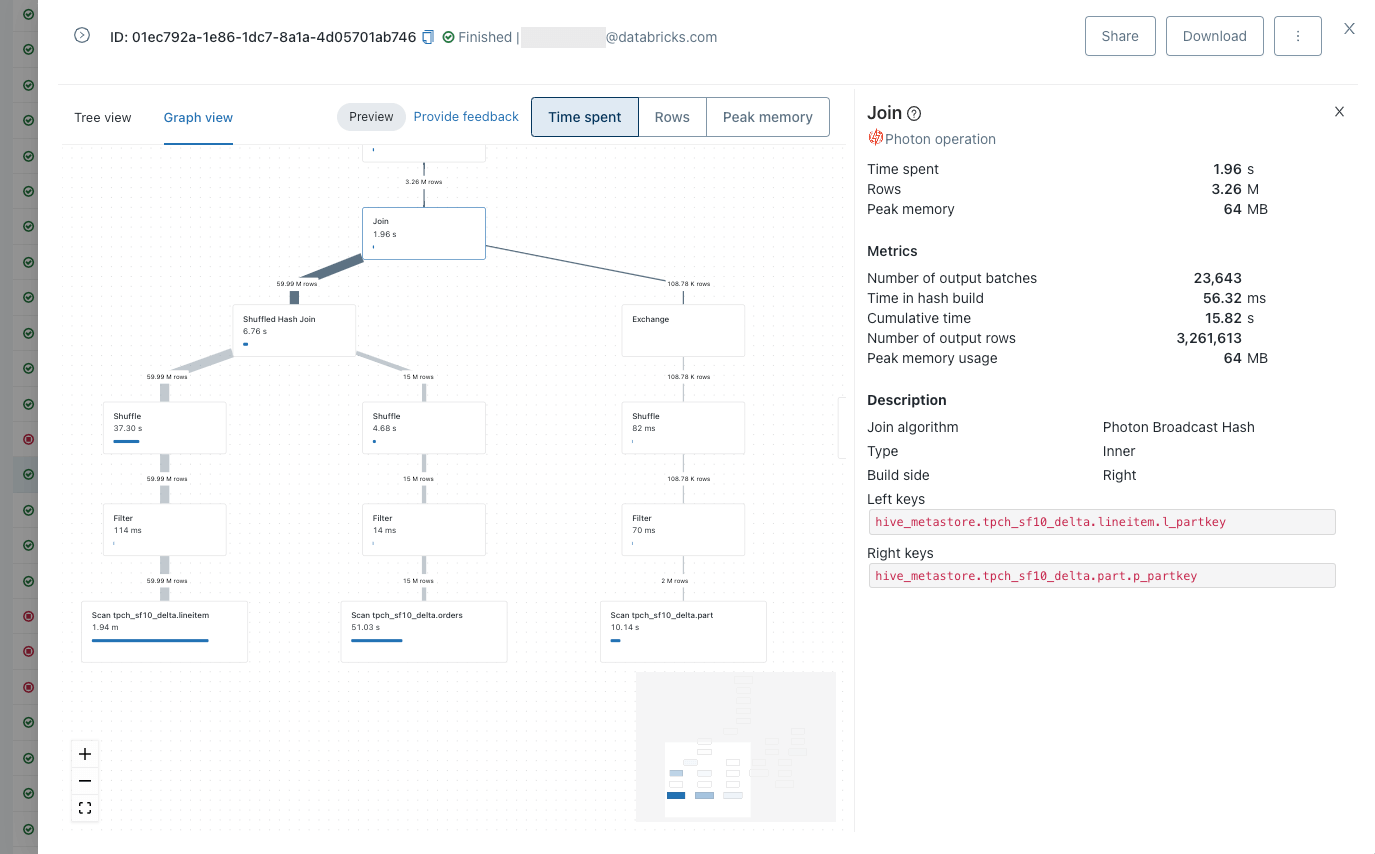
クエリープロファイルには以下の機能が含まれています。
- クエリー実行の主要コンポーネントのブレークダウンと関連メトリクス:タスクに要した時間、処理された行数、メモリー消費量。
- 複数のグラフィカルな表現。これには、一覧して遅い処理を特定するための複合ツリービュー、クエリーのオペレーター間のデータフローを理解するためのグラフビューが含まれます。
- 一般的なクエリーの間違いを容易に発見するための機能(例えば、joinの爆発やフルテーブルスキャン)。
- クエリープロファイルのダウンロードや共有機能によるコラボレーションの改善。
クエリーを高速化する一般的な方法論は、まず最も時間を要しているクエリーオペレーターを特定するというものです。我々は分散システムと分散処理可能なオペレーターを取り扱っているので、オペレーターの正確な「処理時間」よりも、タスクの合計の処理時間に興味を持っています。
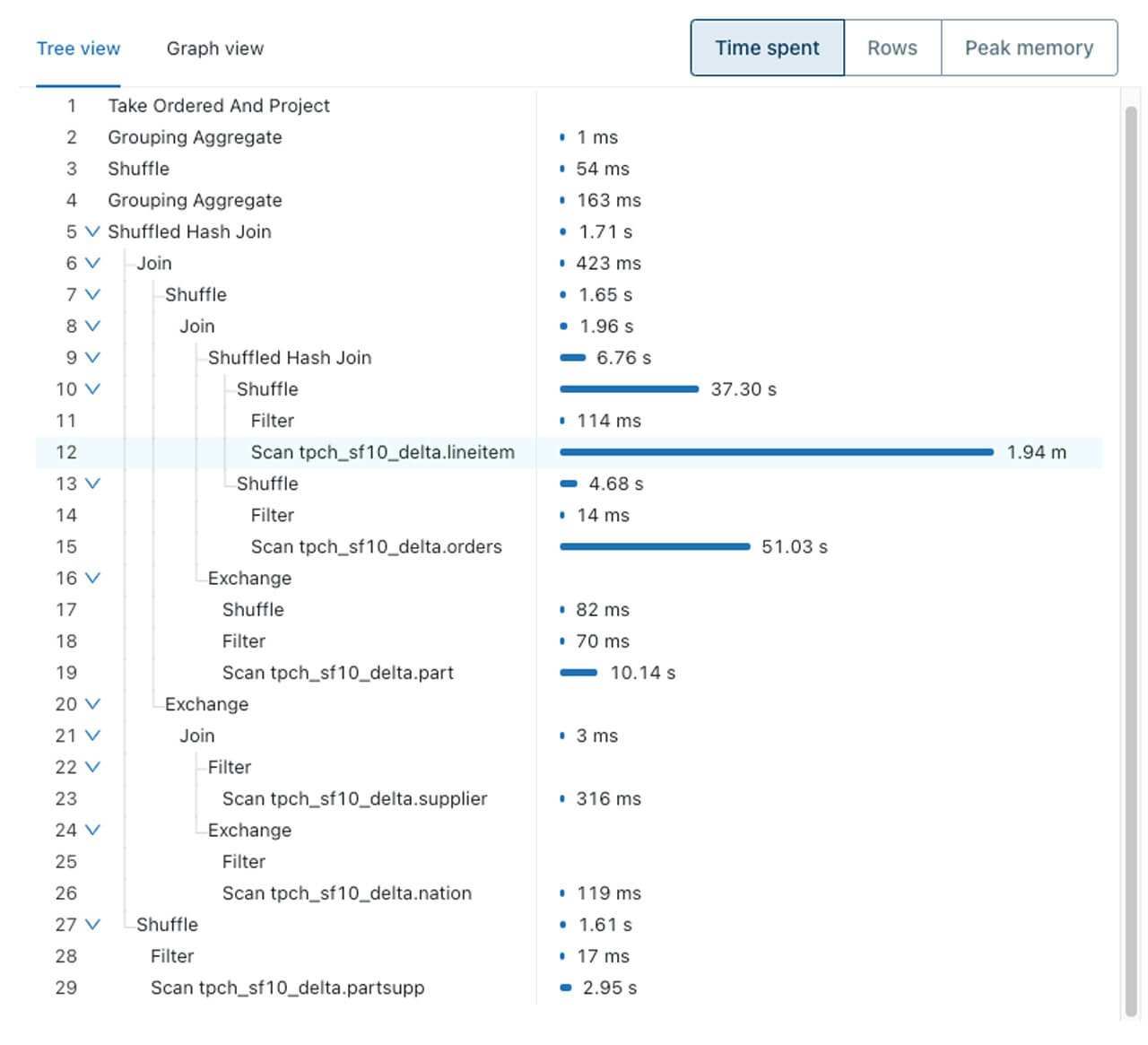
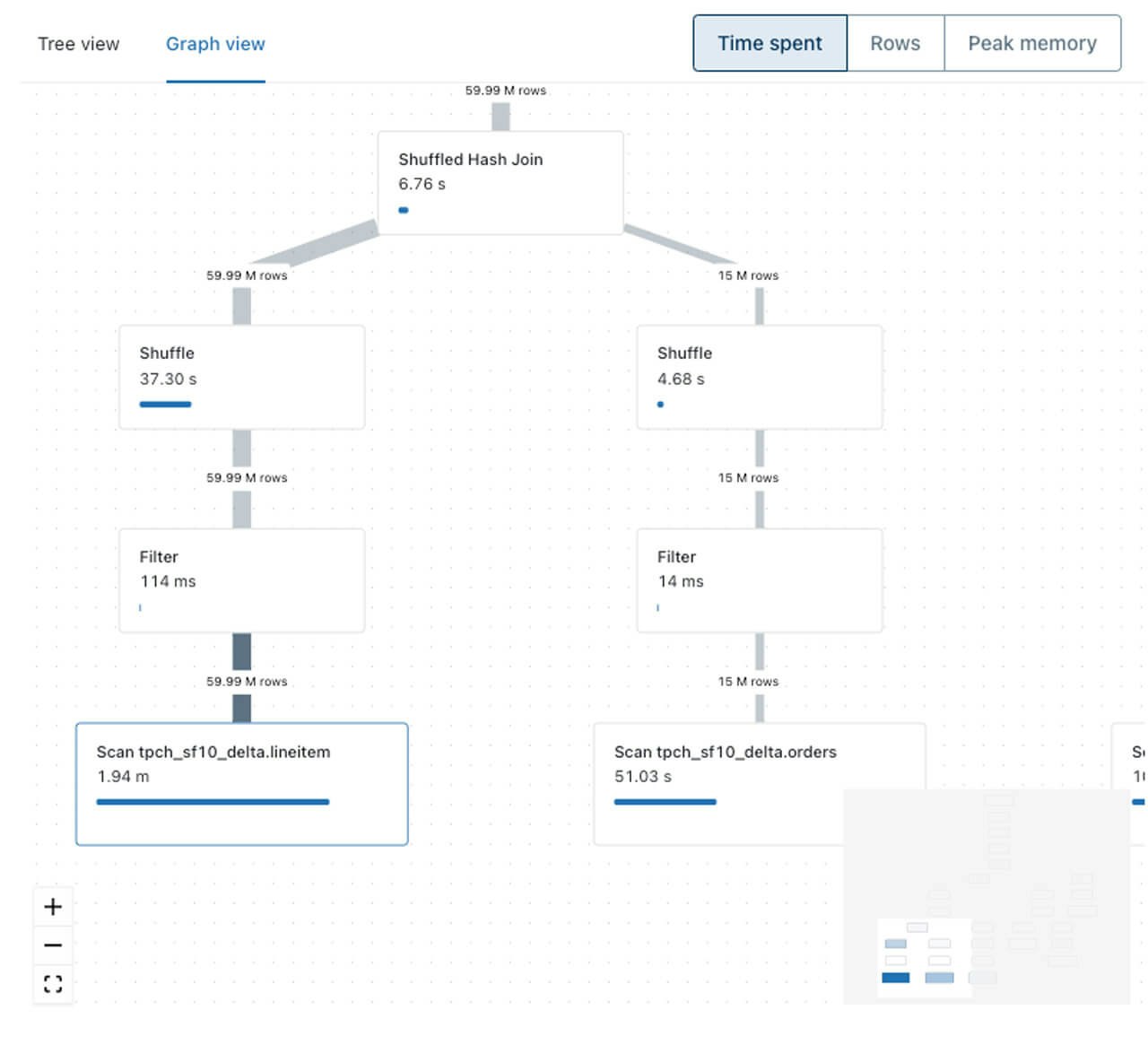
上述した、あるTCP-Hクエリーのクエリープロファイルか、容易に最もコストを要しているオペレーターを特定することができます。この場合はテーブルlineitemのスキャンとなっています。二番目にコストを要しているのは別のテーブル(orders)のスキャンです。
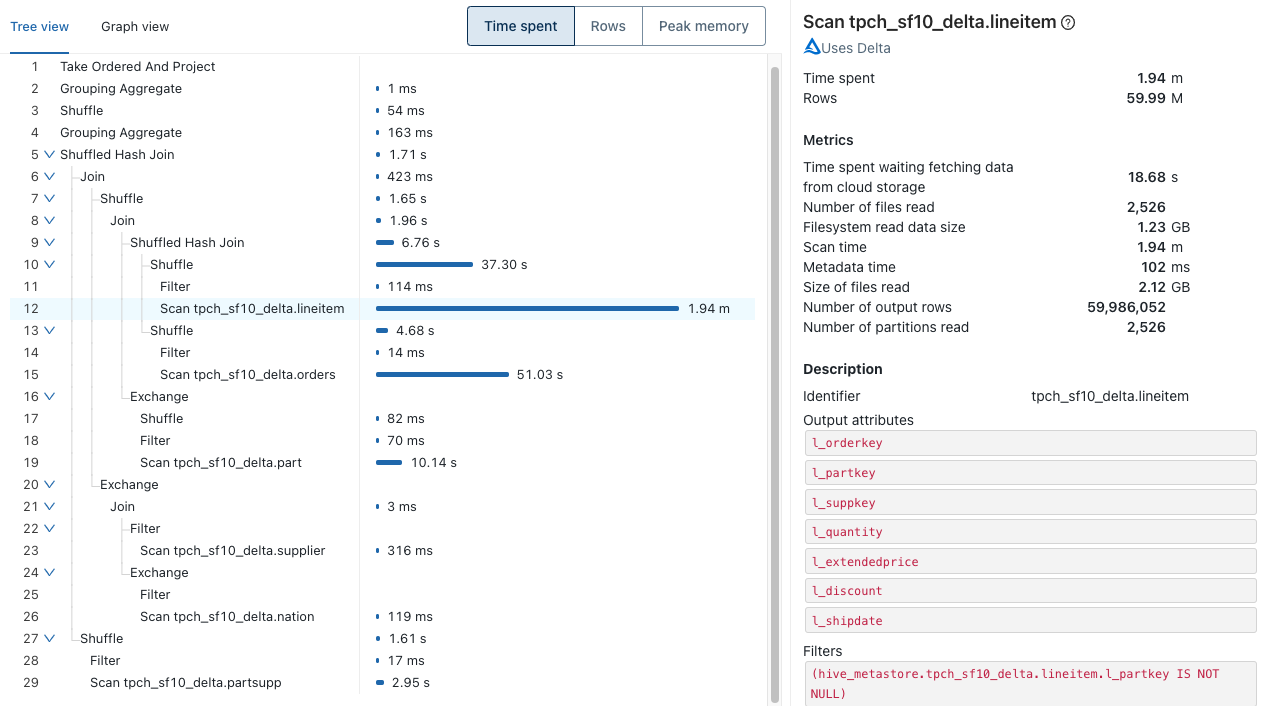
それぞれのクエリーオペレーターは多くの統計情報を持っています。スキャンオペレーターの場合、メトリクスには読み込まれたファイル、データの数、クラウドストレージの待ち時間やファイルの読み込み時間が含まれます。結果として、どのテーブルを最適化すべきか、あるいは、joinに改善する余地があるかという疑問に容易に回答することができるようになります。
クエリー履歴の大掃除
また我々は、クエリー履歴に小さいですが使いやすい改善をしたことを発表できて嬉しく思っています。それぞれのクエリーでアクセスできる詳細情報を増強しました。今では、クエリーのステータス、SQL文、処理時間のブレークダウンと最も重要な実行メトリクスのサマリーを参照することができます。
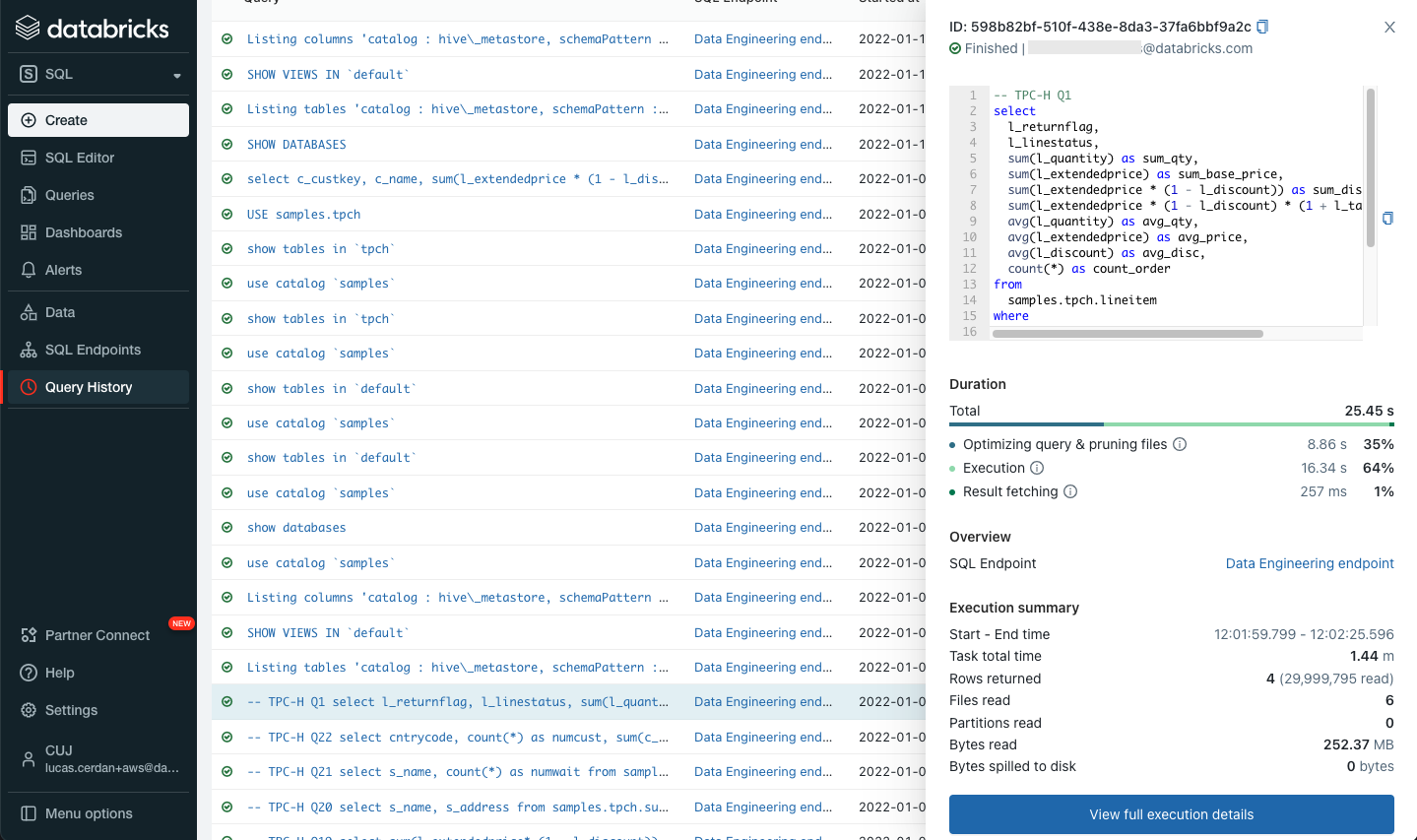
SQLエディターとクエリー履歴を行ったり来たりすることがないようにするために、上述した全ての機能はSQLエディターから直接アクセスすることができます。
クエリープロファイルはDatabricks SQLで利用することができます。フリートライアルに申し込んでDatabricks SQLを使ってみてください。