こちらの続編です。
こちらのノートブックを実行していきます。動画はこちらです。
0. セットアップ
このノートブックの一般的なヒント:
- Spark UIはクラスター -> Spark UIでアクセス可能
- Spark UIの詳細な調査は後のエピソードで行います
-
sc.setJobDescription("Description")はSpark UIのアクションのジョブ説明を独自のものに置き換えます -
sdf.rdd.getNumPartitions()は現在のSpark DataFrameのパーティション数を返します -
sdf.write.format("noop").mode("overwrite").save()は、実際の書き込み中に副作用なしで変換を分析および開始するための良い方法です
クラスターは前回同様4コアのものを使います。
from pyspark.sql import SparkSession
from pyspark.sql import functions as f
import pyspark
指定された行数とパーティション数を持つSparkデータフレームを返却する関数。
def sdf_generator(num_rows: int, num_partitions: int = None) -> "DataFrame":
return (
spark.range(num_rows, numPartitions=num_partitions)
.withColumn("date", f.current_date())
.withColumn("timestamp",f.current_timestamp())
.withColumn("idstring", f.col("id").cast("string"))
.withColumn("idfirst", f.col("idstring").substr(0,1))
.withColumn("idlast", f.col("idstring").substr(-1,1))
)
sdf_gen = sdf_generator(20)
sdf_gen.count()
20
sdf_gen.show()
+---+----------+--------------------+--------+-------+------+
| id| date| timestamp|idstring|idfirst|idlast|
+---+----------+--------------------+--------+-------+------+
| 0|2024-12-02|2024-12-02 07:32:...| 0| 0| 0|
| 1|2024-12-02|2024-12-02 07:32:...| 1| 1| 1|
| 2|2024-12-02|2024-12-02 07:32:...| 2| 2| 2|
| 3|2024-12-02|2024-12-02 07:32:...| 3| 3| 3|
| 4|2024-12-02|2024-12-02 07:32:...| 4| 4| 4|
| 5|2024-12-02|2024-12-02 07:32:...| 5| 5| 5|
| 6|2024-12-02|2024-12-02 07:32:...| 6| 6| 6|
| 7|2024-12-02|2024-12-02 07:32:...| 7| 7| 7|
| 8|2024-12-02|2024-12-02 07:32:...| 8| 8| 8|
| 9|2024-12-02|2024-12-02 07:32:...| 9| 9| 9|
| 10|2024-12-02|2024-12-02 07:32:...| 10| 1| 0|
| 11|2024-12-02|2024-12-02 07:32:...| 11| 1| 1|
| 12|2024-12-02|2024-12-02 07:32:...| 12| 1| 2|
| 13|2024-12-02|2024-12-02 07:32:...| 13| 1| 3|
| 14|2024-12-02|2024-12-02 07:32:...| 14| 1| 4|
| 15|2024-12-02|2024-12-02 07:32:...| 15| 1| 5|
| 16|2024-12-02|2024-12-02 07:32:...| 16| 1| 6|
| 17|2024-12-02|2024-12-02 07:32:...| 17| 1| 7|
| 18|2024-12-02|2024-12-02 07:32:...| 18| 1| 8|
| 19|2024-12-02|2024-12-02 07:32:...| 19| 1| 9|
+---+----------+--------------------+--------+-------+------+
1. coalesceの動作原理
- ドキュメント: https://spark.apache.org/docs/latest/api/python/reference/pyspark.sql/api/pyspark.sql.functions.coalesce.html
- 狭い変換
- パーティションの数を減らすだけで、増やすことはできません。初めに利用可能なパーティション数よりも高い値は無視されます。
- Coalesceは各パーティション内のデータを偏らせることがあり、パフォーマンスが低下し、一部のタスクが非常に長く実行される可能性があります。
- Coalesceは高い数の小さなパーティションを効率的に減らし、パフォーマンスを向上させるのに役立ちます。ただし、パーティションの数があまりにも少ない(より大きなパーティション)場合、OOMやその他の問題が発生する可能性があります。コア数の2-4倍のファクターが推奨されていますが、実際には利用可能なメモリに依存します。コア数を増やすことができない場合、安定した実行でメモリの制限に達しない唯一のオプションは、パーティションの数を増やすことです。インターネット上の推奨事項は、100-1000 MBの間です。Sparkは最大パーティションバイト数のパラメータを128 MBに設定しています。
4つのパーティションから構成される20億行のデータフレームを作成します。
num_rows = 2000000000
sdf1 = sdf_generator(num_rows, 4)
sdf1.rdd.getNumPartitions()
4
row_count1 = sdf1.count()
print(row_count1)
2000000000
パーティションの分布を確認します。
sdf_part1 = sdf1.withColumn("partition_id", f.spark_partition_id())
sdf_part_count1 = sdf_part1.groupBy("partition_id").count()
sdf_part_count1 = sdf_part_count1.withColumn("count_perc", 100*f.col("count")/row_count1)
sdf_part_count1.show()
+------------+---------+----------+
|partition_id| count|count_perc|
+------------+---------+----------+
| 0|500000000| 25.0|
| 1|500000000| 25.0|
| 2|500000000| 25.0|
| 3|500000000| 25.0|
+------------+---------+----------+
ベースラインとして、4パーティションのデータフレームを作成するジョブを実行します。
sc.setJobDescription("Baseline 4 partitions")
sdf1.write.format("noop").mode("overwrite").save()
sc.setJobDescription("None")
パーティションを2つに削減します。
sdf1.coalesce(2).rdd.getNumPartitions()
2
パーティション数を増やそうとしても効果はありません。
sdf1.coalesce(12).rdd.getNumPartitions()
4
coalesceを実行しても、データフレームの行数は変わりません。
sdf2 = sdf1.coalesce(3)
row_count2 = sdf2.count()
print(row_count2)
2000000000
パーティションの分布を確認します。coalesceによって二つのパーティションが結合された結果、最後のパーティションにレコードが偏っています。
sdf_part2 = sdf2.withColumn("partition_id", f.spark_partition_id())
sdf_part_count2 = sdf_part2.groupBy("partition_id").count()
sdf_part_count2 = sdf_part_count2.withColumn("count_perc", 100*f.col("count")/row_count2)
sdf_part_count2.show()
+------------+----------+----------+
|partition_id| count|count_perc|
+------------+----------+----------+
| 0| 500000000| 25.0|
| 1| 500000000| 25.0|
| 2|1000000000| 50.0|
+------------+----------+----------+
このジョブCoalesce from 4 to 3の動作をSpark UIで確認します。
sc.setJobDescription("Coalesce from 4 to 3")
sdf2.write.format("noop").mode("overwrite").save()
sc.setJobDescription("None")
最初からパーティション数が3の場合を確認します。
sdf3 = sdf_generator(num_rows, 3)
print(sdf3.rdd.getNumPartitions())
sc.setJobDescription("3 Partitions")
sdf3.write.format("noop").mode("overwrite").save()
sc.setJobDescription("None")
均等に分布していることがわかります。
パーティション数8のデータフレームを作成します。
sdf4 = sdf_generator(num_rows, 8)
print(sdf4.rdd.getNumPartitions())
sc.setJobDescription("8 Partitions")
sdf4.write.format("noop").mode("overwrite").save()
sc.setJobDescription("None")
8
coalecseを用いてパーティション数を8から4に削減します。
sdf5 = sdf4.coalesce(4)
print(sdf5.rdd.getNumPartitions())
sc.setJobDescription("Coalesce from 8 to 4")
sdf5.write.format("noop").mode("overwrite").save()
sc.setJobDescription("None")
2つづつのパーティションが結合された結果、今回は均等に分配されました。
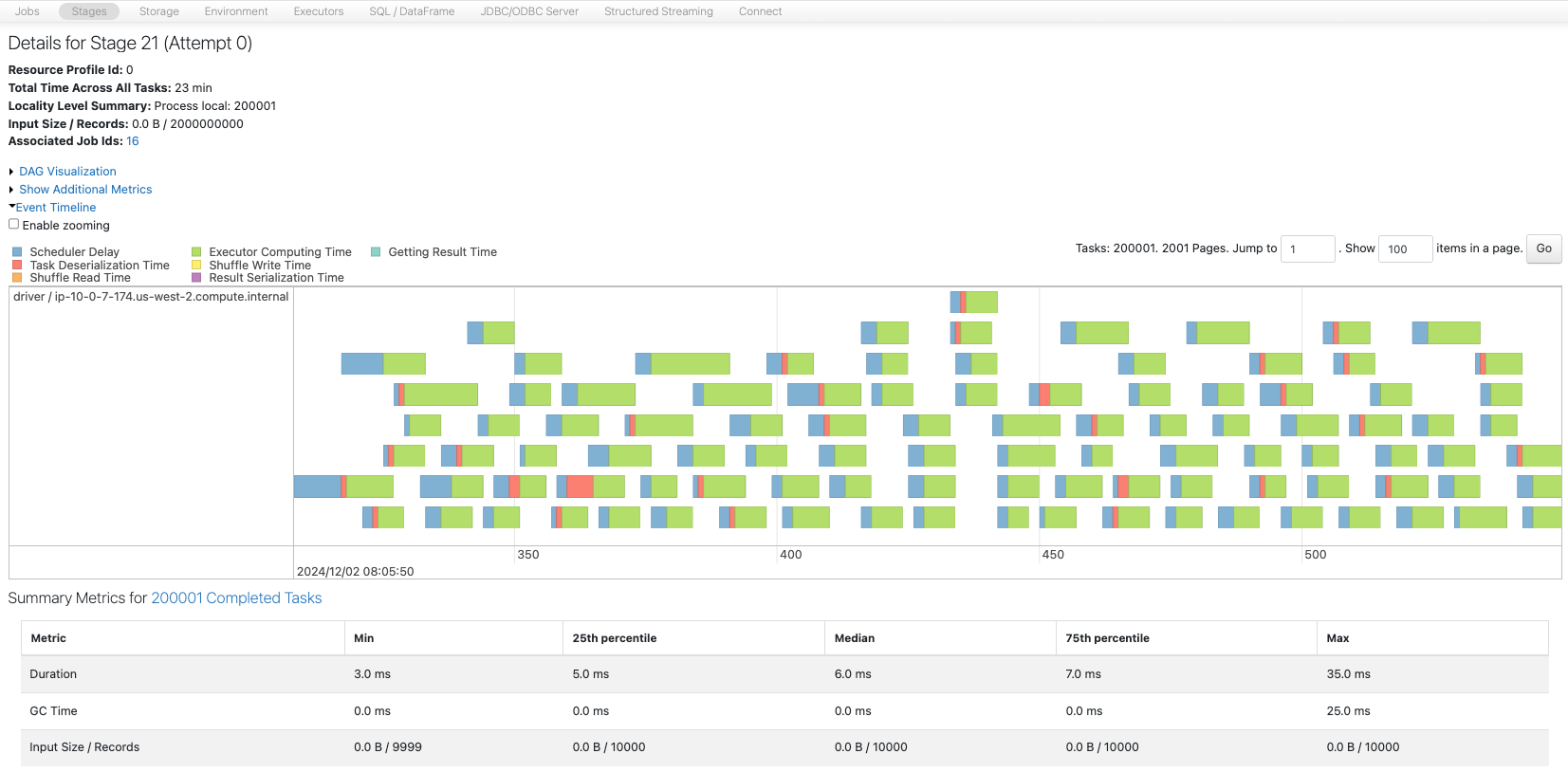
今度はパーティション数を200001個にします。
sdf6 = sdf_generator(num_rows, 200001)
print(sdf6.rdd.getNumPartitions())
sc.setJobDescription("200001 partitions")
sdf6.write.format("noop").mode("overwrite").save()
sc.setJobDescription("None")
200001
多数のパーティションを少ないコアで処理しなくてはならず、スケジューラの遅延が顕著になっています。
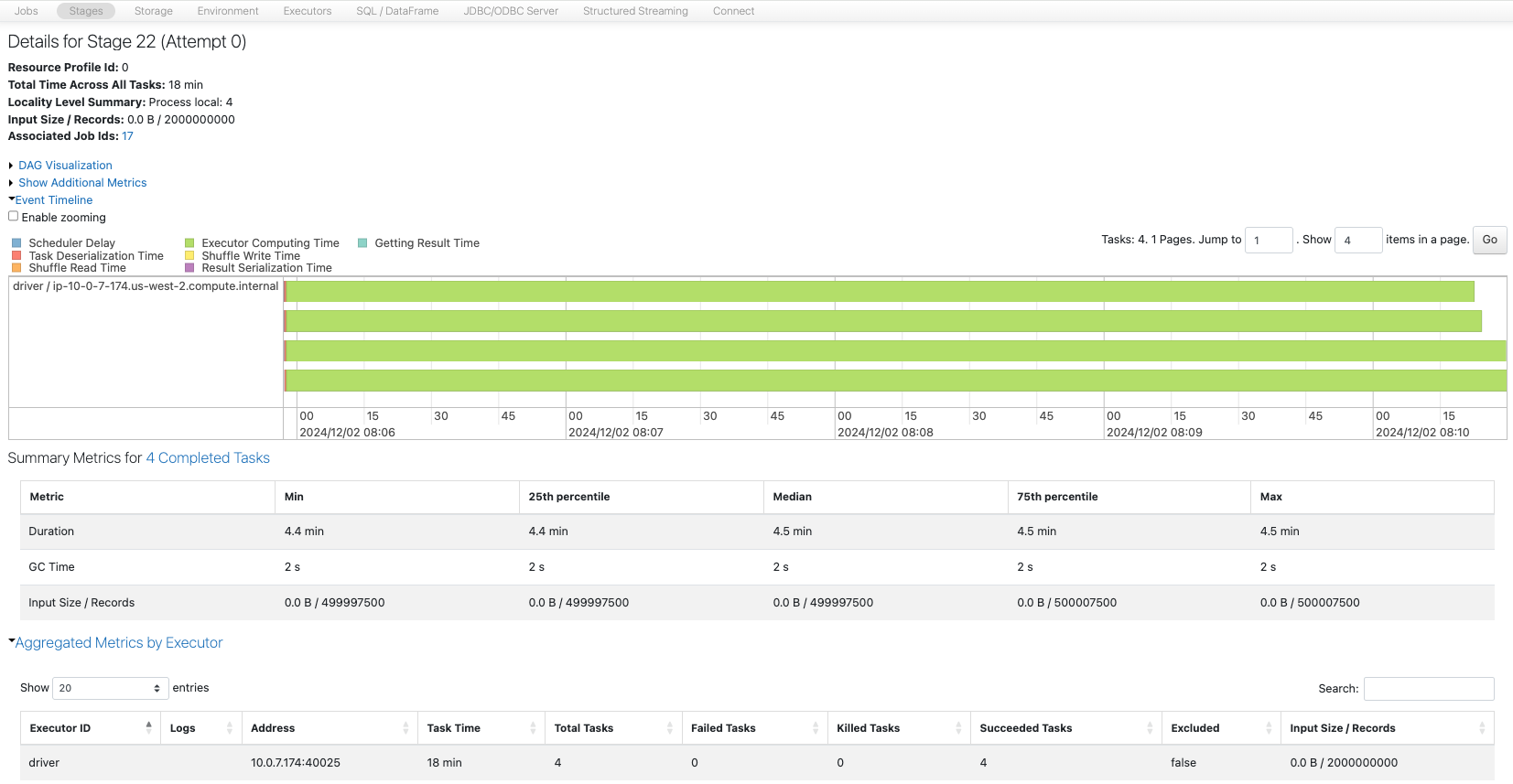
これを4つのパーティションに削減します。
sdf7 = sdf6.coalesce(4)
print(sdf7.rdd.getNumPartitions())
sc.setJobDescription("Coalesce from 200001 to 4")
sdf7.write.format("noop").mode("overwrite").save()
sc.setJobDescription("None")
均等に分配されました。
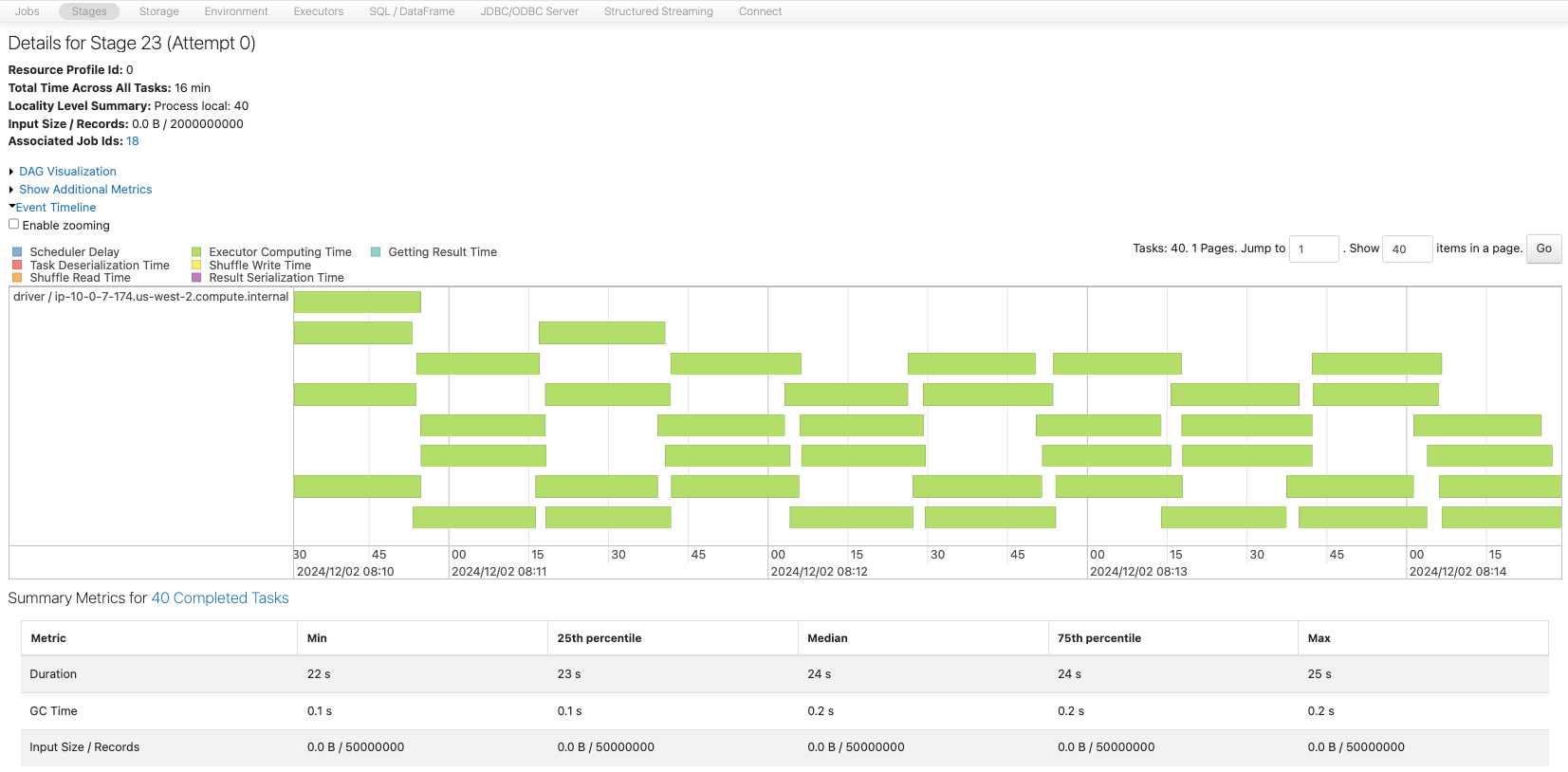
このデータフレームのサイズは約80GBであり、パーティション数を40にすると、200MB/パーティションとなり推奨値に収まります。
sdf8 = sdf_generator(num_rows, 40)
print(sdf8.rdd.getNumPartitions())
sc.setJobDescription("40 partitions")
sdf8.write.format("noop").mode("overwrite").save()
sc.setJobDescription("None")
この場合も、リソースを有効活用しながらタスクが実行されていることを確認できます。
膨大な数のパーティションを取り扱う際に、coalesceを用いることで効率的にパーティション数を削減し、パフォーマンスを改善できることを学びました。
次は、パーティション数を操作するもう一つの手段であるrepartion()を学びます。