Build a Customer 360 Solution with Fivetran and Delta Live Tables - The Databricks Blogの翻訳です。
本書は抄訳であり内容の正確性を保証するものではありません。正確な内容に関しては原文を参照ください。
DatabricksレイクハウスプラットフォームにおけるFivetran、DLTパイプライン、ETLのインテグレーション
Databricksレイクハウスプラットフォームはデータレイクとデータウェアハウスのベストな部分を組み合わせたオープンアーキテクチャです。本記事では、通常のレガシープラットフォームであれば構築に数ヶ月かかる、データや洞察をもたらすカスタマー360ソリューションを、レイクハウスでどのように構築するのかを説明します。SalesforceやMySQLからのデータ取り込みにFivetranを使い、高信頼、メンテナンス可能、テスト可能なデータパイプラインを構築するための宣言型ETLフレームワークであるDelta Live Tables(DLT)を用いてデータを変換します。カスタマー360ソリューションを実装するには、変更を追跡できる様にする必要があります。ここでは、DLTがチェンジデータキャプチャ(CDC)をどのようにシームレスに処理し、カスタマー360ソリューションを最新の状態に保つのかをご説明します。
すべてのコードはこちらのGitHubレポジトリから利用できます。
Delta Live Tablesを使ってみるやChange Data Capture With Delta Live Tableをご覧ください。これらの記事では、どのようにスケーラブル、高信頼なデータパイプラインを構築するのか、DLTのチェンジデータキャプチャ機能と宣言型APIを用いてアップデートを処理する方法を説明しています。
我々のタスク: マルチチャンネルの顧客とのインタラクションに対する統合ビューを構築する
企業においては多くの場合、自身の顧客が自分達の製品とどの様にやり取りしているのかに関して包括的かつ様々な方法を探しています。例えば、衣料品の小売業者は、顧客がいつウェブサイトをブラウズしたのか、直接ある店舗を訪れたのか、トランザクションを完了したのかを知りたいと考えます。カスタマー360として知られる顧客インタラクションに対するこの統合ビューは、パーソナライズされたレコメンデーションから顧客セグメンテーションに至る様々なユースケースを強化します。Databricksがどのようにこのタスクをより簡単にするツールやパターンを提供しているのかを見ていきましょう。
メダリオンアーキテクチャは、アーキテクチャの各レイヤー(ブロンズ⇒シルバー⇒ゴールドテーブル)をデータが流れるに従って構造と品質をインクリメンタルかつ前進的に改善することを狙いとしており、レイクハウスにおけるデータを論理的に整理します。カスタマー360の取り組みをサポートするために、通常データはデータベースからAdobe Analyticsのようなマーケティングアプリケーションに至る様々なソースシステムに存在しています。最初のステップは、Fivetranを用いてこれらのデータタイプをブロンズレイヤーに取り込むところからとなります。レイクハウスにデータが到着すると、シルバー、ゴールドレイヤーのデータを変換、クレンジングするためにDelta Live Tablesが活用されます。このソリューションのシンプルさによって、慣れ親しんだSQLやPythonを用いてETLパイプラインを構築するために複雑なコードを記述することなしに、価値を迅速に得ることが可能となります。Databricksレイクハウスプラットフォームは、オペレーション、インフラストラクチャ、スケールのすべてのをハンドリングします。
以下の図では、アナリストやデータサイエンティストの様な後段の利用者が、どのように新鮮なデータや洞察を活用できるのかを示しています。
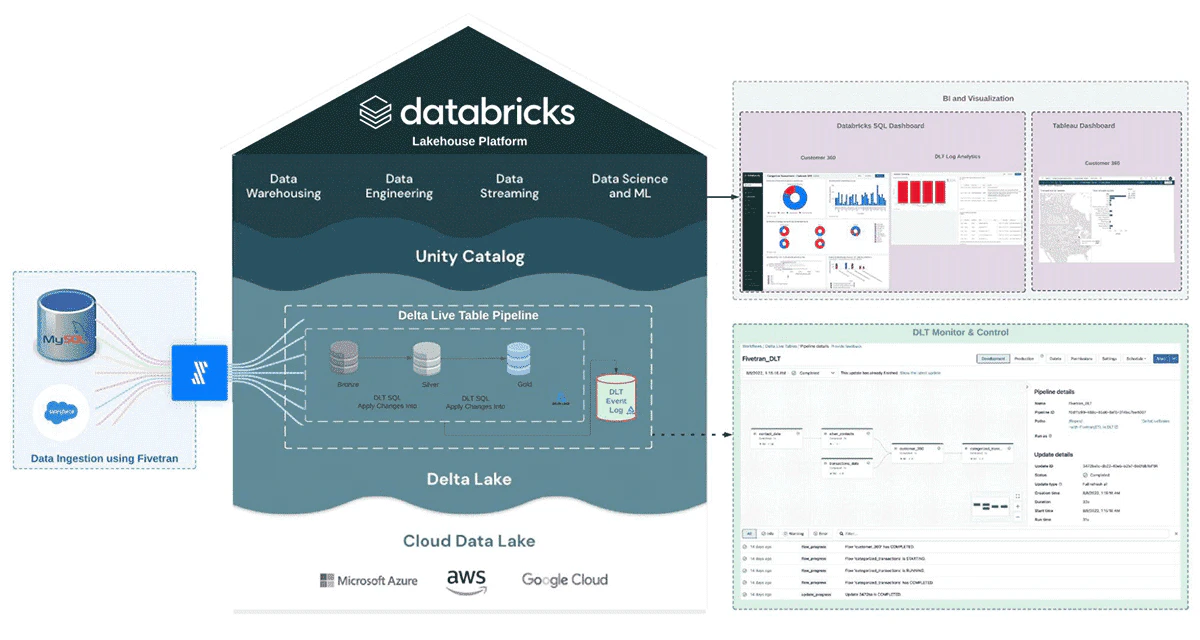
Fivetran、Databricks、Delta Live Tablesを用いたカスタマー360のリファレンスアーキテクチャ
Fivetran: レイクハウスへの自動データ取り込み
様々なアプリケーション、データベース、その他のレガシーシステムからのデータの抽出は困難なものです: APIやプロトコル、変更し続けるスキーマ、リトライなどを取り扱わなくてはなりません。Fivetranのマネージドコネクターによって、ユーザーは200以上のソースからDatabricksレイクハウスプラットフォームへのデータ取り込みを完全に自動化できます。
- コネクターを設定、テストするためのユーザーフレンドリーなUI。
- スキーマドリフト対応を含む自動スキーマ管理。
- API障害、レートリミットなどへの対応。
- 完全、インクリメンタルなロード。
Databricks Partner ConnectによるFivetranへのセキュアな接続
Databricks Partner Connectによって、管理者は数クリックでパートナーへの接続をセットアップすることができます。左のナビゲーションバーからPartner Connectをクリックし、Fivetranロゴをクリックします。DatabricksがFivetranのトライアルアカウントをセットアップし、Fivetranへの認証をセットアップし、レイクハウスにデータを取り込むためにFivetranが使用するSQLウェアハウスを作成します。
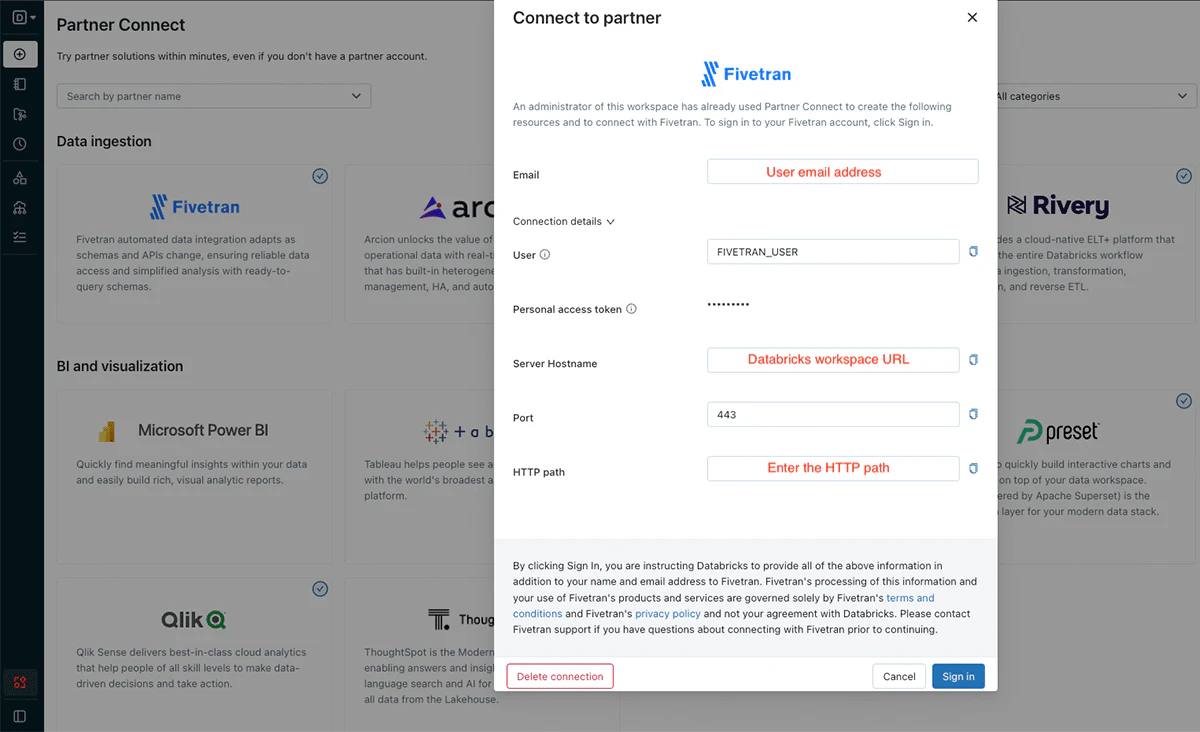
Databricks Partner ConnectでFivetranを選択し、認証情報を入力
Azure MySQLからのインクリメンタルなデータの取り込み
通常、データベースには我々のタスクに必要な顧客の注文や課金情報のようなトランザクション情報が格納されています。このデータを取り込み、Delta Lakeテーブルに取り込むために、FivetranのMySQLコネクターを使用します。Fivetranのコネクターは初期の同期をハンドリングし、大規模データベースデプロイメントにおいては必須である、更新行のみのインクリメンタルな同期にも使用することができます。
Databricks Partner Connectと左のナビゲーションバーのDestinationsからFivetranにサインインします。作成されたDatabricks SQL Warehouse Partner Connectを選択し、Add Connectorをクリックします。
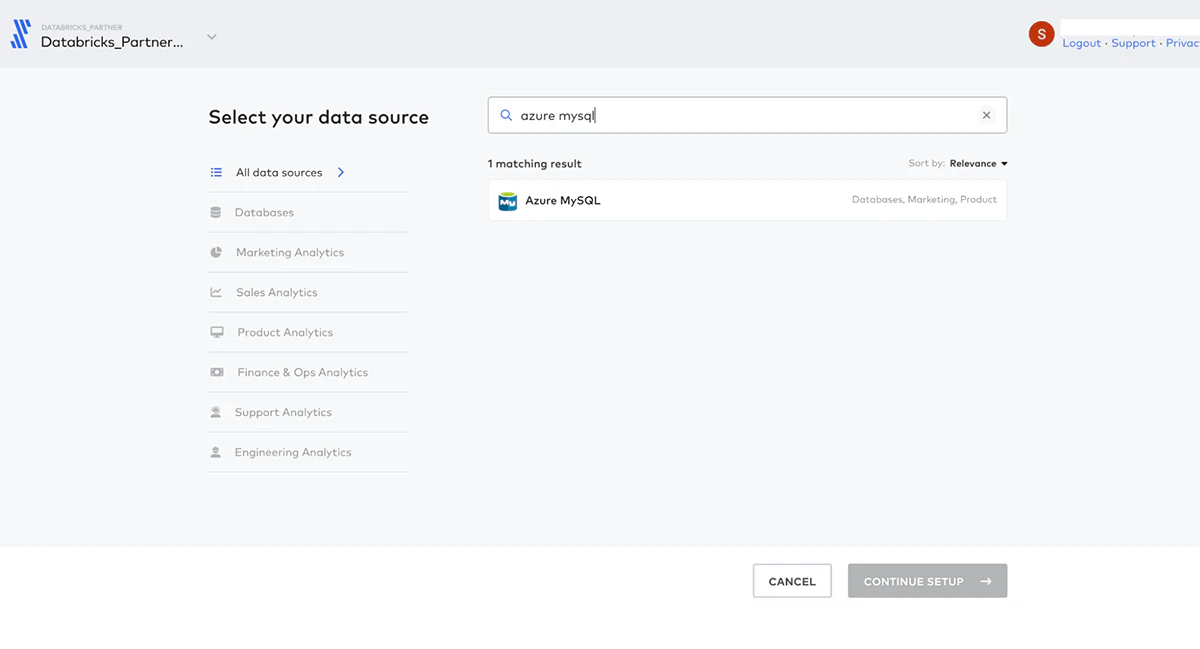
データソースからAzure MySQLを選択し、Add Connectorをクリック
Azure Portalから取得できる接続情報の詳細を指定して、データベースに接続します。MySQLバイナリーログを読み込むことでDatabricksにインクリメンタルな変更を同期するためにFivetranを使用します。
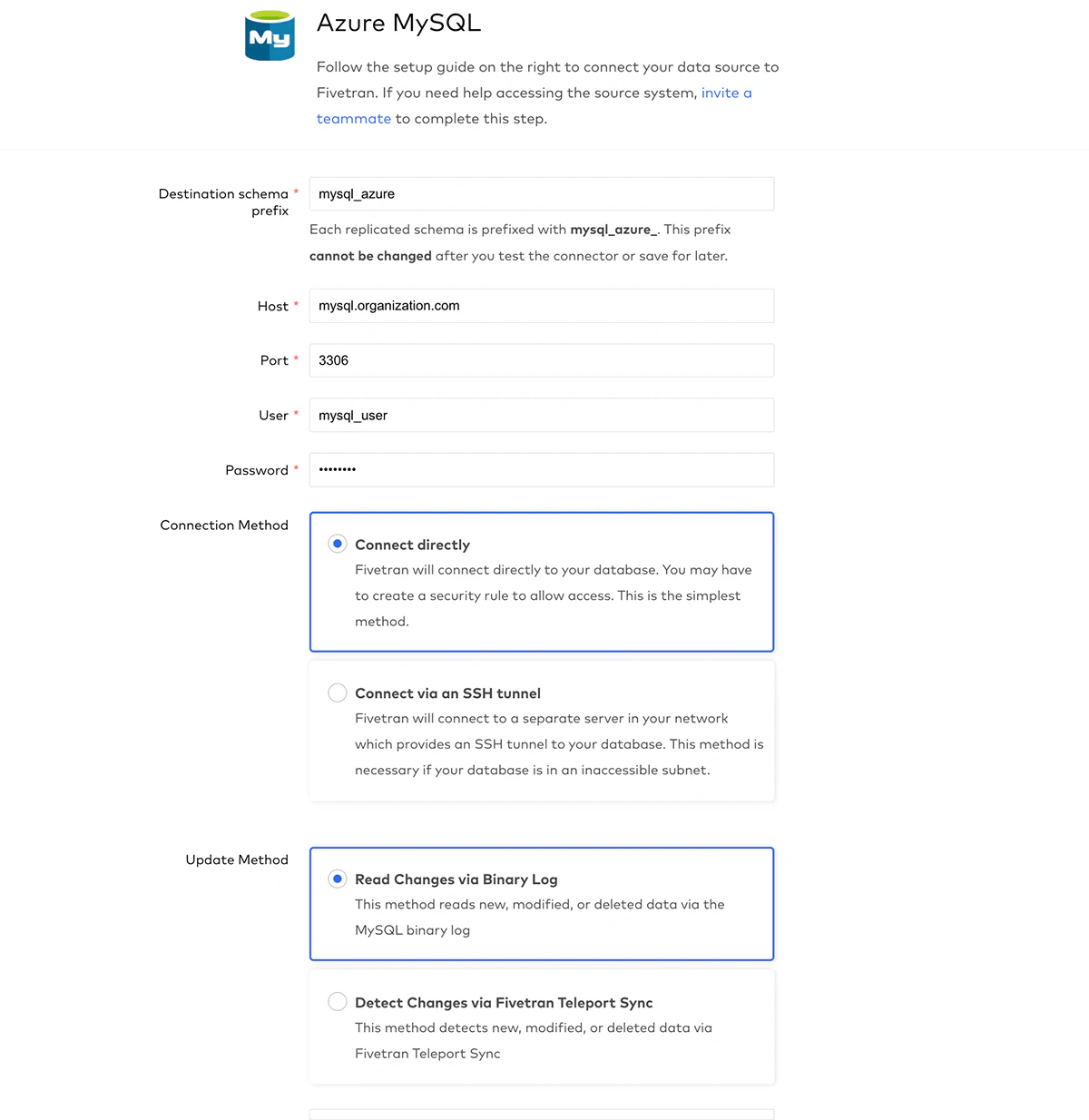
Azure MySQLがFivetranに接続するための認証情報を入力
次に、Databricksに同期したいテーブルを選択します。この場合、トランザクションを同期します。
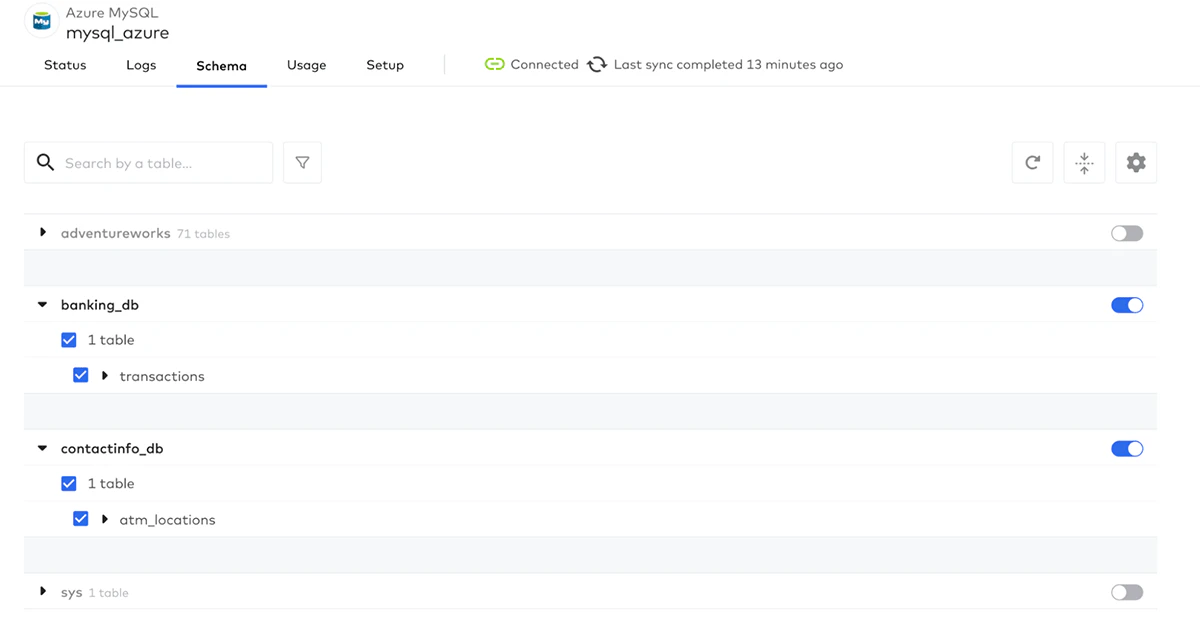
Databricksに同期するテーブルを選択
同期を開始するためにSync Nowをクリックします。
FivetranダッシュボードのステータスページのSync Historyチャート
Salesforceからの顧客データの取り込み
Salesforceは、非常に人気のあるCustomer Relationship Management(CRM)プラットフォームです。通常、CRMにはマーケティングのタッチポイント、セールスオポチュニティのような非トランザクションの顧客データが格納されています。このデータは、我々のカスタマー360ソリューションの構築において非常に価値のあるものとなります。FivetranのSalesforceコネクターを用いることで、このデータのロードを簡単に行える様になります。
Fivetranで、destinationとして上のステップで作成したSQLウェアハウスを選択し、Add Connectorをクリックします。Salesforceコネクターを選択します。
データソースのリストからSalesforceを選択
Fivetranでは、数クリックでSalesforceの認証を完了することができます。

SalesforceがFivetranに接続するための認証情報を入力
次に、Databricksに同期したいSalesforceオブジェクトを選択します。このケースでは、Contactオブジェクトがアカウントに関連づけられている顧客コンタクトに関する情報を保持していますので、これをDatabricksに同期しましょう。
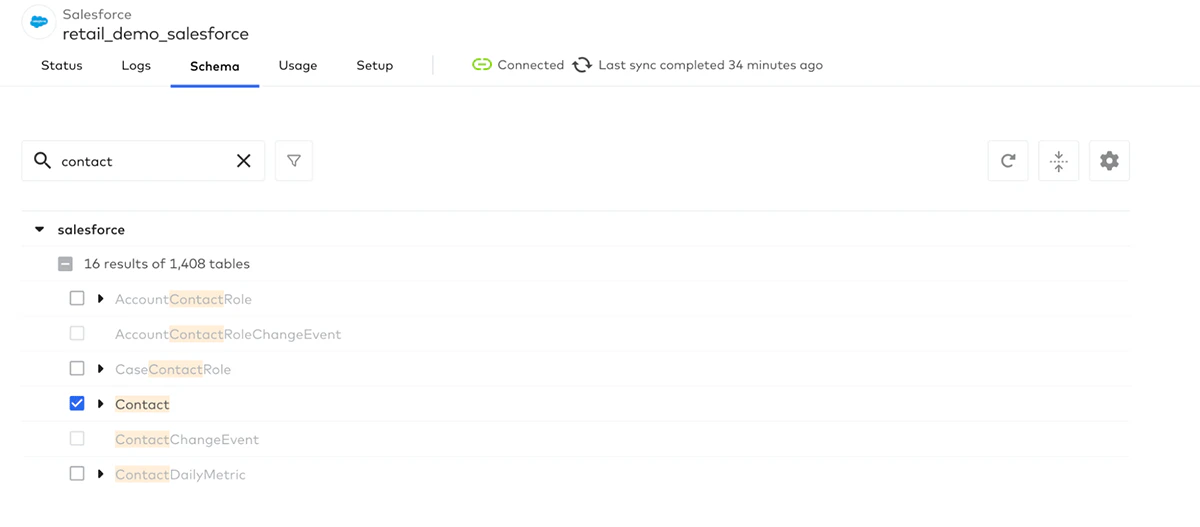
Databricksに同期するオブジェクトを選択
データを初回同期するためにSync Nowをクリックします。また、Fivetranでは同期を自動でスケジュールすることもできます。この完全にマネージドなコネクターは、初期のロードとインクリメンタルな変更のロードも取り扱うことができます。

FivetranダッシュボードのステータスページのSync Historyチャート
Databricksでテーブルとカラムをレビューする
これで入力データの変換の準備がほぼ整いました。しかし、最初にスキーマをレビューしましょう。
transactions: 顧客によるすべてのトランザクションであり、インクリメンタルに処理する必要があります。Fivetranから受け取るレコードは、最終的にはブロンズレイヤーに永続化されます。transactionsテーブルには10カラムあります。

また、Fivetranが生成、維持管理するチェンジデータキャプチャの2つのフィールドを確認することができます。

contact_info: これは90以上のフィールド(氏名、電話番号、メール、職位など)を持つ顧客のディメンショナルな情報であり、これもブロンズレイヤーに取り込まれます。

Delta Live Tablesを用いたデータ変換
データが入手できたので、カスタマー360ソリューションのためにデータを変換、クレンジングするためにDelta Live Tablesを活用します。データの変換処理を表現するためにDLTの宣言型APIを使用します。DLTは、ETLパイプラインに含まれるテーブル、ビュー間のデータフローとリネージュを自動で追跡します。DLTはDeltaのエクスペクテーxションを用いてデータ品質を追跡し、不正レコードの検疫や削除の様な修正アクションを適用し、後段に不正なデータが流入することを防ぎます。Slowly Changing Dimension (SCD) Type 2を作成するためにDLTを使います。最後に、クラスターを手動でチューニングする必要がない様に、DLTにELTインフラストラクチャのスケールアップとスケールダウンをケアさせる様にします。
ノートブックでDelta Live Tableを定義
DLTパイプラインは、1つ以上のノートブックで定義することができます。Databricksにログインし、左のナビゲーションバーのNewをクリックし、ノートブックを選択します。ノートブックの言語をSQLに設定します(同じパイプラインをPythonで定義することもできます)。

DatabricksノートブックでDLT SQLロジックを作成
DLTのSQLロジックを詳細に見ていきましょう。DLTテーブルを定義する際に、依存関係を管理し、オペレーションを自動化するために特別なLIVEキーワードを使います。次に、mailing_countryはUnited Statesであるべきであると言ったエクスペクテーションを用いてデータの適切性を保証します。この品質チェックに失敗した行は削除されます。メタデータを設定するためにテーブルプロパティを使います。最後に、品質チェックに通過したすべての行すべてをシンプルにselectします。
CREATE LIVE TABLE contact_data (
CONSTRAINT `id should not be null` EXPECT (id IS NOT NULL) ON VIOLATION DROP ROW,
CONSTRAINT `mailing_country should be US` EXPECT (mailing_country = 'United States') ON VIOLATION DROP ROW,
CONSTRAINT `mailing_geocode_accuracy should be Address` EXPECT (mailing_geocode_accuracy = 'Address') ON VIOLATION DROP ROW
) COMMENT "bronze table properly takes contact data Ingested from salesforce through Fivetran on each sync" TBLPROPERTIES ("quality" = "bronze") AS
SELECT
*
FROM
retail_demo_salesforce.contact;
同様に、transactions_dataテーブルを作成するために同じフォーマットに従い、item_countに対して正の値を持つ行のみを持つ様にデータ品質のエクスペクテーションを追加し、この評価基準を満たさない行は削除します。
CREATE LIVE TABLE transactions_data (
CONSTRAINT `item_count should be positive value` EXPECT (item_count > 0) ON VIOLATION DROP ROW
) COMMENT "bronze table properly takes transaction data Ingested from mysql through Fivetran on each sync" TBLPROPERTIES ("quality" = "bronze") AS
SELECT
*
FROM
mysql_azure_banking_db.transactions;
APPLY CHANGES INTOによるデータ変更履歴の追跡
それでは、もう少し面白いことをやってみましょう。顧客のコンタクト情報は変更される場合があります。例えば、顧客の住所は顧客が引っ越すたびに変更されます。APPLY CHANGES INTOキーワードを用いてクエリーしやすいSCDタイプ2テーブルを用いて変更を追跡しましょう。このコンセプトにあまり触れたことがない方は、以前のブログ記事をご覧ください。
データの変化を追跡するために、STREAMING LIVE TABLEを作成します。ストリーミングライブテーブルは、最後のパイプラインアップデート以降に追加されたデータのみを処理します。APPLY CHANGES INTOでは、CDCデータ処理の魔法が効果を発揮します。ストリーミングライブテーブルを使用しているので、contact_dataテーブルに対する変更のストリームを選択します。DLTはテーブルとテーブル間の関係性をメンテナンスするので、contact_dataテーブルに対する特別な名前空間としてどのようにLIVEを使っているのかに注意してください。最後に、Fivetranがレコード削除を指示した際に、upsertではなくDLTに堕駆除ロジックを適用する様に指示します。SEQUENCE BYを用いることで、順序を守らず到着した変更イベントをシームレスにハンドリングすることができます。SEQUENCE BYでは、ソースデータのCDCイベントの論理的順序を指定するカラムを使用します。最後に、DLTにSCDタイプ2テーブルとしてデータを格納する様に指示します。
CREATE STREAMING LIVE TABLE silver_contacts;
APPLY CHANGES INTO LIVE.silver_contacts
FROM
stream(LIVE.contact_data) KEYS (id) APPLY AS DELETE
WHEN is_deleted = "true" SEQUENCE BY _fivetran_synced COLUMNS *
EXCEPT
(is_deleted, _fivetran_synced) STORED AS SCD TYPE 2;
分析に使用できるゴールドテーブル
DLTによるゴールドテーブル作成は非常にわかりやすいものです。以下の様にいくつかの集計処理に必要なカラムを選択するだけです。
CREATE LIVE TABLE customer_360
COMMENT "Join contact data with transaction data and materialize a live table"
TBLPROPERTIES ("quality" = "gold")
AS SELECT contact.*,
transactions._fivetran_id,
transactions.operation,
transactions.customer_id,
transactions.transaction_date,
transactions.id as transaction_id,
transactions.operation_date,
transactions.amount,
transactions.category,
transactions.item_count,
transactions._fivetran_index,
transactions._fivetran_deleted
FROM LIVE.transactions_data as transactions
LEFT JOIN live.silver_contacts as contact ON contact.id = transactions.customer_id;
CREATE LIVE TABLE categorized_transactions
COMMENT "Join contact data with transaction data and materialize a gold live table with aggregations"
TBLPROPERTIES ("quality" = "gold")
AS SELECT
account_id,
first_name,
last_name,
sum(amount) as total_expense,
transaction_date,
category
FROM LIVE.customer_360
GROUP BY
account_id,
first_name,
last_name,
transaction_date,
category
初めてのDLT実行
これで初めてのDLTを実行する準備が整いました。DLTパイプラインを作成するにはWorkflowsに移動します。左のナビゲーションバーでWorkflowsをクリックし、Delta Live Tablesをクリックします。そして、Create Pipelineをクリックします。
DLTパイプラインを作成するために、ナビゲーションバーでWorkflowsをクリックし、Delta Live Tablesを選択
パイプラインに「Customer 360」という名前を付け、Notebook librariesで事前に定義したノートブックを選択します。
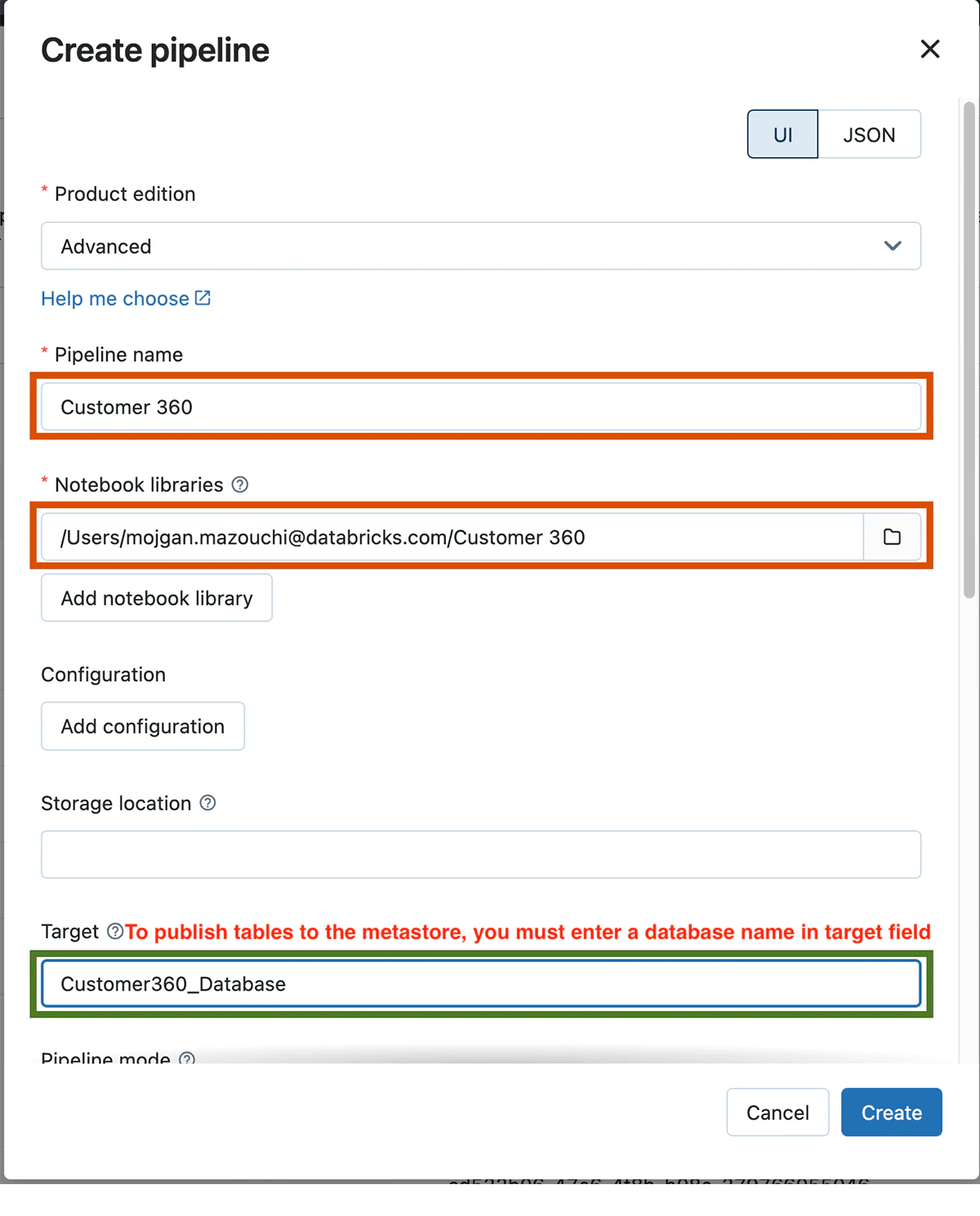
パイプラインの作成に必要な設定とパラメーターを指定
Databricksメタストアにテーブルが公開される様に、ターゲットのデータベース名を指定する必要があります。パイプラインが作成されたら、初めて実行するためにStartをクリックします。すべての設定が適切であれば、ノートブックで定義したデータ変換処理のDAGが表示されます。
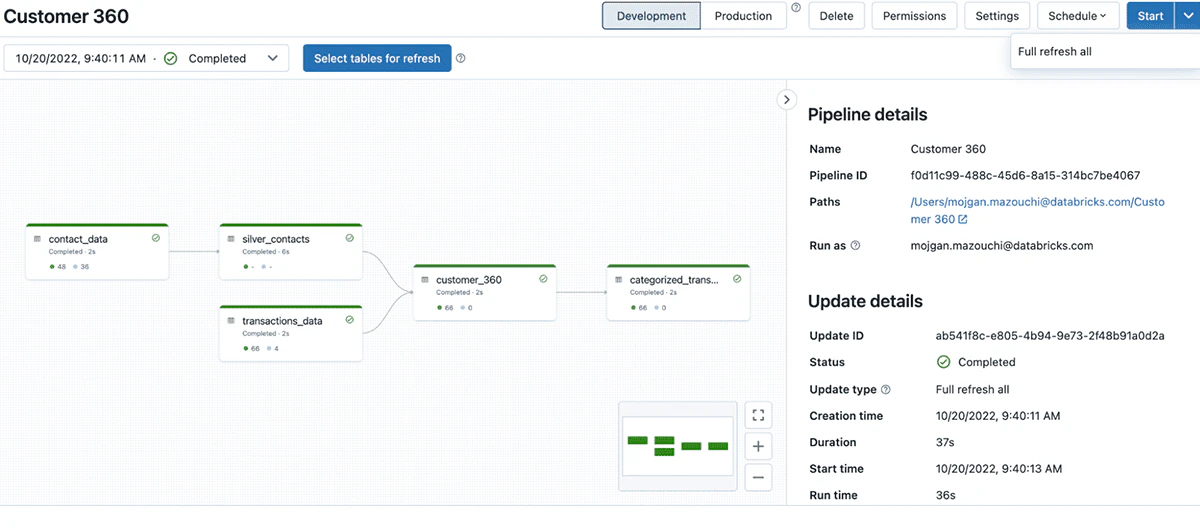
作成したDLTパイプラインで完了した処理のビュー、公開されたテーブルのリネージュを表示
左のナビゲーションバーのDataをクリックすることで、これら公開されたテーブルを参照することができ、DLTパイプラインの設定でターゲットフィールドに指定したデータベース名で検索することができます。

Azure Databricksの左側のナビゲーションバーで、赤枠でハイライトしている「Data」からすべての公開テーブルにアクセスできます
Databricks SQLを用いたデータ品質とパイプラインのモニタリング
DLTはパイプライン実行時のイベントをログに記録します。これらのイベントには、データ品質チェック、パイプライン実行時の統計情報、全体的なパイプラインの進捗が含まれます。これで、データパイプラインをうまく構築できたので、このリッチなメタデータをベースとしたデータ品質モニタリングダッシュボードを構築するためにDatabricks SQLを活用しましょう。以下のスクリーンショットでは最終成果物を示しています。
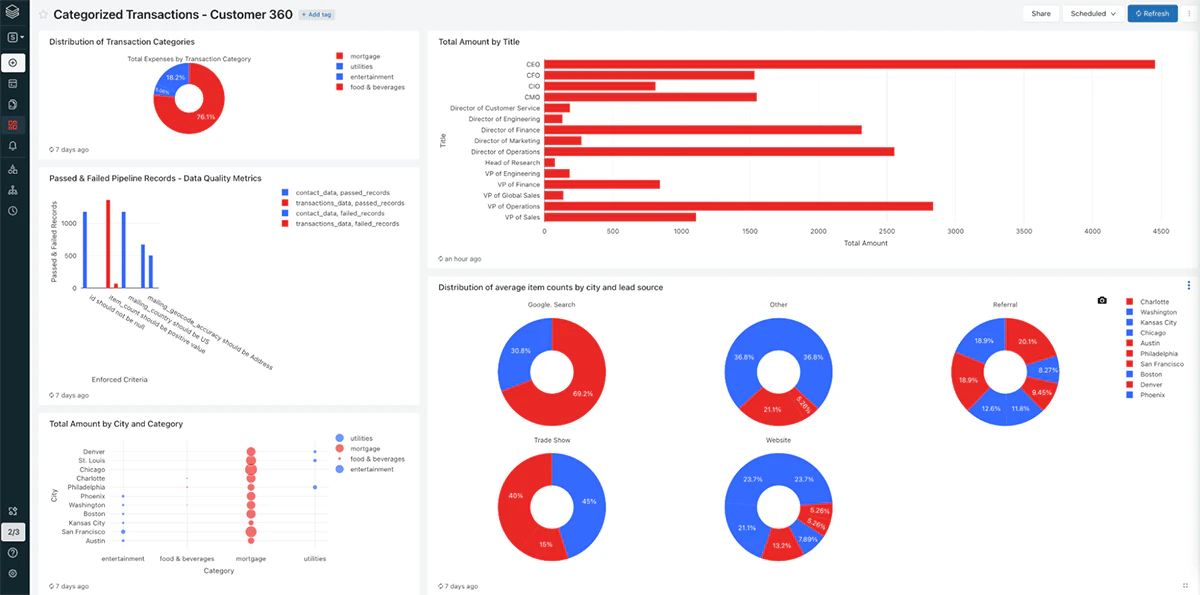
DLTパイプラインのメタデータから構築したデータ品質モニタリングダッシュボードのスクリーショット
DLTはパイプラインのストレージロケーションにメタデータを格納します。このロケーションに格納された、パイプラインのイベントログをクエリーするためのテーブルを作成することができます。左のナビゲーションバーのSQLをクリックし、以下のクエリーを貼り付けます。パイプライン作成時に設定したストレージロケーションで${storage_location}を置き換えます。デフォルトのストレージロケーションはdbfs:/pipelinesです。
CREATE OR REPLACE Table Customer360_Database.pipeline_logs
AS SELECT * FROM delta.`${storage_location}/system/events`;
SELECT * FROM Customer360_Database.pipeline_logs
ORDER BY timestamp;
メタデータをクエリーできることをテストするために、DLTが使っているDatabricksランタイム(DBR)のバージョンを取得するためにこのSQLを実行します。
SELECT details:create_update:runtime_version:dbr_version
FROM Customer360_Database.pipeline_logs
WHERE event_type = 'create_update'
LIMIT 1;
例として、以下のSQLクエリーを用いて、DLTによって生成されるデータの品質をクエリーすることができます。
SELECT
timestamp,
Double(details:cluster_utilization.num_executors) as current_num_executors,
Double(details:cluster_utilization.avg_num_task_slots) as avg_num_task_slots,
Double(
details:cluster_utilization.avg_task_slot_utilization
) as avg_task_slot_utilization,
Double(
details :cluster_utilization.avg_num_queued_tasks
) as queue_size,
Double(details :flow_progress.metrics.backlog_bytes) as backlog
FROM
Customer360_Database.pipeline_logs
WHERE
event_type IN ('cluster_utilization', 'flow_progress')
AND origin.update_id = '${latest_update_id}'
ORDER BY timestamp ASC;
まとめ
本書では、MySQLデータベースからのトランザクションデータとSalesforceの顧客情報を用いてカスタマー360ソリューションを構築しました。最初に、レイクハウスにデータを取り込むためにどのようにFivetranを使い、DatabricksのDelta Live Tableを用いたデータの変換処理、クレンジングを行うのかを説明しました。最後に、DLTを用いることでデータチームはデータ品質を適用し、品質をモニタリングする能力を手に入れることができました。Databricksレイクハウスプラットフォームを用いることで、企業は作成、管理、スケールがシンプルなパワフルなカスタマー360アプリケーションを構築できる様になります。
Databricksでデータアプリケーションの構築をスタートするにはFivetranやDelta Live Tablesのドキュメントをご確認いただき、本書で触れたダッシュボードを構築するには、Githubリポジトリにあるコードやサンプルクエリーをチェックしてみてください。